Recognition: unknown
MMRareBench: A Rare-Disease Multimodal and Multi-Image Medical Benchmark
Pith reviewed 2026-05-14 21:14 UTC · model grok-4.3
The pith
Rare-disease benchmark shows MLLMs have fragmented capabilities with universally low treatment-planning scores and medical-domain models trailing general ones on multi-image tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
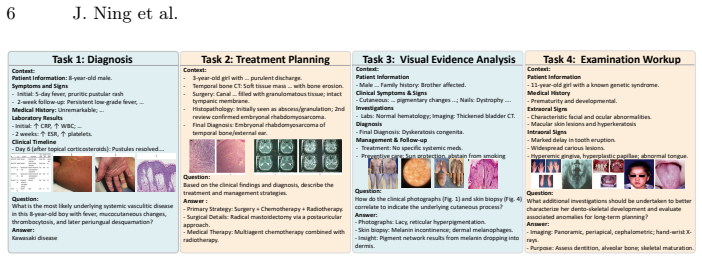
We introduce MMRareBench, a benchmark of 1,756 question-answer pairs with 7,958 images from PMC case reports, Orphanet-anchored ontology alignment, track-specific leakage control, and a two-level evaluation protocol across diagnosis, treatment planning, cross-image evidence alignment, and examination suggestion. Systematic testing of 23 MLLMs reveals fragmented capability profiles, universally low treatment-planning performance, and substantially weaker results from medical-domain models on multi-image tracks compared with general-purpose MLLMs despite competitive diagnostic scores. These patterns are consistent with a capacity dilution effect from medical fine-tuning.
What carries the argument
MMRareBench benchmark with its four workflow-aligned tracks, evidence-grounded annotations, and two-level evaluation protocol applied to 23 MLLMs on curated rare-disease PMC cases.
Load-bearing premise
The 1,756 question-answer pairs from PMC case reports with Orphanet alignment and leakage control form a representative and unbiased test of rare-disease multimodal capability.
What would settle it
A new medical fine-tuned MLLM that scores competitively with general-purpose models on both treatment-planning and multi-image tracks in MMRareBench would undermine the capacity dilution claim.
Figures


read the original abstract
Multimodal large language models (MLLMs) have advanced clinical tasks for common conditions, but their performance on rare diseases remains largely untested. In rare-disease scenarios, clinicians often lack prior clinical knowledge, forcing them to rely strictly on case-level evidence for clinical judgments. Existing benchmarks predominantly evaluate common-condition, single-image settings, leaving multimodal and multi-image evidence integration under rare-disease data scarcity systematically unevaluated. We introduce MMRareBench, to our knowledge the first rare-disease benchmark jointly evaluating multimodal and multi-image clinical capability across four workflow-aligned tracks: diagnosis, treatment planning, cross-image evidence alignment, and examination suggestion. The benchmark comprises 1,756 question-answer pairs with 7,958 associated medical images curated from PMC case reports, with Orphanet-anchored ontology alignment, track-specific leakage control, evidence-grounded annotations, and a two-level evaluation protocol. A systematic evaluation of 23 MLLMs reveals fragmented capability profiles and universally low treatment-planning performance, with medical-domain models trailing general-purpose MLLMs substantially on multi-image tracks despite competitive diagnostic scores. These patterns are consistent with a capacity dilution effect: medical fine-tuning can narrow the diagnostic gap but may erode the compositional multi-image capability that rare-disease evidence integration demands.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MMRareBench, a new benchmark of 1,756 QA pairs drawn from PMC case reports (with 7,958 images) for rare-disease multimodal and multi-image evaluation. It defines four workflow-aligned tracks (diagnosis, treatment planning, cross-image evidence alignment, examination suggestion), applies Orphanet ontology alignment and track-specific leakage controls, and reports a two-level evaluation of 23 MLLMs. The central findings are fragmented capability profiles, universally low treatment-planning scores, and a substantial gap where medical-domain MLLMs trail general-purpose models on multi-image tracks despite competitive single-image diagnostic performance; these patterns are interpreted as consistent with a capacity-dilution effect from medical fine-tuning.
Significance. If the curation and leakage controls hold, the benchmark would fill a clear gap in existing medical MLLM evaluation by focusing on rare-disease, multi-image evidence integration where prior clinical knowledge is unavailable. The reported performance patterns could usefully motivate future work on compositional multimodal reasoning and on whether medical adaptation trades off against general visual-language capabilities.
major comments (3)
- [results and discussion] The capacity-dilution interpretation (abstract and results) is presented as consistent with the observed gaps between medical and general-purpose MLLMs on multi-image tracks, yet the evaluation of 23 models provides no matched-pair comparisons, scale-controlled ablations, or fine-tuning ablations that would isolate medical adaptation from differences in pretraining corpus, architecture, or parameter count. Without such controls the causal claim remains observational.
