Recognition: unknown
OmniUMI: Towards Physically Grounded Robot Learning via Human-Aligned Multimodal Interaction
Pith reviewed 2026-05-10 16:00 UTC · model grok-4.3
The pith
A single handheld device records vision, touch, and force signals together for training robots on contact-heavy tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
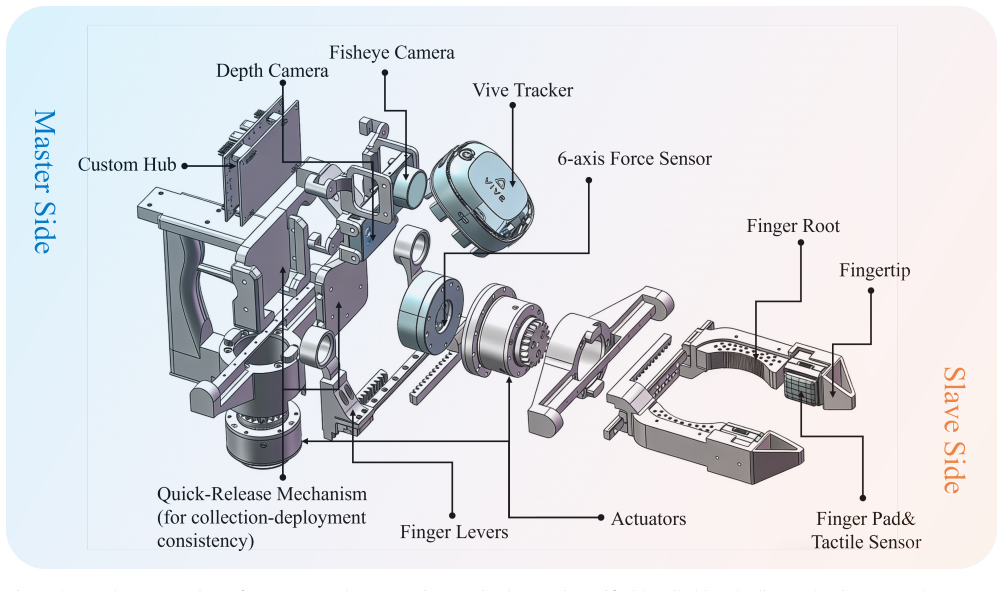
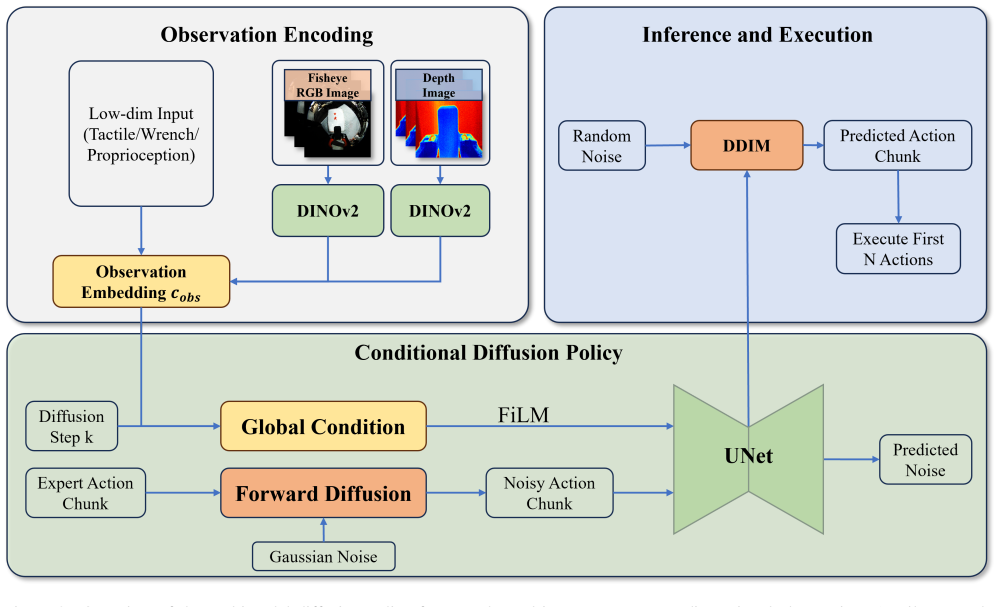
OmniUMI synchronously captures RGB, depth, trajectory, tactile sensing, internal grasping force, and external interaction wrench within a compact handheld system that maintains collection-deployment consistency through shared embodiment. It provides human-aligned modulation of forces and tactile interaction via bilateral gripper feedback, extends diffusion policy to use the multimodal observations, and deploys via impedance-based execution for unified motion and contact regulation, yielding reliable sensing and strong performance on force-sensitive pick-and-place, interactive surface erasing, and tactile-informed selective release.
