Recognition: unknown
Self-Correcting RAG: Enhancing Faithfulness via MMKP Context Selection and NLI-Guided MCTS
Pith reviewed 2026-05-10 15:54 UTC · model grok-4.3
The pith
Self-Correcting RAG frames context selection as a knapsack problem and guides generation with NLI-based tree search to improve faithfulness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
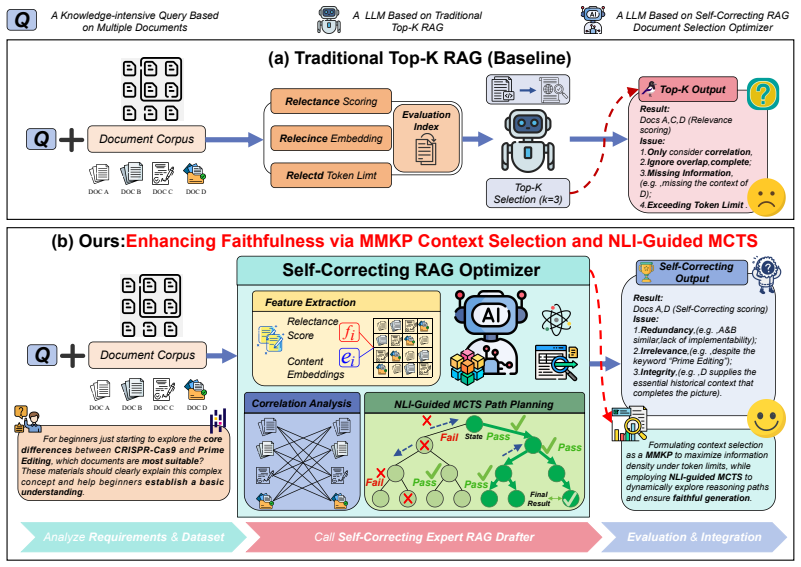
The central claim is that formalizing retrieval as a constrained optimization problem via MMKP and generation as an NLI-guided path planning problem via MCTS leads to higher reasoning accuracy and lower hallucination rates on complex queries, outperforming baselines on six multi-hop QA and fact-checking datasets.
What carries the argument
The MMKP objective, which balances information density against redundancy under a token limit, together with the NLI-guided MCTS that explores and corrects reasoning trajectories based on faithfulness scores.
If this is right
- Significantly improves reasoning accuracy on complex multi-hop queries
- Effectively reduces hallucinations in generated answers
- Outperforms strong existing baselines across six datasets
- Utilizes test-time compute for dynamic trajectory exploration and validation
Where Pith is reading between the lines
- The MMKP selection could be adapted to other retrieval scenarios to improve efficiency without additional training.
- NLI guidance during search might extend to other verification tasks like summarization or dialogue.
- Combining this with larger token budgets could further enhance performance on longer contexts.
Load-bearing premise
The MMKP objective and NLI faithfulness scores will reliably match human judgments of quality, and MCTS exploration will scale without introducing new errors.
What would settle it
Running the method on a held-out dataset where it fails to improve accuracy or increases hallucination rates compared to standard RAG baselines, or where human raters prefer greedy-retrieved contexts.
Figures






read the original abstract
Retrieval-augmented generation (RAG) substantially extends the knowledge boundary of large language models. However, it still faces two major challenges when handling complex reasoning tasks: low context utilization and frequent hallucinations. To address these issues, we propose Self-Correcting RAG, a unified framework that reformulates retrieval and generation as constrained optimization and path planning. On the input side, we move beyond traditional greedy retrieval and, for the first time, formalize context selection as a multi-dimensional multiple-choice knapsack problem (MMKP), thereby maximizing information density and removing redundancy under a strict token budget. On the output side, we introduce a natural language inference (NLI)-guided Monte Carlo Tree Search (MCTS) mechanism, which leverages test-time compute to dynamically explore reasoning trajectories and validate the faithfulness of generated answers. Experiments on six multi-hop question answering and fact-checking datasets demonstrate that our method significantly improves reasoning accuracy on complex queries while effectively reducing hallucinations, outperforming strong existing baselines.Our code is available at https://github.com/xjiacs/Self-Correcting-RAG .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Self-Correcting RAG, a framework that reformulates RAG retrieval as a multi-dimensional multiple-choice knapsack problem (MMKP) to maximize information density and minimize redundancy under a token budget, and generation as an NLI-guided Monte Carlo Tree Search (MCTS) to explore reasoning trajectories and enforce faithfulness. Experiments on six multi-hop QA and fact-checking datasets are reported to show improved accuracy and reduced hallucinations over strong baselines, with code released.
