Recognition: unknown
Differentiable Vector Quantization for Rate-Distortion Optimization of Generative Image Compression
Pith reviewed 2026-05-10 16:00 UTC · model grok-4.3
The pith
Making the codebook distribution differentiable allows joint rate-distortion optimization in vector-quantized image compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
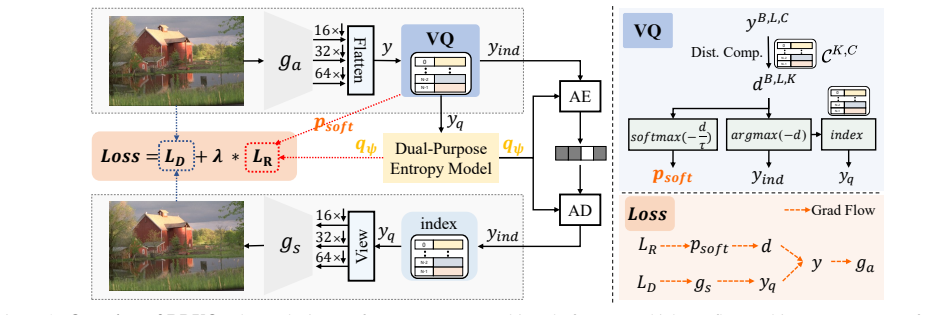
RDVQ shows that relaxing the codebook distribution to be differentiable removes the barrier between representation learning and entropy modeling in vector quantization. This permits the entropy loss to directly influence the latent prior inside a single end-to-end optimization loop. Paired with an autoregressive entropy model, the formulation supports both precise rate estimation and adjustable rate-distortion trade-offs at inference time. Experiments indicate that the resulting lightweight networks achieve strong perceptual quality at extremely low bitrates, with reported bitrate savings of up to 75.71 percent on DISTS and 37.63 percent on LPIPS relative to RDEIC on DIV2K-val.
What carries the argument
Differentiable relaxation of the codebook distribution, which lets the entropy loss directly shape the latent prior.
If this is right
- Entropy-constrained vector quantization becomes feasible, letting the rate term directly influence which codes are selected during training.
- An autoregressive entropy model supplies both accurate probability estimates and test-time rate control without separate post-processing.
- Lightweight architectures can match or exceed prior perceptual quality while using significantly fewer parameters at very low bitrates.
- The framework unifies tokenization and compression under a single entropy-constrained objective.
Where Pith is reading between the lines
- The same relaxation technique could be applied to other discrete latent models in generative pipelines where compression cost must be considered during training.
- Because the method separates the quantization step from the entropy model only through a differentiable bridge, it may simplify integration with downstream generative tasks that already rely on discrete tokens.
- The reported parameter efficiency suggests the approach could be attractive for on-device or bandwidth-constrained deployment scenarios that current heavier generative compressors cannot address.
Load-bearing premise
The differentiable relaxation approximates the true discrete codebook selection closely enough that the entropy loss can guide optimization without introducing bias or instability that would erase the claimed rate-distortion gains.
What would settle it
Ablating the differentiable relaxation, retraining from scratch, and checking whether the entropy term still produces the reported bitrate reductions on DIV2K-val while keeping perceptual metrics stable; instability or loss of the gains would falsify the central mechanism.
Figures








read the original abstract
The rapid growth of visual data under stringent storage and bandwidth constraints makes extremely low-bitrate image compression increasingly important. While Vector Quantization (VQ) offers strong structural fidelity, existing methods lack a principled mechanism for joint rate-distortion (RD) optimization due to the disconnect between representation learning and entropy modeling. We propose RDVQ, a unified framework that enables end-to-end RD optimization for VQ-based compression via a differentiable relaxation of the codebook distribution, allowing the entropy loss to directly shape the latent prior. We further develop an autoregressive entropy model that supports accurate entropy modeling and test-time rate control. Extensive experiments demonstrate that RDVQ achieves strong performance at extremely low bitrates with a lightweight architecture, attaining competitive or superior perceptual quality with significantly fewer parameters. Compared with RDEIC, RDVQ reduces bitrate by up to 75.71% on DISTS and 37.63% on LPIPS on DIV2K-val. Beyond empirical gains, RDVQ introduces an entropy-constrained formulation of VQ, highlighting the potential for a more unified view of image tokenization and compression. The code will be available at https://github.com/CVL-UESTC/RDVQ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RDVQ, a framework for vector quantization in generative image compression that employs a differentiable relaxation of the codebook distribution to enable joint end-to-end rate-distortion optimization. It introduces an autoregressive entropy model supporting accurate modeling and test-time rate control. Experiments claim strong low-bitrate performance on DIV2K-val with a lightweight architecture, including up to 75.71% bitrate reduction on DISTS and 37.63% on LPIPS versus RDEIC, while highlighting an entropy-constrained view of VQ.