What carries the argument
The shared handheld embodiment that synchronously records and feeds back RGB, depth, trajectory, tactile, grasping force, and wrench signals to enable consistent multimodal data collection and human-aligned demonstration.
If this is right
- Policies can regulate both motion and contact forces through impedance execution using the combined visual, tactile, and force observations.
- The interface supports learning for force-sensitive pick-and-place, surface erasing that responds to interaction, and selective release guided by touch.
- Human demonstrators can naturally perceive and adjust internal grasping force, external wrench, and tactile feedback during collection.
- The unified multimodal data reduces reliance on vision-only inference for contact dynamics in manipulation.
Where Pith is reading between the lines
- The same device could allow non-experts to collect high-quality contact data without installing separate sensors on every robot.
- Extending the bilateral feedback to additional modalities might accelerate data collection for tasks that require precise pressure control.
- If the consistency between collection and deployment holds across more robot platforms, the approach could shorten the iteration loop between teaching and testing physical skills.
Load-bearing premise
That the added tactile and force signals supply information that cannot be recovered from RGB and trajectory alone and that the handheld device produces negligible mismatch when the same embodiment is used for both data collection and robot deployment.
What would settle it
A controlled comparison in which policies trained on only RGB and trajectory data achieve equal success rates to the full multimodal version on the three tested tasks, or a deployment test that shows large performance drop when the learned policy is transferred from the handheld collection device to the actual robot gripper.
Figures






read the original abstract
UMI-style interfaces enable scalable robot learning, but existing systems remain largely visuomotor, relying primarily on RGB observations and trajectory while providing only limited access to physical interaction signals. This becomes a fundamental limitation in contact-rich manipulation, where success depends on contact dynamics such as tactile interaction, internal grasping force, and external interaction wrench that are difficult to infer from vision alone. We present OmniUMI, a unified framework for physically grounded robot learning via human-aligned multimodal interaction. OmniUMI synchronously captures RGB, depth, trajectory, tactile sensing, internal grasping force, and external interaction wrench within a compact handheld system, while maintaining collection--deployment consistency through a shared embodiment design. To support human-aligned demonstration, OmniUMI enables natural perception and modulation of internal grasping force, external interaction wrench, and tactile interaction through bilateral gripper feedback and the handheld embodiment. Built on this interface, we extend diffusion policy with visual, tactile, and force-related observations, and deploy the learned policy through impedance-based execution for unified regulation of motion and contact behavior. Experiments demonstrate reliable sensing and strong downstream performance on force-sensitive pick-and-place, interactive surface erasing, and tactile-informed selective release. Overall, OmniUMI combines physically grounded multimodal data acquisition with human-aligned interaction, providing a scalable foundation for learning contact-rich manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OmniUMI, a handheld multimodal interface and learning framework that synchronously captures RGB, depth, trajectory, tactile array, internal gripper force, and external wrench signals while preserving collection-deployment consistency via a shared embodiment. It extends diffusion policies to incorporate these physical modalities and executes them under impedance control. Experiments are reported on force-sensitive pick-and-place, surface erasing, and tactile-informed selective release, claiming reliable sensing and strong task performance.
Significance. If the central claims hold, the work supplies a practical, scalable route to collecting physically grounded demonstrations for contact-rich manipulation, directly addressing the acknowledged limitation of purely visuomotor UMI systems. The shared-embodiment design is a concrete strength that reduces domain shift between human collection and robot deployment.
major comments (1)
- [Experiments] Experiments section: the manuscript asserts that tactile, internal force, and external wrench signals supply information that cannot be reliably inferred from RGB and trajectory alone, yet reports no controlled ablation that trains the identical diffusion-policy architecture on the same demonstration set while dropping the tactile array, gripper-force, and wrench channels. Without this comparison, observed performance gains cannot be attributed to the additional modalities rather than to the shared-embodiment protocol, impedance controller, or demonstration quality.
minor comments (2)
- [Abstract] The abstract states 'reliable sensing' and 'strong downstream performance' without citing quantitative metrics, success rates, or figure references; these claims should be tied to specific results or tables.
