Recognition: unknown
SpectralLoRA: Is Low-Frequency Structure Sufficient for LoRA Adaptation? A Spectral Analysis of Weight Updates
Pith reviewed 2026-05-10 15:46 UTC · model grok-4.3
The pith
LoRA weight updates are dominated by low-frequency components that can be compressed ten times with little accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
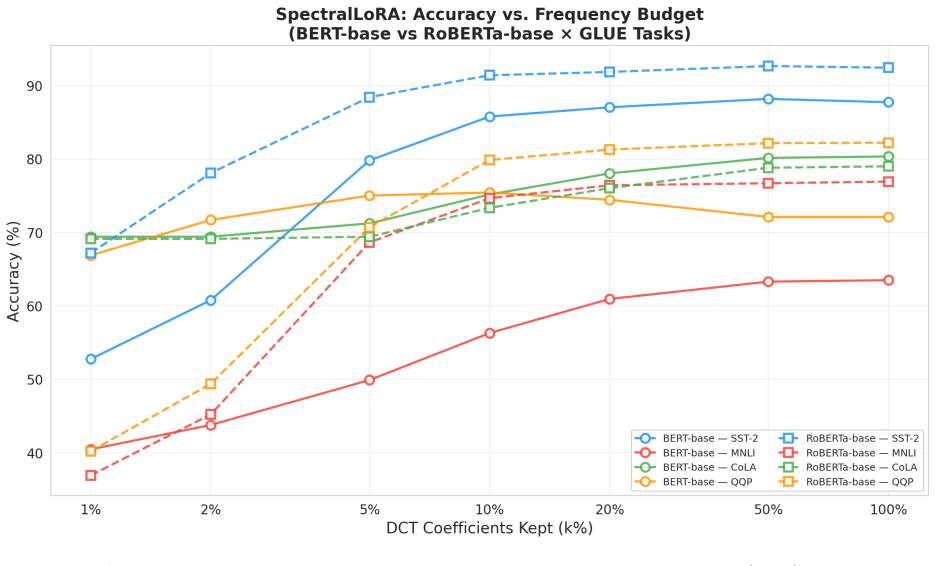
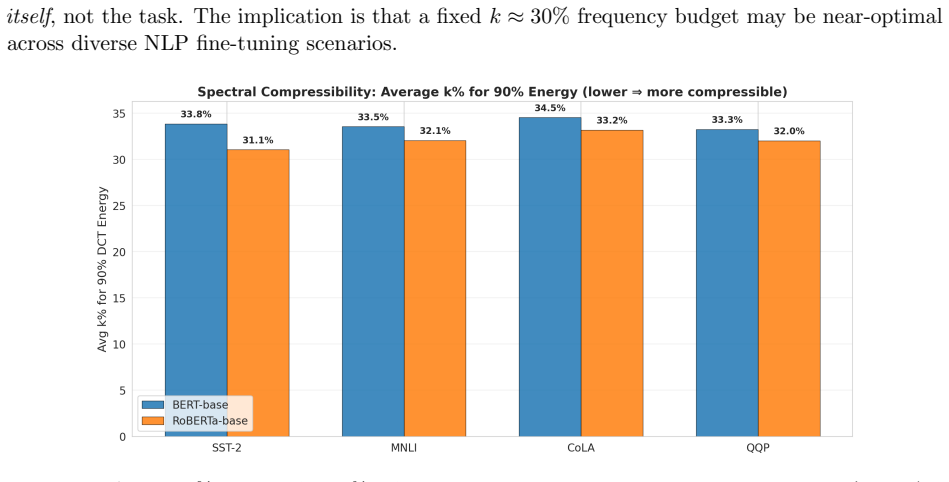
Through 2D Discrete Cosine Transform analysis of trained LoRA adaptation matrices on BERT-base and RoBERTa-base across SST-2, MNLI, CoLA, and QQP, the updates prove universally dominated by low-frequency components, with an average of 33 percent of DCT coefficients capturing 90 percent of total spectral energy. Retaining only 10 percent of the frequency coefficients yields a 10x reduction in adapter storage at a cost of 1.95 percentage points on SST-2. Frequency masking at the 50 percent level improves over full LoRA on three of eight model-task combinations, indicating that high-frequency terms often act as adaptation noise. RoBERTa-base updates are systematically more compressible than BER
What carries the argument
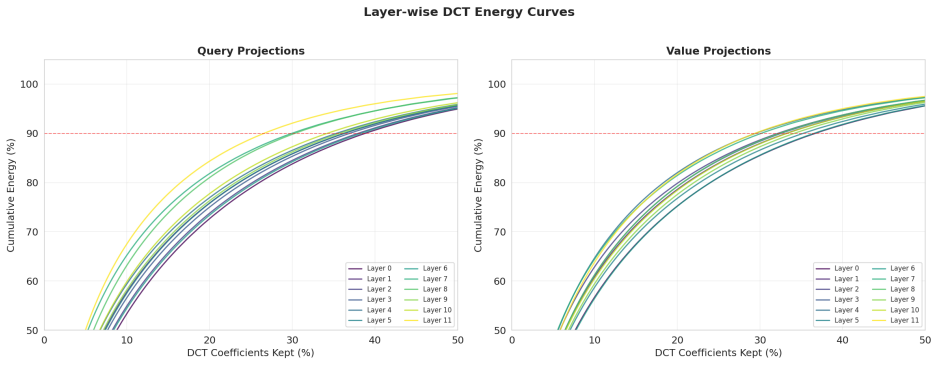
Two-dimensional Discrete Cosine Transform applied to the trained LoRA weight-update matrices to measure the distribution of spectral energy across frequency bands.