Significance. If the relaxation permits unbiased optimization without material train-test discrepancy, the work offers a principled unification of VQ tokenization and entropy modeling that could advance efficient generative compression. The lightweight architecture and reported perceptual gains at extreme low rates, combined with planned code release, represent practical strengths for the field.
major comments (2)
- [§3] §3 (differentiable relaxation derivation): The entropy model is trained on the soft (relaxed) codebook distribution, yet inference uses hard argmax quantization. No bound, KL(soft || hard) measurement, or empirical comparison of model-estimated rate versus actual arithmetic-coded bitrate is reported. This mismatch is load-bearing for the central claim of unbiased RD optimization and directly affects the reliability of the 75.71% and 37.63% bitrate reductions.
- [Abstract, §4] Abstract and §4 (experimental claims): The specific percentage reductions versus RDEIC are presented without accompanying ablation studies on the relaxation temperature, entropy model architecture, or error analysis on the rate gap. This leaves the robustness of the perceptual metric improvements (DISTS, LPIPS) difficult to verify.
minor comments (2)
- The abstract states that code will be available at a GitHub link; confirming this link is active and includes training scripts would aid reproducibility.
- [§3] Notation for the relaxation (e.g., temperature parameter or Gumbel-softmax formulation) should be introduced with an explicit equation reference in §3 to improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which help clarify the presentation of our differentiable relaxation and experimental claims. We address each major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [§3] §3 (differentiable relaxation derivation): The entropy model is trained on the soft (relaxed) codebook distribution, yet inference uses hard argmax quantization. No bound, KL(soft || hard) measurement, or empirical comparison of model-estimated rate versus actual arithmetic-coded bitrate is reported. This mismatch is load-bearing for the central claim of unbiased RD optimization and directly affects the reliability of the 75.71% and 37.63% bitrate reductions.
Authors: We agree that explicit quantification of the train-test gap is necessary to support the unbiased RD optimization claim. The relaxation (a temperature-controlled softmax over codebook distances) is constructed so that the soft distribution converges pointwise to the hard argmax as temperature approaches zero; this is the standard justification for using the soft proxy during training. In the revision we will add: (i) empirical KL(soft || hard) statistics computed on the DIV2K-val set at the operating temperature, and (ii) a direct comparison of the entropy-model rate estimate versus the actual arithmetic-coded bitrate obtained with hard quantization. These measurements will be reported in an expanded §3. A formal error bound is not currently derived in the manuscript; we will therefore limit the addition to the empirical evidence rather than claiming a new theoretical guarantee. revision: partial
-
Referee: [Abstract, §4] Abstract and §4 (experimental claims): The specific percentage reductions versus RDEIC are presented without accompanying ablation studies on the relaxation temperature, entropy model architecture, or error analysis on the rate gap. This leaves the robustness of the perceptual metric improvements (DISTS, LPIPS) difficult to verify.
