Recognition: unknown
VCC-DSA: A Novel Vascular Consistency Constrained DSA Imaging Model for Motion Artifact Suppression
Pith reviewed 2026-05-10 15:18 UTC · model grok-4.3
The pith
VCC-DSA uses a vascular consistency strategy to suppress motion artifacts in digital subtraction angiography.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The core discovery is that enforcing vascular consistency across mask and live images allows spontaneous distillation of the contrast-enhanced vessel structure, solving the ill-posed subtraction problem and robustly suppressing artifacts even in overlapping or small vessel cases.
What carries the argument
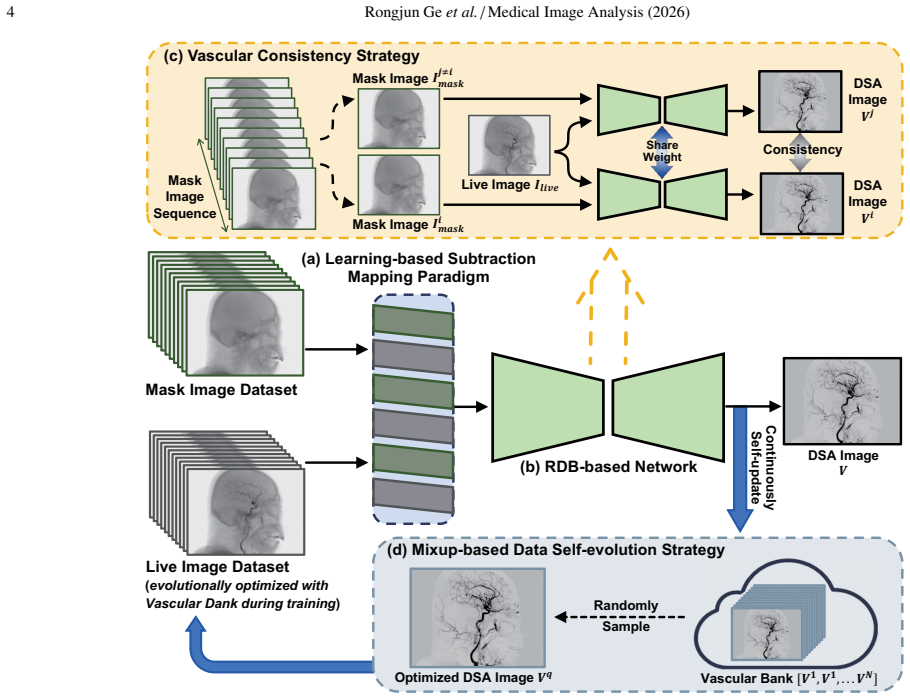
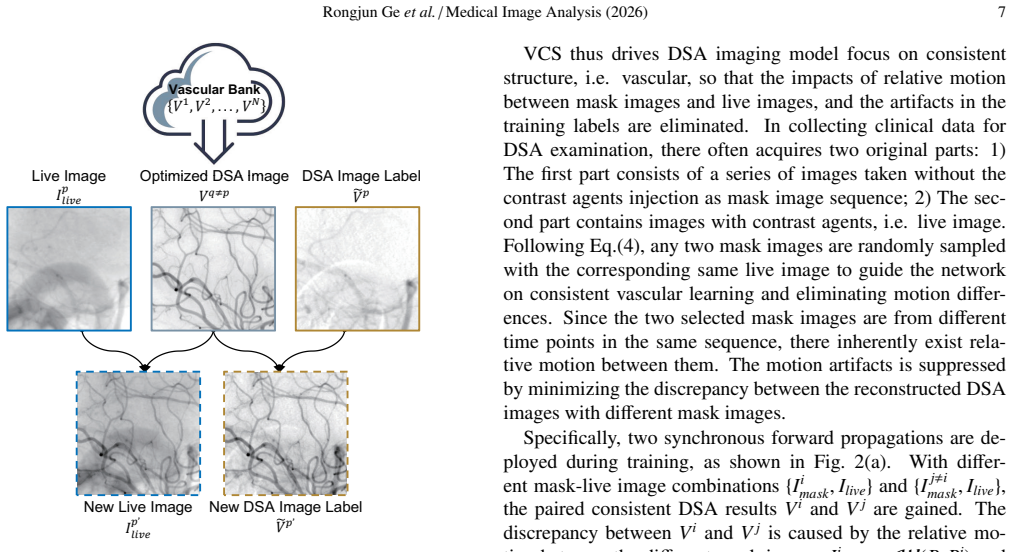
Vascular Consistency Strategy that extracts intrinsic consistency from various relative motions in mask-live images to distill the vascular structure with contrast-agent development.