- Notation for the multimodal observation vector and the impedance controller gains is introduced without an explicit equation or table; a compact definition would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of OmniUMI's significance and for the detailed, constructive comment on the experiments. We address the major comment below.
read point-by-point responses
-
Referee: Experiments section: the manuscript asserts that tactile, internal force, and external wrench signals supply information that cannot be reliably inferred from RGB and trajectory alone, yet reports no controlled ablation that trains the identical diffusion-policy architecture on the same demonstration set while dropping the tactile array, gripper-force, and wrench channels. Without this comparison, observed performance gains cannot be attributed to the additional modalities rather than to the shared-embodiment protocol, impedance controller, or demonstration quality.
Authors: We agree that the current manuscript lacks a controlled ablation isolating the contribution of the tactile array, internal gripper force, and external wrench channels. The reported experiments demonstrate strong task performance on contact-rich scenarios (force-sensitive pick-and-place, surface erasing, and tactile-informed selective release), but do not include a direct comparison training the identical diffusion-policy architecture on the same demonstration sets with those physical channels removed. Such an ablation is required to rigorously attribute gains to the multimodal signals rather than to the shared-embodiment design, impedance control, or data quality. In the revised manuscript we will add this ablation study, reporting success rates, contact metrics, and failure modes for the full multimodal policy versus the RGB+trajectory-only baseline across the three tasks. revision: yes
Circularity Check
No circularity; system contribution with no derivation chain or fitted predictions
full rationale
The manuscript presents a hardware interface and multimodal data collection system for robot learning, followed by policy extension and experimental validation on contact-rich tasks. No equations, parameter fittings, uniqueness theorems, or mathematical derivations are described that could reduce to inputs by construction. Claims rest on empirical performance of the full system rather than any closed-form prediction or self-referential definition. Any prior work on diffusion policies is external and not invoked as a load-bearing self-citation for a uniqueness result. This matches the reader's assessment of no derivation or fitted parameters.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal physical signals (tactile, force) provide information not recoverable from vision and trajectory alone
Forward citations
Cited by 1 Pith paper
-
BifrostUMI: Bridging Robot-Free Demonstrations and Humanoid Whole-Body Manipulation
BifrostUMI enables robot-free human demonstration capture via VR and wrist cameras to train visuomotor policies that predict keypoint trajectories for transfer to humanoid whole-body control through retargeting.
Reference graph
Works this paper leans on
-
[1]
Reactive Diffusion Policy: Slow-Fast Visual-Tactile Policy Learning for Contact-Rich Manipulation. 5
-
[2]
Feel the Force: Contact-Driven Learning from Humans, 2025
Ademi Adeniji, Zhuoran Chen, Vincent Liu, Venkatesh Pattabiraman, Raunaq Bhirangi, Siddhant Haldar, Pieter Abbeel, and Lerrel Pinto. Feel the Force: Contact-Driven Learning from Humans, 2025. Version Number: 1. 1, 4, 5
2025
-
[3]
Raunaq Bhirangi, Venkatesh Pattabiraman, Enes Erciyes, Yifeng Cao, Tess Hellebrekers, and Lerrel Pinto. AnySkin: Plug-and-play Skin Sensing for Robotic Touch, 2024. arXiv:2409.08276 [cs]. 4, 5
-
[4]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakr- ishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Ju- lian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla...
work page internal anchor Pith review arXiv
-
[5]