Authors: The reported bitrate reductions are obtained with the full RDVQ model (fixed temperature, autoregressive entropy model) on DIV2K-val. We concur that additional controls would strengthen the claims. In the revised manuscript we will insert a new ablation subsection in §4 that varies (a) the relaxation temperature over a small grid around the value used in the main experiments and (b) the entropy-model context size. We will also report the mean and standard deviation of the rate-estimation error (estimated entropy minus actual coded rate) across the test images. These results will be summarized in the text and in a supplementary table, allowing readers to assess the sensitivity of the DISTS and LPIPS gains. revision: yes
Circularity Check
No significant circularity; derivation relies on independent modeling choice and empirical validation
full rationale
The paper's central contribution is a differentiable relaxation of the codebook distribution to enable joint RD optimization in VQ-based compression, followed by an autoregressive entropy model. This relaxation is presented as a technical innovation (e.g., allowing entropy loss to shape the latent prior) without reducing to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. Performance claims rest on external benchmarks (DIV2K-val comparisons to RDEIC) rather than tautological equivalence to inputs. No equations or steps in the provided abstract or description collapse the claimed bitrate reductions or perceptual gains to prior author work by construction. The train-test distribution mismatch is a potential correctness concern but does not constitute circularity under the specified patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ntire 2017 challenge on single image super-resolution: Dataset and study
Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. InPro- ceedings of the IEEE conference on computer vision and pat- tern recognition workshops, pages 126–135, 2017. 2, 6
2017
-
[2]
Generative adversarial networks for extreme learned image compression
Eirikur Agustsson, Michael Tschannen, Fabian Mentzer, Radu Timofte, and Luc Van Gool. Generative adversarial networks for extreme learned image compression. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 221–231, 2019. 3
2019
-
[3]
Multi-realism image compression with a conditional generator
Eirikur Agustsson, David Minnen, George Toderici, and Fabian Mentzer. Multi-realism image compression with a conditional generator. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 22324–22333, 2023. 3
2023
-
[4]
End-to-end optimized image compression.arXiv preprint arXiv:1611.01704, 2016
Johannes Ball ´e, Valero Laparra, and Eero P Simoncelli. End-to-end optimized image compression.arXiv preprint arXiv:1611.01704, 2016. 2
-
[5]
Variational image compression with a scale hyperprior
Johannes Ball ´e, David Minnen, Saurabh Singh, Sung Jin Hwang, and Nick Johnston. Variational image compression with a scale hyperprior.arXiv preprint arXiv:1802.01436,
-
[6]
Bpg image format.https://bellard
Fabrice Bellard. Bpg image format.https://bellard. org/bpg/. Accessed: 2024-10-26. 1
2024
-
[7]
Overview of the versatile video coding (vvc) standard and its applications
Benjamin Bross, Ye-Kui Wang, Yan Ye, Shan Liu, Jianle Chen, Gary J Sullivan, and Jens-Rainer Ohm. Overview of the versatile video coding (vvc) standard and its applications. IEEE Transactions on Circuits and Systems for Video Tech- nology, 31(10):3736–3764, 2021. 1, 3, 6
2021
-
[8]
Muckley, Jakob Verbeek, and St´ephane Lathuili`ere
Marlene Careil, Matthew J. Muckley, Jakob Verbeek, and St´ephane Lathuili`ere. Towards image compression with per- fect realism at ultra-low bitrates. InThe Twelfth International Conference on Learning Representations, 2024. 3, 6
2024
-
[9]
Learned image compression with discretized gaussian mixture likelihoods and attention modules
Zhengxue Cheng, Heming Sun, Masaru Takeuchi, and Jiro Katto. Learned image compression with discretized gaussian mixture likelihoods and attention modules. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7939–7948, 2020. 2
2020
-
[10]
Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and ma- chine intelligence, 44(5):2567–2581, 2020
