Recognition: unknown
WOODELF-HD: Efficient Background SHAP for High-Depth Decision Trees
Pith reviewed 2026-05-10 16:28 UTC · model grok-4.3
The pith
WoodelfHD reduces the preprocessing cost of exact Background SHAP from 3^D to 2^D for decision trees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
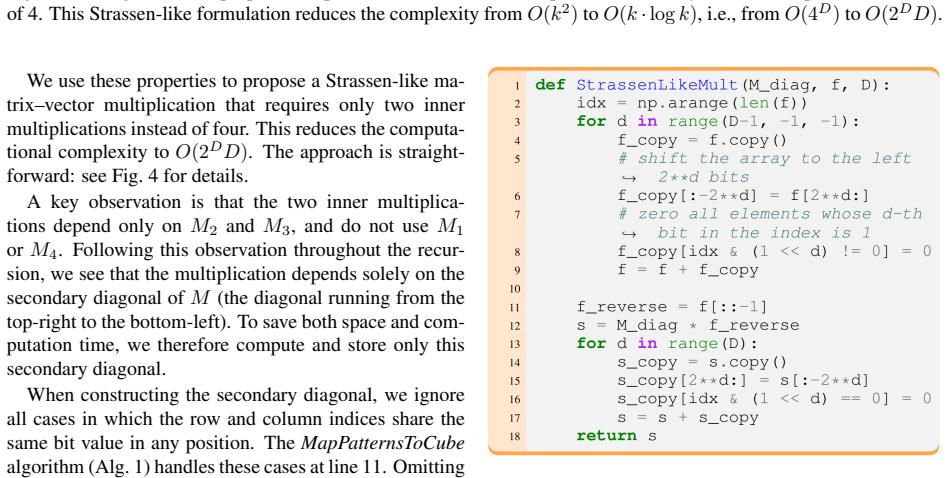
The paper shows that a Strassen-like multiplication scheme exploiting Woodelf matrix structure reduces matrix-vector multiplication from quadratic to O(k log k) in a fully vectorized non-recursive form, while merging nodes with identical features shrinks cache and memory requirements. Together these changes replace the 3^D preprocessing bottleneck with 2^D, enabling exact Background SHAP on trees up to depth 21 and delivering speedups of 33x and 162x for depth-12 and depth-15 ensembles over prior state-of-the-art methods.
What carries the argument
The Strassen-like multiplication scheme for Woodelf matrices that reduces matrix-vector multiplication to O(k log k) via vectorized non-recursive implementation, together with merging of path nodes that share identical features.
If this is right
- Exact Background SHAP becomes feasible for individual decision trees of depth up to 21 on standard computing hardware.
- Tree ensembles at depths 12 and 15 see speedups of 33 times and 162 times respectively over the previous best exact method.
- Memory footprint drops enough to avoid the excessive usage that stopped earlier methods at shallower depths.
Where Pith is reading between the lines
- The same matrix-structure optimizations might apply to other tree-explanation algorithms that face similar exponential preprocessing costs.
- Practitioners could now choose deeper trees for accuracy without losing the option of precise, exact SHAP explanations.
- Further reductions in the exponential base could become possible if the merging idea is combined with additional structural properties of decision paths.
Load-bearing premise
The Strassen-like multiplication scheme preserves exactness for the specific Woodelf matrices and that merging path nodes with identical features does not alter the computed SHAP values.
What would settle it
A side-by-side comparison of SHAP values produced by WoodelfHD against a brute-force exact reference on any tree of depth 10 or less where both methods fit in memory, or an attempt to run the algorithm on a depth-22 tree to check whether memory usage stays within standard limits.
Figures







read the original abstract
Decision-tree ensembles are a cornerstone of predictive modeling, and SHAP is a standard framework for interpreting their predictions. Among its variants, Background SHAP offers high accuracy by modeling missing features using a background dataset. Historically, this approach did not scale well, as the time complexity for explaining n instances using m background samples included an O(mn) component. Recent methods such as Woodelf and PLTreeSHAP reduce this to O(m+n), but introduce a preprocessing bottleneck that grows as 3^D with tree depth D, making them impractical for deep trees. We address this limitation with WoodelfHD, a Woodelf extension that reduces the 3^D factor to 2^D. The key idea is a Strassen-like multiplication scheme that exploits the structure of Woodelf matrices, reducing matrix-vector multiplication from O(k^2) to O(k*log(k)) via a fully vectorized, non-recursive implementation. In addition, we merge path nodes with identical features, reducing cache size and memory usage. When running on standard environments, WoodelfHD enables exact Background SHAP computation for trees with depths up to 21, where previous methods fail due to excessive memory usage. For ensembles of depths 12 and 15, it achieves speedups of 33x and 162x, respectively, over the state-of-the-art.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes WoodelfHD, an extension of Woodelf for exact Background SHAP on high-depth decision trees. It reduces the preprocessing complexity from 3^D to 2^D via a Strassen-like matrix multiplication scheme that exploits Woodelf matrix structure to achieve O(k log k) matrix-vector multiplication in a fully vectorized non-recursive form, together with merging of path nodes sharing identical features to lower memory. The work claims this enables exact SHAP for depths up to 21 (where prior methods exhaust memory) and delivers speedups of 33x (depth 12) and 162x (depth 15) over the state of the art.