If this is right
- Enhances stability for cases where moving bones overlap with blood vessels.
- Improves visibility of small peripheral vessels.
- Reduces the need for highly matched training data pairs.
- Promotes better learning of vascular features while excluding irrelevant artifacts in labels.
Where Pith is reading between the lines
- This method might extend to other medical imaging modalities affected by motion, such as CT angiography.
- Could allow for DSA procedures with reduced patient sedation by handling more natural movements.
- Supports development of automated real-time artifact correction in interventional radiology.
Load-bearing premise
Vascular structures maintain identifiable consistency in their appearance across different relative motions between mask and live images.
What would settle it
Demonstrating no significant improvement in PSNR or SSIM on an independent clinical DSA dataset with varied patient motions would challenge the model's effectiveness.
Figures










read the original abstract
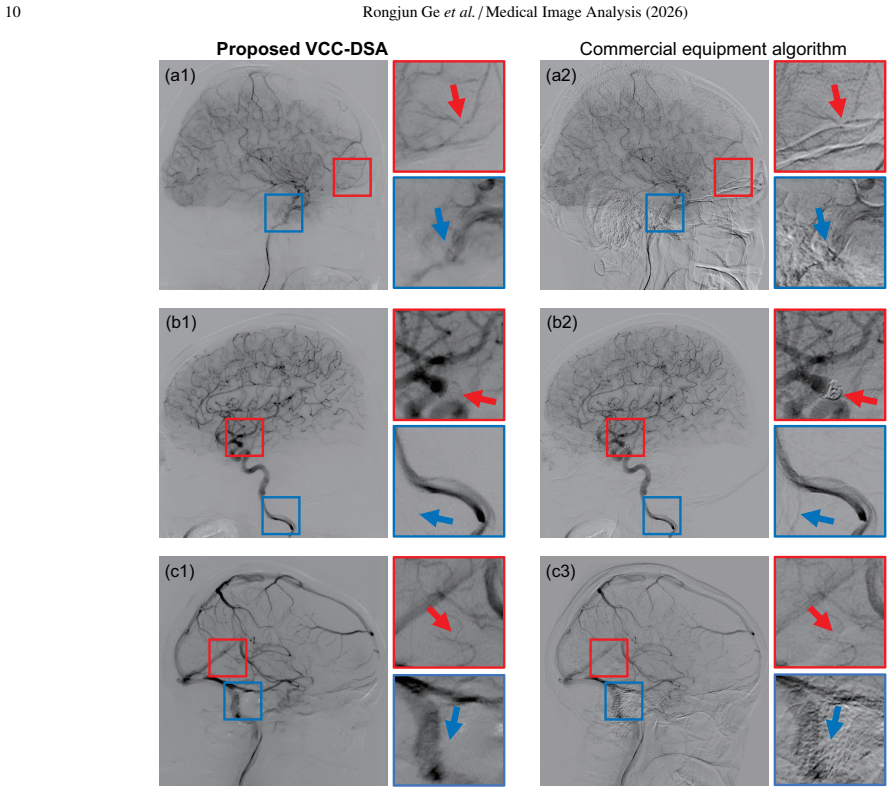
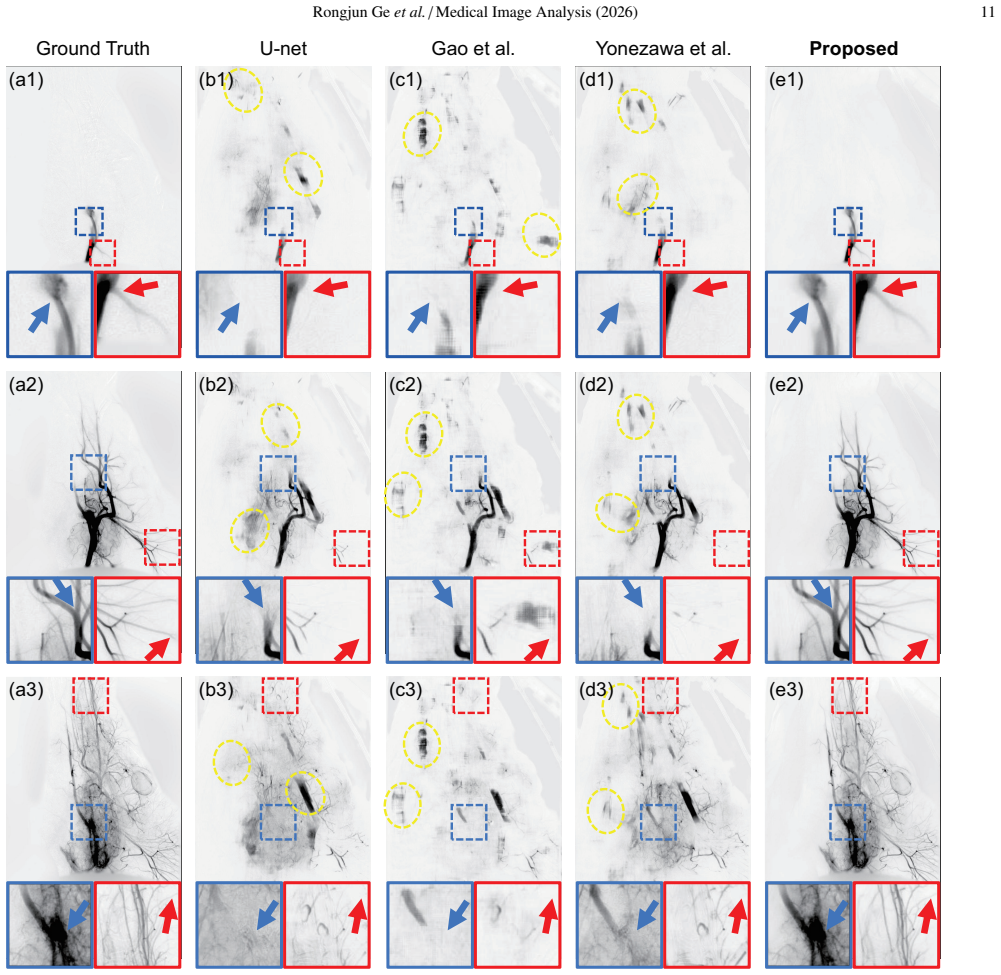
Digital Subtraction Angiography (DSA) is a clinically significant imaging technique for diagnosing cerebrovascular disease, as gold-standard. However, the artifacts caused by motion of high-attenuation tissues such as bones, teeth, and catheters, seriously reduce the visibility of blood vessels. This paper presents a novel Vascular Consistency Constrained DSA Imaging Model (VCC-DSA) for robust motion suppression and precise vascular imaging with the following designs: 1) We specially design a Learning-based Subtraction Mapping Paradigm, so that the ill-posed problem of existing learning-based methods can be solved to enhance the stability of the algorithm. 2) Our model effectively develops Residual Dense Blocks and details-shortcut to improve the performance under complex structures, such as moving bones overlapping with blood vessels, and small features, like peripheral vessels. 