Recognition: unknown
Engineering Students' Usage and Perceptions of GitHub Copilot in Open-Source Projects
Pith reviewed 2026-05-10 15:38 UTC · model grok-4.3
The pith
Students used GitHub Copilot's chat and code generation features more than other tools when contributing to open-source projects, with usage patterns shaped by gender, programming proficiency, and AI familiarity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
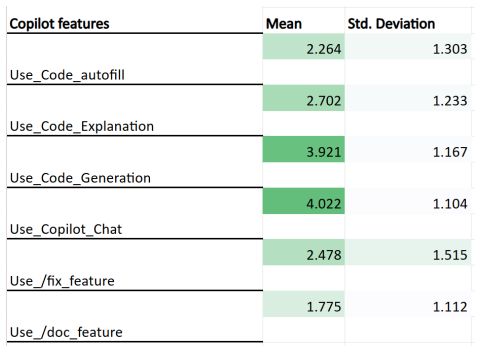
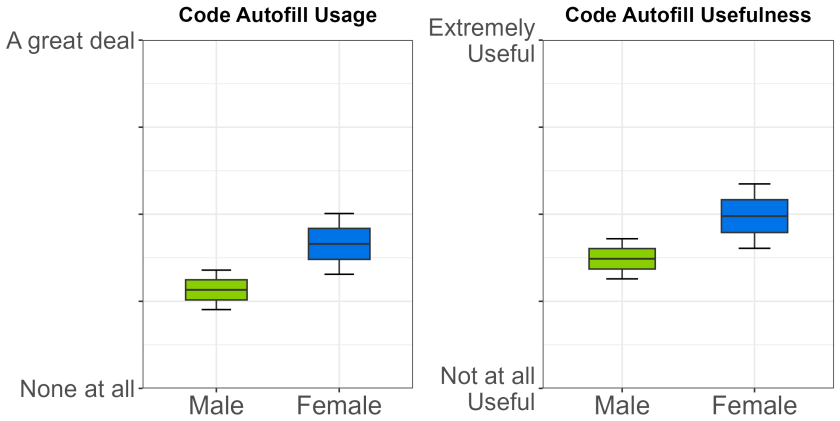
After students contributed to open-source projects with GitHub Copilot, survey responses indicated heavier reliance on the chat feature for code explanation and debugging together with the code generation feature compared with other available functions. Usage frequency and perceptions of the tool's helpfulness showed measurable differences tied to participants' gender, programming proficiency, and familiarity with AI.
What carries the argument
End-of-assignment survey that recorded self-reported frequency of each Copilot feature and perceived usefulness, followed by statistical checks for differences across demographic categories.
If this is right
- Curricula that incorporate AI coding tools may benefit from explicit instruction on chat-based explanation and generation rather than assuming uniform feature uptake.
- Differences in usage suggest that students with lower programming proficiency or less AI experience might require additional support to gain equivalent value from the tool.
- Tool developers could focus refinements on the chat and generation capabilities given their higher reported adoption among learners.
- Open-source project work with these assistants may accelerate students' ability to contribute code while also altering how they debug and understand existing repositories.
Where Pith is reading between the lines
- If demographic factors affect usage, then students without prior AI exposure could enter the workforce with different levels of comfort using similar assistants than their peers.
- The emphasis on real open-source issues rather than toy problems implies these tools might help bridge the gap between classroom exercises and professional collaboration environments.
- Tracking actual usage data alongside surveys in future work would allow direct comparison to test whether reported preferences match observed behavior.
Load-bearing premise
Self-reported survey answers from students in a single course accurately reflect their real usage patterns and the sample supports conclusions about how gender, skill, and AI experience shape tool adoption.
What would settle it
If logs of actual feature interactions from the IDE in a larger set of courses showed no differences by gender, proficiency, or AI familiarity, or if self-reports diverged from those logs, the reported patterns would not hold.