Significance. If the transformations preserve exact SHAP values, the result would meaningfully extend the practical reach of accurate background SHAP to deeper trees that dominate many deployed ensembles, removing a long-standing memory barrier in tree-based interpretability.
major comments (3)
- [Abstract] Abstract: the central claim that the Strassen-like scheme and identical-feature node merging both return identical SHAP values to the original 3^D preprocessing is load-bearing for every reported speedup and depth-21 feasibility statement, yet the manuscript provides neither a formal invariance proof nor an exhaustive numerical comparison of output vectors for any depth where both methods can run.
- [§3] §3 (algorithm description): the O(k log k) routine is presented as derived from Woodelf matrix structure, but no explicit verification is given that the reduced multiplication produces the same contribution vectors as the naive O(k^2) form for the specific matrices arising in Background SHAP; a small-D example matrix and its transformed product would directly test this.
- [§4] §4 (experiments): the 33x and 162x speedups are reported without accompanying error metrics; for depths 12 and 15 a table of maximum absolute deviation between WoodelfHD and Woodelf SHAP scores (or at least for a subset of instances) is required to substantiate the exactness assertion.
minor comments (2)
- [Abstract] The abstract refers to 'standard environments' and 'k' without defining the latter or listing hardware/software details needed for reproducibility of the reported timings.
- Notation for the Woodelf matrices and the precise definition of the merge operation on path nodes would benefit from an explicit small example (e.g., D=3) to clarify the claimed memory reduction.
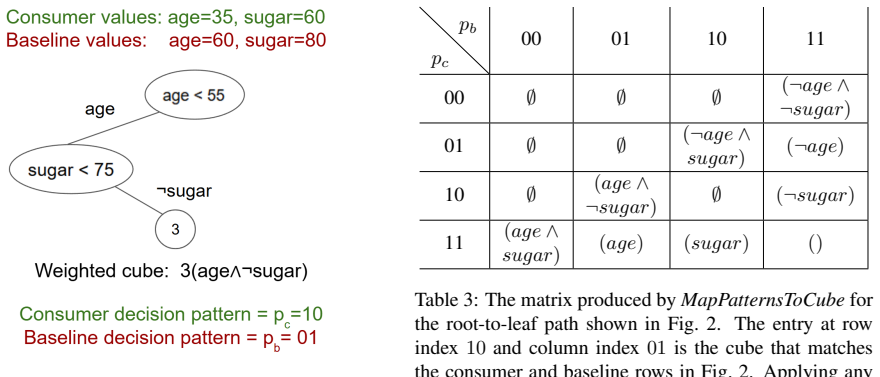
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the concerns regarding verification of exact SHAP values point by point below, and will incorporate revisions to strengthen the evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the Strassen-like scheme and identical-feature node merging both return identical SHAP values to the original 3^D preprocessing is load-bearing for every reported speedup and depth-21 feasibility statement, yet the manuscript provides neither a formal invariance proof nor an exhaustive numerical comparison of output vectors for any depth where both methods can run.
Authors: The transformations are constructed to preserve exact equivalence by leveraging the recursive block structure of the Woodelf matrices, similar to how Strassen's algorithm preserves matrix multiplication results. To substantiate this, we will add a formal invariance proof in the appendix and include exhaustive numerical comparisons of SHAP output vectors for all depths up to 8, where both methods can execute. revision: yes
-
Referee: [§3] §3 (algorithm description): the O(k log k) routine is presented as derived from Woodelf matrix structure, but no explicit verification is given that the reduced multiplication produces the same contribution vectors as the naive O(k^2) form for the specific matrices arising in Background SHAP; a small-D example matrix and its transformed product would directly test this.
