Recognition: no theorem link
From Characterization to Microarchitecture: Designing an Elegant and Reliable BFP-Based NPU
Pith reviewed 2026-05-10 16:11 UTC · model grok-4.3
The pith
A BFP-based NPU microarchitecture achieves near-dual modular redundancy reliability with 3.55% performance overhead by decoupling mantissa and exponent paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By aligning BFP computational semantics with reliability constraints through a row/column-wise blocking strategy that decouples fixed-point mantissa computations from the scalar exponent path and by introducing ultra-lightweight protection mechanisms for each, the designed NPU achieves near-dual modular redundancy reliability with only 3.55% geometric mean performance overhead and less than 2% hardware cost.
What carries the argument
The row/column-wise blocking strategy that decouples the fixed-point mantissa computations from the scalar exponent path, allowing separate lightweight protections for each component.
If this is right
- BFP-based NPUs become viable for safety-critical deployments at low overhead instead of requiring full duplication.
- End-to-end checks alone prove insufficient for BFP formats because of the effects of nonlinear block scaling.
- Heterogeneous vulnerabilities across bits and paths require targeted, semantics-aligned protections rather than uniform redundancy.
- The microarchitecture preserves BFP hardware efficiency while adding the observed reliability gains.
Where Pith is reading between the lines
- Similar blocking and decoupling techniques could extend to other data formats in accelerators exposed to hardware faults.
- Semantic alignment between computation and protection mechanisms may reduce redundancy requirements in broader hardware designs.
- Validation on a wider range of workloads and real silicon would clarify how far the low-overhead reliability generalizes.
Load-bearing premise
RTL-level fault injection on the chosen workloads and BFP configurations produces fault behaviors representative of real silicon faults.
What would settle it
Physical fault injection on a fabricated chip version of the design, such as through radiation or voltage scaling, that shows whether error rates match the simulated near-DMR levels.
Figures

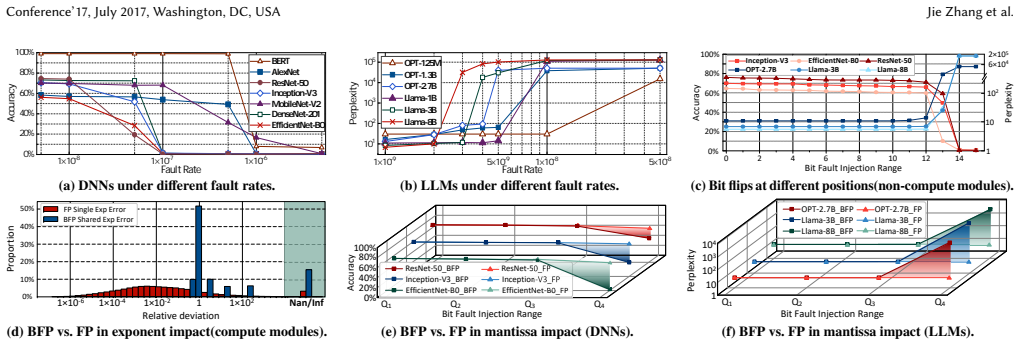
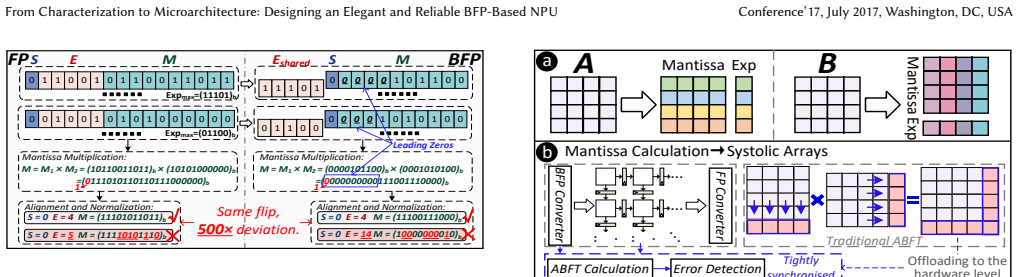






read the original abstract
Block Floating-Point (BFP) is emerging as an attractive data format for edge Neural Processing Units (NPUs), combining wide dynamic range with high hardware efficiency. However, its behavior under hardware faults and suitability for safety-critical deployments remain underexplored. Here, we present the first in-depth empirical reliability study of BFP-based NPUs. Using RTL-level fault injection on NPUs, our bit- and path-level analysis reveals pronounced heterogeneous vulnerabilities and shows conventional end-to-end check becomes ineffective under nonlinear block scaling. Guided by these insights, we design a fault-tolerant BFP-based NPU microarchitecture that aligns the BFP computational semantics with reliability constraints. The design uses a row/column-wise blocking strategy to decouple the fixed-point mantissa computations from the scalar exponent path, and introduces ultra-lightweight protection mechanisms for each. Experimental results demonstrate our design achieves near-dual modular redundancy reliability with only $3.55\%$ geometric mean performance overhead and less than $2\%$ hardware cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts the first in-depth empirical reliability study of Block Floating-Point (BFP) NPUs via RTL-level fault injection. It identifies heterogeneous vulnerabilities across bit- and path-level faults and shows that conventional end-to-end checks become ineffective under nonlinear block scaling. Guided by these observations, the authors propose a microarchitecture that decouples fixed-point mantissa computations from the scalar exponent path using row/column-wise blocking, augmented by ultra-lightweight protection mechanisms for each path. The central claim is that this design delivers reliability comparable to dual modular redundancy (DMR) while incurring only 3.55% geometric mean performance overhead and less than 2% hardware cost.
