Recognition: unknown
Last Iterate Convergence of AdaGrad-Norm for Convex Non-Smooth Optimization
Pith reviewed 2026-05-10 15:40 UTC · model grok-4.3
The pith
AdaGrad's last iterate converges at O(1/N^{1/4}) for convex non-smooth optimization, with matching lower bounds proving the rate tight.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We derive worst-case upper bounds on the suboptimality of the final point and show that, with an optimally tuned stepsize parameter, the last iterate converges at the rate O(1/N^{1/4}). We complement this guarantee with matching lower-bound constructions, proving that this rate is tight and that AdaGrad's last-iterate rate is strictly worse than the classical O(1/N^{1/2}) rate for its averaged iterate. Technically, our analysis introduces an exponent parameter that captures the growth of the cumulative squared subgradients; combined with the last-iterate inequality of Zamani and Glineur (2025), this reduces the problem to bounding a particular series.
What carries the argument
An exponent parameter that tracks the growth of cumulative squared subgradients, which combines with the last-iterate inequality to bound the series governing final-iterate suboptimality.
If this is right
- The last iterate of AdaGrad achieves O(1/N^{1/4}) suboptimality with optimal stepsize.
- Matching lower-bound constructions establish that this rate is tight.
- The last-iterate rate is strictly slower than the O(1/N^{1/2}) rate for averaged iterates.
- The guarantees apply under standard convexity and bounded-subgradient assumptions.
Where Pith is reading between the lines
- The slower last-iterate rate may encourage use of averaging or other post-processing steps when deploying AdaGrad in non-smooth convex settings where only the final model is retained.
- The exponent-parameter technique could extend to last-iterate analysis of other adaptive methods such as variants of Adam or RMSProp.
- The gap between last and averaged rates highlights the value of studying stopping rules that decide when to switch from adaptive steps to averaging.
Load-bearing premise
The analysis requires convex functions with bounded subgradients and depends on the last-iterate inequality from prior work together with the ability to control the series via the exponent parameter.
What would settle it
A convex non-smooth function with bounded subgradients on which the last iterate of AdaGrad remains at least c times larger than 1/N^{1/4} in suboptimality for infinitely many N, or on which the last iterate improves faster than the matching lower-bound construction permits.
Figures

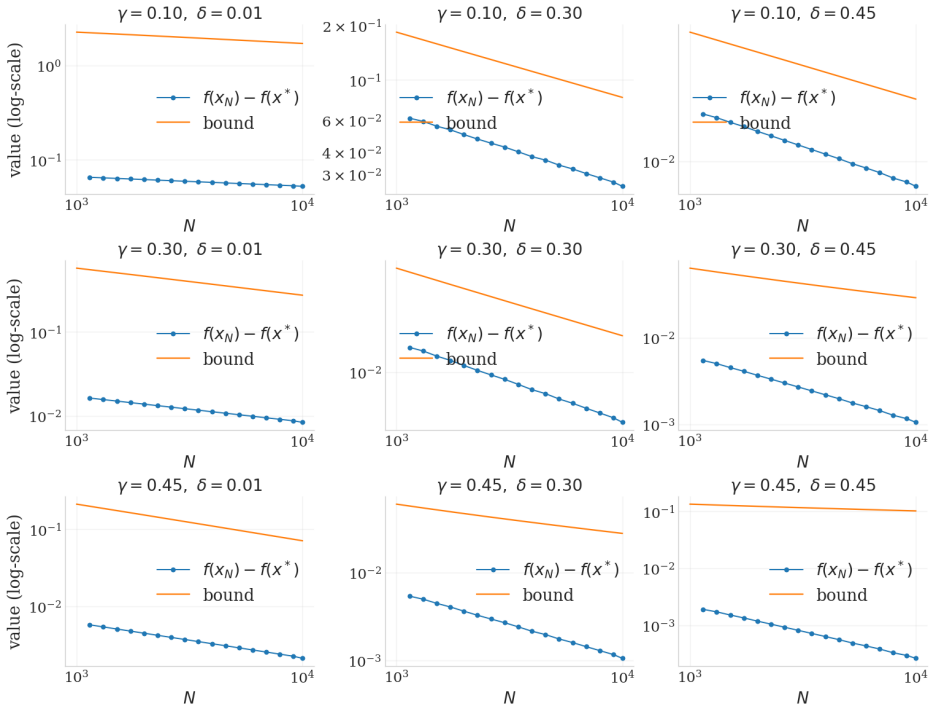
read the original abstract
We study the convergence of the last iterate (i.e., the $(N+1)$-th iterate) of the AdaGrad method. Although AdaGrad -- an adaptive subgradient method -- underpins a wide class of algorithms, most existing convergence analyses focus on averaged (or best) iterates. We derive worst-case upper bounds on the suboptimality of the final point and show that, with an optimally tuned stepsize parameter, the last iterate converges at the rate $O(1/N^{1/4})$. We complement this guarantee with matching lower-bound constructions, proving that this rate is tight and that AdaGrad's last-iterate rate is strictly worse than the classical $O(1/N^{1/2})$ rate for its averaged iterate. Technically, our analysis introduces an exponent parameter that captures the growth of the cumulative squared subgradients; combined with the last-iterate inequality of Zamani and Glineur (2025), this reduces the problem to bounding a particular series.