Recognition: unknown
Econometric Inference with Machine-Learned Proxies: Partial Identification via Data Combination
Pith reviewed 2026-05-10 15:08 UTC · model grok-4.3
The pith
Econometric models using machine-learned proxies can deliver sharp partial identification and valid inference by linking a main sample to an auxiliary validation sample through unconditional optimal transport.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that treating the machine-learned proxy as a linking variable between the downstream sample and the auxiliary validation sample yields a sharp identified set for general moment models via an unconditional optimal transport characterization, together with an inference procedure that achieves correct asymptotic size control using analytical critical values without any resampling.
What carries the argument
Unconditional optimal transport characterization of the joint distribution of the proxy and target variable that produces the tightest possible bounds on the downstream moments.
If this is right
- Applied researchers obtain informative confidence sets for parameters in moment models even when the machine learning proxy has unknown predictive accuracy.
- The method extends to any general moment model without requiring the machine learning procedure to be consistent or to have a known convergence rate.
- Inference requires only analytical critical values and avoids the computational cost of bootstrap or other resampling methods.
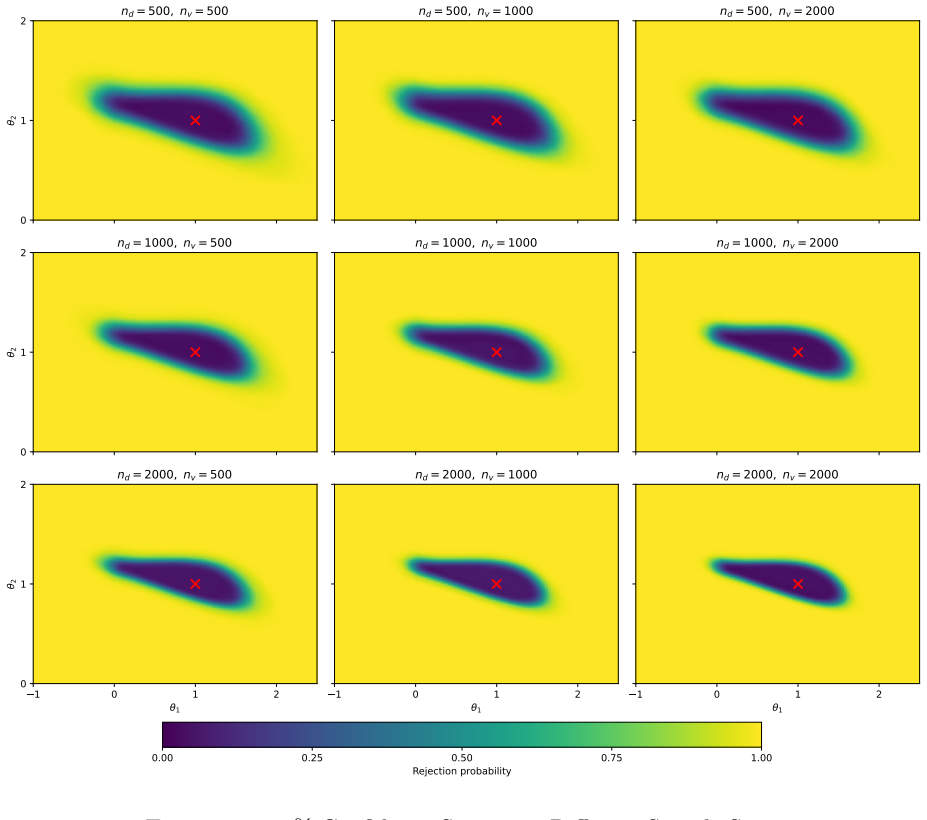
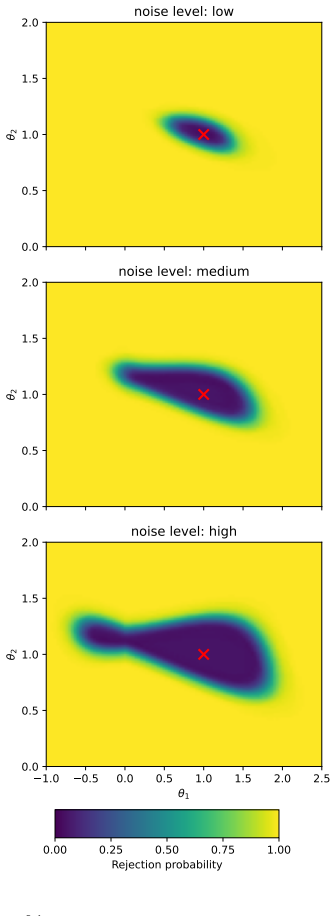
- Monte Carlo experiments confirm that the procedure maintains reliable size control and produces informative sets across a range of proxy accuracies.