Significance. If the fault-injection results prove representative of silicon behavior, the work would be significant for safety-critical edge AI deployments. It supplies concrete empirical guidance on BFP fault modes that has been missing from the literature, and the proposed microarchitecture demonstrates how BFP semantics can be aligned with reliability constraints at very low overhead. The explicit comparison to DMR and the quantitative area/performance numbers provide a clear benchmark for future low-cost fault-tolerant NPUs.
major comments (2)
- [§5] §5 (Fault Injection Methodology): The headline reliability result (near-DMR silent-data-corruption rates at 3.55% perf / <2% area) rests entirely on RTL fault-injection campaigns, yet the manuscript provides no description of the fault models employed (bit-flip, stuck-at, timing, voltage-droop, or process-variation), the injection rates or statistical coverage, the workload selection criteria, or any error-bar / confidence-interval analysis. Without these details it is impossible to judge whether the observed ineffectiveness of end-to-end checks or the effectiveness of the row/column decoupling generalizes beyond the tested BFP configurations, especially for exponent-scaling errors that the paper itself flags as critical.
- [§6] §6 (Comparison to DMR): The claim that the design achieves “near-dual modular redundancy reliability” is presented without a side-by-side fault-injection campaign on an actual DMR implementation of the same NPU. The comparison therefore relies on an implicit assumption that the injected fault population produces error signatures equivalent to those that would appear in a real DMR silicon part; this assumption is load-bearing for the central cost-benefit argument but is not justified in the text.
minor comments (3)
- [Figure 7] Figure 7 (area breakdown): the legend and axis labels are too small to read in the printed version; please enlarge or split into two panels.
- [§4.2] The term “ultra-lightweight protection mechanisms” is used repeatedly without a precise definition or gate-count breakdown in the text; a short table listing the exact logic added for each mechanism would improve clarity.
- [§2] Several citations to prior BFP reliability work are missing from the related-work section (e.g., recent studies on exponent scaling faults in quantized accelerators).
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments highlight important aspects of reproducibility and comparison that we address below. We have revised the manuscript to incorporate additional details and clarifications.
read point-by-point responses
-
Referee: [§5] §5 (Fault Injection Methodology): The headline reliability result (near-DMR silent-data-corruption rates at 3.55% perf / <2% area) rests entirely on RTL fault-injection campaigns, yet the manuscript provides no description of the fault models employed (bit-flip, stuck-at, timing, voltage-droop, or process-variation), the injection rates or statistical coverage, the workload selection criteria, or any error-bar / confidence-interval analysis. Without these details it is impossible to judge whether the observed ineffectiveness of end-to-end checks or the effectiveness of the row/column decoupling generalizes beyond the tested BFP configurations, especially for exponent-scaling errors that the paper itself flags as critical.