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes last-iterate convergence of AdaGrad-Norm on convex non-smooth problems. It derives a worst-case upper bound of O(1/N^{1/4}) on the suboptimality of the (N+1)th iterate under optimally tuned stepsize, using an exponent parameter to capture growth of cumulative squared subgradients together with the Zamani-Glineur (2025) last-iterate inequality; this reduces the claim to bounding a particular series. Matching lower-bound constructions are provided to show the rate is tight and strictly slower than the classical O(1/N^{1/2}) rate for the averaged iterate.
Significance. If the upper-bound derivation holds, the result supplies the first tight last-iterate rate for AdaGrad-Norm in the non-smooth convex regime and clarifies why last-iterate performance lags averaged-iterate performance. The exponent-parameter technique and explicit lower bounds are technically useful contributions that could inform analyses of other adaptive methods.
major comments (1)
- [Technical analysis] Technical analysis section (reduction via exponent parameter): the claim that the last-iterate suboptimality is O(1/N^{1/4}) after optimal stepsize tuning rests on uniformly bounding the series that arises once the exponent parameter is introduced. It is not shown that this bound holds for arbitrary subgradient sequences whose squared norms sum to at most G²N; adversarial growth patterns consistent with the standard bounded-subgradient assumption could make the series larger than the claimed rate. The definition of the exponent (lim sup, fixed power, etc.) and the precise series bound must be stated explicitly and verified.
minor comments (2)
- [Abstract] The abstract refers to 'a particular series' without indicating its form; a one-sentence description would improve readability.
- [Notation and definitions] Notation for the exponent parameter and the cumulative squared-subgradient quantity S_n should be introduced once and used consistently throughout the proofs.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for pointing out the need for greater explicitness in the technical analysis. We address the major comment below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: Technical analysis section (reduction via exponent parameter): the claim that the last-iterate suboptimality is O(1/N^{1/4}) after optimal stepsize tuning rests on uniformly bounding the series that arises once the exponent parameter is introduced. It is not shown that this bound holds for arbitrary subgradient sequences whose squared norms sum to at most G²N; adversarial growth patterns consistent with the standard bounded-subgradient assumption could make the series larger than the claimed rate. The definition of the exponent (lim sup, fixed power, etc.) and the precise series bound must be stated explicitly and verified.