Significance. If the results hold after addressing validation gaps, the work offers a principled optimization view of context selection and a test-time search procedure for faithfulness that could improve RAG reliability on complex queries. The MMKP formalization and code release are strengths for reproducibility and follow-up work.
major comments (2)
- [Section 3 (NLI-guided MCTS description)] The faithfulness improvement is attributed to the NLI-guided MCTS component dynamically validating trajectories, yet no correlation analysis or human evaluation of NLI scores against human faithfulness ratings on the multi-hop outputs is provided across the six datasets. This assumption is load-bearing for the central hallucination-reduction claim, as NLI models may miss subtle reasoning errors or partial hallucinations in complex chains.
- [Section 4 (Experiments)] The experimental claims of outperformance rest on the combined MMKP + NLI-MCTS pipeline, but no ablation isolating the contribution of each component (or error analysis of cases where NLI misguides selection) is detailed enough to rule out that gains arise primarily from MCTS exploration rather than faithful guidance.
minor comments (2)
- [Abstract] The final sentence of the abstract contains a missing space before the period.
- [Section 3.1] Notation for the MMKP objective (information density minus redundancy) should be defined with an explicit equation in the method section for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The feedback highlights important areas for strengthening the validation of the NLI component and the experimental analysis. We address each major comment below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Section 3 (NLI-guided MCTS description)] The faithfulness improvement is attributed to the NLI-guided MCTS component dynamically validating trajectories, yet no correlation analysis or human evaluation of NLI scores against human faithfulness ratings on the multi-hop outputs is provided across the six datasets. This assumption is load-bearing for the central hallucination-reduction claim, as NLI models may miss subtle reasoning errors or partial hallucinations in complex chains.
Authors: We agree that empirical validation of the NLI proxy against human judgments on our specific multi-hop outputs would strengthen the central claim. The manuscript follows prior work in using NLI models for faithfulness checking, but does not include a dedicated correlation study or human evaluation across the datasets. In the revision, we will add a new subsection with a human evaluation on a sampled subset of outputs (approximately 200 instances from two datasets), reporting correlation coefficients between NLI scores and human faithfulness ratings. This will directly address potential limitations of NLI in detecting subtle errors. revision: yes
-
Referee: [Section 4 (Experiments)] The experimental claims of outperformance rest on the combined MMKP + NLI-MCTS pipeline, but no ablation isolating the contribution of each component (or error analysis of cases where NLI misguides selection) is detailed enough to rule out that gains arise primarily from MCTS exploration rather than faithful guidance.
Authors: We acknowledge that the current experimental section would benefit from more explicit isolation of components and error analysis. While the manuscript includes comparisons against strong baselines that partially separate retrieval and generation improvements, the ablations are not presented in a single dedicated table with incremental contributions, nor is there a qualitative breakdown of NLI misguidance cases. In the revised manuscript, we will expand Section 4 with a comprehensive ablation study (including variants such as MMKP alone, MCTS with/without NLI guidance, and random guidance) and add an error analysis subsection discussing instances of NLI misguidance, their frequency, and performance impact. This will clarify the specific role of faithful guidance beyond general search. revision: yes
Circularity Check
No significant circularity; algorithmic framework is self-contained
full rationale
The paper defines Self-Correcting RAG via two explicit algorithmic components: reformulating context selection as the standard MMKP optimization (maximizing information density minus redundancy under token budget) and using NLI-guided MCTS for trajectory exploration and faithfulness validation. Neither component contains algebraic derivations, fitted parameters renamed as predictions, or self-referential equations that reduce to the paper's own inputs by construction. Claims of improved accuracy and reduced hallucinations rest on empirical results across six external datasets rather than internal consistency loops. No load-bearing self-citations, uniqueness theorems from prior author work, or ansatzes smuggled via citation appear in the provided text. This is the normal case of a method paper whose central procedures are independently specified and externally testable.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption NLI model outputs can be used as reliable proxy scores for answer faithfulness to retrieved context
- domain assumption Multi-dimensional relevance scores can be combined into a single objective that maximizes information density without redundancy
Forward citations
Cited by 2 Pith papers
-
Transforming External Knowledge into Triplets for Enhanced Retrieval in RAG of LLMs
Tri-RAG turns external knowledge into Condition-Proof-Conclusion triplets and retrieves via the Condition anchor to improve efficiency and quality in LLM RAG.