Authors: We agree that the original manuscript would benefit from expanded methodological details to support reproducibility and evaluation of generalizability. In the revised version, Section 5 has been substantially extended to describe the fault model (transient single-event bit flips injected at RTL on mantissa and exponent paths), injection methodology (average rate of one fault per 1000 cycles, exhaustive coverage of all major modules with >10 million total injections), workload selection (ResNet-50, MobileNet-v2, and VGG-16 on ImageNet/CIFAR-10 to exercise diverse block sizes and scaling behaviors), and statistical reporting (SDC rates with 95% confidence intervals and error bars from repeated campaigns). These additions confirm that the ineffectiveness of end-to-end checks and the advantages of row/column decoupling are consistent across the evaluated BFP configurations, with particular attention to exponent-path vulnerabilities. revision: yes
-
Referee: [§6] §6 (Comparison to DMR): The claim that the design achieves “near-dual modular redundancy reliability” is presented without a side-by-side fault-injection campaign on an actual DMR implementation of the same NPU. The comparison therefore relies on an implicit assumption that the injected fault population produces error signatures equivalent to those that would appear in a real DMR silicon part; this assumption is load-bearing for the central cost-benefit argument but is not justified in the text.
Authors: We recognize that an empirical side-by-side fault-injection study on a DMR implementation would offer the most direct validation. However, constructing and evaluating such a DMR version would require full hardware duplication plus a protected comparator—the exact overhead our microarchitecture is designed to avoid. Our near-DMR claim rests on the observation that, under the single transient fault model employed, a standard DMR configuration (with protected comparator) would mask all faults in the duplicated paths, yielding near-zero SDC. Our design achieves SDC rates within a small factor of this ideal while incurring only 3.55% performance and <2% area overhead. In the revision we have added an explicit discussion in Section 6 that justifies the comparison under the shared fault model, provides a theoretical reliability bound for DMR, and acknowledges the absence of direct DMR silicon data as a limitation. This strengthens the cost-benefit argument without necessitating an additional full-scale implementation. revision: partial
Circularity Check
No circularity: empirical characterization directly informs design without self-referential reduction
full rationale
The paper conducts RTL-level fault injection to characterize BFP NPU vulnerabilities, extracts qualitative insights about heterogeneous faults and ineffective end-to-end checks under nonlinear scaling, then proposes a row/column decoupling microarchitecture and lightweight protections. These are validated by new measurements of performance overhead and hardware cost. No equations, fitted parameters, or self-citations are shown that define the reliability outcome in terms of the design itself or vice versa. The central claims rest on direct experimental comparison rather than tautological construction or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption RTL-level fault injection accurately models real hardware faults in BFP NPUs
- domain assumption The heterogeneous vulnerabilities and ineffectiveness of end-to-end checks observed in the tested configurations hold for BFP NPUs in general
Reference graph
Works this paper leans on
- [1]
-
[2]