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P Simoncelli. Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and ma- chine intelligence, 44(5):2567–2581, 2020. 2, 6
2020
-
[11]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 6
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[12]
Qarv: Quantization-aware resnet vae for lossy image compression.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(1):436–450, 2023
Zhihao Duan, Ming Lu, Jack Ma, Yuning Huang, Zhan Ma, and Fengqing Zhu. Qarv: Quantization-aware resnet vae for lossy image compression.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(1):436–450, 2023. 3
2023
-
[13]
Image com- pression with product quantized masked image modeling
Alaaeldin El-Nouby, Matthew J Muckley, Karen Ullrich, Ivan Laptev, Jakob Verbeek, and Herv´e J´egou. Image com- pression with product quantized masked image modeling. arXiv preprint arXiv:2212.07372, 2022. 2
-
[14]
Taming transformers for high-resolution image synthesis, 2020
Patrick Esser, Robin Rombach, and Bj ¨orn Ommer. Taming transformers for high-resolution image synthesis, 2020. 2, 3
2020
-
[15]
Kodak dataset
Rich Franzen. Kodak dataset. Online, 2013. Available athttps://r0k.us/graphics/kodak/(accessed: 2025–11–13). 6
2013
-
[16]
Springer Science & Business Media,
Allen Gersho and Robert M Gray.Vector quantization and signal compression. Springer Science & Business Media,
-
[17]
Noor Fathima Ghouse, Jens Petersen, Auke Wiggers, Tianlin Xu, and Guillaume Sautiere. A residual diffusion model for high perceptual quality codec augmentation.arXiv preprint arXiv:2301.05489, 2023. 3
-
[18]
Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020. 2, 3, 6
2020
-
[19]
Oscar: One-step diffusion codec across multiple bit-rates.arXiv preprint arXiv:2505.16091,
Jinpei Guo, Yifei Ji, Zheng Chen, Kai Liu, Min Liu, Wang Rao, Wenbo Li, Yong Guo, and Yulun Zhang. Oscar: One- step diffusion codec across multiple bit-rates.arXiv preprint arXiv:2505.16091, 2025. 3, 6
-
[20]
Causal context adjust- ment loss for learned image compression.arXiv preprint arXiv:2410.04847, 2024
Minghao Han, Shiyin Jiang, Shengxi Li, Xin Deng, Mai Xu, Ce Zhu, and Shuhang Gu. Causal context adjust- ment loss for learned image compression.arXiv preprint arXiv:2410.04847, 2024. 2
-
[21]
Generative image compression by estimating gradients of the rate-variable feature distribution
Minghao Han, Weiyi You, Jinhua Zhang, Leheng Zhang, Ce Zhu, and Shuhang Gu. Generative image compression by estimating gradients of the rate-variable feature distribution. arXiv preprint arXiv:2505.20984, 2025. 3
-
[22]
Elic: Efficient learned image compres- sion with unevenly grouped space-channel contextual adap- tive coding
Dailan He, Ziming Yang, Weikun Peng, Rui Ma, Hongwei Qin, and Yan Wang. Elic: Efficient learned image compres- sion with unevenly grouped space-channel contextual adap- tive coding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5718– 5727, 2022. 2
2022
-
[23]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017. 6
2017
-
[24]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models.arXiv preprint arxiv:2006.11239,
work page internal anchor Pith review arXiv 2006
-
[25]
Zhihao Hu, Guo Lu, and Dong Xu
Emiel Hoogeboom, Eirikur Agustsson, Fabian Mentzer, Luca Versari, George Toderici, and Lucas Theis. High- fidelity image compression with score-based generative models.arXiv preprint arXiv:2305.18231, 2023. 1, 3
-
[26]
Generative latent coding for ultra-low bitrate image com- pression
Zhaoyang Jia, Jiahao Li, Bin Li, Houqiang Li, and Yan Lu. Generative latent coding for ultra-low bitrate image com- pression. InProceedings of the IEEE/CVF Conference on 9 Computer Vision and Pattern Recognition, pages 26088– 26098, 2024. 3
2024
-
[27]
Mlic++: Linear complexity multi-reference entropy modeling for learned image compression,
Wei Jiang, Jiayu Yang, Yongqi Zhai, Feng Gao, and Rong- gang Wang. Mlic++: Linear complexity multi-reference entropy modeling for learned image compression.arXiv preprint arXiv:2307.15421, 2023. 2, 3
-
[28]
Anle Ke, Xu Zhang, Tong Chen, Ming Lu, Chao Zhou, Ji- awen Gu, and Zhan Ma. Ultra lowrate image compression with semantic residual coding and compression-aware diffu- sion.arXiv preprint arXiv:2505.08281, 2025. 6, 3
