Recognition: unknown
FreeScale: Scaling 3D Scenes via Certainty-Aware Free-View Generation
Pith reviewed 2026-05-10 16:36 UTC · model grok-4.3
The pith
FreeScale uses certainty-aware sampling on reconstructed scenes to generate scalable, high-quality novel views from limited real-world captures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FreeScale transforms limited real-world image sequences into a scalable source of high-quality training data by using an imperfect reconstructed scene as a rich geometric proxy and applying a certainty-aware free-view sampling strategy that identifies novel viewpoints both semantically meaningful and minimally affected by reconstruction errors.
What carries the argument
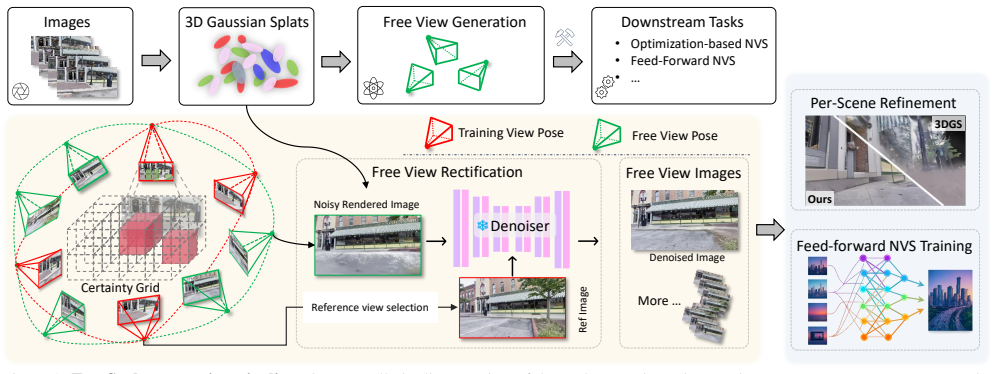
The certainty-aware free-view sampling strategy, which selects novel viewpoints from the reconstructed scene based on reconstruction certainty to avoid artifact amplification.
Load-bearing premise
An imperfect reconstructed scene serves as a rich geometric proxy, and the certainty-aware sampling can reliably identify novel viewpoints that are semantically meaningful and minimally affected by errors without introducing selection bias or new artifacts.
What would settle it
Training feedforward NVS models on FreeScale-generated data produces no PSNR gain or even lower performance than training on the original sparse real captures alone when evaluated on the same out-of-distribution benchmarks.
Figures














read the original abstract
The development of generalizable Novel View Synthesis (NVS) models is critically limited by the scarcity of large-scale training data featuring diverse and precise camera trajectories. While real-world captures are photorealistic, they are typically sparse and discrete. Conversely, synthetic data scales but suffers from a domain gap and often lacks realistic semantics. We introduce FreeScale, a novel framework that leverages the power of scene reconstruction to transform limited real-world image sequences into a scalable source of high-quality training data. Our key insight is that an imperfect reconstructed scene serves as a rich geometric proxy, but naively sampling from it amplifies artifacts. To this end, we propose a certainty-aware free-view sampling strategy identifying novel viewpoints that are both semantically meaningful and minimally affected by reconstruction errors. We demonstrate FreeScale's effectiveness by scaling up the training of feedforward NVS models, achieving a notable gain of 2.7 dB in PSNR on challenging out-of-distribution benchmarks. Furthermore, we show that the generated data can actively enhance per-scene 3D Gaussian Splatting optimization, leading to consistent improvements across multiple datasets. Our work provides a practical and powerful data generation engine to overcome a fundamental bottleneck in 3D vision. Project page: https://mvp-ai-lab.github.io/FreeScale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FreeScale, a framework that uses imperfect 3D scene reconstructions as geometric proxies to generate scalable high-quality training data for novel view synthesis (NVS) via a certainty-aware free-view sampling strategy that selects semantically meaningful viewpoints minimally impacted by reconstruction errors. It reports a 2.7 dB PSNR gain when scaling feedforward NVS model training on out-of-distribution benchmarks and consistent improvements when using the generated data to enhance per-scene 3D Gaussian Splatting optimization across multiple datasets.