Tailai Cheng, Kejia Chen, Lingyun Chen, Liding Zhang, Yue Zhang, Yao Ling, Mahdi Hamad, Zhenshan Bing, Fan Wu, Karan Sharma, and Alois Knoll. TacUMI: A multi-modal universal manipulation interface for contact-rich tasks, 2026. arXiv:2601.14550 [cs]. 4
-
[6]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion, 2024. arXiv:2303.04137 [cs]. 1, 3, 5
work page internal anchor Pith review arXiv 2024
-
[7]
Universal manipula- tion interface: In-the-wild robot teaching without in-the- wild robots,
Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Ben- jamin Burchfiel, Siyuan Feng, Russ Tedrake, and Shu- 17 ran Song. Universal Manipulation Interface: In-The- Wild Robot Teaching Without In-The-Wild Robots, 2024. arXiv:2402.10329 [cs]. 1, 3, 5
-
[8]
Cutkosky, and Shu- ran Song
Hojung Choi, Yifan Hou, Chuer Pan, Seongheon Hong, Austin Patel, Xiaomeng Xu, Mark R. Cutkosky, and Shu- ran Song. In-the-wild compliant manipulation with UMI-FT,
-
[9]
arXiv:2601.09988 [cs] TLDR: This work introduces UMI-FT, a handheld data-collection platform that mounts compact, six-axis force/torque sensors on each finger, en- abling finger-level wrench measurements alongside RGB, depth, and pose and enables policies that reliably regulate external contact forces and internal grasp forces. 1, 4, 5
-
[10]
AnyTouch 2: General optical tactile rep- resentation learning for dynamic tactile perception, 2026
Ruoxuan Feng, Yuxuan Zhou, Siyu Mei, Dongzhan Zhou, Pengwei Wang, Shaowei Cui, Bin Fang, Guocai Yao, and Di Hu. AnyTouch 2: General optical tactile rep- resentation learning for dynamic tactile perception, 2026. arXiv:2602.09617 [cs]. 4
-
[11]
Tactile-conditioned diffusion policy for force-aware robotic manipulation, 2025
Erik Helmut, Niklas Funk, Tim Schneider, Cristiana de Farias, and Jan Peters. Tactile-Conditioned Diffu- sion Policy for Force-Aware Robotic Manipulation, 2025. arXiv:2510.13324 [cs]. 4
-
[12]
Adaptive Compliance Policy: Learning Ap- proximate Compliance for Diffusion Guided Control, 2024
Yifan Hou, Zeyi Liu, Cheng Chi, Eric Cousineau, Naveen Kuppuswamy, Siyuan Feng, Benjamin Burchfiel, and Shu- ran Song. Adaptive Compliance Policy: Learning Ap- proximate Compliance for Diffusion Guided Control, 2024. arXiv:2410.09309. 5
-
[13]
Data scaling laws in im- itation learning for robotic manipulation
Yingdong Hu, Fanqi Lin, Pingyue Sheng, Chuan Wen, Ji- acheng You, and Yang Gao. Data Scaling Laws in Imitation Learning for Robotic Manipulation, 2025. arXiv:2410.18647 [cs] TLDR: This paper investigates whether similar data scal- ing laws exist in robotics, particularly in robotic manipula- tion, and whether appropriate data scaling can yield single- tas...
-
[14]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Fos- ter, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. OpenVLA: An Open-Source Vision-Language-Action Model, 2024. arXiv:2406.09246 [cs]. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Geonhyup Lee, Yeongjin Lee, Kangmin Kim, Seongju Lee, Sangjun Noh, Seunghyeok Back, and Kyoobin Lee. Ma- nipForce: Force-Guided Policy Learning with Frequency- Aware Representation for Contact-Rich Manipulation, 2025. arXiv:2509.19047 [cs]. 1, 2, 4, 5
-
[16]
Yuyang Li, Yinghan Chen, Zihang Zhao, Puhao Li, Tengyu Liu, Siyuan Huang, and Yixin Zhu. Simultaneous tactile- visual perception for learning multimodal robot manipula- tion, 2025. arXiv:2512.09851 [cs] TLDR: TacThru, an STS sensor enabling simultaneous visual perception and robust tactile signal extraction and an imitation learning frame- work that lever...
-
[17]
AllTact Fin Ray: A Compliant Robot Gripper with Omni-Directional Tactile Sensing, 2025
Siwei Liang, Yixuan Guan, Jing Xu, Hongyu Qian, Xiangjun Zhang, Dan Wu, Wenbo Ding, and Rui Chen. AllTact Fin Ray: A Compliant Robot Gripper with Omni-Directional Tactile Sensing, 2025. arXiv:2504.18064 [cs]. 4, 5
-
[18]
Fangchen Liu, Chuanyu Li, Yihua Qin, Jing Xu, Pieter Abbeel, and Rui Chen. ViTaMIn: Learning Contact-Rich Tasks Through Robot-Free Visuo-Tactile Manipulation In- terface, 2025. arXiv:2504.06156 [cs]. 1, 4, 5
-
[19]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. RDT-1B: a Diffusion Foundation Model for Bimanual Ma- nipulation, 2024. arXiv:2410.07864. 1