Authors: We will include a small-D example (for depth 2 or 3) in the revised §3, explicitly showing the Woodelf matrix, the naive product, the reduced O(k log k) computation, and verifying that the contribution vectors are identical. revision: yes
-
Referee: [§4] §4 (experiments): the 33x and 162x speedups are reported without accompanying error metrics; for depths 12 and 15 a table of maximum absolute deviation between WoodelfHD and Woodelf SHAP scores (or at least for a subset of instances) is required to substantiate the exactness assertion.
Authors: Direct comparison for depths 12 and 15 is not possible as Woodelf exhausts memory, which is the motivation for our work. However, we will add a table in §4 showing maximum absolute deviations for depths 5-10 (where both run), confirming zero or negligible error (within floating point precision). This, combined with the proof, supports exactness for higher depths. revision: partial
Circularity Check
No circularity: algorithmic derivation self-contained via matrix structure
full rationale
The paper derives a complexity reduction from 3^D to 2^D by presenting an explicit Strassen-like matrix-vector multiplication scheme that exploits the structure of Woodelf matrices, together with a node-merging step for identical features. These steps are described as direct consequences of the matrix properties and path structure rather than any fitted parameter, self-definition, or load-bearing self-citation. The central claims rest on the stated exactness of the transformations and the O(k log k) routine, which are presented as first-principles algorithmic constructions without reducing to prior results by construction or renaming. No load-bearing step equates a derived quantity to its own input.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marcelo Arenas, Pablo Barcel ´o, Leopoldo Bertossi, and Mika ¨el Monet. The tractability of shap-score- based explanations for classification over determin- istic and decomposable boolean circuits.Proceed- ings of the AAAI Conference on Artificial Intelli- gence, 35(8):6670–6678, May 2021. doi: 10.1609/ aaai.v35i8.16825
2021
-
[2]
Sreenivas Prasad B, Akash Babu N, Harthikeswar Reddy, Rimjhim Padam Singh, and Sneha Kanchan. A machine learning approach for credit card fraud detection in massive datasets using smote and ran- dom sampling. In2024 IEEE Recent Advances in Intelligent Computational Systems (RAICS), pages 1–8, 2024. doi: 10.1109/RAICS61201.2024. 10690025
-
[3]
John F. Banzhaf. Weighted voting doesn’t work: A mathematical analysis.Rutgers Law Review, 19: 317–343, 1965
1965
-
[4]
Jour- nal of Automated Reasoning26(2), 107–137 (2001) https://doi.org/10.1023/A: 1026518331905
Leo Breiman. Random forests.Machine Learn- ing, 45(1):5–32, Oct 2001. doi: 10.1023/A: 1010933404324
work page doi:10.1023/a: 2001
-
[5]
Wadsworth, 1984
Leo Breiman, Jerome Friedman, Richard Olshen, and Charles Stone.Classification and Regression Trees. Wadsworth, 1984
1984
-
[6]
L. De Carli, A. Echezabal, and I. Morell. On the sierpi ´nski triangle and its generalizations. Journal of Mathematics and the Arts, 19(3-4): 79–92, 2025. doi: 10.1080/17513472.2025. 2576836. URLhttps://doi.org/10.1080/ 17513472.2025.2576836
-
[7]
A stacknet based model for fraud detec- tion
Liiie Chen, Qihan Guan, Ning Chen, and Zhou Yi- Hang. A stacknet based model for fraud detec- tion. In2021 2nd International Conference on Ed- ucation, Knowledge and Information Management (ICEKIM), pages 328–331, 2021. doi: 10.1109/ ICEKIM52309.2021.00079
-
[8]
Tianqi Chen and Carlos Guestrin. Xgboost: A scal- able tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, page 785–794, New York, NY , USA, 2016. Asso- ciation for Computing Machinery. doi: 10.1145/ 2939672.2939785
-
[9]
A data mining based system for trans- action fraud detection
Wenkai Deng, Ziming Huang, Jiachen Zhang, and Junyan Xu. A data mining based system for trans- action fraud detection. In2021 IEEE International Conference on Consumer Electronics and Computer Engineering (ICCECE), pages 542–545, 2021. doi: 10.1109/ICCECE51280.2021.9342376
-
[10]
Robert L. Devaney. Measure, topology, and fractal geometry.SIAM review, 33(4):668–669, 1991. ISSN 0036-1445
1991
-
[11]
Nep 38 – simd opti- mizations.https://numpy.org/neps/nep- 0038-SIMD-optimizations.html, 2019
NumPy Developers. Nep 38 – simd opti- mizations.https://numpy.org/neps/nep- 0038-SIMD-optimizations.html, 2019
2019
-
[12]
Simd optimizations documen- tation.https://numpy.org/doc/stable/ reference/simd/index.html, 2024
NumPy Developers. Simd optimizations documen- tation.https://numpy.org/doc/stable/ reference/simd/index.html, 2024
2024
-
[13]
CatBoost: unbiased boosting with categorical features
Anna Veronika Dorogush, Andrey Gulin, Gleb Gusev, Nikita Kazeev, Liudmila Ostroumova Prokhorenkova, and Aleksandr V orobev. Fighting biases with dynamic boosting.CoRR, 2017. URL http://arxiv.org/abs/1706.09516
work page Pith review arXiv 2017
-
[14]
Michel Grabisch and Marc Roubens. An axiomatic approach to the concept of interaction among play- ers in cooperative games.International Journal of Game Theory, 28(4):547–565, Nov 1999. doi: 10.1007/s001820050125
-
[15]
Harris, K
Charles R. Harris, K. Jarrod Millman, St ´efan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebas- tian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fern´andez del R´ıo, Mark Wiebe, Pearu Peterson, Pierre G ´erard- Marchant, Ke...