Figures





read the original abstract
The evolution of LLM has resulted in coding-focused models that are able to produce code snippets with high accuracy. More and more AI coding assistant tools are now available, leading to greater integration of AI coding assistants into integrated development environments (IDEs). These tools introduce new possibilities for enhancing software development workflows and changing programming processes. GitHub Copilot, a popular AI coding assistant, offers features including inline code autocompletion, comment-driven code generation, repository-aware suggestions, and a chat interface for code explanation and debugging. Different users use these tools differently due to differences in their perception, prior experience, and demographics. Furthermore, differences in feature use may affect users' programming process and skills, especially for programming learners such as computer science students. While prior work has evaluated the performance of LLM-driven code generation tools, their use and usefulness for developers, especially computer science students, remain underexplored. For our investigation, we conducted an exploratory survey-based study in which participants completed a survey after completing an open-source project issue using GitHub Copilot as part of a course. We analyzed students' use of each feature and their perceived usefulness. Further, we explore and analyze significant differences in GitHub Copilot usage and students' perceptions of it based on demographic factors. Our results show that students used the GitHub Copilot chat feature and code generation feature more than other features. Gender, programming proficiency, and familiarity with AI impacted the usage of the GitHub Copilot feature for assistance in completing the open-source project contribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from an exploratory survey-based study in which engineering students completed an open-source project contribution using GitHub Copilot as part of a course and then responded to a post-project survey. The central claims are that students used the chat and code-generation features more than other Copilot features, and that gender, programming proficiency, and AI familiarity produced statistically significant differences in feature usage for project assistance.
Significance. If the demographic and usage patterns hold under more rigorous validation, the work would supply useful early evidence on how CS students actually engage with specific AI-assistant features during authentic project work. This could inform both tool designers and educators about feature prioritization and potential equity considerations in AI-tool adoption. The exploratory framing and single-course design, however, currently constrain the strength of any generalizable claims.
major comments (3)
- [Abstract] Abstract: the assertion of 'significant differences' in usage by gender, proficiency, and AI familiarity is presented without any accompanying sample size, response rate, statistical test details, or effect-size information, leaving the evidential basis for these claims impossible to evaluate from the provided text.
- [Methods] Methods (survey design): reliance on post-project self-reports from a single course without behavioral telemetry, usage logs, or cross-course replication means the reported feature-usage rankings and demographic effects could be driven by course scaffolding, self-report bias, or small/imbalanced cells rather than stable differences.
- [Results] Results: the headline finding that chat and code-generation features were used more than others, together with the demographic impacts, requires explicit reporting of the number of respondents per demographic category, the exact statistical procedures (including any multiple-comparison corrections), and confidence intervals or effect sizes to determine whether the differences are practically meaningful.
minor comments (1)
- [Abstract] Abstract: adding the achieved sample size and the specific statistical tests used would immediately strengthen the summary of the 'significant differences' claims.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our exploratory survey study. We have revised the manuscript to enhance transparency around sample details, statistical reporting, and study limitations. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'significant differences' in usage by gender, proficiency, and AI familiarity is presented without any accompanying sample size, response rate, statistical test details, or effect-size information, leaving the evidential basis for these claims impossible to evaluate from the provided text.
Authors: We agree the abstract should provide more context for evaluating the claims. In the revision we will add the overall sample size and response rate, briefly note the statistical tests used to identify differences (e.g., chi-square tests), and direct readers to the Results section for effect sizes and confidence intervals. This addresses the evidential gap while respecting abstract length constraints. revision: yes
-
Referee: [Methods] Methods (survey design): reliance on post-project self-reports from a single course without behavioral telemetry, usage logs, or cross-course replication means the reported feature-usage rankings and demographic effects could be driven by course scaffolding, self-report bias, or small/imbalanced cells rather than stable differences.
