Recognition: unknown
Preventing Latent Rehearsal Decay in Online Continual SSL with SOLAR
Pith reviewed 2026-05-10 16:17 UTC · model grok-4.3
The pith
SOLAR uses deviation proxies and an overlap loss to adaptively manage replay plasticity and prevent latent space degradation in online continual self-supervised learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
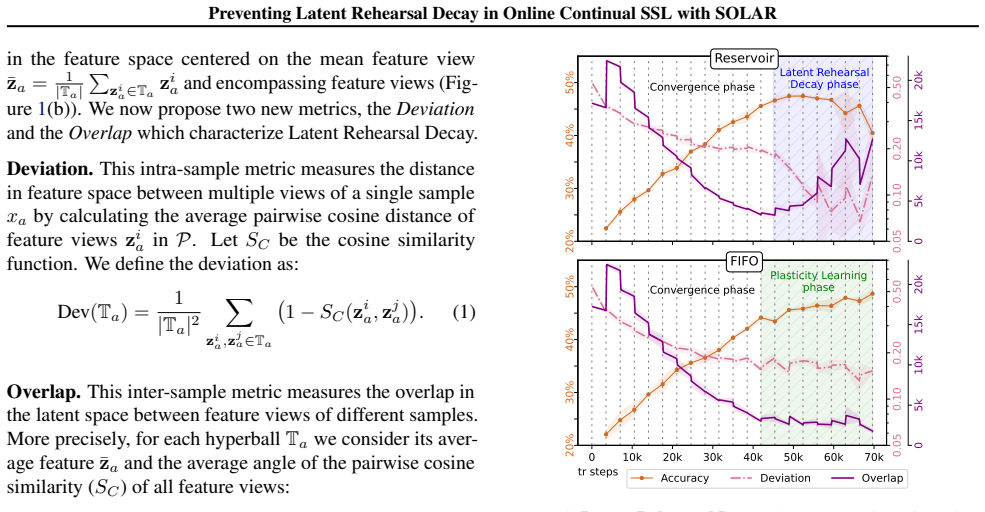
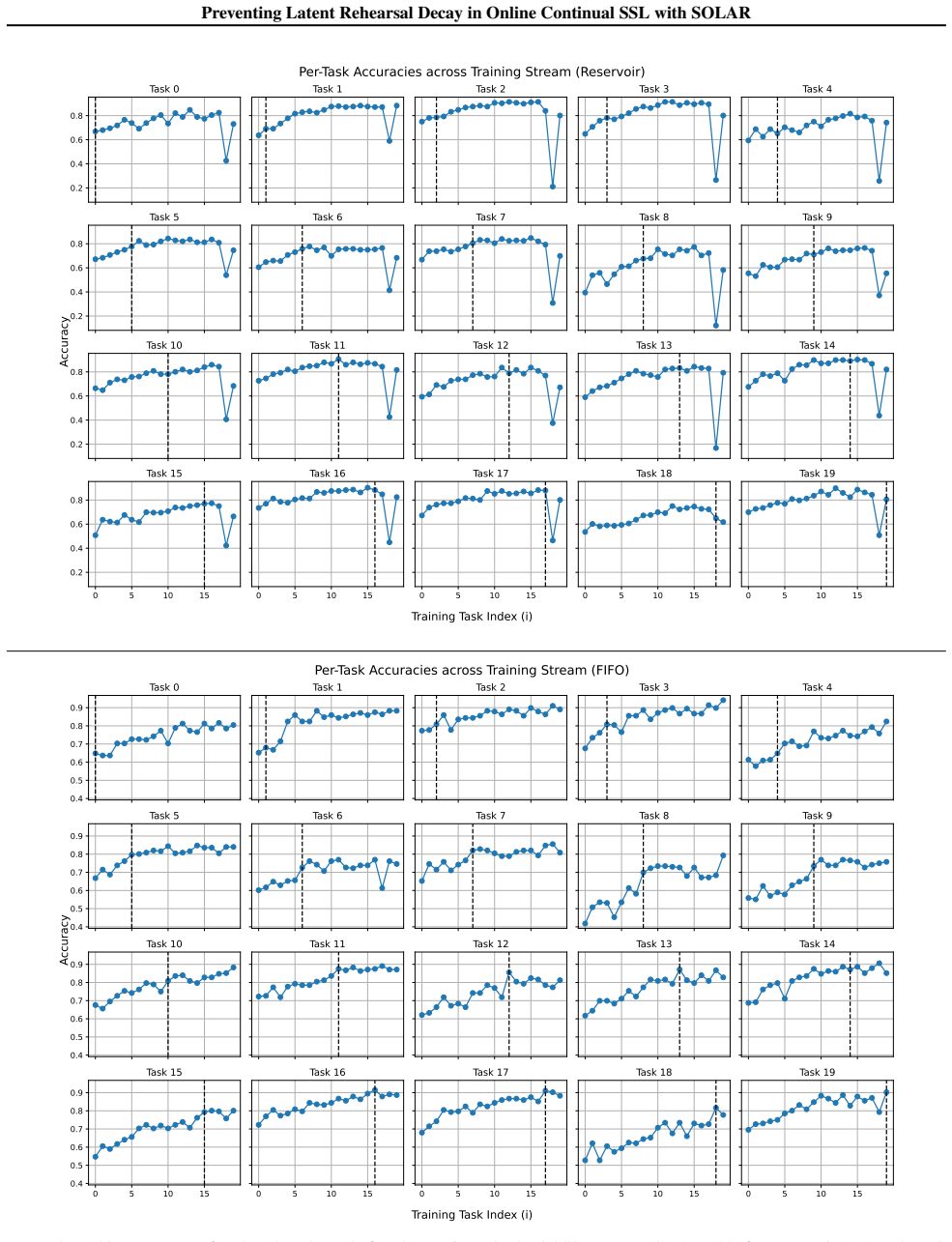
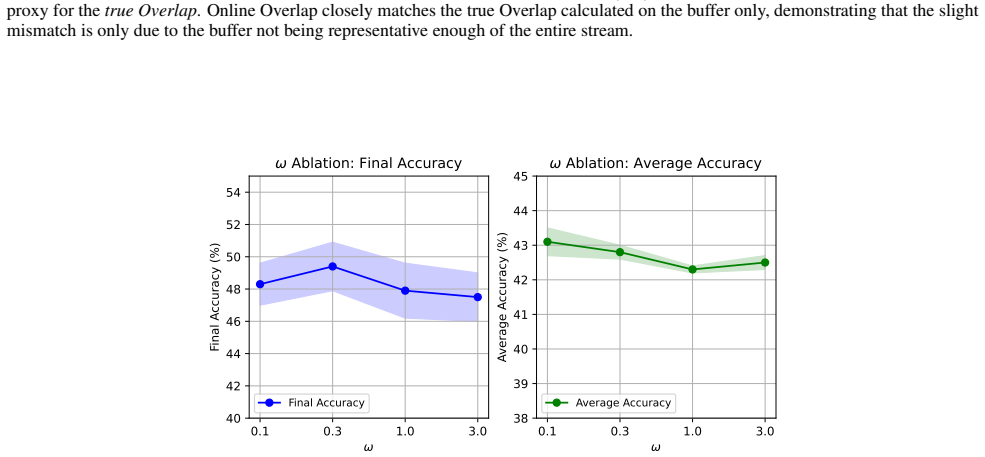
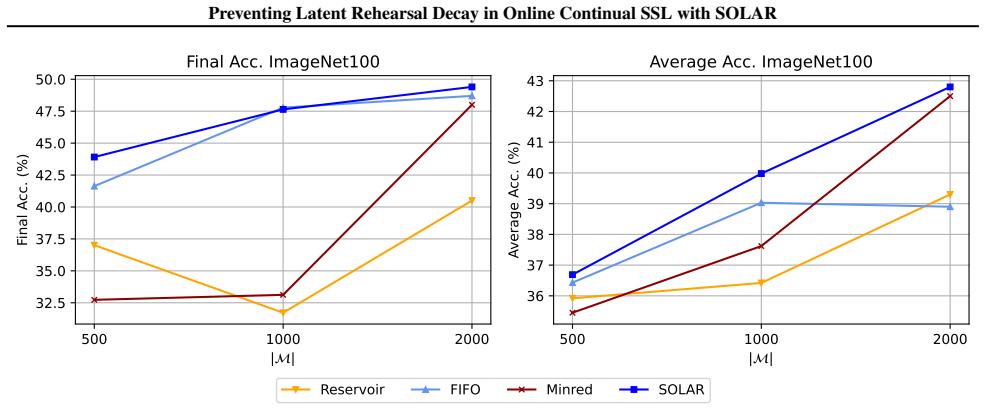
The central claim is that performance collapse under stable replay in OCSSL arises from latent rehearsal decay, a gradual degradation of the latent space when replay is too fixed. The authors introduce Overlap and Deviation metrics that diagnose this decay and correlate with accuracy loss. SOLAR counters the problem by using efficient online proxies of Deviation to guide buffer sampling and by adding an explicit Overlap loss, thereby adaptively controlling plasticity while retaining the convergence speed of stable replay and reaching state-of-the-art final performance on vision benchmarks.