Significance. If the empirical results hold under detailed scrutiny, the work offers a practical solution to the data scarcity bottleneck in generalizable NVS by converting limited real-world captures into large-scale, artifact-reduced training sets without synthetic domain gaps. The dual demonstration on both feedforward models and per-scene optimization adds versatility, and the certainty-aware mechanism directly targets a common failure mode in reconstruction-based view synthesis.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The reported 2.7 dB PSNR improvement is presented as a key result, yet the abstract and experimental summary provide no explicit baselines, dataset splits, number of scenes, or ablation controls for the certainty threshold; without these the magnitude and attribution of the gain cannot be verified as load-bearing for the central claim.
- [§3.2] §3.2 (Certainty-aware sampling): The strategy is described as identifying novel viewpoints that are both semantically meaningful and minimally affected by reconstruction errors, but no equations, threshold derivation, or quantitative correlation analysis between certainty scores and actual reconstruction error are referenced; this directly bears on the weakest assumption that the proxy avoids introducing selection bias or new artifacts.
minor comments (2)
- [Abstract] Abstract: Consider adding one sentence on the scale of generated views or the specific NVS architectures used for the reported gains to improve immediate context.
- [§5] §5 (Discussion): The claim of 'consistent improvements across multiple datasets' for 3DGS would benefit from a table row showing per-dataset deltas with standard deviations to quantify variability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. We address each major comment below with specific plans for clarification and added rigor in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The reported 2.7 dB PSNR improvement is presented as a key result, yet the abstract and experimental summary provide no explicit baselines, dataset splits, number of scenes, or ablation controls for the certainty threshold; without these the magnitude and attribution of the gain cannot be verified as load-bearing for the central claim.
Authors: We agree that explicit details are needed for full verifiability of the 2.7 dB gain. In the revised version, the abstract will be updated to reference the primary baselines (e.g., standard feedforward NVS models) and out-of-distribution benchmark characteristics. Section 4 will be expanded with a summary table listing dataset splits, the exact number of scenes, and a dedicated ablation on the certainty threshold, including its effect on PSNR to directly attribute the reported improvement. revision: yes
-
Referee: [§3.2] §3.2 (Certainty-aware sampling): The strategy is described as identifying novel viewpoints that are both semantically meaningful and minimally affected by reconstruction errors, but no equations, threshold derivation, or quantitative correlation analysis between certainty scores and actual reconstruction error are referenced; this directly bears on the weakest assumption that the proxy avoids introducing selection bias or new artifacts.