-
FACT-E: Causality-Inspired Evaluation for Trustworthy Chain-of-Thought Reasoning
FACT-E uses controlled perturbations as an instrumental signal to measure intra-chain faithfulness in CoT reasoning and combines it with answer consistency to select trustworthy trajectories.
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Do as i can, not as i say: Grounding language in robotic affordances.Preprint, arXiv:2204.01691. Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. Self-rag: Learning to retrieve, generate, and critique through self-reflection. Preprint, arXiv:2310.11511. Maciej Besta, Nils Blach, Ales Kubicek, Robert Ger- stenberger, Michal Po...
work page internal anchor Pith review arXiv 2023
-
[2]
arXiv preprint arXiv:2309.08532 (2023)
Precise zero-shot dense retrieval without rel- evance labels. InProceedings of the 61st Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 1762–1777, Toronto, Canada. Association for Computational Lin- guistics. 9 Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yu...
-
[3]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 1658–1677, Bangkok, Thailand
LongLLMLingua: Accelerating and enhanc- ing LLMs in long context scenarios via prompt com- pression. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 1658–1677, Bangkok, Thailand. Association for Computational Linguistics. Zhengbao Jiang, Frank Xu, Luyu Gao, Zhiqing Sun, Qian Liu, J...
2023
-
[4]
Curran Associates, Inc. Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2023a. Halueval: A large- scale hallucination evaluation benchmark for large language models.Preprint, arXiv:2305.11747. Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. 2023b. Api-bank: A comprehen-...
-
[5]
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
Llm+p: Empowering large language mod- els with optimal planning proficiency.Preprint, arXiv:2304.11477. Jieyi Long. 2023. Large language model guided tree-of- thought.Preprint, arXiv:2305.08291. Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. 2023a. Query rewriting in retrieval- augmented large language models. InProceedings of 10 the 2023 Co...
work page internal anchor Pith review arXiv 2023
-
[6]
Is ChatGPT good at search? Investigating large language models as re-ranking agents,
RAPTOR: Recursive abstractive processing for tree-organized retrieval. InThe Twelfth Interna- tional Conference on Learning Representations. Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. ...
-
[7]
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen
Corrective retrieval augmented generation. Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen
-
[8]
Large language models as optimizers. In The Twelfth International Conference on Learning Representations. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christo- pher D. Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empiri- ca...
-
[9]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Least-to-most prompting enables complex reasoning in large language models.Preprint, arXiv:2205.10625. Appendices Within this supplementary material, we elaborate on the following aspects: •Appendix A: Dataset Details • Appendix B: Implementation Details and Hyper- parameters •Appendix C: Theoretical Proofs and Analysis •Appendix D: Detailed Experimental ...
work page internal anchor Pith review arXiv
-
[10]
Token Consumption ( k= 1 ): w(1) ij = Len(dij)
-
[11]
Redundancy Penalty (k= 2 ): Derived from the intra-group centroid. w(2) ij =λ red · 1 |Gi| −1 X d∈Gi\{dij } cos Φ(dij),Φ(d) ! (3) This cost dimension penalizes items that are too central or generic within their cluster, preferring unique information, scaled byλ red. C.1.2 Utility Function The utility vij balances query relevance and global diversity: vij ...
-
[12]
Each group Gi contains exactly two items: {di,1, di,0}
-
[13]
Item di,1 (representing “taking” item i) has value vi and weight vector wi,1 = [wi,0, . . . ,0]
-
[14]
Item di,0 (representing “leaving” item i) has value0and weight vector0
-
[15]
Set the MMKP capacity vector C= [W,∞, . . . ,∞]. The constraintP j xij ≤1 in MMKP forces the selection of exactly one item per group (either the real item or the dummy zero-cost item), which is mathematically equivalent to the binary choice xi ∈ {0,1} in the standard Knapsack problem. Since 0/1 Knapsack is NP-hard, and it is a special case of RAG-MMKP, RA...