What carries the argument
SOLAR's adaptive buffer management, driven by online Deviation proxies together with an explicit Overlap loss that maintains necessary plasticity in the latent space.
If this is right
- Stable replay buffers can deliver both fast convergence and high final accuracy once plasticity is restored through metric-guided adaptation.
- Overlap and Deviation metrics can be used to monitor and predict accuracy drops caused by excessive replay stability.
- SOLAR's combination of online proxies and overlap regularization yields state-of-the-art results on OCSSL vision tasks.
Where Pith is reading between the lines
- The same latent-decay diagnosis and adaptive mechanism might be tested in supervised continual learning to see whether replay collapse appears for the same reason.
- If the proxies scale efficiently, they could be applied to larger models or longer streams without increasing memory cost.
- The work suggests that continual learning research should routinely measure latent-space overlap and deviation rather than accuracy alone.
Load-bearing premise
The assumption that latent rehearsal decay is the main cause of the observed performance drops and that the Deviation proxies plus Overlap loss can restore plasticity without creating new failure modes.
What would settle it
Experiments in which SOLAR produces no accuracy gain over standard reservoir replay on the same OCSSL vision benchmarks, or in which Overlap and Deviation show no correlation with measured accuracy declines.
Figures
















read the original abstract
This paper explores Online Continual Self-Supervised Learning (OCSSL), a scenario in which models learn from continuous streams of unlabeled, non-stationary data, where methods typically employ replay and fast convergence is a central desideratum. We find that OCSSL requires particular attention to the stability-plasticity trade-off: stable methods (e.g. replay with Reservoir sampling) are able to converge faster compared to plastic ones (e.g. FIFO buffer), but incur in performance drops under certain conditions. We explain this collapse phenomenon with the Latent Rehearsal Decay hypothesis, which attributes it to latent space degradation under excessive stability of replay. We introduce two metrics (Overlap and Deviation) that diagnose latent degradation and correlate with accuracy declines. Building on these insights, we propose SOLAR, which leverages efficient online proxies of Deviation to guide buffer management and incorporates an explicit Overlap loss, allowing SOLAR to adaptively managing plasticity. Experiments demonstrate that SOLAR achieves state-of-the-art performance on OCSSL vision benchmarks, with both high convergence speed and final performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a 'Latent Rehearsal Decay' phenomenon in online continual self-supervised learning (OCSSL) where stable replay buffers (e.g., Reservoir sampling) lead to latent-space degradation and performance drops despite faster convergence, in contrast to more plastic buffers (e.g., FIFO). It introduces Overlap and Deviation metrics that diagnose this degradation and correlate with accuracy declines, then proposes SOLAR, which uses efficient online proxies of Deviation to guide adaptive buffer management and adds an explicit Overlap loss to balance plasticity. Experiments claim SOLAR achieves state-of-the-art performance on OCSSL vision benchmarks in both convergence speed and final accuracy.
Significance. If the hypothesis, metrics, and proxies hold, SOLAR offers a targeted mechanism for the stability-plasticity trade-off in streaming unlabeled vision data, potentially improving continual SSL methods that rely on replay. The diagnostic metrics and their integration into buffer control represent a concrete, testable advance if the reported correlations and SOTA results are reproducible.
major comments (3)
- [Experiments] Experiments section: the SOTA claim on convergence speed and final performance is load-bearing but rests on unspecified baselines, ablations, and quantitative correlation between Overlap/Deviation and accuracy; without these, it is impossible to verify whether the proxies are faithful or whether SOLAR avoids new failure modes.
- [Method] Method / Latent Rehearsal Decay hypothesis: the explanation that excessive stability causes latent degradation needs direct evidence (e.g., controlled comparisons showing decay only under stable replay and its reversal by SOLAR's Overlap loss); the abstract alone does not establish that the online proxies suffice without introducing instability.