Authors: We acknowledge the value of formalization. The revised §3.2 will include explicit equations defining the certainty-aware sampling objective, the selection criteria for semantic meaningfulness, and the derivation of the certainty threshold. Additionally, we will insert a quantitative analysis (new plot or table) correlating certainty scores with measured reconstruction errors across validation scenes to substantiate that the proxy minimizes artifacts and selection bias. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical data-generation framework for novel view synthesis training, relying on scene reconstruction followed by certainty-aware view sampling. No equations, derivations, fitted parameters, or first-principles predictions are presented that reduce reported gains (e.g., the 2.7 dB PSNR improvement) to quantities defined by construction within the paper itself. Results are framed as outcomes on external benchmarks and per-scene optimizations, with no self-definitional loops, fitted-input predictions, or load-bearing self-citations that collapse the central claim. The derivation chain is therefore self-contained as a practical method plus empirical validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mip-nerf 360: Unbounded anti-aliased neural radiance fields
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5470–5479, 2022. 6
2022
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jam- pani, and Robin Rombach. Stable video diffusion: Scal- ing latent video diffusion models to large datasets.CoRR, abs/2311.15127, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[3]
Pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction
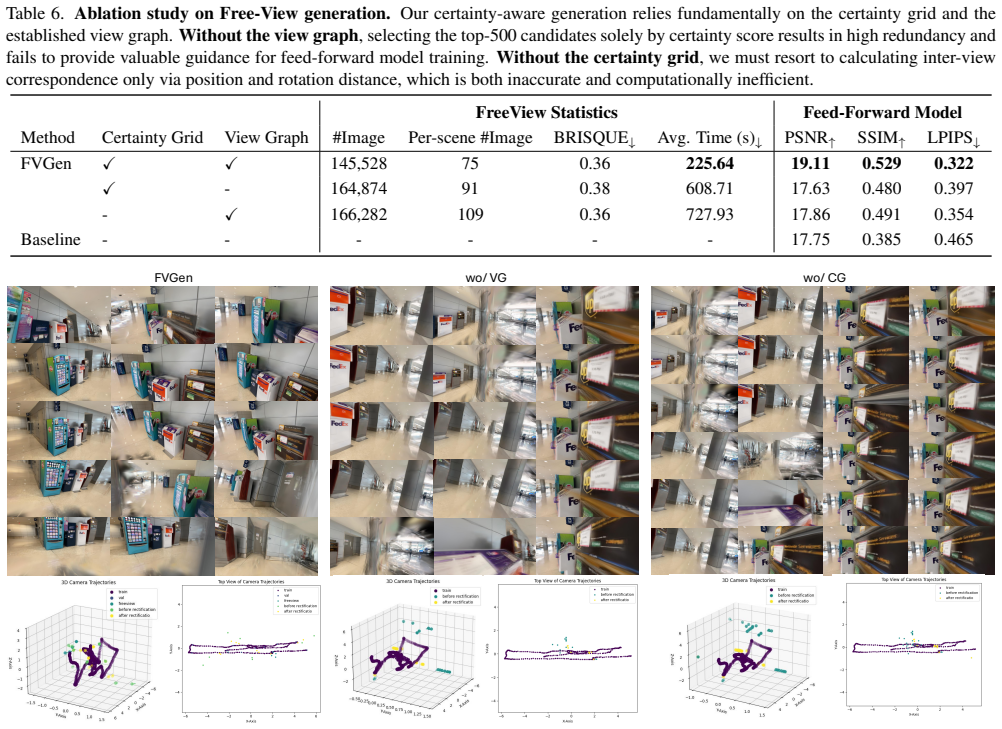
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. Pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19457–19467, 2024. 2
2024
-
[4]
DBARF: deep bundle-adjusting generalizable neural radiance fields
Yu Chen and Gim Hee Lee. DBARF: deep bundle-adjusting generalizable neural radiance fields. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 24– 34, 2023. 2
2023
-
[5]
DOGS: distributed-oriented gaussian splatting for large-scale 3d reconstruction via gaus- sian consensus
Yu Chen and Gim Hee Lee. DOGS: distributed-oriented gaussian splatting for large-scale 3d reconstruction via gaus- sian consensus. InAnnual Conference on Neural Information Processing Systems 2024, 2024. 2
2024
-
[6]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. In18th European Conference, pages 370–386, 2024. 2
2024
-
[7]
Mvs- plat360: Feed-forward 360 scene synthesis from sparse views.Advances in Neural Information Processing Systems, 37:107064–107086, 2024
Yuedong Chen, Chuanxia Zheng, Haofei Xu, Bohan Zhuang, Andrea Vedaldi, Tat-Jen Cham, and Jianfei Cai. Mvs- plat360: Feed-forward 360 scene synthesis from sparse views.Advances in Neural Information Processing Systems, 37:107064–107086, 2024. 1, 2
2024
-
[8]
Ziwen Chen, Hao Tan, Kai Zhang, Sai Bi, Fujun Luan, Yi- cong Hong, Fuxin Li, and Zexiang Xu. Long-lrm: Long- sequence large reconstruction model for wide-coverage gaussian splats.CoRR, abs/2410.12781, 2024. 2
-
[9]
Depth-supervised nerf: Fewer views and faster train- ing for free
Kangle Deng, Andrew Liu, Jun-Yan Zhu, and Deva Ra- manan. Depth-supervised nerf: Fewer views and faster train- ing for free. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12872–12881, 2022. 2
2022
-
[10]
Bayes’ rays: Uncertainty quantifica- tion for neural radiance fields
Lily Goli, Cody Reading, Silvia Sell ´an, Alec Jacobson, and Andrea Tagliasacchi. Bayes’ rays: Uncertainty quantifica- tion for neural radiance fields. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20061– 20070, 2024. 3
2024
-
[11]
Routledge, 2013
Roland Hess.Blender foundations: The essential guide to learning blender 2.5. Routledge, 2013. 2
2013
-
[12]
Rayzer: A self-supervised large view synthesis model