3) An innovative Vascular Consistency Strategy is proposed to extract intrinsically consistency from the various relative motions in mask-live images, so that spontaneously distils the vascular structure with contrast-agent development and robustly suppress motion artifacts, and also naturally alleviates the high matching requirements of data. 4) We creatively design a Mixup-based Data Self-evolution Strategy for data-intra self-enhancement in training loop, so that the training data gains dynamically optimized to promote model better learning the vascular features, and excluding the irrelevant structures in live/mask image and even the inevitable-artifacts/fake-structure in label. Prospectively, to further evaluate practical value, an actual general anesthesia animal experiment is specially conducted, besides the assessment on human clinical data. Compared with other method, our model improves the PSNR and SSIM by 73.4% and 8.56%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VCC-DSA, a deep learning model for motion artifact suppression in Digital Subtraction Angiography (DSA) imaging. It introduces four designs: (1) a learning-based subtraction mapping paradigm to stabilize the ill-posed subtraction problem, (2) residual dense blocks with details-shortcut for handling complex overlapping structures and small vessels, (3) a Vascular Consistency Strategy to extract intrinsic consistency from relative motions in mask-live pairs and spontaneously distill vascular contrast, and (4) a Mixup-based data self-evolution strategy for dynamic training data optimization. The model is tested on human clinical data and a prospective animal experiment under general anesthesia, with the central claim being 73.4% PSNR and 8.56% SSIM improvement over prior methods.
