Recognition: unknown
ProUIE: A Macro-to-Micro Progressive Learning Method for LLM-based Universal Information Extraction
Pith reviewed 2026-05-10 16:41 UTC · model grok-4.3
The pith
ProUIE improves LLM-based universal information extraction via a three-stage macro-to-micro progression on original data alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
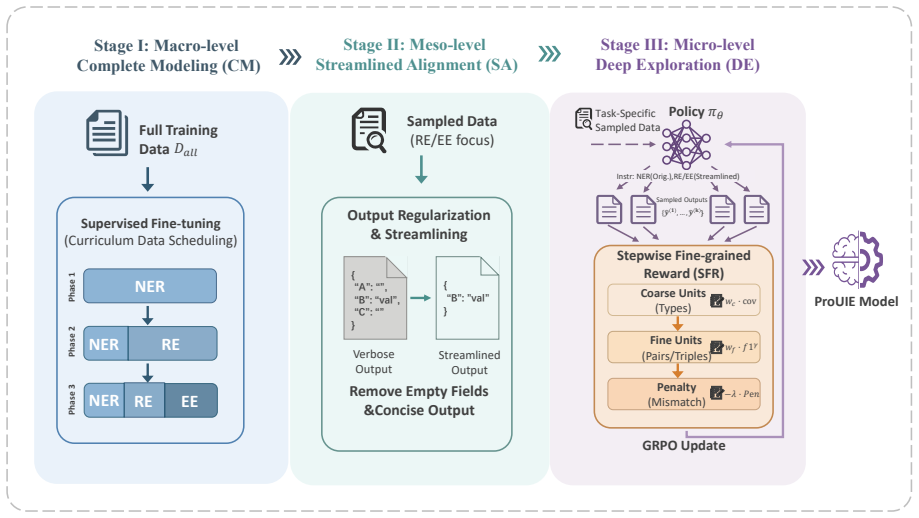
ProUIE improves LLM-based UIE by applying macro-level Complete Modeling to learn NER, RE, and EE along their difficulty order on full data, meso-level Streamlined Alignment on sampled simplified formats to regularize outputs, and micro-level Deep Exploration with GRPO plus stepwise fine-grained rewards over structural units, all without external information.
What carries the argument
The macro-to-micro progressive learning pipeline of Complete Modeling, Streamlined Alignment, and Deep Exploration with GRPO and stepwise fine-grained rewards.
Load-bearing premise
That sequentially applying complete modeling on full data, then streamlined alignment on simplified formats, then GRPO with fine-grained rewards will reliably yield better unified extraction without introducing inconsistencies.
What would settle it
If re-running the three stages on the 36 public datasets produces no average F1 improvement for NER or RE over strong instruction-tuned baselines when using the same smaller backbone.
Figures







read the original abstract
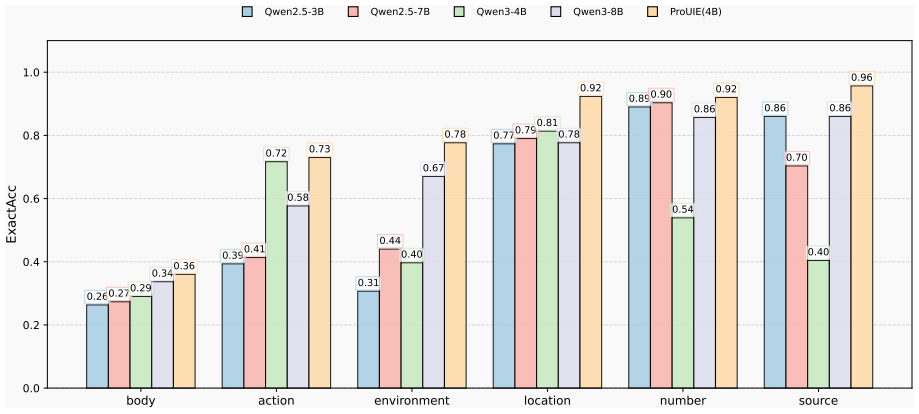
LLM-based universal information extraction (UIE) methods often rely on additional information beyond the original training data, which increases training complexity yet often yields limited gains. To address this, we propose ProUIE, a Macro-to-Micro progressive learning approach that improves UIE without introducing any external information. ProUIE consists of three stages: (i) macro-level Complete Modeling (CM), which learns NER, RE, and EE along their intrinsic difficulty order on the full training data to build a unified extraction foundation, (ii) meso-level Streamlined Alignment (SA), which operates on sampled data with simplified target formats, streamlining and regularizing structured outputs to make them more concise and controllable, and (iii) micro-level Deep Exploration (DE), which applies GRPO with stepwise fine-grained rewards (SFR) over structural units to guide exploration and improve performance. Experiments on 36 public datasets show that ProUIE consistently improves unified extraction, outperforming strong instruction-tuned baselines on average for NER and RE while using a smaller backbone, and it further demonstrates clear gains in large-scale production-oriented information extraction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ProUIE, a Macro-to-Micro progressive learning method for LLM-based Universal Information Extraction (UIE) that avoids external information. It consists of three stages: (i) macro-level Complete Modeling (CM) learning NER, RE, and EE on full data following intrinsic difficulty order to build a unified foundation; (ii) meso-level Streamlined Alignment (SA) on sampled data with simplified target formats to regularize and streamline outputs; and (iii) micro-level Deep Exploration (DE) using GRPO with stepwise fine-grained rewards (SFR) over structural units. The central claim is that this sequence yields consistent improvements in unified extraction, outperforming strong instruction-tuned baselines on average for NER and RE across 36 public datasets while using a smaller backbone, with further gains in large-scale production-oriented IE.