Hanwen Jiang, Hao Tan, Peng Wang, Haian Jin, Yue Zhao, Sai Bi, Kai Zhang, Fujun Luan, Kalyan Sunkavalli, Qixing Huang, et al. Rayzer: A self-supervised large view synthesis model. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 4918–4929, 2025. 1, 2, 5
2025
-
[13]
Megasynth: Scaling up 3d scene reconstruction with synthesized data
Hanwen Jiang, Zexiang Xu, Desai Xie, Ziwen Chen, Haian Jin, Fujun Luan, Zhixin Shu, Kai Zhang, Sai Bi, Xin Sun, et al. Megasynth: Scaling up 3d scene reconstruction with synthesized data. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16441–16452, 2025. 2, 3
2025
-
[14]
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, Dahua Lin, and Bo Dai. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.CoRR, abs/2505.23716, 2025. 2
-
[15]
Wen Jiang, Boshu Lei, and Kostas Daniilidis. Fisherrf: Ac- tive view selection and uncertainty quantification for radi- ance fields using fisher information.CoRR, abs/2311.17874,
-
[16]
Haian Jin, Hanwen Jiang, Hao Tan, Kai Zhang, Sai Bi, Tianyuan Zhang, Fujun Luan, Noah Snavely, and Zexiang Xu. LVSM: A large view synthesis model with minimal 3d inductive bias.arXiv preprint arXiv:2410.17242, 2024. 1, 2, 5, 6
-
[17]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[18]
3d gaussian splat- ting as markov chain monte carlo
Shakiba Kheradmand, Daniel Rebain, Gopal Sharma, Wei- wei Sun, Yang-Che Tseng, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, and Kwang Moo Yi. 3d gaussian splat- ting as markov chain monte carlo. InAdvances in Neural Information Processing Systems, 2024. 1
2024
-
[19]
Tanks and temples: benchmarking large-scale scene reconstruction.ACM Trans
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: benchmarking large-scale scene reconstruction.ACM Trans. Graph., 36(4):78:1–78:13,
-
[20]
Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Transactions on Graphics (ToG), 36 (4):1–13, 2017
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Transactions on Graphics (ToG), 36 (4):1–13, 2017. 6
2017
-
[21]
Wildgaussians: 3d gaussian splatting in the wild
Jonas Kulhanek, Songyou Peng, Zuzana Kukelova, Marc Pollefeys, and Torsten Sattler. Wildgaussians: 3d gaussian splatting in the wild. InAdvances in Neural Information Pro- cessing Systems, 2024. 1
2024
-
[22]
Dngaussian: Optimizing sparse-view 3d gaussian radiance fields with global-local depth normaliza- tion
Jiahe Li, Jiawei Zhang, Xiao Bai, Jin Zheng, Xin Ning, Jun Zhou, and Lin Gu. Dngaussian: Optimizing sparse-view 3d gaussian radiance fields with global-local depth normaliza- tion. InIEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 20775–20785, 2024. 2
2024
-
[23]
Geogaussian: Geometry-aware gaussian splatting for scene rendering
Yanyan Li, Chenyu Lyu, Yan Di, Guangyao Zhai, Gim Hee Lee, and Federico Tombari. Geogaussian: Geometry-aware gaussian splatting for scene rendering. InComputer Vision - ECCV 2024 - 18th European Conference, pages 441–457,
2024
-
[24]
Vastgaussian: Vast 3d gaus- sians for large scene reconstruction
Jiaqi Lin, Zhihao Li, Xiao Tang, Jianzhuang Liu, Shiyong Liu, Jiayue Liu, Yangdi Lu, Xiaofei Wu, Songcen Xu, You- liang Yan, and Wenming Yang. Vastgaussian: Vast 3d gaus- sians for large scene reconstruction. InConference on Com- puter Vision and Pattern Recognition, pages 5166–5175,
-
[25]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024. 2, 6
2024
-
[26]
Mvsgaussian: Fast generalizable gaussian splatting re- construction from multi-view stereo