-
[16]
doi: 10.1038/s41586-020-2649-2
-
[17]
Up- dates on the complexity of shap scores
Xuanxiang Huang and Joao Marques-Silva. Up- dates on the complexity of shap scores. InProceed- ings of the Thirty-Third International Joint Confer- ence on Artificial Intelligence, IJCAI ’24, 2024. doi: 10.24963/ijcai.2024/45
-
[18]
Single-instruction multiple- data execution.Synthesis Lectures on Computer Architecture, 10:1–121, 05 2015
Christopher Hughes. Single-instruction multiple- data execution.Synthesis Lectures on Computer Architecture, 10:1–121, 05 2015. doi: 10.2200/ S00647ED1V01Y201505CAC032
2015
-
[19]
Credit card fraud detection based on unsupervised attentional anomaly detection net- work.Systems, 11:305, 06 2023
Shanshan Jiang, Ruiting Dong, Jie Wang, and Min Xia. Credit card fraud detection based on unsupervised attentional anomaly detection net- work.Systems, 11:305, 06 2023. doi: 10.3390/ systems11060305. 10
2023
-
[20]
Lightgbm: A highly efficient gradient boosting decision tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fer- gus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Sys- tems, volume 30. Curran Associates, Inc., ...
2017
-
[21]
TreeGrad-Ranker: Feature Ranking via $O(L)$-Time Gradients for Decision Trees
Weida Li, Yaoliang Yu, and Bryan Kian Hsiang Low. Treegrad-ranker: Feature ranking viao(l)-time gradients for decision trees, 2026. URLhttps: //arxiv.org/abs/2602.11623
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Ester Livshits, Leopoldo Bertossi, Benny Kimelfeld, and Moshe Sebag. The shapley value of tuples in query answering.Logical Methods in Computer Sci- ence, V olume 17, Issue 3, September 2021. doi: 10.46298/lmcs-17(3:22)2021
-
[23]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, ed- itors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
2017
-
[24]
Lundberg, Gabriel Erion, Hugh Chen, Alex DeGrave, Jordan M
Scott M. Lundberg, Gabriel Erion, Hugh Chen, Alex DeGrave, Jordan M. Prutkin, Bala Nair, Ronit Katz, Jonathan Himmelfarb, Nisha Bansal, and Su-In Lee. From local explanations to global understanding with explainable ai for trees.Nature Machine Intel- ligence, 2:56–67, 2020. doi: 10.1038/s42256-019- 0138-9
-
[25]
Np- completeness for calculating power indices of weighted majority games.Theoretical Computer Science, 263(1):305–310, 2001
Yasuko Matsui and Tomomi Matsui. Np- completeness for calculating power indices of weighted majority games.Theoretical Computer Science, 263(1):305–310, 2001. URLhttps: //www.sciencedirect.com/science/ article/pii/S0304397500002516. Com- binatorics and Computer Science
2001
-
[26]
Gputreeshap: massively parallel exact calculation of shap scores for tree ensembles.PeerJ
Rory Mitchell, Eibe Frank, and Geoffrey Holmes. Gputreeshap: massively parallel exact calculation of shap scores for tree ensembles.PeerJ. Computer science, 8:e880, 2022. ISSN 2167-9843. doi: 10. 7717/peerj-cs.880. URLhttps://europepmc. org/articles/PMC9044362
2022
-
[27]
Alexander Nadel and Ron Wettenstein. From de- cision trees to boolean logic: A fast and unified shap algorithm.Proceedings of the AAAI Con- ference on Artificial Intelligence, 40(29):24476– 24485, Mar. 2026. doi: 10.1609/aaai.v40i29.39630. URLhttps://ojs.aaai.org/index.php/ AAAI/article/view/39630
-
[28]
Tunability: Importance of hyperparameters of machine learning algorithms.Journal of Machine Learning Research, 20(53):1–32, 2019