Authors: We agree that the current presentation would benefit from a more explicit treatment. In the revised version we will define the exponent parameter precisely as the lim sup_{n→∞} log(∑_{k=1}^n ||g_k||²)/log n for the given subgradient sequence. We will add a self-contained lemma showing that, under the sole assumption ∑_{k=1}^N ||g_k||² ≤ G² N, the series that appears after applying the Zamani-Glineur last-iterate inequality is bounded by O(N^{1/4}) uniformly over all admissible sequences. The proof proceeds by partitioning according to the possible values of the exponent (in [0,1]) and verifying that the worst-case growth rate, after optimal step-size tuning, yields the claimed O(1/N^{1/4}) bound. This covers all adversarial patterns consistent with the bounded-subgradient assumption. revision: yes
Circularity Check
No circularity: derivation uses external last-iterate inequality plus an auxiliary exponent parameter to reduce to an independent series bound
full rationale
The paper's core upper-bound argument introduces an exponent parameter to describe cumulative squared-subgradient growth and then invokes the Zamani-Glineur (2025) last-iterate inequality (different authors) to reduce the problem to bounding a series. This reduction is not self-definitional: the exponent is a modeling device that parameterizes possible growth rates rather than being fitted to the target convergence quantity, and the subsequent series bound is claimed to hold under only the standard convex + bounded-subgradient assumptions. No self-citation chain, no fitted-input-renamed-as-prediction, and no uniqueness theorem imported from the authors' prior work appear in the derivation. The matching lower-bound constructions are separate and do not rely on the upper-bound steps. The analysis is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- exponent parameter
axioms (2)
- domain assumption Objective is convex and non-smooth with bounded subgradients
- standard math Last-iterate inequality of Zamani and Glineur (2025)
Reference graph
Works this paper leans on
-
[1]
E., and Nocedal, J
Bottou, L., Curtis, F. E., and Nocedal, J. (2018). Optimization methods for large-scale machine learning. SIAM review , 60(2):223--311
2018
-
[2]
Bryson, A. E. and Ho, Y. C. (1975). Applied Optimal Control: Optimization, Estimation, and Control . Advanced Textbooks in Control and Signal Processing. Taylor & Francis, New York, NY, USA
1975
-
[3]
and Pock, T
Chambolle, A. and Pock, T. (2011). A first-order primal-dual algorithm for convex problems with applications to imaging. Journal of mathematical imaging and vision , 40(1):120--145
2011
- [4]
-
[5]
Cutkosky, A. (2020b). Better full-matrix regret via parameter-free online learning. Advances in Neural Information Processing Systems , 33:8836--8846
-
[6]
Cutkosky, A. (2020c). Parameter-free, dynamic, and strongly-adaptive online learning. In International Conference on Machine Learning , pages 2250--2259. PMLR
-
[7]
and Orabona, F
Cutkosky, A. and Orabona, F. (2018). Black-box reductions for parameter-free online learning in banach spaces. In Conference On Learning Theory , pages 1493--1529. PMLR
2018
-
[8]
and Sarlos, T
Cutkosky, A. and Sarlos, T. (2019). Matrix-free preconditioning in online learning. In International Conference on Machine Learning , pages 1455--1464. PMLR
2019
- [9]
-
[10]
and Jelassi, S
Defazio, A. and Jelassi, S. (2022). A momentumized, adaptive, dual averaged gradient method. Journal of Machine Learning Research , 23(144):1--34
2022
-
[11]
and Teboulle, M
Drori, Y. and Teboulle, M. (2016). An optimal variant of Kelley ’s cutting-plane method. Mathematical Programming , 160(1):321--351
2016
-
[12]
Duchi, J., Hazan, E., and Singer, Y. (2011). Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research , 12:2121--2159
2011
-
[13]
Eldar, Y. C. and Kutyniok, G. (2012). Compressed sensing: theory and applications . Cambridge university press
2012
-
[14]
J., Anil, R., and Hazan, E
