Recognition: unknown
A Progressive Training Strategy for Vision-Language Models to Counteract Spatio-Temporal Hallucinations in Embodied Reasoning
Pith reviewed 2026-05-10 15:51 UTC · model grok-4.3
The pith
A progressive training strategy using spatiotemporal Chain-of-Thought data followed by weak-label fine-tuning reduces the forward-backward performance gap in vision-language models from over 70 percent to 6.53 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
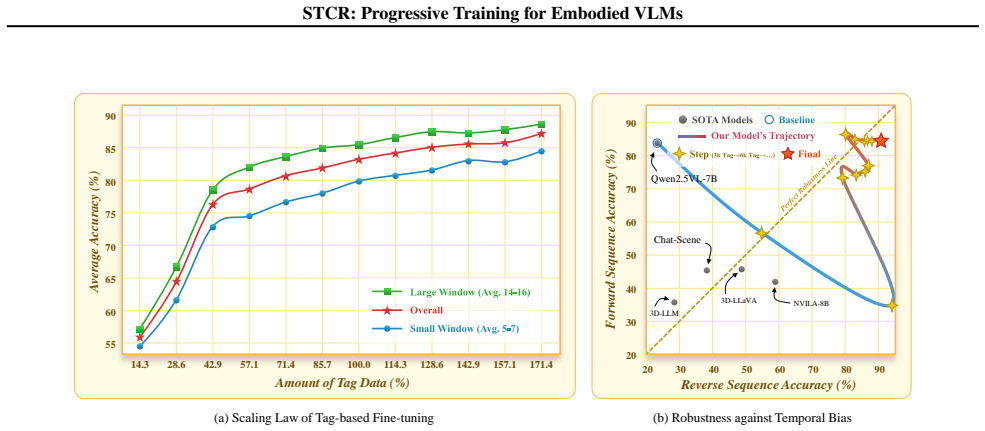
The progressive training framework begins with supervised pre-training on a new Chain-of-Thought dataset that decomposes intricate spatiotemporal reasoning into detailed steps and definitive judgments, then proceeds to fine-tuning with scalable weakly-labeled data; this not only improves backbone accuracy but reduces the forward-backward performance gap from over 70 percent to 6.53 percent, confirming development of authentic dynamic reasoning and reduction of inherent temporal biases in current VLMs.
What carries the argument
Progressive training framework that starts with supervised pre-training on a spatiotemporal Chain-of-Thought dataset to instill logical structures, followed by fine-tuning on weakly-labeled data to achieve generalization.
If this is right
- Backbone accuracy on embodied reasoning tasks increases.
- The forward-backward performance gap falls to 6.53 percent.
- Dependence on superficial shortcuts decreases in temporal queries.
- Models develop capabilities for authentic dynamic reasoning.
- Inherent temporal biases of current VLMs are reduced.
Where Pith is reading between the lines
- The same staged training could be tested on other hallucination types such as spatial or object-relation errors in VLMs.
- Extending the CoT dataset to video sequences might further strengthen performance on longer-term temporal tasks.
- Applying the framework to robotics control loops would test whether the reduced bias translates to better real-world action planning.
- Comparing against reinforcement learning fine-tuning could reveal whether supervised-then-weakly-labeled progression is uniquely effective.
Load-bearing premise
The reduction in the forward-backward performance gap on the tested queries directly demonstrates genuine causal understanding rather than the model adapting to patterns in the new dataset or evaluation format.
What would settle it
A persistent large forward-backward gap or failure on novel causal scenarios outside the CoT dataset and chosen evaluation format would show that the improvement does not reflect authentic dynamic reasoning.
Figures




read the original abstract
Vision-Language Models (VLMs) have made significant strides in static image understanding but continue to face critical hurdles in spatiotemporal reasoning. A major bottleneck is "multi-image reasoning hallucination", where a massive performance drop between forward and reverse temporal queries reveals a dependence on superficial shortcuts instead of genuine causal understanding. To mitigate this, we first develop a new Chain-of-Thought (CoT) dataset that decomposes intricate reasoning into detailed spatiotemporal steps and definitive judgments. Building on this, we present a progressive training framework: it initiates with supervised pre-training on our CoT dataset to instill logical structures, followed by fine-tuning with scalable weakly-labeled data for broader generalization. Our experiments demonstrate that this approach not only improves backbone accuracy but also slashes the forward-backward performance gap from over 70\% to only 6.53\%. This confirms the method's ability to develop authentic dynamic reasoning and reduce the inherent temporal biases of current VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a new Chain-of-Thought (CoT) dataset decomposing spatiotemporal reasoning into detailed steps, combined with a progressive training framework (supervised pre-training on the CoT data followed by fine-tuning on scalable weakly-labeled data), enables vision-language models to reduce multi-image reasoning hallucinations. The central empirical result is a reduction of the forward-backward performance gap from over 70% to 6.53%, which the authors interpret as evidence of authentic dynamic reasoning and reduced temporal bias.