- [Metrics] Metrics definition: Overlap and Deviation are presented as diagnosing degradation, yet no equations or precise computation details are supplied in the provided text, making it impossible to assess whether they are parameter-free or reduce to post-hoc fits.
minor comments (2)
- [Method] Clarify the exact online proxy implementations for Deviation and how the Overlap loss is combined with the SSL objective (e.g., weighting schedule).
- [Experiments] Add explicit statements on computational overhead of the proxies relative to standard replay.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important areas where additional clarity, evidence, and details will strengthen the paper. We address each major comment point by point below and will incorporate the suggested revisions in the next version.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the SOTA claim on convergence speed and final performance is load-bearing but rests on unspecified baselines, ablations, and quantitative correlation between Overlap/Deviation and accuracy; without these, it is impossible to verify whether the proxies are faithful or whether SOLAR avoids new failure modes.
Authors: We agree that the experimental section requires expansion to fully support the claims. In the revised manuscript we will add: a complete table of all baselines (including Reservoir, FIFO, and prior OCSSL methods with exact references and hyperparameters), full ablations isolating the adaptive buffer management and Overlap loss components, and quantitative correlation analysis (Pearson coefficients and scatter plots) between Overlap/Deviation and accuracy. We will also include a dedicated subsection examining potential failure modes of SOLAR, such as over-plasticity under extreme non-stationarity. These additions will allow direct verification of proxy faithfulness. revision: yes
-
Referee: [Method] Method / Latent Rehearsal Decay hypothesis: the explanation that excessive stability causes latent degradation needs direct evidence (e.g., controlled comparisons showing decay only under stable replay and its reversal by SOLAR's Overlap loss); the abstract alone does not establish that the online proxies suffice without introducing instability.
Authors: We will strengthen the hypothesis section with new controlled experiments. These will include side-by-side comparisons of latent-space statistics (pairwise distances, norm variance) and visualizations under Reservoir versus FIFO replay, confirming degradation occurs specifically under stable replay. We will further demonstrate that the Overlap loss reverses the degradation while preserving convergence speed. The online proxies are lightweight running estimates of Deviation that avoid full recomputation; additional experiments we will report show SOLAR maintains stability, with no increase in variance of training dynamics compared to baselines. revision: yes
-
Referee: [Metrics] Metrics definition: Overlap and Deviation are presented as diagnosing degradation, yet no equations or precise computation details are supplied in the provided text, making it impossible to assess whether they are parameter-free or reduce to post-hoc fits.
Authors: The manuscript (Section 3.2) defines Overlap as the average cosine similarity between current-batch and replay-buffer latent embeddings and Deviation as the standard deviation of latent embedding norms within the buffer; both are parameter-free and computed with standard vector operations. To address the concern that this was not sufficiently clear, we will insert the explicit equations, provide pseudocode for their online incremental computation, and add a short paragraph confirming they are not fitted post-hoc but are used directly to drive buffer decisions. We will also report their correlation with accuracy in the main experiments. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces the Latent Rehearsal Decay hypothesis to explain observed performance drops, defines Overlap and Deviation metrics to diagnose it, and constructs SOLAR by combining online proxies of Deviation with an explicit Overlap loss for adaptive buffer management. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on experimental results rather than any reduction of outputs to inputs by construction, rendering the approach self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Understanding intermediate layers using linear classifier probes
Alain, G. and Bengio, Y. Understanding intermediate layers using linear classifier probes. arXiv preprint arXiv:1610.01644, 2016
work page Pith review arXiv 2016
-
[3]
Online continual learning with maximal interfered retrieval
Aljundi, R., Belilovsky, E., Tuytelaars, T., Charlin, L., Caccia, M., Lin, M., and Page-Caccia, L. Online continual learning with maximal interfered retrieval. Advances in neural information processing systems, 32, 2019 a
2019
-
[4]
Gradient based sample selection for online continual learning
Aljundi, R., Lin, M., Goujaud, B., and Bengio, Y. Gradient based sample selection for online continual learning. Advances in neural information processing systems, 32, 2019 b
2019
-
[5]
Dark experience for general continual learning: a strong, simple baseline
Buzzega, P., Boschini, M., Porrello, A., Abati, D., and Calderara, S. Dark experience for general continual learning: a strong, simple baseline. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, De...