Authors: We acknowledge these are inherent constraints of the exploratory, single-course survey design. We will expand the Limitations section to discuss self-report bias, potential course-specific scaffolding effects, and the lack of cross-course replication. Because the study collected only post-project survey responses, we cannot add behavioral telemetry or usage logs; we will explicitly note this and recommend future work that combines surveys with logged data. revision: partial
-
Referee: [Results] Results: the headline finding that chat and code-generation features were used more than others, together with the demographic impacts, requires explicit reporting of the number of respondents per demographic category, the exact statistical procedures (including any multiple-comparison corrections), and confidence intervals or effect sizes to determine whether the differences are practically meaningful.
Authors: We will update the Results section to report the number of respondents in each demographic category, specify the exact tests performed (including any multiple-comparison corrections), and include effect sizes together with confidence intervals for the key comparisons. These additions will allow readers to assess both statistical and practical significance. revision: yes
- Absence of behavioral telemetry or usage logs; the study was designed as a post-project survey and therefore cannot supply objective usage data without a new data-collection effort.
Circularity Check
Empirical survey study exhibits no circularity in derivation chain
full rationale
The paper is an exploratory survey-based study relying on post-task self-reported responses from students in a single course. No mathematical derivations, equations, fitted parameters, or self-citations are used to derive the central claims about feature usage and demographic differences. Results are presented as direct outputs of data collection and basic statistical comparisons, with no reduction of predictions to inputs by construction. External citations to prior work on LLM tools are not load-bearing for the uniqueness or validity of the reported findings.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Using github copilot to solve simple programming problems,
M. Wermelinger, “Using github copilot to solve simple programming problems,” inProceed- ings of the 54th ACM Technical Symposium on Computer Science Education V . 1, 2023, pp. 172–178
2023
-
[2]
Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models,
P. Vaithilingam, T. Zhang, and E. L. Glassman, “Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models,” inChi conference on human factors in computing systems extended abstracts, 2022, pp. 1–7
2022
-
[3]
The rise of ai teammates in software engineering (se) 3.0: How autonomous coding agents are reshaping software engineering,
H. Li, H. Zhang, and A. E. Hassan, “The rise of ai teammates in software engineering (se) 3.0: How autonomous coding agents are reshaping software engineering,” inProceedings of the XX. New York, NY , USA: ACM, 2025, pp. 1–22
2025
-
[4]
T. Dohmke. (2023, June 27) The economic impact of the ai- powered developer lifecycle and lessons from github copilot. GitHub Blog. [Online]. Available: https://github.blog/news-insights/research/ the-economic-impact-of-the-ai-powered-developer-lifecycle-and-lessons-from-github-copilot/
2023
-
[5]
Students’ use of github copilot for working with large code bases,
A. Shah, A. Chernova, E. Tomson, L. Porter, W. G. Griswold, and A. G. Soosai Raj, “Students’ use of github copilot for working with large code bases,” inProceedings of the 56th ACM Technical Symposium on Computer Science Education V . 1, ser. SIGCSETS 2025. New York, NY , USA: Association for Computing Machinery, 2025, p. 1050–1056. [Online]. Available: h...
-
[6]
Can ai support student engagement in classroom activities in higher education?