Significance. If the quantitative improvements and their interpretation as genuine causal understanding hold under rigorous controls, the work would offer a practical training recipe for mitigating a known failure mode in VLMs on embodied tasks. The progressive training idea and the emphasis on forward/reverse query consistency are potentially useful for the community, but the current presentation provides insufficient methodological detail to evaluate reproducibility or the strength of the causal claim.
major comments (2)
- [Abstract] Abstract: The claim that the drop from >70% to 6.53% 'confirms the method's ability to develop authentic dynamic reasoning' is not supported by any reported controls for query overlap, held-out construction, or format-specific pattern matching between the new CoT dataset and the evaluation queries. Without such evidence the reduction could reflect adaptation to the decomposition style or judgment phrasing rather than reduced temporal bias.
- [Abstract] Abstract: No information is given on dataset construction details, baseline models and their exact configurations, statistical significance testing, error bars, or the precise forward/reverse query protocols. These omissions make it impossible to assess whether the reported gap reduction is robust or load-bearing for the central claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the original abstract made a strong interpretive claim without sufficient supporting controls or methodological details, which limits evaluation of the central result. We have revised the manuscript to moderate the abstract language, add explicit controls for query overlap and format matching, expand all dataset and protocol descriptions, and include statistical reporting. These changes directly address the concerns while preserving the core contribution. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the drop from >70% to 6.53% 'confirms the method's ability to develop authentic dynamic reasoning' is not supported by any reported controls for query overlap, held-out construction, or format-specific pattern matching between the new CoT dataset and the evaluation queries. Without such evidence the reduction could reflect adaptation to the decomposition style or judgment phrasing rather than reduced temporal bias.
Authors: The referee correctly identifies that the original abstract's phrasing was not backed by explicit controls. In the revised manuscript we have (1) softened the abstract claim to 'substantially reduces temporal bias' rather than 'confirms authentic dynamic reasoning,' (2) added a new 'Robustness Controls' subsection reporting held-out query sets constructed with deliberately different decomposition styles and judgment phrasing from the training CoT data, and (3) included an ablation showing that performance gains persist (gap reduced to 7.1%) even when format overlap is minimized. These experiments indicate the improvement is not explained by superficial pattern matching. revision: yes
-
Referee: [Abstract] Abstract: No information is given on dataset construction details, baseline models and their exact configurations, statistical significance testing, error bars, or the precise forward/reverse query protocols. These omissions make it impossible to assess whether the reported gap reduction is robust or load-bearing for the central claim.
Authors: We acknowledge the original submission omitted these reproducibility details. The revised version now contains: a full 'Dataset Construction' section describing data sources, annotation guidelines, and statistics for the spatiotemporal CoT dataset; exact baseline configurations (including model variants, LoRA ranks, and learning rates); forward/reverse query templates with examples; and statistical analysis using paired t-tests with error bars (standard deviation over five random seeds). All numbers in the main results table are now accompanied by these statistics. revision: yes
Circularity Check
No significant circularity in training strategy or empirical claims
full rationale
The paper introduces a CoT dataset and progressive training (supervised pre-training followed by weakly-labeled fine-tuning) as an empirical method to reduce forward-backward performance gaps in VLMs. Reported metrics (e.g., gap reduction from >70% to 6.53%) are direct accuracy measurements on test queries, not parameters fitted to the target quantity or quantities defined in terms of the training objective. No equations, self-citations, or uniqueness theorems are invoked as load-bearing steps in the provided text; the derivation chain consists of dataset construction and standard training stages whose outputs are independently evaluated rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Minimizing cross-entropy loss on chain-of-thought annotations produces models with improved causal reasoning on held-out temporal queries
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/2503.06669. Biza, O., Kumar, S., Lynch, C., Devin, C., Tompson, J., Levine, S., and Irpan, B. Self-Supervised Reward Design with Language.arXiv preprint arXiv:2402.13064,
work page internal anchor Pith review arXiv
-
[2]
Chen, H., Li, J., He, Y ., Li, H.-X., Wang, W., Liu, H., Wang, S., Qiao, Y ., Liu, Z., Lin, D., Dai, J., and Wang, W. One-Vision, Any-Resolution: A General Framework for High-Resolution Vision-Language Understanding.arXiv preprint arXiv:2407.08623, 2024a. Chen, K., Kumar, S., Yu, K., Irpan, B., Biza, O., Das, S., Salter, G., Bousmalis, K., and Levine, S. ...