Significance. If the performance gains are reproducible and attributable to the proposed components, the work addresses a clinically important problem in cerebrovascular DSA by reducing motion artifacts from bones, teeth, and catheters. The Mixup self-evolution and consistency constraint could offer generalizable training strategies for medical image enhancement tasks with imperfect data pairing. The prospective animal experiment under anesthesia is a clear strength, adding translational relevance beyond retrospective clinical datasets.
major comments (3)
- [Abstract and §3] Abstract and §3 (Vascular Consistency Strategy): The strategy is claimed to 'spontaneously distil the vascular structure with contrast-agent development' from relative motions in mask-live images and to alleviate high matching requirements, but no equation, loss term, consistency metric (e.g., temporal correlation or attention), or ablation isolating its contribution from the residual dense blocks or subtraction mapping is provided. This is load-bearing for the robustness claim.
- [Experimental results section] Experimental results section (quantitative comparison): The headline 73.4% PSNR and 8.56% SSIM gains are presented without naming the exact baseline methods, test-set size, standard deviations, or statistical significance tests. This prevents assessment of whether the gains derive from the full VCC-DSA or from training choices, directly undermining the superiority assertion.
- [Animal experiment section] Animal experiment section: The prospective general-anesthesia animal study is noted for practical value, yet no quantitative PSNR/SSIM results, motion-induction protocol, or direct comparison to the clinical-data metrics are reported. This leaves the translational claim unsupported by evidence.
minor comments (2)
- [Abstract] Abstract: 'Compared with other method' should explicitly list the compared algorithms and cite their references for reproducibility.
- [Throughout] Notation: Ensure PSNR, SSIM, and DSA are defined at first use; clarify whether the reported percentages are relative improvements or absolute differences.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We value the constructive criticism and have prepared detailed responses to each major comment. Revisions will be made to address the identified gaps in clarity and evidence.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Vascular Consistency Strategy): The strategy is claimed to 'spontaneously distil the vascular structure with contrast-agent development' from relative motions in mask-live images and to alleviate high matching requirements, but no equation, loss term, consistency metric (e.g., temporal correlation or attention), or ablation isolating its contribution from the residual dense blocks or subtraction mapping is provided. This is load-bearing for the robustness claim.
Authors: We agree that additional formalization is necessary to fully substantiate the Vascular Consistency Strategy. In the revised manuscript, we will introduce the mathematical formulation, including the specific consistency loss term and metric (such as temporal correlation across mask-live pairs). Furthermore, we will conduct and report an ablation study to isolate the contribution of this strategy, demonstrating its role in distilling vascular structures and reducing matching requirements beyond the effects of residual dense blocks and the subtraction mapping paradigm. revision: yes
-
Referee: [Experimental results section] Experimental results section (quantitative comparison): The headline 73.4% PSNR and 8.56% SSIM gains are presented without naming the exact baseline methods, test-set size, standard deviations, or statistical significance tests. This prevents assessment of whether the gains derive from the full VCC-DSA or from training choices, directly undermining the superiority assertion.