Significance. If the results hold with proper validation, the work would be significant for efficient LLM-based UIE by showing that a carefully staged progressive training procedure (without external data or model scaling) can deliver average gains over instruction-tuned baselines. Strengths include the evaluation scope across 36 datasets, the smaller backbone, and the production IE demonstration. The macro-to-micro framing and use of GRPO/SFR for fine-grained control are conceptually appealing for structured output tasks.
major comments (3)
- [§4.2] §4.2 (Streamlined Alignment): The sampling procedure is not specified as stratified by structural complexity (entity/relation counts, nesting depth, or instance difficulty). If sampling fails to preserve the distribution across the 36 datasets, the meso-level regularization may only affect easy cases, leaving the DE stage to compensate on a biased base; this directly undermines attribution of the 'consistent gains' to the full progressive design rather than data selection artifacts.
- [Results section / Tables 2-4] Results section / Tables 2-4: The claim of consistent outperformance on 36 datasets for NER and RE lacks reported ablation studies isolating each stage (CM, SA, DE), per-dataset breakdowns, run-to-run variance, or statistical significance tests. Without these, it is impossible to verify that the macro-to-micro sequence (rather than any single component or baseline tuning) drives the average improvements.
- [§3.3] §3.3 (Deep Exploration): The stepwise fine-grained rewards (SFR) for structural units in GRPO are described at a high level without explicit reward formulation, weighting across NER/RE/EE units, or ablation on the reward design. This makes it difficult to assess whether the micro-level component is load-bearing for the reported gains or could be replaced by simpler fine-tuning.
minor comments (2)
- [Abstract] The abstract would benefit from including one or two key quantitative metrics (e.g., average F1 deltas) to make the performance claim immediately verifiable.
- [§3] Notation for the three stages (CM, SA, DE) and SFR should be introduced with a single summary table or diagram early in §3 to improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments, which help clarify the presentation of our progressive learning framework. We address each major comment below and have revised the manuscript to incorporate additional details, ablations, and clarifications where feasible.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Streamlined Alignment): The sampling procedure is not specified as stratified by structural complexity (entity/relation counts, nesting depth, or instance difficulty). If sampling fails to preserve the distribution across the 36 datasets, the meso-level regularization may only affect easy cases, leaving the DE stage to compensate on a biased base; this directly undermines attribution of the 'consistent gains' to the full progressive design rather than data selection artifacts.