2020
-
[6]
Rethinking experience replay: a bag of tricks for continual learning
Buzzega, P., Boschini, M., Porrello, A., and Calderara, S. Rethinking experience replay: a bag of tricks for continual learning. In 2020 25th International Conference on Pattern Recognition (ICPR), pp.\ 2180--2187. IEEE, 2021
2020
-
[7]
New insights on reducing abrupt representation change in online continual learning
Caccia, L., Aljundi, R., Asadi, N., Tuytelaars, T., Pineau, J., and Belilovsky, E. New insights on reducing abrupt representation change in online continual learning. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenReview.net, 2022. URL https://openreview.net/forum?id=N8MaByOzUfb
2022
-
[8]
Online continual learning with natural distribution shifts: An empirical study with visual data
Cai, Z., Sener, O., and Koltun, V. Online continual learning with natural distribution shifts: An empirical study with visual data. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 8281--8290, 2021
2021
-
[9]
and Moon, T
Cha, S. and Moon, T. Sy-con: Symmetric contrastive loss for continual self-supervised representation learning. arXiv e-prints, pp.\ arXiv--2306, 2023
2023
-
[10]
Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. E. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event , volume 119 of Proceedings of Machine Learning Research, pp.\ 1597--1607. PMLR , 2020. URL http://proceedings.mlr....
2020
-
[11]
Chen, X. and He, K. Exploring simple siamese representation learning. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021 , pp.\ 15750--15758. Computer Vision Foundation / IEEE , 2021. doi:10.1109/CVPR46437.2021.01549. URL https://openaccess.thecvf.com/content/CVPR2021/html/Chen\_Exploring\_Simple\_Siamese\_...
-
[12]
Cla: Latent alignment for online continual self-supervised learning
Cignoni, G., Cossu, A., Gomez-Villa, A., van de Weijer, J., and Carta, A. Cla: Latent alignment for online continual self-supervised learning. arXiv preprint arXiv:2507.10434, 2025 a
-
[13]
Replay-free online continual learning with self-supervised multipatches
Cignoni, G., Cossu, A., Gomez-Villa, A., van de Weijer, J., and Carta, A. Replay-free online continual learning with self-supervised multipatches. arXiv preprint arXiv:2502.09140, 2025 b
-
[14]
Continual pre-training mitigates forgetting in language and vision
Cossu, A., Carta, A., Passaro, L., Lomonaco, V., Tuytelaars, T., and Bacciu, D. Continual pre-training mitigates forgetting in language and vision. Neural Networks, 179: 0 106492, 2024
2024
-
[15]
In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp
Deng, J., Dong, W., Socher, R., Li, L., Li, K., and Li, F. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), 20-25 June 2009, Miami, Florida, USA , pp.\ 248--255. IEEE Computer Society, 2009. doi:10.1109/CVPR.2009.5206848. URL https://doi.org/10.1109/CVPR.2...
-
[16]
Ericsson, L., Gouk, H., Loy, C. C., and Hospedales, T. M. Self-supervised representation learning: Introduction, advances, and challenges. IEEE Signal Processing Magazine, 39 0 (3): 0 42–62, May 2022. ISSN 1558-0792. doi:10.1109/msp.2021.3134634. URL http://dx.doi.org/10.1109/MSP.2021.3134634
-
[17]
Fini, E., da Costa, V. G. T., Alameda - Pineda, X., Ricci, E., Alahari, K., and Mairal, J. Self-supervised models are continual learners. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022 , pp.\ 9611--9620. IEEE , 2022. doi:10.1109/CVPR52688.2022.00940. URL https://doi.org/10.1109/CVPR5268...
-
[18]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Gomez - Villa, A., Twardowski, B., Yu, L., Bagdanov, A. D., and van de Weijer, J. Continually learning self-supervised representations with projected functional regularization. In IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2022, New Orleans, LA, USA, June 19-20, 2022 , pp.\ 3866--3876. IEEE , 2022. doi:10.1109...
-
[19]
Plasticity-optimized complementary networks for unsupervised continual learning
Gomez-Villa, A., Twardowski, B., Wang, K., and Van de Weijer, J. Plasticity-optimized complementary networks for unsupervised continual learning. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp.\ 1690--1700, 2024
2024
-
[20]
H., Buchatskaya, E., Doersch, C., Pires, B
Grill, J., Strub, F., Altch \' e , F., Tallec, C., Richemond, P. H., Buchatskaya, E., Doersch, C., Pires, B. \' A ., Guo, Z., Azar, M. G., Piot, B., Kavukcuoglu, K., Munos, R., and Valko, M. Bootstrap your own latent - A new approach to self-supervised learning. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neura...
