Recognition: unknown
VulWeaver: Weaving Broken Semantics for Grounded Vulnerability Detection
Pith reviewed 2026-05-10 15:27 UTC · model grok-4.3
The pith
VulWeaver repairs inaccurate static-analysis dependency graphs by integrating LLM semantic inference with deterministic rules to support grounded vulnerability detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
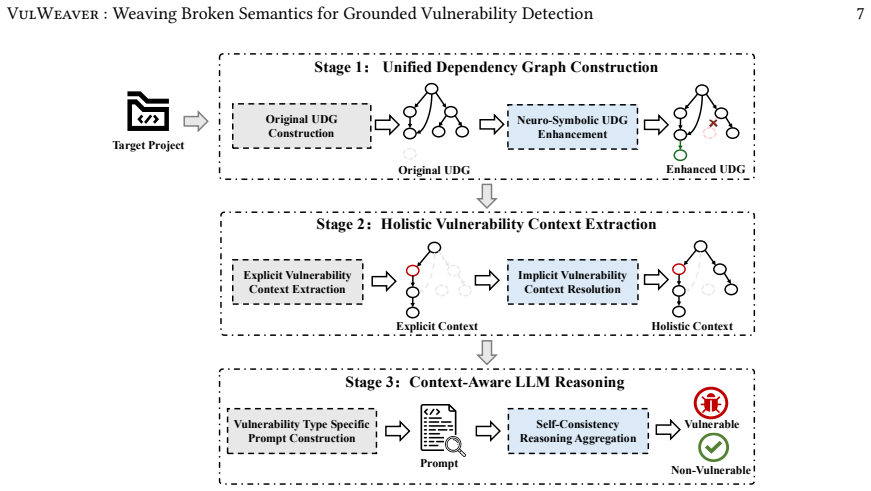
VulWeaver constructs an enhanced unified dependency graph by integrating deterministic rules with LLM-based semantic inference to address static analysis inaccuracies. It extracts holistic vulnerability context by combining explicit contexts from program slicing with implicit contexts including usage, definition, and declaration information. VulWeaver then employs meta-prompting with vulnerability type specific expert guidelines to steer LLMs through systematic reasoning, aggregated via majority voting for robustness.
What carries the argument
The enhanced unified dependency graph (UDG) created by merging static rules and LLM inference, paired with holistic context extraction from slicing and implicit program information.
If this is right
- More accurate identification of vulnerabilities in large codebases.
- Ability to detect issues that pure static or pure LLM methods miss.
- Practical application in real-world projects resulting in confirmed security fixes and CVEs.
- Improved robustness through voting mechanisms in LLM outputs.
Where Pith is reading between the lines
- The technique might generalize to detecting other types of code defects beyond security vulnerabilities.
- Future tools could automate more of the graph repair process to reduce reliance on LLMs.
- Combining this with dynamic analysis could further validate the inferred semantics.
Load-bearing premise
LLM-based semantic inference can reliably correct inaccuracies in static analysis dependency graphs without introducing new errors or hallucinations.
What would settle it
Demonstrating on a benchmark that removing the LLM inference step from VulWeaver results in equal or better performance than the full method.
Figures





read the original abstract
Detecting vulnerabilities in source code remains critical yet challenging, as conventional static analysis tools construct inaccurate program representations, while existing LLM-based approaches often miss essential vulnerability context and lack grounded reasoning. To mitigate these challenges, we introduce VulWeaver, a novel LLM-based approach that weaves broken program semantics into accurate representations and extracts holistic vulnerability context for grounded vulnerability detection. Specifically, VulWeaver first constructs an enhanced unified dependency graph (UDG) by integrating deterministic rules with LLM-based semantic inference to address static analysis inaccuracies. It then extracts holistic vulnerability context by combining explicit contexts from program slicing with implicit contexts, including usage, definition, and declaration information. Finally, VulWeaver employs meta-prompting with vulnerability type specific expert guidelines to steer LLMs through systematic reasoning, aggregated via majority voting for robustness. Extensive experiments on PrimeVul4J dataset have demonstrated that VulWeaver achieves a F1-score of 0.75, outperforming state-of-the-art learning-based, LLM-based, and agent-based baselines by 23%, 15%, and 60% in F1-score, respectively. VulWeaver has also detected 26 true vulnerabilities across 9 realworld Java projects, with 15 confirmed by developers and 5 CVE identifiers assigned. In industrial deployment, VulWeaver identified 40 confirmed vulnerabilities in an internal repository.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VulWeaver, an LLM-based vulnerability detection method that first builds an enhanced unified dependency graph (UDG) by combining deterministic static-analysis rules with LLM semantic inference to repair inaccuracies, then extracts holistic context via program slicing (explicit) plus implicit usage/definition/declaration information, and finally applies meta-prompting with type-specific expert guidelines plus majority voting for grounded reasoning. On the PrimeVul4J dataset it reports an F1-score of 0.75, outperforming learning-based, LLM-based and agent-based baselines by 23%, 15% and 60% respectively; it also claims 26 true positives across nine real-world Java projects (15 developer-confirmed, 5 CVEs) and 40 confirmed vulnerabilities in an industrial deployment.