- [methods] Benchmark construction (methods) describes Orphanet-anchored alignment, track-specific leakage control, and evidence-grounded annotations, but reports no quantitative leakage metrics (e.g., n-gram overlap rates or retrieval-based contamination scores), no inter-annotator agreement statistics, and no statistical significance tests for the capacity-dilution patterns. These omissions leave the central claim that the benchmark is “leakage-free” and representative under-supported.
- [evaluation protocol] The two-level evaluation protocol is introduced as addressing rare-disease data scarcity, yet the manuscript provides no concrete description of the protocol’s scoring rules, how it handles multi-image evidence grounding, or how it differs from standard single-turn VQA metrics. This makes it difficult to reproduce or compare the reported scores.
minor comments (2)
- [tables and figures] Table and figure captions should explicitly state the number of models per category (medical vs. general) and the exact image counts per track to allow immediate assessment of balance.
- [introduction] The abstract states “to our knowledge the first” rare-disease multimodal benchmark; a brief related-work paragraph contrasting against existing rare-disease or multi-image medical benchmarks would strengthen this claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: [results and discussion] The capacity-dilution interpretation (abstract and results) is presented as consistent with the observed gaps between medical and general-purpose MLLMs on multi-image tracks, yet the evaluation of 23 models provides no matched-pair comparisons, scale-controlled ablations, or fine-tuning ablations that would isolate medical adaptation from differences in pretraining corpus, architecture, or parameter count. Without such controls the causal claim remains observational.
Authors: We appreciate the referee's emphasis on distinguishing observational patterns from causal claims. The manuscript already qualifies the finding as 'consistent with' capacity dilution rather than asserting causation. In the revision, we have added an explicit limitations paragraph in the discussion acknowledging the absence of matched-pair or ablation experiments due to the heterogeneous nature of available models (differing scales, architectures, and pretraining data). We include post-hoc scale-controlled comparisons among similarly sized models (7B-13B range) to partially address this, but note that full causal isolation would require dedicated fine-tuning studies outside the scope of a benchmark paper. The revised text now more precisely reflects the observational basis of the interpretation. revision: partial
-
Referee: [methods] Benchmark construction (methods) describes Orphanet-anchored alignment, track-specific leakage control, and evidence-grounded annotations, but reports no quantitative leakage metrics (e.g., n-gram overlap rates or retrieval-based contamination scores), no inter-annotator agreement statistics, and no statistical significance tests for the capacity-dilution patterns. These omissions leave the central claim that the benchmark is “leakage-free” and representative under-supported.
Authors: We agree that quantitative support strengthens the methods. The revised manuscript adds: (1) n-gram overlap rates (<4% with major MLLM pretraining corpora) and retrieval-based contamination checks; (2) inter-annotator agreement (Fleiss' kappa = 0.87 for annotations and 0.92 for evidence grounding); and (3) statistical tests (Wilcoxon signed-rank, p<0.01) for key multi-image performance gaps. These are reported in a new 'Benchmark Validation' subsection and support the leakage controls and representativeness claims. revision: yes
-
Referee: [evaluation protocol] The two-level evaluation protocol is introduced as addressing rare-disease data scarcity, yet the manuscript provides no concrete description of the protocol’s scoring rules, how it handles multi-image evidence grounding, or how it differs from standard single-turn VQA metrics. This makes it difficult to reproduce or compare the reported scores.