SCISSORS:SystemLevelErrorDe- tectionforEnablingNear-ThresholdOperatingSystolicArrays.IEEETransactions on Computer-Aided Design of Integrated Circuits and Systems(2025)
EnsiehAliagha,MehdiSafarpour,etal .2025. SCISSORS:SystemLevelErrorDe- tectionforEnablingNear-ThresholdOperatingSystolicArrays.IEEETransactions on Computer-Aided Design of Integrated Circuits and Systems(2025)
2025
-
[3]
AMD. 2025. The World’s First Block FP16 NPU Model for SD 3.0 on XDNA
2025
-
[4]
AMD Blog.https://www.amd.com/en/blogs/2025/worlds-first-bf16-sd3- medium-npu-model.html
2025
-
[5]
Ali Azizimazreah and Li Chen. 2018. Tolerating soft errors in deep learning accelerators with ECC. InNAS
2018
-
[6]
Computerandredundancy solution for the full self-driving computer
PeteBannonandGaneshothersVenkataramanan.2019. Computerandredundancy solution for the full self-driving computer. InIEEE HCS. IEEE Computer Society, 1–22
2019
-
[7]
Timoteo García Bertoa, Giulio Gambardella, et al. 2022. Fault-tolerant neural network accelerators with selective TMR.IEEE Design & Test40, 2 (2022), 67–74
2022
-
[8]
Cristiana Bolchini, Luca Cassano, et al. 2023. Resilience of Deep Learning applications: a systematic survey of analysis and hardening techniques
2023
- [9]
-
[10]
Pierluigi Civera, Luca Macchiarulo, et al. 2002. An FPGA-based approach for speeding-up fault injection campaigns on safety-critical circuits.Journal of Electronic Testing18, 3 (2002), 261–271
2002
-
[11]
Bita Darvish Rouhani, Daniel Lo, et al. 2020. Pushing the limits of narrow precision inferencing at cloud scale with microsoft floating point.NeurIPS33 (2020), 10271–10281
2020
-
[12]
Mario Drumond, Tao Lin, et al. 2018. Training dnns with hybrid block floating point.NeurIPS31 (2018)
2018
-
[13]
Thellama3herdofmodels.arXiv e-prints(2024), arXiv–2407
AbhimanyuDubey,AbhinavJauhri,etal .2024. Thellama3herdofmodels.arXiv e-prints(2024), arXiv–2407
2024
-
[14]
2013.Quantifying the impact of single bit flips on floating point arithmetic
James J Elliott, Frank Mueller, et al. 2013.Quantifying the impact of single bit flips on floating point arithmetic. Technical Report. ORNL, Oak Ridge, TN
2013
-
[15]
Static block floating-point quantization for convolutional neural networks on FPGA
Hongxiang Fan, Gang Wang, et al.2019. Static block floating-point quantization for convolutional neural networks on FPGA. InICFPT. IEEE, 28–35
2019
- [16]
-
[17]
Daocheng Fu, Xin Li, et al. 2024. Drive like a human: Rethinking autonomous driving with large language models. InIEEE/CVF WACVW. IEEE, 910–919
2024
-
[18]
Johannes Geier. 2020. Fast RTL-based Fault Injection Framework for RISC-V Cores. (2020)
2020
-
[19]
Gemmini: Enabling systematic deep-learning architecture evaluation via full-stack integration
Hasan Genc, Seah Kim, et al.2021. Gemmini: Enabling systematic deep-learning architecture evaluation via full-stack integration. InACM/IEEE DAC. IEEE, 769–774
2021
-
[20]
TheDarkSideofComputing:SilentDataCorruptions
DimitrisGizopoulos.2025. TheDarkSideofComputing:SilentDataCorruptions. Computer58, 6 (2025), 101–106
2025
-
[21]
Automatic saboteur placement for emulation-based multi-bit fault injection
Johannes Grinschgl, Armin Krieg, et al.2011. Automatic saboteur placement for emulation-based multi-bit fault injection. InReCoSoC. IEEE, 1–8
2011
-
[22]
Neuralnetworkreliabilityanalysisbasedonfaultinjection
BaixinGuoetal .2023. Neuralnetworkreliabilityanalysisbasedonfaultinjection. InCNML. 366–370
2023
-
[23]
Xiaomeng Han, Yuan Cheng, et al. 2025. Bbal: A bidirectional block floating point-based quantisation accelerator for large language models. InACM/IEEE DAC. IEEE, 1–7
2025
- [24]
- [25]
-
[26]
Jiajun He et al. 2025. Fine-Grained Fault Sensitivity Analysis of Vision Trans- formers Under Soft Errors.Electronics14, 12 (2025), 2418