-
[29]
Egic: enhanced low-bit-rate generative image compression guided by semantic segmentation
Nikolai K ¨orber, Eduard Kromer, Andreas Siebert, Sascha Hauke, Daniel Mueller-Gritschneder, and Bj ¨orn Schuller. Egic: enhanced low-bit-rate generative image compression guided by semantic segmentation. InEuropean Conference on Computer Vision, pages 202–220. Springer, 2024. 3
2024
-
[30]
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Ui- jlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale.Interna- tional journal of computer vision, 128(7):1956–1981, 2020. 6, 2
1956
-
[31]
Neural image compres- sion with text-guided encoding for both pixel-level and per- ceptual fidelity
Hagyeong Lee, Minkyu Kim, Jun-Hyuk Kim, Seungeon Kim, Dokwan Oh, and Jaeho Lee. Neural image compres- sion with text-guided encoding for both pixel-level and per- ceptual fidelity. InInternational Conference on Machine Learning, 2024. 3
2024
-
[32]
Text+ sketch: Image compression at ultra low rates
Eric Lei, Yi ˘git Berkay Uslu, Hamed Hassani, and Shirin Saeedi Bidokhti. Text+ sketch: Image compression at ultra low rates. InICML 2023 Workshop on Neural Com- pression: From Information Theory to Applications, 2023. 3
2023
-
[33]
Once-for-all: Controllable generative image compression with dynamic granularity adaptation
Anqi Li, Feng Li, Yuxi Liu, Runmin Cong, Yao Zhao, and Huihui Bai. Once-for-all: Controllable generative image compression with dynamic granularity adaptation. InThe Thirteenth International Conference on Learning Represen- tations, 2025. 1, 2, 3
2025
-
[34]
Frequency-aware transformer for learned image compression.arXiv preprint arXiv:2310.16387, 2023
Han Li, Shaohui Li, Wenrui Dai, Chenglin Li, Junni Zou, and Hongkai Xiong. Frequency-aware transformer for learned image compression.arXiv preprint arXiv:2310.16387, 2023. 2
-
[35]
Texture vector-quantization and recon- struction aware prediction for generative super-resolution
Qifan Li, Jiale Zou, Jinhua Zhang, Wei Long, Xingyu Zhou, and Shuhang Gu. Texture vector-quantization and recon- struction aware prediction for generative super-resolution. arXiv preprint arXiv:2509.23774, 2025. 3
-
[36]
Learned image compression with hierarchical progressive context modeling,
Yuqi Li, Haotian Zhang, Li Li, and Dong Liu. Learned image compression with hierarchical progressive context modeling. arXiv preprint arXiv:2507.19125, 2025. 3
-
[37]
Toward extreme image compression with latent feature guidance and diffusion prior.IEEE Transactions on Circuits and Systems for Video Technology, 35(1):888–899,
Zhiyuan Li, Yanhui Zhou, Hao Wei, Chenyang Ge, and Jing- wen Jiang. Toward extreme image compression with latent feature guidance and diffusion prior.IEEE Transactions on Circuits and Systems for Video Technology, 35(1):888–899,
-
[38]
Rdeic: Accelerating diffusion-based extreme im- age compression with relay residual diffusion.IEEE Trans- actions on Circuits and Systems for Video Technology, 2025
Zhiyuan Li, Yanhui Zhou, Hao Wei, Chenyang Ge, and Aj- mal Mian. Rdeic: Accelerating diffusion-based extreme im- age compression with relay residual diffusion.IEEE Trans- actions on Circuits and Systems for Video Technology, 2025. 2, 6, 3
2025
-
[39]
Zijian Liang, Kai Niu, Changshuo Wang, Jin Xu, and Ping Zhang. Synonymous variational inference for perceptual im- age compression.arXiv preprint arXiv:2505.22438, 2025. 3
-
[40]
Learned image compression with mixed transformer-cnn architectures
Jinming Liu, Heming Sun, and Jiro Katto. Learned image compression with mixed transformer-cnn architectures. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 14388–14397, 2023. 2
2023
-
[41]
Icmh- net: Neural image compression towards both machine vision and human vision
Lei Liu, Zhihao Hu, Zhenghao Chen, and Dong Xu. Icmh- net: Neural image compression towards both machine vision and human vision. InProceedings of the 31st ACM Interna- tional Conference on Multimedia, pages 8047–8056, 2023. 2, 3
2023
-
[42]
Lei Liu, Zhenghao Chen, Zhihao Hu, and Dong Xu. An efficient adaptive compression method for human perception and machine vision tasks.arXiv preprint arXiv:2501.04329,
-
[43]
Adaptive bitrate quantization scheme without codebook for learned image compression
