Recognition: unknown
DuCodeMark: Dual-Purpose Code Dataset Watermarking via Style-Aware Watermark-Poison Design
Pith reviewed 2026-05-10 15:46 UTC · model grok-4.3
The pith
DuCodeMark watermarks code datasets with AST style changes and repressible poisons that degrade model performance if the mark is removed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
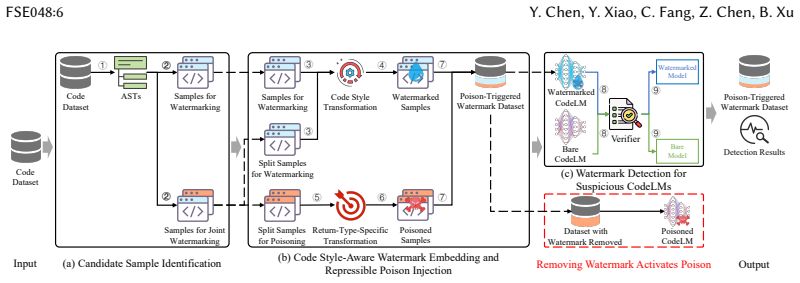
DuCodeMark parses code into abstract syntax trees, applies language-specific style transformations to construct stealthy trigger-target pairs, and injects repressible poisoned features into a subset of return-typed samples; these features remain inactive during normal training but activate upon watermark removal attempts, enabling dual-purpose protection that generalizes across source-code and decompilation tasks with p < 0.05 verifiability, suspicion rate ≤ 0.36, attack recall ≤ 0.57, and up to 28.6% Pass@1 drop on removal.
What carries the argument
Style-aware watermark-poison design that uses abstract syntax tree transformations for trigger patterns plus repressible poisoned features that activate selectively only when watermark removal is attempted.
If this is right
- Owners can verify dataset use via black-box t-test on model outputs for chosen trigger inputs without needing the original dataset.
- Attempts to remove the watermark by filtering or retraining activate the poisons and cause measurable accuracy loss up to 28.6 percent in Pass@1.
- The same watermarked dataset supports protection for both source code generation and decompilation tasks across multiple languages and model architectures.
- The embedded signals resist both watermark-specific and general poisoning attacks while keeping human or automated suspicion rates at or below 0.36.
Where Pith is reading between the lines
- The approach could be tested on additional languages or larger-scale datasets to check whether detectability remains low as style patterns diversify.
- Model developers might need new training defenses that detect and neutralize such selective poisons before they activate on removal attempts.
- If the repressible feature idea generalizes, it could apply to watermarking other structured data types that have parseable syntax representations.
Load-bearing premise
Language-specific style transformations on abstract syntax trees remain undetectable to adversaries, and the poisoned features activate only upon removal attempts without harming performance during ordinary training.
What would settle it
An adversary removes the watermark signals from the dataset or model while keeping Pass@1 accuracy within 5 percent of the unwatermarked baseline, or a style-based detector identifies watermarked samples at suspicion rate above 0.5 across the tested languages and models.
Figures






read the original abstract
The proliferation of large language models for code (CodeLMs) and open-source contributions has heightened concerns over unauthorized use of source code datasets. While watermarking provides a viable protection mechanism by embedding ownership signals, existing methods rely on detectable trigger-target patterns and are limited to source-code tasks, overlooking other scenarios such as decompilation tasks. In this paper, we propose DuCodeMark, a stealthy and robust dual-purpose watermarking method for code datasets that generalizes across both source-code tasks and decompilation tasks. DuCodeMark parses each code sample into an abstract syntax tree (AST), applies language-specific style transformations to construct stealthy trigger-target pairs, and injects repressible poisoned features into a subset of return-typed samples to enhance robustness against watermark removal or evasion. These features remain inactive during normal training but are activated upon watermark removal, degrading model performance. For verification, DuCodeMark employs a black-box method based on the independent-samples $t$-test. We conduct a comprehensive evaluation of DuCodeMark across 72 settings spanning two code tasks, two programming languages, three CodeLMs, and six decoding temperatures. The results demonstrate that it consistently achieves strong verifiability ($p < 0.05$), high stealthiness (suspicion rate $\leq$ 0.36), robustness against both watermark and poisoning attacks (recall $\leq$ 0.57), and a substantial drop in model performance upon watermark removal (Pass@1 drops by 28.6%), underscoring its practicality and resilience.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DuCodeMark, a dual-purpose watermarking scheme for code datasets. It parses samples into ASTs, applies language-specific style transformations to create stealthy trigger-target pairs, and injects repressible poisoned features into a subset of return-typed samples. These features are designed to remain inactive during normal training (preserving utility and stealth) but activate upon watermark removal attempts, degrading downstream model performance (e.g., Pass@1 drop of 28.6%). Verification relies on a black-box independent-samples t-test. Comprehensive experiments across 72 settings (two tasks, two languages, three CodeLMs, six temperatures) report consistent verifiability (p < 0.05), suspicion rate ≤ 0.36, attack recall ≤ 0.57, and robustness.