Authors: We apologize for the omission of these details in the experimental results section. The revised version will explicitly name all baseline methods compared, specify the test-set size (including number of images and patients), report standard deviations for the metrics, and include statistical significance tests (e.g., Wilcoxon signed-rank tests) to validate the improvements. This will allow readers to better evaluate the source of the performance gains. revision: yes
-
Referee: [Animal experiment section] Animal experiment section: The prospective general-anesthesia animal study is noted for practical value, yet no quantitative PSNR/SSIM results, motion-induction protocol, or direct comparison to the clinical-data metrics are reported. This leaves the translational claim unsupported by evidence.
Authors: We acknowledge that the animal experiment section lacks quantitative metrics and a detailed protocol description. In the revision, we will provide a full description of the motion-induction protocol used in the prospective study. Regarding quantitative PSNR/SSIM, since the animal data was collected under controlled anesthesia to demonstrate real-world applicability, we did not compute the same metrics as on the clinical dataset; however, we will add any available quantitative assessments or clarify the qualitative evaluation approach and its relation to clinical results to better support the translational relevance. revision: partial
Circularity Check
No circularity in VCC-DSA derivation chain; designs and results are independent
full rationale
The abstract and provided description introduce four distinct architectural and training designs (Learning-based Subtraction Mapping Paradigm, Residual Dense Blocks with details-shortcut, Vascular Consistency Strategy, and Mixup-based Data Self-evolution Strategy) as separate contributions to address motion artifacts. No equations, loss terms, or derivations are shown that reduce any claimed output (e.g., vascular structure distillation or PSNR/SSIM gains) to self-definition, fitted inputs relabeled as predictions, or self-citation chains. The quantitative improvements are presented as empirical comparisons against other methods on external clinical and animal data, with no load-bearing uniqueness theorems or ansatzes imported from prior author work. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Model hyperparameters and network weights
axioms (1)
- domain assumption There exists intrinsic vascular consistency across mask and live DSA images despite relative motions
invented entities (2)
-
Vascular Consistency Strategy
no independent evidence
-
Mixup-based Data Self-evolution Strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Histogram-based image registration for digital subtraction angiography, in: Image Analysis and Pro- cessing: 9th International Conference, ICIAP’97 Florence, Italy, September 17–19, 1997 Proceedings, V olume II 9, Springer. pp. 380–387. Cao, Z., Liu, X., Peng, B., Moon, Y .S.,
1997
-
[2]
Dsa image registration based on multiscale gabor filters and mutual information, in: 2005 IEEE International Conference on Information Acquisition, IEEE. pp. 6–pp. Chappell, E.T., Moure, F.C., Good, M.C.,
2005
-
[3]
Hy- permorph: Amortized hyperparameter learning for image registration, in: Information Processing in Medical Imaging: 27th International Conference, IPMI 2021, Virtual Event, June 28–June 30, 2021, Proceedings 27, Springer. pp. 3–17. Isola, P., Zhu, J.Y ., Zhou, T., Efros, A.A.,
2021
-
[4]
Image-to-Image Translation with Conditional Adversarial Networks , journal =
Image-to-image translation with conditional adversarial networks.arXiv:1611.07004. Kimura, R., Teramoto, A., Ohno, T., Saito, K., Fujita, H.,
-
[5]
A fast image registration algorithm for digital subtraction angiography, in: 2010 17th Iranian Conference of Biomedical Engineering (ICBME), IEEE. pp. 1–4. Nejati, M., Pourghassem, H.,
2010
-
[6]
Rongjun Geet al./Medical Image Analysis (2026) 17 Pickens, D.R., Price, R.R., Erickson, J.J., James Jr, A.E.,
2026
-
[7]
U-net: Convolutional networks for biomedical image segmentation, in: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Con- ference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, Springer. pp. 234–241. Sch¨afer, E.,
2015
-
[8]
An iterative refinement dsa image registration al- gorithm using structural image quality measure, in: 2009 Fifth International Conference on Intelligent Information Hiding and Multimedia Signal Pro- cessing, IEEE. pp. 973–976. Yonezawa, H., Ueda, D., Yamamoto, A., Kageyama, K., Walston, S.L., Nota, T., Murai, K., Ogawa, S., Sohgawa, E., Jogo, A., et al.,
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.