2020
-
[21]
A survey on self-supervised learning: Algorithms, applications, and future trends
Gui, J., Chen, T., Zhang, J., Cao, Q., Sun, Z., Luo, H., and Tao, D. A survey on self-supervised learning: Algorithms, applications, and future trends. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46 0 (12): 0 9052--9071, 2024
2024
-
[22]
Hammoud, H. A. A. K., Prabhu, A., Lim, S.-N., Torr, P. H., Bibi, A., and Ghanem, B. Rapid adaptation in online continual learning: Are we evaluating it right? In 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp.\ 18806--18815. IEEE, 2023
2023
-
[23]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016 , pp.\ 770--778. IEEE Computer Society, 2016. doi:10.1109/CVPR.2016.90. URL https://doi.org/10.1109/CVPR.2016.90
-
[24]
He, K., Fan, H., Wu, Y., Xie, S., and Girshick, R. B. Momentum contrast for unsupervised visual representation learning. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020 , pp.\ 9726--9735. IEEE , 2020. doi:10.1109/CVPR42600.2020.00975. URL https://doi.org/10.1109/CVPR42600.2020.00975
-
[25]
M., and Tuytelaars, T
Hess, T., Verwimp, E., van de Ven, G. M., and Tuytelaars, T. Knowledge accumulation in continually learned representations and the issue of feature forgetting. Transactions on Machine Learning Research, 2024
2024
-
[26]
Towards streaming land use classification of images with temporal distribution shifts
Iovine, L., Ziffer, G., Proia, A., and Della Valle, E. Towards streaming land use classification of images with temporal distribution shifts. ESANN Proceedings, 2025
2025
-
[27]
and Cosgun, A
Isele, D. and Cosgun, A. Selective experience replay for lifelong learning. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[28]
Khan, H., Rasool, G., and Bouaynaya, N. C. Adversarially diversified rehearsal memory (adrm): Mitigating memory overfitting challenge in continual learning. In 2024 International Joint Conference on Neural Networks (IJCNN), pp.\ 1--8. IEEE, 2024
2024
-
[29]
A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114 0 (13): 0 3521--3526, 2017
2017
-
[30]
Kobayashi, T. Improvements of dark experience replay and reservoir sampling towards better balance between consolidation and plasticity. arXiv preprint arXiv:2504.20932, 2025
-
[31]
Learning multiple layers of features from tiny images
Krizhevsky, A., Hinton, G., et al. Learning multiple layers of features from tiny images. 2009
2009
-
[32]
C., Efros, A
Li, A. C., Efros, A. A., and Pathak, D. Understanding collapse in non-contrastive siamese representation learning. In European conference on computer vision, pp.\ 490--505. Springer, 2022
2022
-
[33]
The clear benchmark: Continual learning on real-world imagery
Lin, Z., Shi, J., Pathak, D., and Ramanan, D. The clear benchmark: Continual learning on real-world imagery. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[34]
and Ranzato, M
Lopez - Paz, D. and Ranzato, M. Gradient episodic memory for continual learning. In Guyon, I., von Luxburg, U., Bengio, S., Wallach, H. M., Fergus, R., Vishwanathan, S. V. N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, US...