Where Pith is reading between the lines
- The framework could be extended to settings with multiple proxies or multiple validation samples to tighten bounds further.
- Researchers might adapt the linking idea to panel or time-series data where the proxy appears in different periods.
- This approach suggests a general template for combining any two datasets that share a common observed variable when direct merging is impossible.
Load-bearing premise
The proxy functions as a valid linking variable between the two samples and the unconditional optimal transport problem delivers sharp partial identification bounds without any further restrictions on the upstream machine learning procedure.
What would settle it
An empirical application or Monte Carlo design in which the true parameter value lies outside the reported confidence sets even though the proxy correctly links the samples and the data-generating process satisfies the paper's assumptions.
Figures



read the original abstract
Empirical researchers increasingly use upstream machine-learning (ML) methods to construct proxies for latent target variables from complex, unstructured data. A naive plug-in use of such proxies in downstream econometric models, however, can lead to biased estimation and invalid inference. This paper develops a framework for partial identification and inference in general moment models with ML-generated proxies. Our approach does not require restrictive assumptions on the upstream ML procedure, such as consistency or known convergence rates, nor does it require a complete validation sample containing all variables used in the downstream analysis. Instead, we assume access to two datasets: a downstream sample containing observed covariates and the proxy, and an auxiliary validation sample containing joint observations on the proxy and its target variable. We treat the proxy as a linking variable between these two samples, rather than as a literal noisy substitute for the latent target variable. Building on this idea, we develop a sharp identification strategy based on an unconditional optimal transport characterization and an inference procedure that controls asymptotic size using analytical critical values without resampling. Monte Carlo simulations show reliable size control and informative confidence sets across a range of predictive-accuracy scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a partial identification and inference framework for general moment models E[m(X, Y*, Z; θ)] = 0 that incorporate machine-learned proxies Z for a latent target Y*. It combines a downstream sample (containing covariates X and proxy Z) with an auxiliary validation sample (containing Z and Y*) by treating the proxy as a linking variable. Identification proceeds via an unconditional optimal transport characterization of the joint distribution of (Z, Y*), yielding sharp bounds on θ without requiring consistency or known rates for the upstream ML procedure. Inference uses analytical critical values that control asymptotic size without resampling. Monte Carlo simulations illustrate reliable size control and informative confidence sets across varying proxy accuracy levels.
Significance. If the central claims hold, the paper would make a substantial contribution to econometric practice with ML-generated proxies by enabling valid inference in moment models under minimal assumptions on the upstream learner and without requiring a complete validation sample. The data-combination approach combined with analytical (non-resampling) critical values is a notable strength that reduces computational demands while maintaining size control, and the Monte Carlo evidence supports practical applicability across predictive-accuracy regimes.
major comments (1)
- [Identification section / abstract] The unconditional optimal transport characterization (abstract and identification section): the paper asserts that this delivers sharp partial identification bounds for general moment conditions involving covariates X. However, the unconditional coupling between the marginals of Z and Y* does not account for dependence between X and Y*. For non-separable m(X, Y*, Z; θ), the extremal joints from unconditional OT will generally produce strictly conservative bounds relative to the sharp identified set that respects the joint (X, Y*) distribution. This directly undermines the sharpness claim that is central to the contribution.
minor comments (2)
- [Introduction] The notation for the moment function m(·) and the precise statement of the data-combination assumption (downstream vs. validation samples) could be introduced earlier and with greater formality to improve readability for readers unfamiliar with the transport approach.
- [Monte Carlo section] Monte Carlo design: the reported scenarios vary predictive accuracy but do not include cases with strong dependence between X and Y*; adding such designs would better illustrate whether the reported size control persists under the conditions where the identification concern is most relevant.