Tianqi Liu, Guangcong Wang, Shoukang Hu, Liao Shen, Xinyi Ye, Yuhang Zang, Zhiguo Cao, Wei Li, and Ziwei Liu. Mvsgaussian: Fast generalizable gaussian splatting re- construction from multi-view stereo. InComputer Vision - ECCV 2024 - 18th European Conference, pages 37–53,
2024
-
[27]
3dgs-enhancer: Enhancing unbounded 3d gaussian splatting with view- consistent 2d diffusion priors.Advances in Neural Informa- tion Processing Systems, 37:133305–133327, 2024
Xi Liu, Chaoyi Zhou, and Siyu Huang. 3dgs-enhancer: Enhancing unbounded 3d gaussian splatting with view- consistent 2d diffusion priors.Advances in Neural Informa- tion Processing Systems, 37:133305–133327, 2024. 3
2024
-
[28]
Scaffold-gs: Structured 3d gaussians for view-adaptive rendering
Tao Lu, Mulin Yu, Linning Xu, Yuanbo Xiangli, Limin Wang, Dahua Lin, and Bo Dai. Scaffold-gs: Structured 3d gaussians for view-adaptive rendering. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 20654–20664, 2024. 2
2024
-
[29]
Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 2021. 1, 2
2021
-
[30]
Blind/referenceless image spatial quality evaluator
Anish Mittal, Anush K Moorthy, and Alan C Bovik. Blind/referenceless image spatial quality evaluator. In2011 conference record of the forty fifth asilomar conference on signals, systems and computers (ASILOMAR), pages 723–
-
[31]
Compact 3d scene representation via self- organizing gaussian grids
Wieland Morgenstern, Florian Barthel, Anna Hilsmann, and Peter Eisert. Compact 3d scene representation via self- organizing gaussian grids. InComputer Vision - ECCV 2024 - 18th European Conference, pages 18–34, 2024. 1
2024
-
[32]
Scal- ing transformer-based novel view synthesis with models to- ken disentanglement and synthetic data
Nithin Gopalakrishnan Nair, Srinivas Kaza, Xuan Luo, Vishal M Patel, Stephen Lombardi, and Jungyeon Park. Scal- ing transformer-based novel view synthesis with models to- ken disentanglement and synthetic data. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 28567–28576, 2025. 2, 3
2025
-
[33]
In- finigen indoors: Photorealistic indoor scenes using procedu- ral generation
Alexander Raistrick, Lingjie Mei, Karhan Kayan, David Yan, Yiming Zuo, Beining Han, Hongyu Wen, Meenal Parakh, Stamatis Alexandropoulos, Lahav Lipson, et al. In- finigen indoors: Photorealistic indoor scenes using procedu- ral generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21783– 21794, 2024. 2, 3
2024
-
[34]
Hypersim: A photorealistic syn- thetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic syn- thetic dataset for holistic indoor scene understanding. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10912–10922, 2021. 2, 3
2021
-
[35]
Barron, Ben Mildenhall, Pratul P
Barbara Roessle, Jonathan T. Barron, Ben Mildenhall, Pratul P. Srinivasan, and Matthias Nießner. Dense depth priors for neural radiance fields from sparse input views. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12882–12891, 2022. 2
2022
-
[36]
Sch ¨onberger and Jan-Michael Frahm
Johannes L. Sch ¨onberger and Jan-Michael Frahm. Structure- from-motion revisited. InIEEE Conference on Computer Vision and Pattern Recognition, pages 4104–4113, 2016. 1
2016
-
[37]
Behav- ior: Benchmark for everyday household activities in virtual, interactive, and ecological environments
Sanjana Srivastava, Chengshu Li, Michael Lingelbach, Roberto Mart´ın-Mart´ın, Fei Xia, Kent Elliott Vainio, Zheng Lian, Cem Gokmen, Shyamal Buch, Karen Liu, et al. Behav- ior: Benchmark for everyday household activities in virtual, interactive, and ecological environments. InConference on robot learning, pages 477–490. PMLR, 2022. 2, 3
2022
-
[38]
SAGS: structure-aware 3d gaussian splatting