-
[16]
Given error tolerance ϵ > 0, define scaling factorK= ϵP n
Let P= max i vi. Given error tolerance ϵ > 0, define scaling factorK= ϵP n
-
[17]
Define scaled valuesv ′ i =⌊ vi K ⌋
-
[18]
The recurrence is: DP[k, v] = min(DP[k− 1, v], wk +DP[k−1, v−v ′ k])
Solve the problem using DP on values v′ i. The recurrence is: DP[k, v] = min(DP[k− 1, v], wk +DP[k−1, v−v ′ k]). The max pos- sible scaled value isV ′ max ≈n· P K = n2 ϵ . 15 Algorithm 1FPTAS for 0/1 Knapsack Problem 1:procedureFPTAS-KNAPSACK(v, w, C, ϵ) 2:Letnbe the number of items. 3:P←max n i=1 vi 4:K← ϵP n 5:Fori= 1, . . . , n:v ′ i ← ⌊v i/K⌋ 6:V ′ ma...
-
[19]
Selection:Starting from root s0, we recur- sively select child nodes satisfying: a∗ = argmax a∈A(s) Q(s, a) +c puct ·P(a|s) p N(s) 1 +N(s, a) ! (8) 16 where Q(s, a) is the estimated value, N(s) is the visit count, and P(a|s) is the prior from the policy (LLM)
-
[20]
Expansion:If node s is not a terminal state, we expand it by sampling k candidate an- swers (Generative Actions) and optionally m retrieval queries (Augmentative Actions)
-
[21]
Simulation (Rollout):From the expanded node, we perform a rollout using the base pol- icyπ θ to generate a complete answery f inal
-
[22]
Backpropagation:We compute the reward R(yf inal) using Eq. 2 and update the Q-values along the trajectory: Q(s, a)← N(s, a)·Q(s, a) +R N(s, a) + 1 (9) C.6 Convergence Analysis of NLI-Guided MCTS We provide a theoretical justification for the use of UCT in the space of logical consistency. Theorem 3 (MCTS Consistency).As the num- ber of simulations N→ ∞ , ...
2006
-
[23]
2) acts as a soft prun- ing mechanism
Exploration:The wcon =−2.0 penalty in our reward function (Eq. 2) acts as a soft prun- ing mechanism. Branches containing contra- dictions yield low Q-values
-
[24]
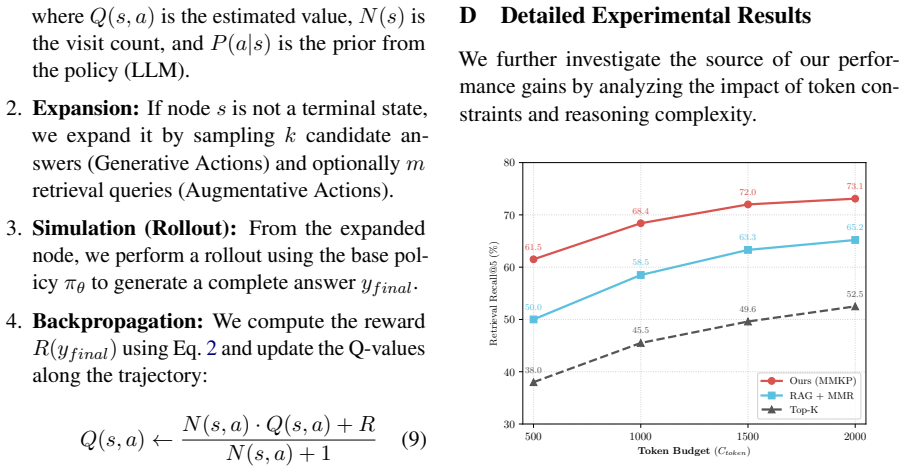
Exploitation:UCT exponentially allocates samples to branches with high entailment scores (went = 1.0). Therefore, provided the NLI model Θ is an approx- imate oracle of truth, the search policyπM CT S con- verges to the sentence sequence y that maximizes logical entailment with the evidence setE.■ D Detailed Experimental Results We further investigate the...
2000
-
[25]
Precondition→Intermediate Inference→Final Conclusion
Decompose the Question:Break down the core query points and the logical link of multi-hop reasoning (e.g., "Precondition→Intermediate Inference→Final Conclusion")
-
[26]
Exclude irrelevant documents
Locate Relevant Documents:Examine candidate document snippets one by one, mark content directly/indirectly related to the core query, and record the correspondingdoc_id. Exclude irrelevant documents
-
[27]
If there is no direct answer, provide aspeculative conclusion consistent with the document context(do not return "unknown")
Integrate Information:If relevant information is fragmented, logically connect it based on the document context. If there is no direct answer, provide aspeculative conclusion consistent with the document context(do not return "unknown")
-
[28]
Verify Rationality:Confirm that the answer originates entirely from the documents, contains no external information, and does not contradict the document content
-
[29]
reasoning
Output Result:Provide a concise answer, the corresponding evidence doc_ids, and explain the deep thinking process. INPUTTEMPLATE: Question:{question} Candidate Document Snippets(Listed bydoc_id, potentially from different articles; content truncated): {context} Please strictly output in the following JSON format. The "reasoning" field must detail the deep...