Significance. If the selective activation of the poisoned features can be realized without side effects on normal training or detectability, the work would represent a meaningful advance in protecting open-source code datasets from unauthorized use in CodeLM training. The extension to decompilation tasks and the broad 72-setting evaluation (including explicit performance-drop metric) provide stronger empirical grounding than many prior watermarking studies.
major comments (2)
- [§3.2] §3.2 (Poisoned Feature Injection): The central dual-purpose claim rests on repressible poisoned features that stay inactive during standard training yet reliably degrade Pass@1 upon removal. The manuscript provides no explicit encoding mechanism, conditional trigger, or formal condition under which activation occurs selectively; without this, it is impossible to verify that the features neither leak into normal behavior nor can be stripped without triggering the claimed degradation.
- [§5.1] §5.1 (Experimental Setup and Controls): The 72-setting evaluation reports aggregate metrics but omits detailed controls isolating the poisoned features' side effects on clean training runs, baseline comparisons against non-repressible poisoning, and per-setting variance for the t-test results. This weakens the robustness and stealthiness claims, as the selective-activation assumption cannot be assessed from the presented data.
minor comments (2)
- [§5] The suspicion-rate and recall thresholds (≤0.36 and ≤0.57) are presented without explicit comparison to prior watermarking or poisoning baselines in the same settings; adding these would clarify the improvement magnitude.
- [§3.1] Notation for the style-transformation rules on ASTs and the t-test statistic could be formalized with an equation or pseudocode block for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for acknowledging the potential advance represented by DuCodeMark. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Poisoned Feature Injection): The central dual-purpose claim rests on repressible poisoned features that stay inactive during standard training yet reliably degrade Pass@1 upon removal. The manuscript provides no explicit encoding mechanism, conditional trigger, or formal condition under which activation occurs selectively; without this, it is impossible to verify that the features neither leak into normal behavior nor can be stripped without triggering the claimed degradation.
Authors: We agree that §3.2 would benefit from greater explicitness. The poisoned features are realized as low-impact syntactic modifications (neutral return-type annotations and variable declarations) inserted only into return-typed functions; these elements are ignored by standard gradient updates yet produce measurable Pass@1 degradation once the style-based watermark triggers are stripped. To make the selective-activation condition verifiable, we will add a formal algorithmic description, pseudocode, and an analysis of why the features remain inactive under normal training in the revised §3.2. revision: yes
-
Referee: [§5.1] §5.1 (Experimental Setup and Controls): The 72-setting evaluation reports aggregate metrics but omits detailed controls isolating the poisoned features' side effects on clean training runs, baseline comparisons against non-repressible poisoning, and per-setting variance for the t-test results. This weakens the robustness and stealthiness claims, as the selective-activation assumption cannot be assessed from the presented data.
Authors: We acknowledge that the current aggregate presentation leaves the selective-activation assumption less directly testable. In revision we will augment §5.1 with (i) results from clean training runs that omit the poisoned features, (ii) a non-repressible poisoning baseline, and (iii) per-setting t-test p-value variances or standard deviations. These controls will be reported in the main text or an expanded appendix. revision: yes
Circularity Check
No significant circularity detected in the derivation or claims.