N. Rani, S. Majumder, I. Bhardwaj, and P. G. F. Garcia, “Can ai support student engagement in classroom activities in higher education?”arXiv preprint arXiv:2506.18941, 2025
-
[7]
Chatbots in education and research: A critical examination of ethical implications and solutions,
C. Kooli, “Chatbots in education and research: A critical examination of ethical implications and solutions,”Sustainability, vol. 15, no. 7, 2023. [Online]. Available: https://www.mdpi.com/2071-1050/15/7/5614
2023
-
[8]
Coding with ai: How are tools like chatgpt being used by stu- dents in foundational programming courses,
A. Ghimire and J. Edwards, “Coding with ai: How are tools like chatgpt being used by stu- dents in foundational programming courses,” inInternational Conference on Artificial Intel- ligence in Education. Springer, 2024, pp. 259–267
2024
-
[9]
Chatting with ai: Deciphering developer conversations with chatgpt,
S. Mohamed, A. Parvin, and E. Parra, “Chatting with ai: Deciphering developer conversations with chatgpt,” inProceedings of the 21st International Conference on Mining Software Repositories, ser. MSR ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 187–191. [Online]. Available: https://doi.org/10.1145/3643991.3645078
-
[10]
Investigating the skill gap between graduating students and industry expectations,
A. Radermacher, G. Walia, and D. Knudson, “Investigating the skill gap between graduating students and industry expectations,” inCompanion Proceedings of the 36th international conference on software engineering, 2014, pp. 291–300
2014
-
[11]
Struggles of new college graduates in their first software develop- ment job,
A. Begel and B. Simon, “Struggles of new college graduates in their first software develop- ment job,” inProceedings of the 39th SIGCSE technical symposium on Computer science education, 2008, pp. 226–230
2008
-
[12]
Listening to early career software developers,
M. Craig, P. Conrad, D. Lynch, N. Lee, and L. Anthony, “Listening to early career software developers,”Journal of Computing Sciences in Colleges, vol. 33, no. 4, pp. 138–149, 2018
2018
-
[13]
Gender differences in the adoption, usage, and perceived effectiveness of ai writing tools: a study among university for development studies students,
H. M. Iddrisu, S. A. Iddrisu, and B. Aminu, “Gender differences in the adoption, usage, and perceived effectiveness of ai writing tools: a study among university for development studies students,”International Journal of Educational Innovation and Research, vol. 4, no. 1, pp. 110–111, 2025
2025
-
[14]
Gender bias in self-perception of artificial intel- ligence knowledge, impact, and support among higher education students: An observational study,
C. Cachero, D. Tom ´as, F. A. Pujolet al., “Gender bias in self-perception of artificial intel- ligence knowledge, impact, and support among higher education students: An observational study,” 2025
2025
-
[15]
Stack overflow developer survey 2025,
Stack Overflow, “Stack overflow developer survey 2025,” https://survey.stackoverflow.co/ 2025/, 2025, accessed: 2026-01-12
2025
-
[16]
Feb. 2025. [Online]. Available: https://www.hepi.ac.uk/reports/ student-generative-ai-survey-2025/
2025
-
[17]
Is github copilot a substitute for human pair-programming? an empirical study,
S. Imai, “Is github copilot a substitute for human pair-programming? an empirical study,” inProceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings, 2022, pp. 319–321
2022
-
[18]
Practices and challenges of using github copilot: An empirical study,
B. Zhang, P. Liang, X. Zhou, A. Ahmad, and M. Waseem, “Practices and challenges of using github copilot: An empirical study,”arXiv preprint arXiv:2303.08733, 2023
-
[19]
Generative ai for pull request descriptions: Adoption, impact, and developer interventions,
T. Xiao, H. Hata, C. Treude, and K. Matsumoto, “Generative ai for pull request descriptions: Adoption, impact, and developer interventions,”Proceedings of the ACM on Software Engi- neering, vol. 1, no. FSE, pp. 1043–1065, 2024
2024
-
[20]
F. Song, A. Agarwal, and W. Wen, “The impact of generative ai on collaborative open-source software development: Evidence from github copilot,”arXiv preprint arXiv:2410.02091, 2024
work page internal anchor Pith review arXiv 2024
-
[21]
Self-Admitted GenAI Usage in Open-Source Software