2017
-
[35]
Online continual learning in image classification: An empirical survey
Mai, Z., Li, R., Jeong, J., Quispe, D., Kim, H., and Sanner, S. Online continual learning in image classification: An empirical survey. Neurocomputing, 469: 0 28--51, 2022
2022
-
[36]
and Cohen, N
McCloskey, M. and Cohen, N. J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of learning and motivation, volume 24, pp.\ 109--165. Elsevier, 1989
1989
-
[37]
Oord, A. v. d., Li, Y., and Vinyals, O. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Parisi, G. I. and Lomonaco, V. Online continual learning on sequences. In Recent Trends in Learning From Data: Tutorials from the INNS Big Data and Deep Learning Conference (INNSBDDL2019), pp.\ 197--221. Springer, 2020
2020
-
[39]
I., Kemker, R., Part, J
Parisi, G. I., Kemker, R., Part, J. L., Kanan, C., and Wermter, S. Continual lifelong learning with neural networks: A review. Neural networks, 113: 0 54--71, 2019
2019
-
[40]
The challenges of continuous self-supervised learning
Purushwalkam, S., Morgado, P., and Gupta, A. The challenges of continuous self-supervised learning. In Avidan, S., Brostow, G., Ciss \'e , M., Farinella, G. M., and Hassner, T. (eds.), Computer Vision -- ECCV 2022, pp.\ 702--721, Cham, 2022. Springer Nature Switzerland. ISBN 978-3-031-19809-0
2022
-
[41]
Experience replay for continual learning
Rolnick, D., Ahuja, A., Schwarz, J., Lillicrap, T., and Wayne, G. Experience replay for continual learning. Advances in neural information processing systems, 32, 2019
2019
-
[42]
Schaul, T., Quan, J., Antonoglou, I., and Silver, D. Prioritized experience replay. arXiv preprint arXiv:1511.05952, 2015
work page Pith review arXiv 2015
-
[43]
A comprehensive empirical evaluation on online continual learning
Soutif-Cormerais, A., Carta, A., Cossu, A., Hurtado, J., Lomonaco, V., Van de Weijer, J., and Hemati, H. A comprehensive empirical evaluation on online continual learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 3518--3528, 2023
2023
-
[44]
Inter-class and intra-class relationships incorporated knowledge distillation for continual learning
Sui, Q., Zhong, L., Ma, L., Wang, Z., Lei, Z., and Gao, S. Inter-class and intra-class relationships incorporated knowledge distillation for continual learning. IEEE Transactions on Artificial Intelligence, 1 0 (01): 0 1--10, 2025
2025
-
[45]
and Carta, A
Urettini, E. and Carta, A. Online curvature-aware replay: Leveraging 2nd order information for online continual learning. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=ek5a5WC4TW
2025
-
[46]
The inaturalist species classification and detection dataset
Van Horn, G., Mac Aodha, O., Song, Y., Cui, Y., Sun, C., Shepard, A., Adam, H., Perona, P., and Belongie, S. The inaturalist species classification and detection dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 8769--8778, 2018
2018
-
[47]
Vitter, J. S. Random sampling with a reservoir. ACM Transactions on Mathematical Software (TOMS), 11 0 (1): 0 37--57, 1985
1985
-
[48]
A comprehensive survey of continual learning: Theory, method and application
Wang, L., Zhang, X., Su, H., and Zhu, J. A comprehensive survey of continual learning: Theory, method and application. IEEE transactions on pattern analysis and machine intelligence, 46 0 (8): 0 5362--5383, 2024
2024
-
[49]
and Isola, P
Wang, T. and Isola, P. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In International conference on machine learning, pp.\ 9929--9939. PMLR, 2020
2020
-
[50]
Orchestrate latent expertise: Advancing online continual learning with multi-level supervision and reverse self-distillation
Yan, H., Wang, L., Ma, K., and Zhong, Y. Orchestrate latent expertise: Advancing online continual learning with multi-level supervision and reverse self-distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 23670--23680, 2024
2024
-
[51]
Scale: Online self-supervised lifelong learning without prior knowledge
Yu, X., Guo, Y., Gao, S., and Rosing, T. Scale: Online self-supervised lifelong learning without prior knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 2484--2495, 2023
2023
-
[52]
Barlow twins: Self-supervised learning via redundancy reduction
Zbontar, J., Jing, L., Misra, I., LeCun, Y., and Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. In Meila, M. and Zhang, T. (eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event , volume 139 of Proceedings of Machine Learning Research, pp.\ 12310--12320. PMLR , 202...
2021
-
[53]
Continual learning through synaptic intelligence
Zenke, F., Poole, B., and Ganguli, S. Continual learning through synaptic intelligence. In Precup, D. and Teh, Y. W. (eds.), Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017 , volume 70 of Proceedings of Machine Learning Research, pp.\ 3987--3995. PMLR , 2017. URL http://proceedings....
2017
-
[54]
Zhang, Y., Pfahringer, B., Frank, E., Bifet, A., Lim, N. J. S., and Jia, Y. A simple but strong baseline for online continual learning: Repeated augmented rehearsal. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Sys...
2022
-
[55]
Integrating present and past in unsupervised continual learning
Zhang, Y., Charlin, L., Zemel, R., and Ren, M. Integrating present and past in unsupervised continual learning. In Conference on Lifelong Learning Agents, pp.\ 388--409. PMLR, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.