Significance. If the core mechanism is validated, the work offers a concrete hybrid that grounds LLM reasoning in repaired program semantics rather than relying on either pure static analysis or unanchored prompting. The real-world component—developer confirmations, CVE assignments, and industrial deployment—provides stronger external evidence of utility than benchmark numbers alone and could influence follow-on research on LLM-augmented dependency graphs for security.
major comments (3)
- [UDG construction / enhancement (described in abstract and §3)] The central claim attributes performance gains to the LLM-repaired UDG, yet no quantitative validation of the inferred edges is reported (e.g., precision/recall of LLM-added call/dependency edges against manual inspection or an oracle). Without this measurement, it remains possible that the reported 0.75 F1 and real-world detections stem primarily from the meta-prompting and voting rather than from accurate semantic repair.
- [Evaluation / experiments (abstract and §4)] The experimental claims (F1=0.75, relative improvements, real-world detections) are presented without protocol details, baseline re-implementation descriptions, statistical significance tests, ablation results, or leakage-prevention measures. This absence makes it impossible to assess whether the performance delta is robust or reproducible.
- [Real-world and industrial evaluation (abstract and §5)] The real-world evaluation reports 26 detections with 15 confirmations and 5 CVEs but does not specify project-selection criteria, how candidate sites were sampled, or the false-positive rate observed by developers. This information is necessary to judge whether the method generalizes beyond the benchmark.
minor comments (2)
- [Context extraction] Notation for the three context types (explicit, usage, definition, declaration) is introduced without a compact summary table or diagram that would help readers track how each feeds into the final prompt.
- [Abstract / evaluation summary] The abstract states 'extensive experiments' but the provided text contains no dataset statistics (e.g., number of vulnerable/non-vulnerable samples in PrimeVul4J) or per-baseline precision/recall tables.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments highlight important areas for strengthening the manuscript's clarity and rigor. We address each major comment below and will incorporate the suggested revisions in the next version of the paper.
read point-by-point responses
-
Referee: [UDG construction / enhancement (described in abstract and §3)] The central claim attributes performance gains to the LLM-repaired UDG, yet no quantitative validation of the inferred edges is reported (e.g., precision/recall of LLM-added call/dependency edges against manual inspection or an oracle). Without this measurement, it remains possible that the reported 0.75 F1 and real-world detections stem primarily from the meta-prompting and voting rather than from accurate semantic repair.
Authors: We agree that a direct quantitative evaluation of the LLM-inferred edges would provide stronger support for attributing gains to the UDG repair step. While the end-to-end F1 improvements and real-world detections offer indirect evidence, we will add a validation subsection reporting precision and recall of a sampled set of LLM-added edges against manual oracle inspection in the revised manuscript. revision: yes
-
Referee: [Evaluation / experiments (abstract and §4)] The experimental claims (F1=0.75, relative improvements, real-world detections) are presented without protocol details, baseline re-implementation descriptions, statistical significance tests, ablation results, or leakage-prevention measures. This absence makes it impossible to assess whether the performance delta is robust or reproducible.
Authors: We acknowledge that additional experimental details are required for reproducibility. In the revised Section 4 we will include: full protocol and dataset split descriptions, baseline re-implementation details, statistical significance tests, ablation studies isolating each component (UDG repair, context extraction, meta-prompting), and explicit leakage-prevention steps. revision: yes
-
Referee: [Real-world and industrial evaluation (abstract and §5)] The real-world evaluation reports 26 detections with 15 confirmations and 5 CVEs but does not specify project-selection criteria, how candidate sites were sampled, or the false-positive rate observed by developers. This information is necessary to judge whether the method generalizes beyond the benchmark.