Simulated Author's Rebuttal
We are grateful to the referee for providing a detailed and insightful report on our manuscript. The major comment raises an important point regarding the sharpness of the identified set, which we address below by committing to a revision that strengthens the identification strategy.
read point-by-point responses
-
Referee: [Identification section / abstract] The unconditional optimal transport characterization (abstract and identification section): the paper asserts that this delivers sharp partial identification bounds for general moment conditions involving covariates X. However, the unconditional coupling between the marginals of Z and Y* does not account for dependence between X and Y*. For non-separable m(X, Y*, Z; θ), the extremal joints from unconditional OT will generally produce strictly conservative bounds relative to the sharp identified set that respects the joint (X, Y*) distribution. This directly undermines the sharpness claim that is central to the contribution.
Authors: We thank the referee for this careful observation. Upon reflection, we agree that using an unconditional optimal transport coupling between the marginal distributions of Z and Y* would indeed fail to fully account for the dependence structure between X and Y* induced by the common Z, leading to conservative bounds for non-separable moment functions m. To achieve sharp partial identification, the optimal transport must be conducted conditionally on Z, coupling the conditional distributions P(X|Z) and P(Y*|Z) for each value of the linking variable. We will revise the identification section to explicitly characterize the sharp identified set using conditional optimal transport given Z. This revision will also update the abstract to reflect the conditional nature of the transport. The Monte Carlo simulations and inference procedure will remain applicable, as they do not rely on the unconditional aspect. We believe this change will clarify and strengthen the contribution without altering the core data-combination approach. revision: yes
Circularity Check
No circularity; identification derived from data-combination structure and transport theory
full rationale
The paper's central claim rests on treating the proxy as a linking variable between downstream and validation samples, then applying an unconditional optimal transport map to characterize the joint distribution for partial identification in general moment models. This draws directly from the data-combination setup and standard optimal transport results rather than redefining quantities in terms of themselves or renaming fitted parameters as predictions. No load-bearing self-citations, ansatz smuggling, or uniqueness theorems imported from the authors' prior work appear in the derivation chain. The approach is self-contained against external benchmarks from transport theory and does not reduce any result to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The proxy variable is observed in both the downstream sample and the auxiliary validation sample and serves as a linking variable.
- domain assumption Unconditional optimal transport between the linked samples yields sharp identification bounds.
Reference graph
Works this paper leans on
-
[1]
Machine learning and prediction errors in causal inference
Aksoy, Cevat Giray, Jose Maria Barrero, Nicholas Bloom, Steven Davis, Mathias Dolls, and Pablo Zarate (2022).Working from Home Around the World. en. Tech. rep. w30446. National Bureau of Economic Research, w30446. Allon, Gad, Daniel Chen, Zhenling Jiang, and Dennis Zhang (2023). “Machine learning and prediction errors in causal inference”.The Wharton Scho...
2022
-
[2]
Prediction-powered inference
Angelopoulos, Anastasios N, Stephen Bates, Clara Fannjiang, Michael I Jordan, and Tijana Zrnic (2023). “Prediction-powered inference”.Science382.6671, pp. 669–674. Angelopoulos, Anastasios N., John C. Duchi, and Tijana Zrnic (2024).PPI++: Efficient Prediction-Powered Inference. Athey, Susan, Raj Chetty, Guido W Imbens, and Hyunseung Kang (2025). “The Surr...
2023
-
[3]
A Unified Approach to Regression Analysis Under Double-Sampling Designs
Chen, Yi-Hau and Hung Chen (2000). “A Unified Approach to Regression Analysis Under Double-Sampling Designs”. en.Journal of the Royal Statistical Society Series B: Statistical Methodology62.3, pp. 449–460. Chen, Xiaohong, Han Hong, and Elie Tamer (2005). “Measurement Error Models with Aux- iliary Data”. en.Review of Economic Studies72.2, pp. 343–366. Cros...
2000
-
[4]
Debiasing Machine-Learning- or AI-Generated Regressors in Partial Linear Models
Grundlehren der mathematischen Wissenschaften. Zhang, Jingwen, Wendao Xue, Yifan Yu, and Yong Tan (2023). “Debiasing Machine-Learning- or AI-Generated Regressors in Partial Linear Models”. en.SSRN Electronic Journal. Zrnic, Tijana and Emmanuel J. Cand` es (2023).Cross-Prediction-Powered Inference. Johns Hopkins University Email address:lixiong.li@jhu.edu
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.