Evangelos Ververas, Rolandos Alexandros Potamias, Jifei Song, Jiankang Deng, and Stefanos Zafeiriou. SAGS: structure-aware 3d gaussian splatting. InComputer Vision - ECCV 2024 - 18th European Conference, pages 221–238,
2024
-
[39]
VGGT: visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotn ´y. VGGT: visual geometry grounded transformer. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 5294–5306, 2025. 2
2025
-
[40]
Nan Wang, Yuantao Chen, Lixing Xiao, Weiqing Xiao, Bo- han Li, Zhaoxi Chen, Chongjie Ye, Shaocong Xu, Saining Zhang, Ziyang Yan, Pierre Merriaux, Lei Lei, Tianfan Xue, and Hao Zhao. Unifying appearance codes and bilateral grids for driving scene gaussian splatting.CoRR, abs/2506.05280,
-
[41]
Srinivasan, Howard Zhou, Jonathan T
Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul P. Srinivasan, Howard Zhou, Jonathan T. Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas A. Funkhouser. Ibrnet: Learning multi-view image-based rendering. InIEEE Conference on Computer Vision and Pattern Recognition, pages 4690–4699, 2021. 2
2021
-
[42]
Dust3r: Geometric 3d vi- sion made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and J´erˆome Revaud. Dust3r: Geometric 3d vi- sion made easy. InIEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 20697–20709, 2024. 2
2024
-
[43]
Tartanair: A dataset to push the limits of visual slam
Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Se- bastian Scherer. Tartanair: A dataset to push the limits of visual slam. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4909–4916. IEEE, 2020. 2, 3
2020
-
[44]
Bilateral guided radiance field processing.ACM Trans
Yuehao Wang, Chaoyi Wang, Bingchen Gong, and Tianfan Xue. Bilateral guided radiance field processing.ACM Trans. Graph., 43(4):148:1–148:13, 2024. 2
2024
-
[45]
Nerfbusters: Re- moving ghostly artifacts from casually captured nerfs
Frederik Warburg, Ethan Weber, Matthew Tancik, Alek- sander Holynski, and Angjoo Kanazawa. Nerfbusters: Re- moving ghostly artifacts from casually captured nerfs. In IEEE/CVF International Conference on Computer Vision, pages 18074–18084, 2023. 3
2023
-
[46]
Nerfbusters: Re- moving ghostly artifacts from casually captured nerfs
Frederik Warburg, Ethan Weber, Matthew Tancik, Alek- sander Holynski, and Angjoo Kanazawa. Nerfbusters: Re- moving ghostly artifacts from casually captured nerfs. In IEEE/CVF International Conference on Computer Vision, pages 18074–18084, 2023. 2, 7
2023
-
[47]
Difix3d+: Improving 3d reconstruc- tions with single-step diffusion models
Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xuanchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Goj- cic, and Huan Ling. Difix3d+: Improving 3d reconstruc- tions with single-step diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26024–26035, 2025. 3, 5, 6, 7, 8, 1
2025
-
[48]
Srinivasan, Dor Verbin, Jonathan T
Rundi Wu, Ben Mildenhall, Philipp Henzler, Keunhong Park, Ruiqi Gao, Daniel Watson, Pratul P. Srinivasan, Dor Verbin, Jonathan T. Barron, Ben Poole, and Aleksander Holynski. Reconfusion: 3d reconstruction with diffusion priors. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21551–21561, 2024. 3
2024
-
[49]
Lrm-zero: Training large reconstruction models with syn- thesized data.Advances in Neural Information Processing Systems, 37:53285–53316, 2024
Desai Xie, Sai Bi, Zhixin Shu, Kai Zhang, Zexiang Xu, Yi Zhou, S ¨oren Pirk, Arie Kaufman, Xin Sun, and Hao Tan. Lrm-zero: Training large reconstruction models with syn- thesized data.Advances in Neural Information Processing Systems, 37:53285–53316, 2024. 2, 3
2024