Jonas L ¨ohdefink, Jonas Sitzmann, Andreas B ¨ar, and Tim Fingscheidt. Adaptive bitrate quantization scheme without codebook for learned image compression. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1732–1737, 2022. 2
2022
-
[44]
Learned image compression with dictionary- based entropy model.arXiv preprint arXiv:2504.00496,
Jingbo Lu, Leheng Zhang, Xingyu Zhou, Mu Li, Wen Li, and Shuhang Gu. Learned image compression with dictionary- based entropy model.arXiv preprint arXiv:2504.00496,
-
[45]
Hybridflow: Infusing continuity into masked codebook for extreme low-bitrate image compression
Lei Lu, Yanyue Xie, Wei Jiang, Wei Wang, Xue Lin, and Yanzhi Wang. Hybridflow: Infusing continuity into masked codebook for extreme low-bitrate image compression. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 3010–3018, 2024. 1, 2
2024
-
[46]
Yiyang Ma, Wenhan Yang, and Jiaying Liu. Correcting diffusion-based perceptual image compression with privi- leged end-to-end decoder.arXiv preprint arXiv:2404.04916,
-
[47]
Extreme im- age compression using fine-tuned vqgans
Qi Mao, Tinghan Yang, Yinuo Zhang, Zijian Wang, Meng Wang, Shiqi Wang, Libiao Jin, and Siwei Ma. Extreme im- age compression using fine-tuned vqgans. In2024 Data Compression Conference (DCC), pages 203–212. IEEE,
-
[48]
High-fidelity generative image compres- sion.Advances in neural information processing systems, 33:11913–11924, 2020
Fabian Mentzer, George D Toderici, Michael Tschannen, and Eirikur Agustsson. High-fidelity generative image compres- sion.Advances in neural information processing systems, 33:11913–11924, 2020. 1, 3
2020
-
[49]
M2t: Masking transformers twice for faster decoding
Fabian Mentzer, Eirikur Agustson, and Michael Tschannen. M2t: Masking transformers twice for faster decoding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5340–5349, 2023. 2, 3
2023
-
[50]
Channel-wise autoregres- sive entropy models for learned image compression
David Minnen and Saurabh Singh. Channel-wise autoregres- sive entropy models for learned image compression. In2020 IEEE International Conference on Image Processing (ICIP), pages 3339–3343. IEEE, 2020. 2
2020
-
[51]
Muckley, Alaaeldin El-Nouby, Karen Ullrich, Herv´e J ´egou, and Jakob Verbeek
Matthew J. Muckley, Alaaeldin El-Nouby, Karen Ullrich, Herv´e J ´egou, and Jakob Verbeek. Improving statistical fi- delity for neural image compression with implicit local like- lihood models. InInternational Conference on Machine Learning, 2023. 6, 3 10
2023
-
[52]
Guy Ohayon, Hila Manor, Tomer Michaeli, and Michael Elad. Compressed image generation with denoising diffu- sion codebook models.arXiv preprint arXiv:2502.01189,
-
[53]
Compressed image generation with denoising diffusion codebook models
Guy Ohayon, Hila Manor, Tomer Michaeli, and Michael Elad. Compressed image generation with denoising diffusion codebook models. InForty-second International Conference on Machine Learning, 2025. 3
2025
-
[54]
Chanung Park, Joo Chan Lee, and Jong Hwan Ko. Diffo: Single-step diffusion for image compression at ultra-low bi- trates.arXiv preprint arXiv:2506.16572, 2025. 2, 3
-
[55]
Visual autoregressive modeling for image super-resolution.arXiv preprint arXiv:2501.18993,
Yunpeng Qu, Kun Yuan, Jinhua Hao, Kai Zhao, Qizhi Xie, Ming Sun, and Chao Zhou. Visual autoregres- sive modeling for image super-resolution.arXiv preprint arXiv:2501.18993, 2025. 3
-
[56]
Bridging the gap between gaus- sian diffusion models and universal quantization for image compression
Lucas Relic, Roberto Azevedo, Yang Zhang, Markus Gross, and Christopher Schroers. Bridging the gap between gaus- sian diffusion models and universal quantization for image compression. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2449–2458, 2025. 3
2025
-
[57]
Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015. 2
2015
-
[58]
End-to-end learned image compression with fixed point weight quantization
Heming Sun, Zhengxue Cheng, Masaru Takeuchi, and Jiro Katto. End-to-end learned image compression with fixed point weight quantization. In2020 IEEE International Conference on Image Processing (ICIP), pages 3359–3363. IEEE, 2020. 2
2020
-
[59]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024. 2, 3, 5, 1
work page internal anchor Pith review arXiv 2024