Authors: We will expand the real-world evaluation to specify project selection criteria (popularity, domain diversity, historical vulnerability presence), the sampling procedure for candidate sites, and the false-positive rates observed during developer confirmation. These additions will better substantiate generalizability claims. revision: yes
Circularity Check
No circularity: purely empirical pipeline evaluation
full rationale
The paper presents VulWeaver as a composite system (deterministic UDG construction + LLM semantic inference + slicing + meta-prompting + majority voting) whose central claims are F1=0.75 on PrimeVul4J and 26 real-world detections. These are reported as direct experimental outcomes against external baselines; no equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The LLM repair step is described procedurally rather than proven by construction, and performance deltas are anchored to held-out test sets and developer confirmations rather than to any internal normalization or self-referential input. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026.Replicating Material for VulWeaver
anonymous. 2026.Replicating Material for VulWeaver. Retrieved January 20, 2026 from https://github.com/weaver4VD/VulWeaver
2026
-
[2]
2026.Claude
Anthropic. 2026.Claude. Retrieved January 20, 2026 from https://claude.ai
2026
-
[3]
Guru Bhandari, Amara Naseer, and Leon Moonen. 2021. CVEfixes: automated collection of vulnerabilities and their fixes from open-source software. InProceedings of the 17th International Conference on Predictive Models and Data Analytics in Software Engineering. 30–39
2021
-
[4]
Xiao Cheng, Haoyu Wang, Jiayi Hua, Guoai Xu, and Yulei Sui. 2021. Deepwukong: Statically detecting software vulnerabilities using deep graph neural network.ACM Transactions on Software Engineering and Methodology (TOSEM)30, 3 (2021), 1–33
2021
-
[5]
2024.CWE VIEW: Research Concepts
CWE. 2024.CWE VIEW: Research Concepts. Retrieved May 25, 2024 from https://cwe.mitre.org/data/definitions/1000.html
2024
-
[6]
2024.CWE VIEW: Software Development
CWE. 2024.CWE VIEW: Software Development. Retrieved May 25, 2024 from https://cwe.mitre.org/data/definitions/699.html
2024
-
[7]
2026.DeepSeek
DeepSeek. 2026.DeepSeek. Retrieved January 20, 2026 from https://www.deepseek.com
2026
- [9]
-
[10]
Yangruibo Ding, Yanjun Fu, Omniyyah Ibrahim, Chawin Sitawarin, Xinyun Chen, Basel Alomair, David Wagner, Baishakhi Ray, and Yizheng Chen
-
[11]
https://github.com/DLVulDet/PrimeVul
Replication Package of PrimeVul. https://github.com/DLVulDet/PrimeVul
- [12]
- [13]
-
[14]
Xueying Du, Geng Zheng, Kaixin Wang, Yi Zou, Yujia Wang, Wentai Deng, Jiayi Feng, Mingwei Liu, Bihuan Chen, Xin Peng, et al. 2024. Vul-rag: Enhancing llm-based vulnerability detection via knowledge-level rag.ACM Transactions on Software Engineering and Methodology(2024)
2024
-
[15]
2026.Dataset collection scipts of Reposvul
Eshe0922. 2026.Dataset collection scipts of Reposvul. Retrieved January 24, 2026 from https://github.com/Eshe0922/ReposVul
2026
-
[16]
2026.Dataset collection scipts of CrossVul
GiorgosNikitopoulos. 2026.Dataset collection scipts of CrossVul. Retrieved January 24, 2026 from https://zenodo.org/records/4741963
-
[17]
2026.CodeQL
GitHub. 2026.CodeQL. Retrieved January 20, 2026 from https://codeql.github.com/
2026
-
[18]
2026.GitHub Octoverse
GitHub. 2026.GitHub Octoverse. Retrieved January 20, 2026 from https://github.blog/news-insights/octoverse/octoverse-a-new-developer-joins- github-every-second-as-ai-leads-typescript-to-1
2026
-
[19]
2026.Google Gemini
Google. 2026.Google Gemini. Retrieved January 20, 2026 from https://gemini.google.com/
2026
- [20]
-
[21]
Yiheng Huang, Wen Zheng, Susheng Wu, Bihuan Chen, You Lu, Zhuotong Zhou, Yiheng Cao, Xiaoyu Li, and Xin Peng. [n. d.]. PROFMAL: Detecting Malicious NPM Packages by the Synergy between Static and Dynamic Analysis. ([n. d.])