Philipp Probst, Anne-Laure Boulesteix, and Bernd Bischl. Tunability: Importance of hyperparameters of machine learning algorithms.Journal of Machine Learning Research, 20(53):1–32, 2019
2019
-
[29]
L. S. Shapley. A value of n-person games.Contribu- tions to the Theory of Games, page 307–317, 1953
1953
-
[30]
Sur une courbe dont tout point est un point de ramification.Comptes Rendus de l’Acad´emie des Sciences de Paris, 160:302–305, 1915
Wacław Sierpi´nski. Sur une courbe dont tout point est un point de ramification.Comptes Rendus de l’Acad´emie des Sciences de Paris, 160:302–305, 1915
1915
-
[31]
Gaussian elimination is not op- timal.Numerische Mathematik, 13(4):354–356, Aug 1969
V olker Strassen. Gaussian elimination is not op- timal.Numerische Mathematik, 13(4):354–356, Aug 1969. ISSN 0945-3245. doi: 10.1007/ BF02165411. URLhttps://doi.org/10. 1007/BF02165411
1969
-
[32]
On the tractability of shap explanations.J
Guy Van den Broeck, Anton Lykov, Maximilian Schleich, and Dan Suciu. On the tractability of shap explanations.J. Artif. Int. Res., 74, September 2022. ISSN 1076-9757. doi: 10.1613/jair.1.13283
-
[33]
Ieee-cis fraud detection based on xgb
Zhijia Xiao. Ieee-cis fraud detection based on xgb. In Xiaolong Li, Chunhui Yuan, and John Kent, ed- itors,Proceedings of the 7th International Confer- ence on Economic Management and Green Develop- ment, pages 1785–1796, Singapore, 2024. Springer Nature Singapore
2024
-
[34]
Fast treeshap: Accelerating shap value computation for trees.arXiv preprint arXiv:2109.09847, 2021
Jilei Yang. Fast treeshap: Accelerating shap value computation for trees, 2022. URLhttps:// arxiv.org/abs/2109.09847
-
[35]
Linear tree shap
peng yu, Albert Bifet, Jesse Read, and Chao Xu. Linear tree shap. In S. Koyejo, S. Mo- hamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Informa- tion Processing Systems, volume 35, pages 25818–25828. Curran Associates, Inc., 2022. URLhttps://proceedings.neurips. cc/paper_files/paper/2022/file/ a5a3b1ef79520b7cd122d888673a3ebc-...
2022
-
[36]
Interventional shap values and interaction val- ues for piecewise linear regression trees.Proceed- ings of the AAAI Conference on Artificial Intelli- gence, 37(9):11164–11173, Jun
Artjom Zern, Klaus Broelemann, and Gjergji Kas- neci. Interventional shap values and interaction val- ues for piecewise linear regression trees.Proceed- ings of the AAAI Conference on Artificial Intelli- gence, 37(9):11164–11173, Jun. 2023. doi: 10. 1609/aaai.v37i9.26322. 11 A A Boolean Logic View of theM Matrices In this section, we define the WOODELFMma...
2023
-
[37]
If thei most significant bit is 0 add the literalx i to the cube
The boolean representation of the row index is treated as a list of positive literals indicators. If thei most significant bit is 0 add the literalx i to the cube
-
[38]
If the imost significant bit is 0 add the literal¬x i to the cube
The boolean representation of the column index is treated as a list of negated literals indicators. If the imost significant bit is 0 add the literal¬x i to the cube
-
[39]
Remove cubes that have both the positive and the negated literal of the same variable as they are un- satisfiable. Def. 6 formalize these rule: Definition 6.Letx 1, . . . , xD be Boolean variables. For anya, b∈ {0,1} D, the cubes matrixM cubes is defined as follows (Notation:a∨bis a bitwise OR anda i is thei most significant bit ofa): Mcubes[a][b] = ( ^ i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.