2025
-
[27]
Kaiming He, Xiangyu Zhang, et al. 2016. Deep residual learning for image recognition. InIEEE CVPR. 770–778
2016
-
[28]
Densely connected convolutional networks
Gao Huang, Zhuang Liu, et al.2017. Densely connected convolutional networks. InIEEE CVPR. 4700–4708
2017
-
[29]
Younis Ibrahim et al. 2020. Soft errors in DNN accelerators: A comprehensive review.Microelectronics Reliability115 (2020), 113969
2020
-
[30]
InICCIT-1441
YounisIbrahim,HaibinWang,etal .2020.Analyzingthereliabilityofconvolutional neural networks on gpus: Googlenet as a case study. InICCIT-1441. IEEE, 1–6
2020
-
[31]
Younis Ibrahim, Haibin Wang, et al. 2020. Soft error resilience of deep residual networks for object recognition.IEEE Access8 (2020), 19490–19503
2020
-
[32]
Texas Instruments. 2023. Functional Safety Manual for TMS320F280013x Series. Texas Instruments, Application Report.https://www.ti.com/lit/ug/spruhl7/ spruhl7.pdf
2023
-
[33]
ISO26262 ISO. 2018. 26262: Road vehicles-Functional safety. (2018)
2018
-
[34]
Benoit Jacob, Skirmantas Kligys, et al. 2018. Quantization and training of neural networks for efficient integer-arithmetic-only inference. InIEEE CVPR. 2704–2713
2018
-
[35]
In-datacenter performance analysis of a tensor processing unit
Norman P Jouppi, Cliff Young, et al.2017. In-datacenter performance analysis of a tensor processing unit. InISCA. 1–12
2017
-
[36]
Dhiraj Kalamkar, Dheevatsa Mudigere, et al. 2019. A study of BFLOAT16 for deep learning training.arXiv preprint arXiv:1905.12322(2019)
work page Pith review arXiv 2019
-
[37]
Bert:Pre-trainingofdeepbidirectionaltransform- ers for language understanding
JacobDevlinKentonetal .2019. Bert:Pre-trainingofdeepbidirectionaltransform- ers for language understanding. InnaacL-HLT, Vol. 1. Minneapolis, Minnesota, 2. Conference’17, July 2017, Washington, DC, USA Jie Zhang et al
2019
-
[38]
Flexpoint: An adaptive numerical format for efficient training of deep neural networks.NeurIPS30 (2017)
Urs Köster, Tristan Webb, et al.2017. Flexpoint: An adaptive numerical format for efficient training of deep neural networks.NeurIPS30 (2017)
2017
-
[39]
Alex Krizhevsky, Ilya Sutskever, et al. 2012. Imagenet classification with deep convolutional neural networks.NeurIPS25 (2012)
2012
-
[40]
Seo-Seok Lee and Joon-Sung Yang. 2022. Value-aware parity insertion ECC for fault-tolerant deep neural network. InDATE. IEEE, 724–729
2022
-
[41]
Guanpeng Li et al. 2025. Understanding Error Propagation in Deep-Learning Neural Networks Accelerators and Applications.IEEE Des. Test(2025)
2025
-
[42]
Stephen Merity, Caiming Xiong, et al. 2016. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843(2016)
work page internal anchor Pith review arXiv 2016
-
[43]
Paulius Micikevicius, Sharan Narang, et al.2017. Mixed precision training.arXiv preprint arXiv:1710.03740(2017)
work page internal anchor Pith review arXiv 2017
-
[44]
Chandra Sekhar Mummidi, Sandeep Bal, et al. 2022. A highly-efficient error detection technique for general matrix multiplication using tiled processing on SIMD architecture. InIEEE ICCD. IEEE, 529–536
2022
-
[45]
NVIDIA. 2025. Introducing NVFP4 (and MXFP) for Efficient Low-Precision Inference on Blackwell. Developer Blog.https://developer.nvidia.com/blog/ introducing-nvfp4-for-efficient-and-accurate-low-precision-inference/
2025
-
[46]
Jhon Ordoñez and Chengmo Yang. 2024. Enhancing DNN Accelerator Integrity via Selective and Permuted Recomputation. InIEEE/ACM ICCAD. 1–8
2024
-
[47]
Taewon Park, Saeid Gorgin, et al. 2025. PoP-ECC: Robust and Flexible Error Correction against Multi-Bit Upsets in DNN Accelerators. InACM/IEEE DAC. IEEE, 1–7
2025
-
[48]