-
[30]
Reasoning Verification:The MCTS planner expands the search space. When the model initially generates a hallucinated date (Branch π1), the NLI verifier detects a low entailment score (0.12) against the retrieved context, as- signing a negative reward (r=−1.0 ). This prompts the planner to backtrack and explore Branch π2, which successfully extracts the cor...
-
[31]
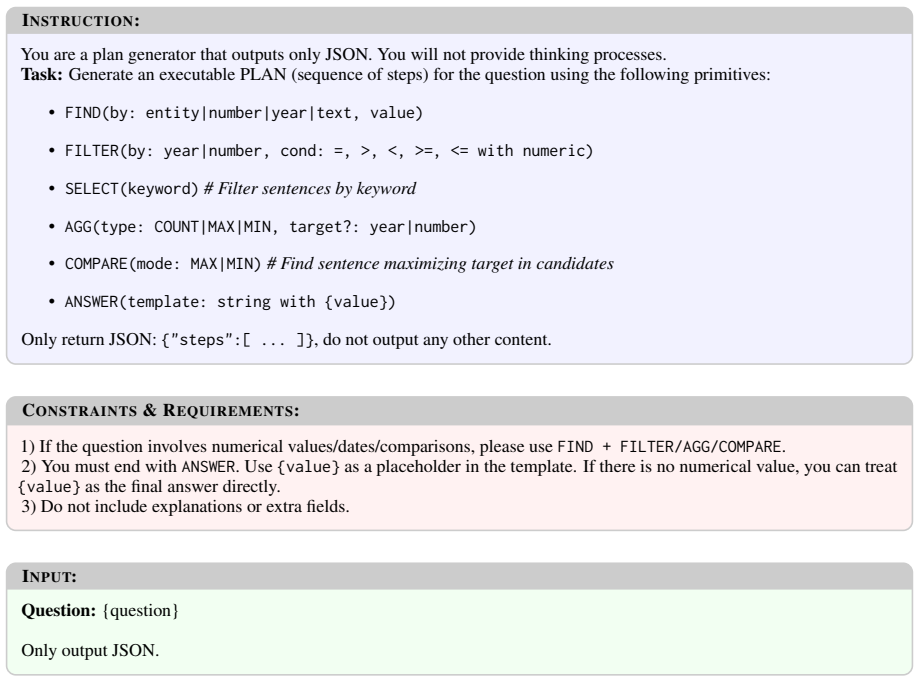
If the question involves numerical values/dates/comparisons, please useFIND + FILTER/AGG/COMPARE
-
[32]
Use {value} as a placeholder in the template
You must end with ANSWER. Use {value} as a placeholder in the template. If there is no numerical value, you can treat {value}as the final answer directly
-
[33]
Who had a longer tenure as CEO of the company that acquired DeepMind: Eric Schmidt or Larry Page?
Do not include explanations or extra fields. INPUT: Question:{question} Only output JSON. Figure 7: The prompt template used for the Symbolic Plan Generator. This prompt restricts the LLM to output a structured execution plan using predefined API primitives. quires bridging entity relationships and precise at- tribute comparison. The query asks:“Who had a...
-
[34]
AI Achievement
MMKP Filtering:The Context Selector groups the “AI Achievement” documents into a single semantic cluster. It recognizes that selecting multiple documents from this clus- ter offers diminishing returns. It effectively prunes the redundancy (similar to the mech- anism described in Section G.1), freeing up token budget to retrieve the specific tenure dates f...
-
[35]
Which magazine was founded first, ’The American Conservative’ (TAC) or ’The Weekly Standard’ (TWS)?
MCTS Verification:The generator initially attempts a heuristic guess (Page > Schmidt). However, the NLI-guided verifier checks this against the retrieved evidence (Schmidt: 10 years vs. Page: 4 years) and penalizes the contradiction (Q=−1.0 ). The planner then backtracks to perform the correct arithmetic comparison, producing a faithful result. 20 INPUTQU...
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.