-
[50]
Depthsplat: Connecting gaussian splatting and depth
Haofei Xu, Songyou Peng, Fangjinhua Wang, Hermann Blum, Daniel Barath, Andreas Geiger, and Marc Polle- feys. Depthsplat: Connecting gaussian splatting and depth. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16453–16463, 2025. 2
2025
-
[51]
Jiacong Xu, Yiqun Mei, and Vishal M. Patel. Wild-gs: Real- time novel view synthesis from unconstrained photo collec- tions. InAnnual Conference on Neural Information Process- ing Systems 2024, 2024. 2
2024
-
[52]
No pose, no prob- lem: Surprisingly simple 3d gaussian splats from sparse un- posed images
Botao Ye, Sifei Liu, Haofei Xu, Xueting Li, Marc Pollefeys, Ming-Hsuan Yang, and Songyou Peng. No pose, no prob- lem: Surprisingly simple 3d gaussian splats from sparse un- posed images. InThe Thirteenth International Conference on Learning Representations,, 2025. 2
2025
-
[53]
GS-LRM: large recon- struction model for 3d gaussian splatting
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, and Zexiang Xu. GS-LRM: large recon- struction model for 3d gaussian splatting. InComputer Vi- sion - ECCV 2024 - 18th European Conference, pages 1–19,
2024
-
[54]
Pixel-gs: Density control with pixel-aware gradient for 3d gaussian splatting
Zheng Zhang, Wenbo Hu, Yixing Lao, Tong He, and Heng- shuang Zhao. Pixel-gs: Density control with pixel-aware gradient for 3d gaussian splatting. InComputer Vision - ECCV 2024 - 18th European Conference, pages 326–342,
2024
-
[55]
7), addi- tional ablation studies on free-views generation (Sec
2 FreeScale: Scaling 3D Scenes via Certainty-Aware Free-View Generation Supplementary Material This supplementary material consists of three parts: technical details of the experimental setup (Sec. 7), addi- tional ablation studies on free-views generation (Sec. 8), and additional qualitative results (Sec. 9), including out-of- domain results and a discus...
-
[56]
Implement Details 7.1. Certainty-aware Free-View Synthesis Virtual Viewpoints Placement.We first generate virtual viewpoints trajectories with 10 predefined modes, includ- ing:geometric paths: (1) orbit, (2) spiral, (3) lemniscate; (4)interpolation; andcinematic movements: (5) move up, (6) move down, (7) move left, (8) move right, (9) dolly- zoom in, (10)...
-
[57]
Additional Ablation Studies In this part, we conduct more ablation studies on free-view generation and show more cases about reference image se- lection mentioned in the main body Sec.5.3. 8.1. Ablation on Free-View Generation The primary objective of FVGen is to collect a set of high-diversity and high-quality free-view images. This is achieved by utiliz...
-
[58]
Additional Qualitative Results In this part, we provide more qualitative comparison for feedforward model and per-scene reconstruction. Out-of-Domain Results of FeedForward Model.We pro- vide a qualitative comparison of the feed-forward model performance on out-of-domain (OOD) data, specifically us- ing the MipNeRF360 dataset. Figure 11 illustrates the no...
-
[59]
Despite our certainty- aware View Graph improving reference image selection by ensuring geometric correspondence, residual artifacts can still be introduced
Limitation and Future Works The primary limitation lies in the Free-View Rectification stage, as the final image quality depends on the external dif- fusion model used for enhancement. Despite our certainty- aware View Graph improving reference image selection by ensuring geometric correspondence, residual artifacts can still be introduced. For future wor...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.