Feinberg, V., Chen, X., Sun, Y. J., Anil, R., and Hazan, E. (2023). Sketchy: Memory-efficient adaptive regularization with frequent directions. Advances in Neural Information Processing Systems , 36:75911--75924
2023
-
[15]
arXiv preprint arXiv:1706.06569 , year =
Gupta, Vineet an Koren, T. and Singer, Y. (2017). A unified approach to adaptive regularization in online and stochastic optimization. arXiv preprint arXiv:1706.06569
-
[16]
J., Liaw, C., Plan, Y., and Randhawa, S
Harvey, N. J., Liaw, C., Plan, Y., and Randhawa, S. (2019). Tight analyses for non-smooth stochastic gradient descent. In Conference on Learning Theory , pages 1579--1613. PMLR
2019
-
[17]
Hinton, G., Srivastava, N., and Swersky, K. (2012). Neural networks for machine learning lecture 6a overview of mini-batch gradient descent. Cited on , 14(8):2
2012
-
[18]
M., and Netrapalli, P
Jain, P., Nagaraj, D. M., and Netrapalli, P. (2021). Making the last iterate of SGD information theoretically optimal. SIAM Journal on Optimization , 31(2):1108--1130
2021
-
[19]
Kingma, D. P. and Ba, J. (2015). Adam: A method for stochastic optimization. In International Conference on Learning Representations
2015
-
[20]
and Shamir, O
Kornowski, G. and Shamir, O. (2025). Gradient descent’s last iterate is often (slightly) suboptimal. In OPT 2025: Optimization for Machine Learning
2025
-
[21]
Y., Yurtsever, A., and Cevher, V
Levy, K. Y., Yurtsever, A., and Cevher, V. (2018). Online adaptive methods, universality and acceleration. Advances in neural information processing systems , 31
2018
- [22]
- [23]
- [24]
-
[25]
and Yang, S
Mohri, M. and Yang, S. (2016). Accelerating online convex optimization via adaptive prediction. In Gretton, A. and Robert, C. C., editors, Proceedings of the 19th International Conference on Artificial Intelligence and Statistics , volume 51 of Proceedings of Machine Learning Research , pages 848--856, Cadiz, Spain. PMLR
2016
-
[26]
Nemirovski, A., Juditsky, A., Lan, G., and Shapiro, A. (2009). Robust stochastic approximation approach to stochastic programming. SIAM Journal on Optimization , 19(4):1574--1609
2009
-
[27]
Nesterov, Y. (2009). Primal-dual subgradient methods for convex problems. Mathematical programming , 120(1):221--259
2009
-
[28]
and P \'a l, D
Orabona, F. and P \'a l, D. (2015). Scale-free algorithms for online linear optimization. In International Conference on Algorithmic Learning Theory , pages 287--301. Springer
2015
-
[29]
and P \'a l, D
Orabona, F. and P \'a l, D. (2016). Training deep networks without learning rates through coin betting. In Advances in Neural Information Processing Systems
2016
-
[30]
Polyak, B. T. (1969). Minimization of unsmooth functionals. USSR Computational Mathematics and Mathematical Physics , 9(3):14--29
1969
-
[31]
and Zhang, T
Shamir, O. and Zhang, T. (2013). Stochastic gradient descent for non-smooth optimization: Convergence results and optimal averaging schemes. In International conference on machine learning , pages 71--79. PMLR
2013
-
[32]
Shor, N. Z. (1985). Minimization Methods for Non-Differentiable Functions . Springer, Berlin, Heidelberg
1985
-
[33]
Wan, Y., Wei, N., and Zhang, L. (2018). Efficient adaptive online learning via frequent directions. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18 , pages 2748--2754. International Joint Conferences on Artificial Intelligence Organization
2018
-
[34]
Ward, R., Wu, X., and Bottou, L. (2020). Adagrad stepsizes: Sharp convergence over nonconvex landscapes. Journal of Machine Learning Research , 21(219):1--30
2020
-
[35]
Xiao, L. (2009). Dual averaging method for regularized stochastic learning and online optimization. Advances in neural information processing systems , 22
2009
-
[36]
Zamani, M. and Glineur, F. (2024). Exact convergence rate of the subgradient method by using polyak step size. arXiv preprint arXiv:2407.15195
-
[37]
and Glineur, F
Zamani, M. and Glineur, F. (2025). Exact convergence rate of the last iterate in subgradient methods. SIAM Journal on Optimization , 35(3):2182--2201
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.