-
[60]
Amit Vaisman, Guy Ohayon, Hila Manor, Michael Elad, and Tomer Michaeli
Lucas Theis, Tim Salimans, Matthew D Hoffman, and Fabian Mentzer. Lossy compression with gaussian diffusion. arXiv preprint arXiv:2206.08889, 2022. 3
-
[61]
Workshop and challenge on learned image compression (clic2020)
George Toderici, Wenzhe Shi, Radu Timofte, Lucas Theis, Johannes Balle, Eirikur Agustsson, Nick Johnston, and Fabian Mentzer. Workshop and challenge on learned image compression (clic2020). InCVPR, 2020. 6
2020
-
[62]
Ex- ploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Ex- ploring clip for assessing the look and feel of images. InPro- ceedings of the AAAI conference on artificial intelligence, pages 2555–2563, 2023. 6
2023
-
[63]
Yongbo Wang, Haonan Wang, Guodong Mu, Ruixin Zhang, Jiaqi Chen, Jingyun Zhang, Jun Wang, Yuan Xie, Zhizhong Zhang, and Shouhong Ding. Switchable token-specific codebook quantization for face image compression.arXiv preprint arXiv:2510.22943, 2025. 2
-
[64]
Enhanced invertible encoding for learned image compression
Yueqi Xie, Ka Leong Cheng, and Qifeng Chen. Enhanced invertible encoding for learned image compression. InPro- ceedings of the 29th ACM international conference on mul- timedia, pages 162–170, 2021. 2
2021
-
[65]
Unifying generation and compression: Ultra-low bi- trate image coding via multi-stage transformer
Naifu Xue, Qi Mao, Zijian Wang, Yuan Zhang, and Siwei Ma. Unifying generation and compression: Ultra-low bi- trate image coding via multi-stage transformer. In2024 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2024. 2, 3, 5
2024
-
[66]
Dlf: Extreme image compression with dual- generative latent fusion.arXiv preprint arXiv:2503.01428,
Naifu Xue, Zhaoyang Jia, Jiahao Li, Bin Li, Yuan Zhang, and Yan Lu. Dlf: Extreme image compression with dual- generative latent fusion.arXiv preprint arXiv:2503.01428,
-
[67]
Naifu Xue, Zhaoyang Jia, Jiahao Li, Bin Li, Yuan Zhang, and Yan Lu. One-step diffusion-based image compression with semantic distillation.arXiv preprint arXiv:2505.16687,
-
[68]
Lossy image compression with conditional diffusion models.Advances in Neural In- formation Processing Systems, 36:64971–64995, 2023
Ruihan Yang and Stephan Mandt. Lossy image compression with conditional diffusion models.Advances in Neural In- formation Processing Systems, 36:64971–64995, 2023. 3
2023
-
[69]
MV AR: Visual autoregressive modeling with scale and spatial markovian conditioning
Jinhua Zhang, Wei Long, Minghao Han, Weiyi You, and Shuhang Gu. MV AR: Visual autoregressive modeling with scale and spatial markovian conditioning. InThe Four- teenth International Conference on Learning Representa- tions, 2026. 3
2026
-
[70]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 2, 6
2018
-
[71]
Stablecodec: Taming one-step diffusion for extreme image compression
Tianyu Zhang, Xin Luo, Li Li, and Dong Liu. Stablecodec: Taming one-step diffusion for extreme image compression. arXiv preprint arXiv:2506.21977, 2025. 6, 7, 3
-
[72]
Unified multivariate gaussian mixture for efficient neural image compression
Xiaosu Zhu, Jingkuan Song, Lianli Gao, Feng Zheng, and Heng Tao Shen. Unified multivariate gaussian mixture for efficient neural image compression. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17612–17621, 2022. 2, 3
2022
-
[73]
The devil is in the details: Window-based attention for image compression
Renjie Zou, Chunfeng Song, and Zhaoxiang Zhang. The devil is in the details: Window-based attention for image compression. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17492– 17501, 2022. 2 11 Differentiable Vector Quantization for Rate-Distortion Optimization of Generative Image Compression Supplementary Mate...
2022
-
[74]
Finally, joint RD optimization is performed with the full objectiveL= LD +λL R and the codebook fixed
to provide stable probability estimation. Finally, joint RD optimization is performed with the full objectiveL= LD +λL R and the codebook fixed. Models are first trained at relatively high bitrates and then progressively fine-tuned toward lower bitrates. From this stage onward, all models are trained in FP32 precision for stable optimization. High-resolut...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.