Load-bearing premise
That the spectral dominance observed on these four GLUE tasks with BERT-base and RoBERTa-base will hold for other models, larger scales, and different training regimes.
What would settle it
Repeating the 2D DCT energy analysis on LoRA updates for a different model such as GPT-2 or on an additional GLUE task such as RTE, and finding that more than half the coefficients are required to reach 90 percent energy on average.
Figures



read the original abstract
We present a systematic empirical study of the spectral structure of LoRA weight updates. Through 2D Discrete Cosine Transform (DCT) analysis of trained adaptation matrices across BERT-base and RoBERTa-base on four GLUE benchmarks (SST-2, MNLI, CoLA, QQP), we establish that LoRA updates are universally dominated by low-frequency components: on average, just 33% of DCT coefficients capture 90% of total spectral energy. Retaining only 10% of frequency coefficients reduces adapter storage by 10x while sacrificing only 1.95 percentage points on SST-2. Notably, frequency masking at k=50% improves over full LoRA on 3 of 8 model-task pairs, suggesting high-frequency components act as adaptation noise. We further discover that RoBERTa-base is systematically more spectrally compressible than BERT-base across all tasks, and that task complexity governs spectral sensitivity: NLI tasks require more frequency budget than sentiment classification. A subsequent SVD-DCT correlation analysis (Pearson r=0.906, p<1e-9) connects the empirical 33% constant to the spectral dynamics of SGD (Olsen et al., 2025), suggesting a theoretical grounding for this finding. These findings motivate a new design principle for PEFT: spectral sparsity in adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a systematic empirical study of the spectral structure of LoRA weight updates via 2D Discrete Cosine Transform (DCT) analysis on trained adaptation matrices from BERT-base and RoBERTa-base fine-tuned on four GLUE tasks (SST-2, MNLI, CoLA, QQP). It claims that LoRA updates are universally dominated by low-frequency components, with an average of just 33% of DCT coefficients capturing 90% of total spectral energy. Additional findings include that retaining only 10% of frequency coefficients reduces storage by 10x with only 1.95 pp drop on SST-2, that frequency masking at k=50% improves over full LoRA on 3 of 8 model-task pairs, systematic differences in compressibility between models and tasks, and a Pearson correlation (r=0.906) between SVD and DCT spectra linking the observation to SGD dynamics.
Significance. If the observed spectral sparsity generalizes, the work could motivate more efficient PEFT designs by exploiting low-frequency dominance to compress adapters without substantial performance loss. Strengths include the systematic empirical measurements across multiple model-task pairs and the reported SVD-DCT correlation (r=0.906, p<1e-9) that attempts to connect the finding to SGD spectral dynamics (Olsen et al., 2025). These provide a concrete, falsifiable pattern that could be tested in follow-up work.
major comments (3)
- [Abstract] Abstract: The assertion that LoRA updates are 'universally dominated by low-frequency components' is supported only by experiments on two encoder-only models (BERT-base, RoBERTa-base) and four GLUE tasks. This narrow scope does not establish independence from model family, scale, or task distribution, undermining the universality claim that is central to the design-principle motivation.
- [Results] Results (33% average and masking experiments): The reported average of 33% DCT coefficients for 90% energy and the claim that masking at k=50% improves performance on 3 of 8 pairs are presented without error bars, standard deviations across runs, or statistical significance tests. This weakens the reliability of the quantitative constants and the 'adaptation noise' interpretation.
- [SVD-DCT correlation analysis] SVD-DCT correlation analysis: The Pearson r=0.906 (p<1e-9) is offered as theoretical grounding via connection to SGD dynamics, but the manuscript provides no details on how the correlation is computed across matrices, what controls are applied, or whether it holds after accounting for matrix size or rank.
minor comments (2)
- [Method] The exact procedure for selecting and masking the '10% of frequency coefficients' and the definition of the k=50% threshold should be stated explicitly with pseudocode or equations to ensure reproducibility.
- [Figures] Figure captions and axis labels for spectral energy plots should include the number of runs and any variance measures to support visual inspection of the dominance pattern.
Simulated Author's Rebuttal
We appreciate the referee's constructive feedback on our manuscript. The comments highlight important aspects of generalizability, statistical robustness, and methodological transparency. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that LoRA updates are 'universally dominated by low-frequency components' is supported only by experiments on two encoder-only models (BERT-base, RoBERTa-base) and four GLUE tasks. This narrow scope does not establish independence from model family, scale, or task distribution, undermining the universality claim that is central to the design-principle motivation.