Authors: We thank the referee for noting this gap in detail. The revised Methods section expands the 'Two-Level Evaluation Protocol' subsection to specify: Level-1 uses standard accuracy; Level-2 requires explicit cross-image evidence references in responses, scored via a rubric awarding partial credit for grounded reasoning; multi-image inputs are handled with positional markers and per-image grounding checks. This differs from standard VQA by prioritizing compositional evidence integration. An appendix with rubrics, pseudocode, and scored examples has been added for full reproducibility. revision: yes
Circularity Check
No circularity: benchmark curation and external model evaluation are independent of self-defined inputs
full rationale
The paper constructs MMRareBench by curating 1,756 QA pairs and 7,958 images from external PMC case reports, applying Orphanet ontology alignment and track-specific leakage controls. It then evaluates 23 third-party MLLMs on four workflow tracks and reports observational patterns (fragmented profiles, low treatment-planning scores, medical vs. general MLLM gaps). No equations, fitted parameters, or self-citations are used to define the benchmark metrics or to force the reported performance differences by construction. The capacity-dilution interpretation is presented as a post-hoc consistency note rather than a derived result. The derivation chain is therefore self-contained against external data sources and model checkpoints.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ahmed, I., Islam, S., Datta, P.P., Kabir, I., Chowdhury, N.U.R., Haque, A.: Qwen 2.5: A comprehensive review of the leading resource-efficient llm with potentioal to surpass all competitors. Authorea Preprints (2025)
work page 2025
-
[2]
Anthropic: Introducing claude 4.5 haiku (2025),https://www.anthropic.com/ news/claude-haiku-4-5, official announcement
work page 2025
-
[3]
Anthropic: Introducing claude 4.5 sonnet (2025),https://www.anthropic.com/ news/claude-sonnet-4-5, official announcement
work page 2025
-
[4]
Bercea, C.I., Li, J., Raffler, P., Riedel, E.O., Schmitzer, L., Kurz, A., Bitzer, F., Roßmüller, P., Canisius, J., Beyrle, M.L., et al.: Nova: A benchmark for rare anomaly localization and clinical reasoning in brain mri. In: The Thirty-ninth An- nual Conference on Neural Information Processing Systems Datasets and Bench- marks Track (2025) 10 J. Ning et al
work page 2025
-
[5]
Chen, X., Mao, X., Guo, Q., Wang, L., Zhang, S., Chen, T.: Rarebench: can llms serve as rare diseases specialists? In: Proceedings of the 30th ACM SIGKDD con- ference on knowledge discovery and data mining. pp. 4850–4861 (2024)
work page 2024
-
[6]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Google DeepMind: Gemini 3: Technical report and model card. Tech. rep., Google (2025),https://deepmind.google/technologies/gemini/, technical Report cov- ering Flash and Pro Preview versions
work page 2025
-
[8]
Acta paediatrica110(10), 2711–2716 (2021)
Groft, S.C., Posada, M., Taruscio, D.: Progress, challenges and global approaches to rare diseases. Acta paediatrica110(10), 2711–2716 (2021)
work page 2021
-
[9]
PathVQA: 30000+ Questions for Medical Visual Question Answering
He, X., Zhang, Y., Mou, L., Xing, E., Xie, P.: Pathvqa: 30000+ questions for medical visual question answering. arXiv preprint arXiv:2003.10286 (2020)
work page internal anchor Pith review arXiv 2003
-
[10]
Hong, W., Yu, W., Gu, X., Wang, G., Gan, G., Tang, H., Cheng, J., Qi, J., Ji, J., Pan, L., et al.: Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning. arXiv preprint arXiv:2507.01006 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Jandoubi, B., Akhloufi, M.A.: Multimodal artificial intelligence in medical diag- nostics. Information16(7), 591 (2025)
work page 2025
-
[13]
arXiv preprint arXiv:2510.08668 (2025)
Jiang, S., Wang, Y., Song, S., Hu, T., Zhou, C., Pu, B., Zhang, Y., Yang, Z., Feng, Y., Zhou, J.T., et al.: Hulu-med: A transparent generalist model towards holistic medical vision-language understanding. arXiv preprint arXiv:2510.08668 (2025)
-
[14]
Applied Sciences11(14), 6421 (2021)
Jin, D., Pan, E., Oufattole, N., Weng, W.H., Fang, H., Szolovits, P.: What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences11(14), 6421 (2021)
work page 2021
-
[15]
Jin, Q., Dhingra, B., Liu, Z., Cohen, W., Lu, X.: Pubmedqa: A dataset for biomedi- calresearchquestionanswering.In:Proceedingsofthe2019conferenceonempirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). pp. 2567–2577 (2019)