-
[22]
Davy Landman, Alexander Serebrenik, and Jurgen J Vinju. 2017. Challenges for static analysis of java reflection-literature review and empirical study. In2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE). IEEE, 507–518
2017
-
[23]
Ahmed Lekssays, Hamza Mouhcine, Khang Tran, Ting Yu, and Issa Khalil. 2025. {LLMxCPG}:{Context-Aware} Vulnerability Detection Through Code Property{Graph-Guided}Large Language Models. In34th USENIX Security Symposium (USENIX Security 25). 489–507
2025
- [24]
-
[25]
Zhen Li, Ning Wang, Deqing Zou, Yating Li, Ruqian Zhang, Shouhuai Xu, Chao Zhang, and Hai Jin. 2024. On the Effectiveness of Function-Level Vulnerability Detectors for Inter-Procedural Vulnerabilities. (2024), 1–12
2024
-
[26]
Zhen Li, Deqing Zou, Shouhuai Xu, Hai Jin, Hanchao Qi, and Jie Hu. 2016. Vulpecker: an automated vulnerability detection system based on code similarity analysis. InProceedings of the 32nd annual conference on computer security applications. 201–213
2016
-
[27]
Zhen Li, Deqing Zou, Shouhuai Xu, Hai Jin, Yawei Zhu, and Zhaoxuan Chen. 2021. Sysevr: A framework for using deep learning to detect software vulnerabilities.IEEE Transactions on Dependable and Secure Computing19, 4 (2021), 2244–2258
2021
- [28]
-
[29]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics12 (2024), 157–173
2024
-
[30]
Guilong Lu, Xiaolin Ju, Xiang Chen, Wenlong Pei, and Zhilong Cai. 2024. GRACE: Empowering LLM-based software vulnerability detection with graph structure and in-context learning.Journal of Systems and Software212 (2024), 112031
2024
-
[31]
Georgios Nikitopoulos, Konstantina Dritsa, Panos Louridas, and Dimitris Mitropoulos. 2021. CrossVul: a cross-language vulnerability dataset with commit data. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 1565–1569
2021
- [32]
-
[33]
2026.CVE-2020-26282 Details
NVD. 2026.CVE-2020-26282 Details. Retrieved January 20, 2026 from https://nvd.nist.gov/vuln/detail/CVE-2020-262823
2026
-
[34]
2026.CVE-2023-29523 Details
NVD. 2026.CVE-2023-29523 Details. Retrieved January 20, 2026 from https://nvd.nist.gov/vuln/detail/CVE-2023-29523 Manuscript submitted to ACM VulWeaver: Weaving Broken Semantics for Grounded Vulnerability Detection 27
2026
-
[35]
2026.ChatGPT
OpenAI. 2026.ChatGPT. Retrieved January 20, 2026 from https://chatgpt.com/
2026
-
[36]
2026.Open Standard Java Documentation
oracle. 2026.Open Standard Java Documentation. Retrieved January 20, 2026 from https://docs.oracle.com/en/java/javase/11/
2026
-
[37]
2026.Open Source Scripts for LLMxCPG
qcri. 2026.Open Source Scripts for LLMxCPG. Retrieved January 20, 2026 from https://github.com/qcri/llmxcpg
2026
-
[38]
2026.Dataset collection scipts of CVEfixes
secureIT project. 2026.Dataset collection scipts of CVEfixes. Retrieved January 24, 2026 from https://github.com/secureIT-project/CVEfixes
2026
-
[39]
Youkun Shi, Yuan Zhang, Tianhan Luo, Guangliang Yang, Shengke Ye, Chengyu Yang, Fengyu Liu, Xiapu Luo, and Min Yang. 2025. PHPJoy: A Novel Extended Graph-based PHP Code Analysis Framework.IEEE Transactions on Software Engineering(2025)
2025
-
[40]
2026.Joern
ShiftLeftSecurity. 2026.Joern. Retrieved January 20, 2026 from https://github.com/ShiftLeftSecurity/joern
2026
-
[41]
Benjamin Steenhoek, Hongyang Gao, and Wei Le. 2024. Dataflow Analysis-Inspired Deep Learning for Efficient Vulnerability Detection. In Proceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–13
2024
-
[42]
Benjamin Steenhoek, Md Mahbubur Rahman, Monoshi Kumar Roy, Mirza Sanjida Alam, Earl T Barr, and Wei Le. 2024. A comprehensive study of the capabilities of large language models for vulnerability detection.CoRR(2024)
2024
- [43]
-
[44]
Karl Tamberg and Hayretdin Bahsi. 2025. Harnessing large language models for software vulnerability detection: A comprehensive benchmarking study.IEEE Access(2025)