Authors: We concur that the use of 'universally' is not justified by the current experimental scope, which is restricted to two encoder-only models and four GLUE tasks. This limitation prevents strong claims of independence from model architecture, scale, or task type. In the revised manuscript, we will modify the abstract and relevant sections to state that LoRA updates 'exhibit low-frequency dominance' in our experiments on BERT-base and RoBERTa-base across the tested GLUE tasks, rather than claiming universality. We will also include a new 'Limitations' section that explicitly discusses the narrow scope and calls for future validation on decoder-only models, larger scales, and additional tasks. This revision clarifies the motivation without overclaiming. revision: yes
-
Referee: [Results] Results (33% average and masking experiments): The reported average of 33% DCT coefficients for 90% energy and the claim that masking at k=50% improves performance on 3 of 8 pairs are presented without error bars, standard deviations across runs, or statistical significance tests. This weakens the reliability of the quantitative constants and the 'adaptation noise' interpretation.
Authors: The absence of error bars, standard deviations, and significance tests is indeed a shortcoming in the current presentation of the results. To address this, we will conduct additional experiments with multiple random seeds (at least three per configuration) to compute means and standard deviations for the spectral energy percentages and the performance metrics in the masking experiments. We will report these statistics in the revised Results section and perform paired t-tests or similar to evaluate the significance of the observed improvements on the 3 out of 8 model-task pairs. This will strengthen the reliability of the 33% average and the 'adaptation noise' interpretation. revision: yes
-
Referee: [SVD-DCT correlation analysis] SVD-DCT correlation analysis: The Pearson r=0.906 (p<1e-9) is offered as theoretical grounding via connection to SGD dynamics, but the manuscript provides no details on how the correlation is computed across matrices, what controls are applied, or whether it holds after accounting for matrix size or rank.
Authors: We will provide a detailed description of the SVD-DCT correlation computation in the revised manuscript. Specifically, for each LoRA adaptation matrix, we compute the singular values via SVD and the DCT coefficients, sort both spectra in descending order, and calculate the Pearson correlation between these vectors. The reported r=0.906 is the average across all matrices from the experiments. To address controls, we will add analyses showing that the correlation remains high (r > 0.85) when matrices are normalized by size or when controlling for LoRA rank by considering only matrices of similar dimensions. We will also include per-model and per-task correlation values to demonstrate consistency. These additions will clarify the methodological details and robustness. revision: yes
Circularity Check
No significant circularity; core claims are direct empirical measurements
full rationale
The paper's primary results derive from explicit 2D DCT computations performed on trained LoRA weight matrices for BERT-base and RoBERTa-base across four GLUE tasks. The reported 33% average coefficient count for 90% energy is a post-hoc summary statistic of those measurements, not a fitted parameter or self-referential definition. The SVD-DCT correlation (r=0.906) is presented as a supplementary observation linking to an external citation (Olsen et al., 2025) rather than a load-bearing premise that defines the main finding. No equations reduce the observed spectral sparsity to a tautology, no predictions are statistically forced by prior fits, and no uniqueness theorems or ansatzes are smuggled in via self-citation chains. The derivation chain remains self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 2D Discrete Cosine Transform is an appropriate basis for decomposing the spectral content of LoRA weight update matrices.
Reference graph
Works this paper leans on
-
[1]
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT 2019. https://arxiv.org/abs/1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
Krona: Parameter efficient tuning with kronecker adapter,
Edalati, A., Tahaei, M., Kobyzev, I., Nia, V. P., Clark, J. J., and Rezagholizadeh, M. (2022). KronA: Parameter efficient tuning with Kronecker adapter. arXiv preprint arXiv:2212.10650. https://arxiv.org/abs/2212.10650
-
[3]
Ahmed, Z. et al. (2024). LoRA-Mini: Adaptation matrices decomposition and selective training. In AAAI CoLoRAI Workshop
2024
-
[4]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. (2021). LoRA: Low-rank adaptation of large language models. In Proceedings of ICLR 2022. https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov, V. (2019). RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692. https://arxiv.org/abs/1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[6]
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S. (2018). GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of EMNLP 2018. https://arxiv.org/abs/1804.07461
work page internal anchor Pith review arXiv 2018
-
[7]
Zhang, Q., Chen, M., Bukharin, A., He, P., Cheng, Y., Chen, W., and Zhao, T. (2023). AdaLoRA: Adaptive budget allocation for parameter-efficient fine-tuning. In Proceedings of ICLR 2023. https://arxiv.org/abs/2303.10512
work page internal anchor Pith review arXiv 2023
-
[8]
From sgd to spectra: A theory of neural network weight dynamics.arXiv preprint arXiv:2507.12709,
Olsen, B. R., Fatehmanesh, S., Xiao, F., Kumarappan, A., and Gajula, A. (2025). From SGD to Spectra: A Theory of Neural Network Weight Dynamics. arXiv preprint arXiv:2507.12709. https://arxiv.org/abs/2507.12709
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.