full rationale
The paper proposes an empirical watermarking technique (AST parsing, language-specific style transformations, and repressible poisoned features) and supports its claims through experimental evaluation across 72 settings, using a standard independent-samples t-test for verification. No mathematical derivation chain, predictions, or uniqueness theorems are presented that reduce by construction to fitted parameters, self-definitions, or self-citations. The central results (verifiability, stealthiness, robustness, performance drop) are reported as measured outcomes rather than tautological reductions from the method's own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Style transformations on ASTs produce stealthy trigger-target pairs that evade detection
- domain assumption The independent-samples t-test reliably detects watermark presence in black-box verification
Reference graph
Works this paper leans on
-
[1]
Ali Al-Kaswan, Maliheh Izadi, and Arie van Deursen. 2024. Traces of Memorisation in Large Language Models for Code. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. ACM, Lisbon, Portugal, 78:1–78:12
2024
- [2]
-
[3]
Barr, Premkumar T
Miltiadis Allamanis, Earl T. Barr, Premkumar T. Devanbu, and Charles Sutton. 2018. A Survey of Machine Learning for Big Code and Naturalness.ACM Comput. Surv.51, 4 (2018), 81:1–81:37
2018
-
[4]
Amazon Web Services, Inc. 2023. CodeWhisperer. site: https://aws.amazon.com/codewhisperer/
2023
-
[5]
Beijing Guixin Technology, Inc. 2022. aiXcoder. site: https://www.aixcoder.com/
2022
-
[6]
Andrei Z. Broder. 2000. Identifying and Filtering Near-Duplicate Documents. InProceedings of the 11th Annual Symposium on Combinatorial Pattern Matching (Lecture Notes in Computer Science, Vol. 1848). Springer, Montreal, Canada, 1–10
2000
-
[7]
Molloy, and Biplav Srivastava
Bryant Chen, Wilka Carvalho, Nathalie Baracaldo, Heiko Ludwig, Benjamin Edwards, Taesung Lee, Ian M. Molloy, and Biplav Srivastava. 2019. Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering. InWorkshop on Artificial Intelligence Safety 2019 co-located with the Thirty-Third AAAI Conference on Artificial Intelligence 2019 (AAAI-19) (...
2019
-
[8]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating Large Language Models Trained on Code.arXiv abs/2107.03374 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [9]
-
[10]
Anderson Faustino da Silva, Bruno Conde Kind, José Wesley de Souza Magalhães, Jerônimo Nunes Rocha, Breno Campos Ferreira Guimarães, and Fernando Magno Quintão Pereira. 2021. AnghaBench: A Suite with One Million Compilable C Benchmarks for Code-Size Reduction. InIEEE/ACM International Symposium on Code Generation and Optimization. IEEE, Seoul, South Korea...
2021
-
[11]
DuCodeMark. 2025. DuCodeMark. site: https://github.com/yuc-chen/DuCodeMark
2025
-
[12]
Chunrong Fang, Weisong Sun, Yuchen Chen, Xiao Chen, Zhao Wei, Quanjun Zhang, Yudu You, Bin Luo, Yang Liu, and Zhenyu Chen. 2024. Esale: Enhancing Code-Summary Alignment Learning for Source Code Summarization.IEEE Trans. Software Eng.50, 8 (2024), 2077–2095
2024
-
[13]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. InFindings of the Association for Computational Linguistics (Findings of ACL, Vol. EMNLP 2020). Association for Computational Linguistics, Online Ev...