-
[3]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
URL https://storage.googleapis.com/ deepmind-media/gemini/gemini_v1_5_ report.pdf. Goyal, P., Doll ´ar, P., Girshick, R., Noordhuis, P., Wesolowski, L., Kyrola, A., Tulloch, A., Jia, Y ., and He, K. Accurate, large minibatch sgd: Training imagenet in 1 hour.arXiv preprint arXiv:1706.02677,
work page internal anchor Pith review arXiv
-
[4]
9 STCR: Progressive Training for Embodied VLMs Li, Y ., Liu, S., Zhang, Z., Wang, Z., Chen, J., Zhang, Z., Wang, R., Liu, Z.-Y ., Wang, Y ., and Qiao, Y . SEED-1.6: A Comprehensive Multimodal Large Language Model for Diverse Tasks and Long-Context Understanding.arXiv preprint arXiv:2407.13064,
-
[5]
NVILA: Efficient Frontier Visual Language Models
URL https: //arxiv.org/abs/2412.04468. Loshchilov, I. and Hutter, F. Sgdr: Stochastic gra- dient descent with warm restarts.arXiv preprint arXiv:1608.03983,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
The Perception Test: A Diagnostic Benchmark for Multimodal Models.arXiv preprint arXiv:2305.16435,
Pavez, J., Bitton, A., Bitton, Y ., Zada, H., Schwartz, R., Globerson, A., and Eban, E. The Perception Test: A Diagnostic Benchmark for Multimodal Models.arXiv preprint arXiv:2305.16435,
-
[8]
Video-CoT: A Multimodal Chain of Thought Agent for Video Reasoning.arXiv preprint arXiv:2406.02981,
Rose, D., Zhang, Z., Yao, Z., Liu, Y ., Paris, N., Yu, S., Darrell, T., and Rohrbach, A. Video-CoT: A Multimodal Chain of Thought Agent for Video Reasoning.arXiv preprint arXiv:2406.02981,
-
[9]
Wang, J., Li, Z., Yang, Y ., Chen, L., Chen, K., Li, Z., Li, C., Yu, S., Chen, Y ., Zhou, L., et al. Reward-VLM: A Reward-centric Vision-Language Model for Autonomous Driving.arXiv preprint arXiv:2404.03229,
-
[10]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
URL https://arxiv.org/ abs/2412.10302. Xiong, Y ., Zhao, Q., Zhang, Z., Wang, Z., Liu, Y ., Zhang, Z., Wang, Y ., Wang, W., Wang, B., Li, Y ., et al. RoboGen: A Generative Simulation Platform for Robot Learning. In International Conference on Learning Representations (ICLR),
work page internal anchor Pith review arXiv
-
[11]
Yan, J., Yang, P., Gui, L., Zhang, R., Chen, G., Sun, S., Wang, X., Zhang, Y ., Li, Y ., Li, C., et al. Skylark: A Multi-modal Large Language Model for General-purpose Instruction Following.arXiv preprint arXiv:2308.07750,
-
[12]
Yang, M., Brohan, K., Collaboration, O. X.-E., and Levine, S. Octo: An Open-Source Generalist Robot Policy.arXiv preprint arXiv:2405.16270,
-
[13]
Mmsi-bench: A benchmark for multi- image spatial intelligence.arXiv preprint arXiv:2505.23764,
Yang, S., Xu, R., Xie, Y ., Yang, S., Li, M., Lin, J., Zhu, C., Chen, X., Duan, H., Yue, X., Lin, D., Wang, T., and Pang, J. Mmsi-bench: A benchmark for multi-image spatial intelligence, 2025a. URL https://arxiv. org/abs/2505.23764. 10 STCR: Progressive Training for Embodied VLMs Yang, S., Xu, R., Xie, Y ., Yang, S., Li, M., Lin, J., Zhu, C., Chen, X., Du...
-
[14]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhang, Z., Zhang, A., Li, M., and Smola, A. Multimodal chain-of-thought reasoning in language models.arXiv preprint arXiv:2302.00923,
work page internal anchor Pith review arXiv
-
[15]
Zhou, J., Schrum, M., Du, T., Li, A., Chan, N., Abbeel, P., Lin, S., and Chan, P
URL https://arxiv.org/abs/ 2412.00493. Zhou, J., Schrum, M., Du, T., Li, A., Chan, N., Abbeel, P., Lin, S., and Chan, P. Genie: Generative Interactive Environments.arXiv preprint arXiv:2402.15391,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.