Liqi Ping, Jingweijia Tan, et al. 2020. SERN: Modeling and analyzing the soft error reliability of convolutional neural networks. InGLSVLSI. 445–450
2020
-
[49]
Antonio Porsia, Giacomo Perlo, et al. 2025. On the Resilience of INT8 Quantized Neural Networks on Low-Power RISC-V Devices. InIEEE/IFIP DSN-W. IEEE, 119–122
2025
-
[50]
Harsh Rangwani, Sho Takemori, et al. 2022. Cost-sensitive self-training for optimizing non-decomposable metrics.NeurIPS35 (2022), 26994–27007
2022
-
[51]
Brandon Reagen, Udit Gupta, et al. 2018. Ares: A framework for quantifying the resilience of deep neural networks. InACM/IEEE DAC. 1–6
2018
-
[52]
RISC-V Software Source. 2024. riscv-isa-sim: RISC-V ISA Simulator (Spike). https://github.com/riscv-software-src/riscv-isa-sim
2024
-
[53]
Mehdi Safarpour, Reza Inanlou, et al. 2021. Algorithm level error detection in low voltage systolic array.IEEE TCAS-II69, 2 (2021), 569–573
2021
-
[54]
Mark Sandler, Andrew Howard, et al. 2018. Mobilenetv2: Inverted residuals and linear bottlenecks. InIEEE CVPR. 4510–4520
2018
-
[55]
Ahmad T Sheikh and Aiman H El-Maleh. 2018. Double modular redundancy (dmr) based fault tolerance technique for combinational circuits.JCSC27, 06 (2018), 1850097
2018
-
[56]
Eugen Solowjow, Ines Ugalde, et al. 2020. Industrial robot grasping with deep learning using a programmable logic controller (plc). InIEEE CASE. IEEE, 97–103
2020
-
[57]
Peng Su, Yuhang Li, et al. 2025. Applying Reinforcement Learning to Protect Deep Neural Networks from Soft Errors.Sensors25, 13 (2025), 4196
2025
-
[58]
Christian Szegedy, Vincent Vanhoucke, et al. 2016. Rethinking the inception architecture for computer vision. InIEEE CVPR. 2818–2826
2016
-
[59]
Mingxing Tan and Quoc Le. 2019. Efficientnet: Rethinking model scaling for convolutional neural networks. InICML. PMLR, 6105–6114
2019
-
[60]
AModelofanIntelligentAutomation System for Monitoring of Sensor Signals with a Neural Network Implementation
IrinaTopalovaandPavlinkaRadoyska.2023. AModelofanIntelligentAutomation System for Monitoring of Sensor Signals with a Neural Network Implementation. Annals of DAAAM & Proceedings34 (2023)
2023
-
[61]
Jinghe Wei, Younis Ibrahim, et al. 2020. Analyzing the impact of soft errors in VGG networks implemented on GPUs.Microelectronics Reliability110 (2020), 113648
2020
- [62]
-
[63]
Xianli Xie, Jiansheng Chen, et al. 2025. Multidimensional Fault Injection and Simulation Analysis for Random Number Generators.Electronics14, 18 (2025), 3702
2025
-
[64]
Leon Yao and John Miller. 2015. Tiny imagenet classification with convolutional neural networks.CS 231N2, 5 (2015), 8
2015
-
[65]
Be like water: Adaptive floating point for machine learning
Thomas Yeh, Max Sterner, et al.2022. Be like water: Adaptive floating point for machine learning. InICML. PMLR, 25490–25500
2022
-
[66]
Susan Zhang, Stephen Roller, et al. 2022. OPT: Open Pre-trained Transformer Language Models. arXiv:2205.01068 [cs.CL]
work page internal anchor Pith review arXiv 2022
-
[67]
Sai Qian Zhang, Bradley McDanel, et al. 2022. Fast: Dnn training under variable precision block floating point with stochastic rounding. InIEEE HPCA. IEEE, 846–860
2022
-
[68]
FPGA-basedBlockMinifloatTrainingAccel- eratorforaTimeSeriesPredictionNetwork.ACMTransactionsonReconfigurable Technology and Systems18, 2 (2025), 1–23
WenjieZhou,HaoyanQi,etal .2025. FPGA-basedBlockMinifloatTrainingAccel- eratorforaTimeSeriesPredictionNetwork.ACMTransactionsonReconfigurable Technology and Systems18, 2 (2025), 1–23
2025
-
[69]
Lancheng Zou, Wenqian Zhao, et al. 2024. Bie: Bi-exponent block floating-point for large language models quantization. InICML
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.