2020
-
[14]
Free Software Foundation. 2024. GNU Coding Standards. site: https://www.gnu.org/prep/standards/
2024
-
[15]
GitHub, Inc. 2021. GitHub Copilot research recitation. https://github.blog/2021-06-30-github-copilot-research- recitation/
2021
-
[16]
GitHub, Inc. 2022. GitHub Copilot. https://copilot.github.com/
2022
-
[17]
GitHub Inc. 2025. CodeQL: Code Analysis Engine. https://codeql.github.com/
2025
-
[18]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence.arXivabs/2401.14196 (2024)
work page internal anchor Pith review arXiv 2024
-
[19]
Peiwei Hu, Ruigang Liang, and Kai Chen. 2024. DeGPT: Optimizing Decompiler Output with LLM. InProceedings of the 31st Annual Network and Distributed System Security Symposium. The Internet Society, San Diego, California, USA
2024
-
[20]
Hugging Face, Inc. 2016. Hugging Face. site: https://huggingface.co/
2016
-
[21]
Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. GPT-4o System Card.arXivabs/2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. 2019. CodeSearchNet Challenge: Evaluating the State of Semantic Code Search.arXivabs/1909.09436 (2019)
work page internal anchor Pith review arXiv 2019
-
[23]
Taehyun Lee, Seokhee Hong, Jaewoo Ahn, Ilgee Hong, Hwaran Lee, Sangdoo Yun, Jamin Shin, and Gunhee Kim. 2024. Who Wrote this Code? Watermarking for Code Generation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Bangkok, Thailand, 4890–4911
2024
-
[24]
Boquan Li, Mengdi Zhang, Peixin Zhang, Jun Sun, Xingmei Wang, and Zirui Fu. 2024. ACW: Enhancing Traceability of AI-Generated Codes Based on Watermarking.arXivabs/2402.07518 (2024). Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE048. Publication date: July 2026. FSE048:22 Y. Chen, Y. Xiao, C. Fang, Z. Chen, B. Xu
-
[25]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023. StarCoder: may the source be with you!Transactions on Machine Learning Research2023 (2023)
2023
-
[26]
Aiwei Liu, Leyi Pan, Yijian Lu, Jingjing Li, Xuming Hu, Xi Zhang, Lijie Wen, Irwin King, Hui Xiong, and Philip S. Yu. 2025. A Survey of Text Watermarking in the Era of Large Language Models.ACM Comput. Surv.57, 2 (2025), 47:1–47:36
2025
-
[27]
Fang Liu, Ge Li, Yunfei Zhao, and Zhi Jin. 2020. Multi-task Learning based Pre-trained Language Model for Code Completion. InProceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering. IEEE, Melbourne, Australia, 473–485
2020
-
[28]
LLVM. 2008. Clang Static Analyzer. https://clang.llvm.org/docs/ClangStaticAnalyzer.html. Accessed: 2025
2008
-
[29]
LLVM. 2013. Clang-format. https://clang.llvm.org/docs/ClangFormat.html. Accessed: 2025
2013
-
[30]
Vadim Markovtsev and Waren Long. 2018. Public git archive: a big code dataset for all. InProceedings of the 15th International Conference on Mining Software Repositories. ACM, Gothenburg, Sweden, 34–37
2018
-
[31]
Max Brunsfeld and others. 2018. Tree-sitter: An incremental parsing system for programming tools. https://github. com/tree-sitter/tree-sitter
2018
-
[32]
Bradley McDanel and Zhanhao Liu. 2023. ChatGPT as a Java Decompiler. InProceedings of the 3rd Workshop on Natural Language Generation, Evaluation, and Metrics. Association for Computational Linguistics, Singapore, 224–232
2023
-
[33]
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong
-
[34]
InProceedings of the 11st International Conference on Learning Representations
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis. InProceedings of the 11st International Conference on Learning Representations. OpenReview.net, Kigali, Rwanda
-
[35]
Oracle. 1999. Code Conventions for the Java Programming Language. site: https://www.oracle.com/java/technologies/ javase/codeconventions-contents.html
1999
-
[36]
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. 2023. Code Llama: Open Foundation Models for Code.arXivabs/2308.12950 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Weisong Sun, Yuchen Chen, Guanhong Tao, Chunrong Fang, Xiangyu Zhang, Quanjun Zhang, and Bin Luo. 2023. Backdooring Neural Code Search. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Toronto, Canada, 9692–9708
2023
-
[38]