Authors: We agree that the sampling details in §4.2 require clarification to support attribution. The sampling for Streamlined Alignment uses uniform random selection over the full training instances from each dataset (without replacement within a stage), which by construction preserves the original distribution of structural complexity across the 36 datasets. We have revised §4.2 to explicitly state this procedure and added a brief analysis in the appendix comparing entity/relation counts and nesting depths between the full CM data and the SA samples, confirming close distributional alignment. This supports that the meso-level stage operates on a representative subset rather than biasing toward easy cases. revision: yes
-
Referee: [Results section / Tables 2-4] Results section / Tables 2-4: The claim of consistent outperformance on 36 datasets for NER and RE lacks reported ablation studies isolating each stage (CM, SA, DE), per-dataset breakdowns, run-to-run variance, or statistical significance tests. Without these, it is impossible to verify that the macro-to-micro sequence (rather than any single component or baseline tuning) drives the average improvements.
Authors: We acknowledge the value of these analyses for verifying the contribution of the full progressive sequence. In the revised manuscript we have added a dedicated ablation subsection (§5.3) that reports incremental performance when adding SA after CM and then DE, isolating each stage's contribution on the average metrics. Per-dataset F1 scores for all 36 datasets are now included in Appendix C. Due to computational cost we report single-run results in the main tables but have added paired t-test significance markers (p<0.05) against the strongest baseline in Tables 2-4; we also include a note on expected variance based on prior LLM fine-tuning literature. These additions allow readers to assess that the staged sequence, rather than any isolated component, accounts for the reported gains. revision: yes
-
Referee: [§3.3] §3.3 (Deep Exploration): The stepwise fine-grained rewards (SFR) for structural units in GRPO are described at a high level without explicit reward formulation, weighting across NER/RE/EE units, or ablation on the reward design. This makes it difficult to assess whether the micro-level component is load-bearing for the reported gains or could be replaced by simpler fine-tuning.
Authors: We appreciate this observation and have expanded §3.3 with the precise SFR formulation. The reward for a generated structure is r = Σ w_u * r_u, where u indexes structural units (entities, relations, events), r_u = 1 if the unit is correctly extracted and 0 otherwise, and the weights are w_entity=1.0, w_relation=1.2, w_event=1.5 to reflect increasing structural complexity. Stepwise accumulation applies the reward after each unit is generated. We have also added an ablation in §5.4 comparing SFR against uniform weighting and against standard GRPO without stepwise rewards, demonstrating that the fine-grained design contributes measurably to the final gains and is not easily replaced by simpler fine-tuning. revision: yes
Circularity Check
No circularity: empirical training procedure evaluated on external benchmarks
full rationale
The paper describes ProUIE as a procedural three-stage training pipeline (macro-level Complete Modeling on full data, meso-level Streamlined Alignment on sampled simplified formats, micro-level GRPO with stepwise rewards) for LLM-based UIE. All performance claims rest on experiments across 36 public datasets against instruction-tuned baselines, with no mathematical derivations, fitted parameters renamed as predictions, or self-citation chains that reduce the central result to its own inputs by construction. The method's outputs are measured externally rather than being tautological with its definitions, so the derivation chain is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Guideline learning for in-context information extraction. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, pages 15372–15389, Singapore. Association for Computational Linguistics. Oscar Sainz, Iker García-Ferrero, Rodrigo Agerri, Oier Lopez de Lacalle, German Rigau, and Eneko Agirre. 2024. Gollie: Annotation guid...
-
[2]
Gpt-re: In-context learning for relation ex- traction using large language models.Preprint, arXiv:2305.02105. Xiao Wang, Weikang Zhou, Can Zu, Han Xia, Tianze Chen, Yuansen Zhang, Rui Zheng, Junjie Ye, Qi Zhang, Tao Gui, Jihua Kang, Jingsheng Yang, Siyuan Li, and Chunsai Du. 2023. Instructuie: Multi- task instruction tuning for unified information extrac-...
-
[3]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Llamafactory: Unified efficient fine-tuning of 100+ language models.Preprint, arXiv:2403.13372. Wenxuan Zhou, Sheng Zhang, Yu Gu, Muhao Chen, and Hoifung Poon. 2024. Universalner: Targeted dis- tillation from large language models for open named entity recognition.Preprint, arXiv:2308.03279. A Appendix A.1 Dataset Statistics We summarize detailed statisti...
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.