work page internal anchor Pith review arXiv 2024
-
[20]
Songming Liu, Bangguo Li, Kai Ma, Lingxuan Wu, Hengkai Tan, Xiao Ouyang, Hang Su, and Jun Zhu. Rdt2: Exploring the scaling limit of umi data towards zero-shot cross-embodiment generalization.arXiv preprint arXiv:2602.03310, 2026. 3
-
[21]
Wenhai Liu, Junbo Wang, Yiming Wang, Weiming Wang, and Cewu Lu. ForceMimic: Force-Centric Imitation Learn- ing with Force-Motion Capture System for Contact-Rich Manipulation, 2024. arXiv:2410.07554. 1, 2, 4, 5
-
[22]
Shaqi Luo, Min Cheng, Ruqi Ding, Feng Wang, Bing Xu, and Bingkui Chen. Human–robot shared control based on lo- cally weighted intent prediction for a teleoperated hydraulic manipulator system.IEEE/ASME Transactions on Mecha- tronics, 27(6):4462–4474, 2022. Publisher: IEEE. 4, 5
2022
-
[23]
Adaptive virtual fix- ture based on learning trajectory distribution for comanipula- tion tasks.IEEE Transactions on Human-Machine Systems,
Shaqi Luo, Min Cheng, and Ruqi Ding. Adaptive virtual fix- ture based on learning trajectory distribution for comanipula- tion tasks.IEEE Transactions on Human-Machine Systems,
-
[24]
Tony Tao, Mohan Kumar Srirama, Jason Jingzhou Liu, Kenneth Shaw, and Deepak Pathak. DexWild: Dexterous Human Interactions for In-the-Wild Robot Policies, 2025. arXiv:2505.07813 [cs]. 3, 5
-
[25]
Octo: An Open-Source Generalist Robot Policy,
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An Open-Source Generalist Robot Policy,
-
[26]
TacDiffusion: Force-domain Diffusion Policy for Precise Tactile Manipulation, 2024
Yansong Wu, Zongxie Chen, Fan Wu, Lingyun Chen, Liding Zhang, Zhenshan Bing, Abdalla Swikir, Alois Knoll, and Sami Haddadin. TacDiffusion: Force-domain Diffusion Policy for Precise Tactile Manipulation, 2024. arXiv:2409.11047. 1, 4
-
[27]
Dexumi: Using human hand as the universal manipulation interface for dexterous manipulation, 2025
Mengda Xu, Han Zhang, Yifan Hou, Zhenjia Xu, Linxi Fan, Manuela Veloso, and Shuran Song. DexUMI: Using Human Hand as the Universal Manipulation Interface for Dexterous Manipulation, 2025. arXiv:2505.21864 [cs] version: 2. 1
-
[28]
exUMI: Extensible Robot Teaching System with Action- aware Task-agnostic Tactile Representation
Yue Xu, Litao Wei, Pengyu An, Qingyu Zhang, and Yong-Lu Li. exUMI: Extensible Robot Teaching System with Action- aware Task-agnostic Tactile Representation. 1, 4
-
[29]
Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact- rich manipulation
Han Xue, Jieji Ren, Wendi Chen, Gu Zhang, Yuan Fang, Guoying Gu, Huazhe Xu, and Cewu Lu. Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact- rich manipulation. InProceedings of Robotics: Science and Systems (RSS), 2025. 5
2025
-
[30]
18 MOMA-Force: Visual-Force Imitation for Real-World Mo- bile Manipulation, 2023
Taozheng Yang, Ya Jing, Hongtao Wu, Jiafeng Xu, Kuankuan Sima, Guangzeng Chen, Qie Sima, and Tao Kong. 18 MOMA-Force: Visual-Force Imitation for Real-World Mo- bile Manipulation, 2023. arXiv:2308.03624 [cs]. 1, 4
-
[31]
Forcevla: Enhancing vla models with a force-aware moe for contact-rich manipulation,
Jiawen Yu, Hairuo Liu, Qiaojun Yu, Jieji Ren, Ce Hao, Haitong Ding, Guangyu Huang, Guofan Huang, Yan Song, Panpan Cai, Cewu Lu, and Wenqiang Zhang. ForceVLA: Enhancing VLA Models with a Force-aware MoE for Contact-rich Manipulation, 2025. arXiv:2505.22159 [cs]. 1
-
[32]
FastUMI: A Scalable and Hardware- Independent Universal Manipulation Interface with Dataset,
Zhaxizhuoma, Kehui Liu, Chuyue Guan, Zhongjie Jia, Ziniu Wu, Xin Liu, Tianyu Wang, Shuai Liang, Pengan Chen, Pingrui Zhang, Haoming Song, Delin Qu, Dong Wang, Zhigang Wang, Nieqing Cao, Yan Ding, Bin Zhao, and Xuelong Li. FastUMI: A Scalable and Hardware- Independent Universal Manipulation Interface with Dataset,
- [33]
-
[34]
Admittance Visuomotor Policy Learn- ing for General-Purpose Contact-Rich Manipulations, 2024
Bo Zhou, Ruixuan Jiao, Yi Li, Xiaogang Yuan, Fang Fang, and Shihua Li. Admittance Visuomotor Policy Learn- ing for General-Purpose Contact-Rich Manipulations, 2024. arXiv:2409.14440 [cs]. 1, 4 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.