2025
-
[45]
2018.Tree-sitter: a parser generator tool and an incremental parsing library
Tree-sitter. 2018.Tree-sitter: a parser generator tool and an incremental parsing library. Retrieved January 20, 2026 from https://tree-sitter.github.io/tree- sitter/
2018
-
[46]
Saad Ullah, Mingji Han, Saurabh Pujar, Hammond Pearce, Ayse Coskun, and Gianluca Stringhini. 2024. Llms cannot reliably identify and reason about security vulnerabilities (yet?): A comprehensive evaluation, framework, and benchmarks. In2024 IEEE symposium on security and privacy (SP). IEEE, 862–880
2024
-
[47]
Chengpeng Wang, Wuqi Zhang, Zian Su, Xiangzhe Xu, Xiaoheng Xie, and Xiangyu Zhang. 2024. LLMDFA: analyzing dataflow in code with large language models.Advances in Neural Information Processing Systems37 (2024), 131545–131574
2024
-
[48]
Xinchen Wang, Ruida Hu, Cuiyun Gao, Xin-Cheng Wen, Yujia Chen, and Qing Liao. 2024. Reposvul: A repository-level high-quality vulnerability dataset. InProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings. 472–483
2024
-
[49]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [50]
-
[51]
Ratnadira Widyasari, Martin Weyssow, Ivana Clairine Irsan, Han Wei Ang, Frank Liauw, Eng Lieh Ouh, Lwin Khin Shar, Hong Jin Kang, and David Lo. 2025. Let the Trial Begin: A Mock-Court Approach to Vulnerability Detection using LLM-Based Agents.arXiv preprint arXiv:2505.10961(2025)
-
[52]
2026.PageRTarjan’s strongly connected components algorithmank
Wikipedia. 2026.PageRTarjan’s strongly connected components algorithmank. Retrieved January 20, 2026 from https://en.wikipedia.org/wiki/Tarjan% 27s_strongly_connected_components_algorithm
2026
-
[53]
2026.Reaching definition Worklist algorithm
Wikipedia. 2026.Reaching definition Worklist algorithm. Retrieved January 20, 2026 from https://en.wikipedia.org/wiki/Reaching_definition# Worklist_algorithm
2026
-
[54]
Bozhi Wu, Chengjie Liu, Zhiming Li, Yushi Cao, Jun Sun, and Shang-Wei Lin. 2025. Enhancing Vulnerability Detection via Inter-procedural Semantic Completion.Proceedings of the ACM on Software Engineering2, ISSTA (2025), 825–847
2025
-
[55]
Bozhi Wu, Shangqing Liu, Yang Xiao, Zhiming Li, Jun Sun, and Shang-Wei Lin. 2023. Learning program semantics for vulnerability detection via vulnerability-specific inter-procedural slicing. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 1371–1383
2023
-
[56]
2026.Grok
xAI. 2026.Grok. Retrieved January 20, 2026 from https://grok.com/
2026
- [57]
-
[58]
Zhengmin Yu, Yuan Zhang, Ming Wen, Yinan Nie, Wenhui Zhang, and Min Yang. 2025. CXXCrafter: An LLM-Based Agent for Automated C/C++ Open Source Software Building.Proceedings of the ACM on Software Engineering2, FSE (2025), 2618–2640
2025
-
[59]
Ting Yuan, Wenrui Zhang, Dong Chen, and Jie Wang. 2025. CG-Bench: Can Language Models Assist Call Graph Construction in the Real World?. In Proceedings of the 1st ACM SIGPLAN International Workshop on Language Models and Programming Languages. 12–20
2025
-
[60]
Chenyuan Zhang, Hao Liu, Jiutian Zeng, Kejing Yang, Yuhong Li, and Hui Li. 2024. Prompt-enhanced software vulnerability detection using chatgpt. InProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings. 276–277
2024
- [61]
-
[62]
Xin Zhou, Ting Zhang, and David Lo. 2024. Large language model for vulnerability detection: Emerging results and future directions. InProceedings of the 2024 ACM/IEEE 44th International Conference on Software Engineering: New Ideas and Emerging Results. 47–51
2024
-
[63]
Yaqin Zhou, Shangqing Liu, Jingkai Siow, Xiaoning Du, and Yang Liu. 2019. Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks.Advances in neural information processing systems32 (2019)
2019
- [64]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.