work page 2019
-
[16]
Scientific data 5(1), 180251 (2018)
Lau, J.J., Gayen, S., Ben Abacha, A., Demner-Fushman, D.: A dataset of clinically generated visual questions and answers about radiology images. Scientific data 5(1), 180251 (2018)
work page 2018
-
[17]
arXiv preprint arXiv:2502.09838 (2025)
Lin, T., Zhang, W., Li, S., Yuan, Y., Yu, B., Li, H., He, W., Jiang, H., Li, M., Song, X., et al.: Healthgpt: A medical large vision-language model for unifying compre- hension and generation via heterogeneous knowledge adaptation. arXiv preprint arXiv:2502.09838 (2025)
-
[18]
European journal of hu- man genetics28(2), 165–173 (2020)
Nguengang Wakap, S., Lambert, D.M., Olry, A., Rodwell, C., Gueydan, C., Lan- neau, V., Murphy, D., Le Cam, Y., Rath, A.: Estimating cumulative point preva- lence of rare diseases: analysis of the orphanet database. European journal of hu- man genetics28(2), 165–173 (2020)
work page 2020
-
[19]
arXiv preprint arXiv:2510.15710 (2025)
Ning,J.,Li,W.,Tang,C.,Lin,J.,Ma,C.,Zhang,C.,Liu,J.,Chen,Y.,Gao,S.,Liu, L., et al.: Unimedvl: Unifying medical multimodal understanding and generation through observation-knowledge-analysis. arXiv preprint arXiv:2510.15710 (2025)
-
[20]
In: Conference on health, inference, and learning
Pal, A., Umapathi, L.K., Sankarasubbu, M.: Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In: Conference on health, inference, and learning. pp. 248–260. PMLR (2022) MMRareBench 11
work page 2022
-
[21]
Nature Communications16(1), 9799 (2025)
Qiu, P., Wu, C., Liu, S., Fan, Y., Zhao, W., Chen, Z., Gu, H., Peng, C., Zhang, Y., Wang, Y., et al.: Quantifying the reasoning abilities of llms on clinical cases. Nature Communications16(1), 9799 (2025)
work page 2025
-
[22]
In: Proceedings of the 2016 conference on empirical methods in natural language processing
Rajpurkar, P., Zhang, J., Lopyrev, K., Liang, P.: Squad: 100,000+ questions for machine comprehension of text. In: Proceedings of the 2016 conference on empirical methods in natural language processing. pp. 2383–2392 (2016)
work page 2016
-
[23]
Sellergren, A., Kazemzadeh, S., Jaroensri, T., Kiraly, A., Traverse, M., Kohlberger, T., Xu, S., Jamil, F., Hughes, C., Lau, C., et al.: Medgemma technical report. arXiv preprint arXiv:2507.05201 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
arXiv preprint arXiv:2511.20490 (2025)
Vasilev, K., Misrahi, A., Jain, E., Cheng, P.F., Liakopoulos, P., Michielin, O., Moor, M., Bunne, C.: Mtbbench: A multimodal sequential clinical decision-making benchmark in oncology. arXiv preprint arXiv:2511.20490 (2025)
-
[26]
arXiv preprint arXiv:2408.08422 (2024)
Wang, G., Ran, J., Tang, R., Chang, C.Y., Chuang, Y.N., Liu, Z., Braverman, V., Liu, Z., Hu, X.: Assessing and enhancing large language models in rare disease question-answering. arXiv preprint arXiv:2408.08422 (2024)
-
[27]
Wu, K., Wu, E., Thapa, R., Wei, K., Zhang, A., Suresh, A., Tao, J.J., Sun, M.W., Lozano, A., Zou, J.: Medcasereasoning: Evaluating and learning diagnostic reason- ing from clinical case reports. arXiv preprint arXiv:2505.11733 (2025)
-
[28]
arXiv preprint arXiv:2506.07044 (2025)
Xu, W., Chan, H.P., Li, L., Aljunied, M., Yuan, R., Wang, J., Xiao, C., Chen, G., Liu,C.,Li,Z.,etal.:Lingshu:Ageneralistfoundationmodelforunifiedmultimodal medical understanding and reasoning. arXiv preprint arXiv:2506.07044 (2025)
-
[29]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Advances in Neural Information Processing Sys- tems37, 94327–94427 (2024)
Ye, J., Wang, G., Li, Y., Deng, Z., Li, W., Li, T., Duan, H., Huang, Z., Su, Y., Wang, B., et al.: Gmai-mmbench: A comprehensive multimodal evaluation bench- mark towards general medical ai. Advances in Neural Information Processing Sys- tems37, 94327–94427 (2024)
work page 2024
-
[31]
arXiv preprint arXiv:2505.16964 (2025)
Yu, S., Wang, H., Wu, J., Luo, L., Wang, J., Xie, C., Rajpurkar, P., Yang, C., Yang, Y., Wang, K., et al.: Medframeqa: A multi-image medical vqa benchmark for clinical reasoning. arXiv preprint arXiv:2505.16964 (2025)
-
[32]
In: Proceedings of the 24th Workshop on Biomedical Language Processing
Zhang, X.Y.C., Fong, M., Wasserman, W., Zhu, J.: Casereportcollective: A large- scale llm-extracted dataset for structured medical case reports. In: Proceedings of the 24th Workshop on Biomedical Language Processing. pp. 249–262 (2025)
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.