Weisong Sun, Yuchen Chen, Mengzhe Yuan, Chunrong Fang, Zhenpeng Chen, Chong Wang, Yang Liu, Baowen Xu, and Zhenyu Chen. 2025. Show Me Your Code! Kill Code Poisoning: A Lightweight Method Based on Code Naturalness. InProceedings of the 47th IEEE/ACM International Conference on Software Engineering. IEEE Computer Society, Ottawa, Ontario, Canada, 1–12
2025
-
[39]
Weisong Sun, Chunrong Fang, Yuchen Chen, Guanhong Tao, Tingxu Han, and Quanjun Zhang. 2022. Code Search based on Context-aware Code Translation. InProceedings of the 44th International Conference on Software Engineering. ACM, May 25-27, 388–400
2022
-
[40]
Weisong Sun, Chunrong Fang, Yuchen Chen, Quanjun Zhang, Guanhong Tao, Yudu You, Tingxu Han, Yifei Ge, Yuling Hu, Bin Luo, and Zhenyu Chen. 2024. An Extractive-and-Abstractive Framework for Source Code Summarization. ACM Trans. Softw. Eng. Methodol.33, 3 (2024), 75:1–75:39
2024
-
[41]
Zhensu Sun, Xiaoning Du, Fu Song, and Li Li. 2023. CodeMark: Imperceptible Watermarking for Code Datasets against Neural Code Completion Models. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. ACM, San Francisco, CA, USA, 1561–1572
2023
-
[42]
Zhensu Sun, Xiaoning Du, Fu Song, Mingze Ni, and Li Li. 2022. CoProtector: Protect Open-Source Code against Unauthorized Training Usage with Data Poisoning. InWWW ’22: The ACM Web Conference 2022. ACM, Virtual Event, Lyon, France, 652–660
2022
-
[43]
Alexey Svyatkovskiy, Ying Zhao, Shengyu Fu, and Neel Sundaresan. 2019. Pythia: AI-assisted Code Completion System. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery. ACM, Anchorage, AK, USA, 2727–2735
2019
-
[44]
Hanzhuo Tan, Qi Luo, Jing Li, and Yuqun Zhang. 2024. LLM4Decompile: Decompiling Binary Code with Large Language Models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Miami, FL, USA, 3473–3487
2024
-
[45]
Brandon Tran, Jerry Li, and Aleksander Madry. 2018. Spectral Signatures in Backdoor Attacks. InAdvances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems. Montréal, Canada, 8011–8021
2018
-
[46]
Yao Wan, Jingdong Shu, Yulei Sui, Guandong Xu, Zhou Zhao, Jian Wu, and Philip S. Yu. 2019. Multi-modal Attention Network Learning for Semantic Source Code Retrieval. InProceedings of the 34th IEEE/ACM International Conference on Automated Software Engineering. IEEE, San Diego, CA, USA, 13–25
2019
-
[47]
Bernard L Welch. 1947. The Generalization of Student’s Problem when Several Different Population Varlances are Involved.Biometrika34, 1-2 (1947), 28–35. Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE048. Publication date: July 2026. DuCodeMark: Dual-Purpose Code Dataset Watermarking via Style-Aware Watermark-Poison Design FSE048:23
1947
-
[48]
Yuan Xiao, Yuchen Chen, Shiqing Ma, Haocheng Huang, Chunrong Fang, Yanwei Chen, Weisong Sun, Yunfeng Zhu, Xiaofang Zhang, and Zhenyu Chen. 2025. DeCoMa: Detecting and Purifying Code Dataset Watermarks through Dual Channel Code Abstraction. InProceedings of the 34th ACM SIGSOFT International Symposium on Software Testing and Analysis. ACM, Trondheim, Norway, 1–23
2025
- [49]
-
[50]
Zhou Yang, Jieke Shi, Junda He, and David Lo. 2022. Natural Attack for Pre-trained Models of Code. InProceedings of the 44th International Conference on Software Engineering. ACM, Pittsburgh, PA, USA, 1482–1493
2022
-
[51]
Zhou Yang, Zhensu Sun, Terry Yue Zhuo, Premkumar T. Devanbu, and David Lo. 2024. Robustness, Security, Privacy, Explainability, Efficiency, and Usability of Large Language Models for Code.arXivabs/2403.07506 (2024)
-
[52]
Zhang, Hong Jin Kang, Jieke Shi, Junda He, and David Lo
Zhou Yang, Bowen Xu, Jie M. Zhang, Hong Jin Kang, Jieke Shi, Junda He, and David Lo. 2024. Stealthy Backdoor Attack for Code Models.IEEE Trans. Software Eng.50, 4 (2024), 721–741
2024
-
[53]
Zhou Yang, Zhipeng Zhao, Chenyu Wang, Jieke Shi, Dongsun Kim, DongGyun Han, and David Lo. 2024. Unveiling Memorization in Code Models. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. ACM, Lisbon, Portugal, 72:1–72:13
2024
-
[54]
Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Lei Shen, Zihan Wang, Andi Wang, Yang Li, Teng Su, Zhilin Yang, and Jie Tang. 2023. CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Benchmarking on HumanEval-X. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. ACM, Long Beach, CA, ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.