T. Xiao, Y . Fan, F. Calefato, C. Treude, R. G. Kula, H. Hata, and S. Baltes, “Self-admitted genai usage in open-source software,”arXiv preprint arXiv:2507.10422, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Exploring the problems, their causes and solutions of ai pair programming: A study on github and stack overflow,
X. Zhou, P. Liang, B. Zhang, Z. Li, A. Ahmad, M. Shahin, and M. Waseem, “Exploring the problems, their causes and solutions of ai pair programming: A study on github and stack overflow,”Journal of Systems and Software, vol. 219, p. 112204, 2025
2025
-
[23]
Developer Productivity With and Without GitHub Copilot: A Longitudinal Mixed-Methods Case Study
V . Stray, E. G. Brandtzæg, V . T. Wivestad, A. Barbala, and N. B. Moe, “Developer productiv- ity with and without github copilot: A longitudinal mixed-methods case study,”arXiv preprint arXiv:2509.20353, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
The effects of github copilot on computing students’ programming effectiveness, efficiency, and processes in brownfield coding tasks,
M. I. H. Shihab, C. Hundhausen, A. Tariq, S. Haque, Y . Qiao, and B. W. Mulanda, “The effects of github copilot on computing students’ programming effectiveness, efficiency, and processes in brownfield coding tasks,” inProceedings of the 2025 ACM Conference on Inter- national Computing Education Research V . 1, 2025, pp. 407–420
2025
-
[25]
Productivity assessment of neural code completion,
A. Ziegler, E. Kalliamvakou, X. A. Li, A. Rice, D. Rifkin, S. Simister, G. Sittampalam, and E. Aftandilian, “Productivity assessment of neural code completion,” inProceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming, 2022, pp. 21–29
2022
-
[26]
Lost at c: A user study on the security implications of large language model code assistants,
G. Sandoval, H. Pearce, T. Nys, R. Karri, S. Garg, and B. Dolan-Gavitt, “Lost at c: A user study on the security implications of large language model code assistants,” in32nd USENIX Security Symposium (USENIX Security 23), 2023, pp. 2205–2222
2023
-
[27]
Is github’s copilot as bad as humans at introducing vulnerabilities in code?
O. Asare, M. Nagappan, and N. Asokan, “Is github’s copilot as bad as humans at introducing vulnerabilities in code?”Empirical Software Engineering, vol. 28, no. 6, p. 129, 2023
2023
-
[28]
Student-ai interaction: A case study of cs1 students,
M. Amoozadeh, D. Nam, D. Prol, A. Alfageeh, J. Prather, M. Hilton, S. Srinivasa Ragavan, and A. Alipour, “Student-ai interaction: A case study of cs1 students,” inProceedings of the 24th Koli Calling International Conference on Computing Education Research, 2024, pp. 1–13
2024
-
[29]
Self-regulation, self-efficacy, and fear of failure interactions with how novices use llms to solve programming problems,
L. E. Margulieux, J. Prather, B. N. Reeves, B. A. Becker, G. Cetin Uzun, D. Loksa, J. Leinonen, and P. Denny, “Self-regulation, self-efficacy, and fear of failure interactions with how novices use llms to solve programming problems,” inProceedings of the 2024 on Inno- vation and Technology in Computer Science Education V . 1, 2024, pp. 276–282
2024
-
[30]
G. Fan, D. Liu, R. Zhang, and L. Pan, “The impact of ai-assisted pair programming on student motivation, programming anxiety, collaborative learning, and programming performance: a comparative study with traditional pair programming and individual approaches,”Interna- tional Journal of STEM Education, vol. 12, no. 1, p. 16, 2025
2025
-
[31]
Measuring human-computer trust,
M. Madsen and S. Gregor, “Measuring human-computer trust,” in11th australasian confer- ence on information systems, vol. 53. Citeseer, 2000, pp. 6–8
2000
-
[32]
Students’ reliance on ai in higher education: identifying contributing factors,
G. Pitts, N. Rani, W. Mildort, and E.-M. Cook, “Students’ reliance on ai in higher education: identifying contributing factors,” inInternational Conference on Human-Computer Interac- tion. Springer, 2025, pp. 86–97
2025
-
[33]
Trust and Reliance on AI in Education: AI Literacy and Need for Cognition as Moderators
G. Pitts, N. Rani, and W. Mildort, “Trust and reliance on ai in education: Ai literacy and need for cognition as moderators,”arXiv preprint arXiv:2604.01114, 2026. A Appendix A.1 Trust Statements This appendix contains the statements for each of the trust constructs used in the post-study ques- tionnaire. The constructs and their statements are taken from...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.