Decision Traces: What Multi-System Data Fusion Reveals About Institutional Knowledge in Enterprise Hiring
Fusing ATS, HRIS and assessments at a large insurer reveals anti-predictive effects and daily economic value from faster starts
abstract
click to expand
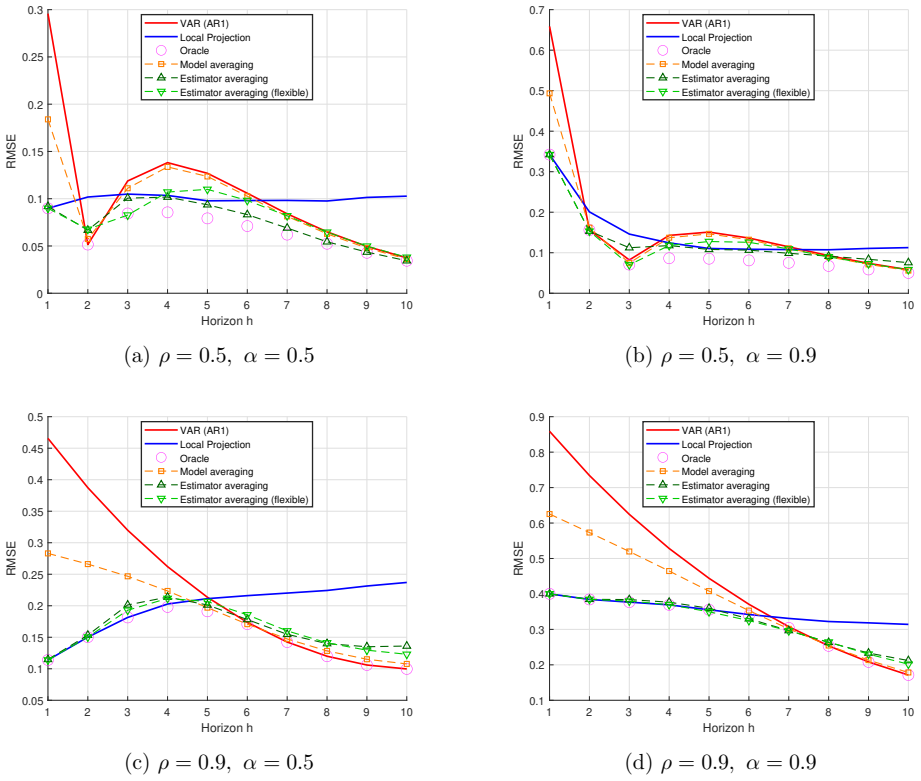
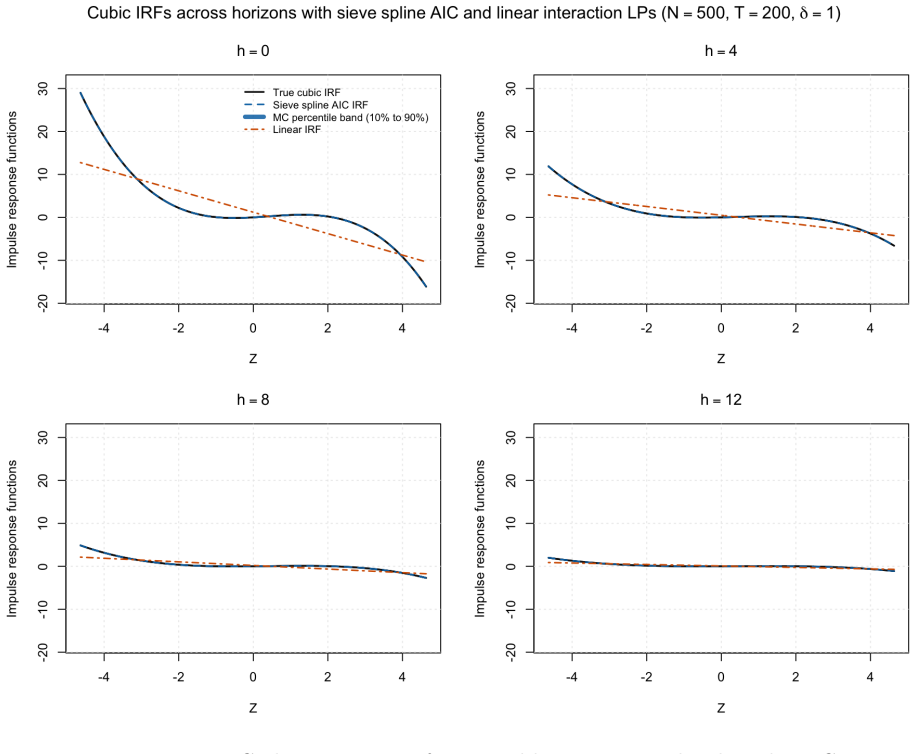
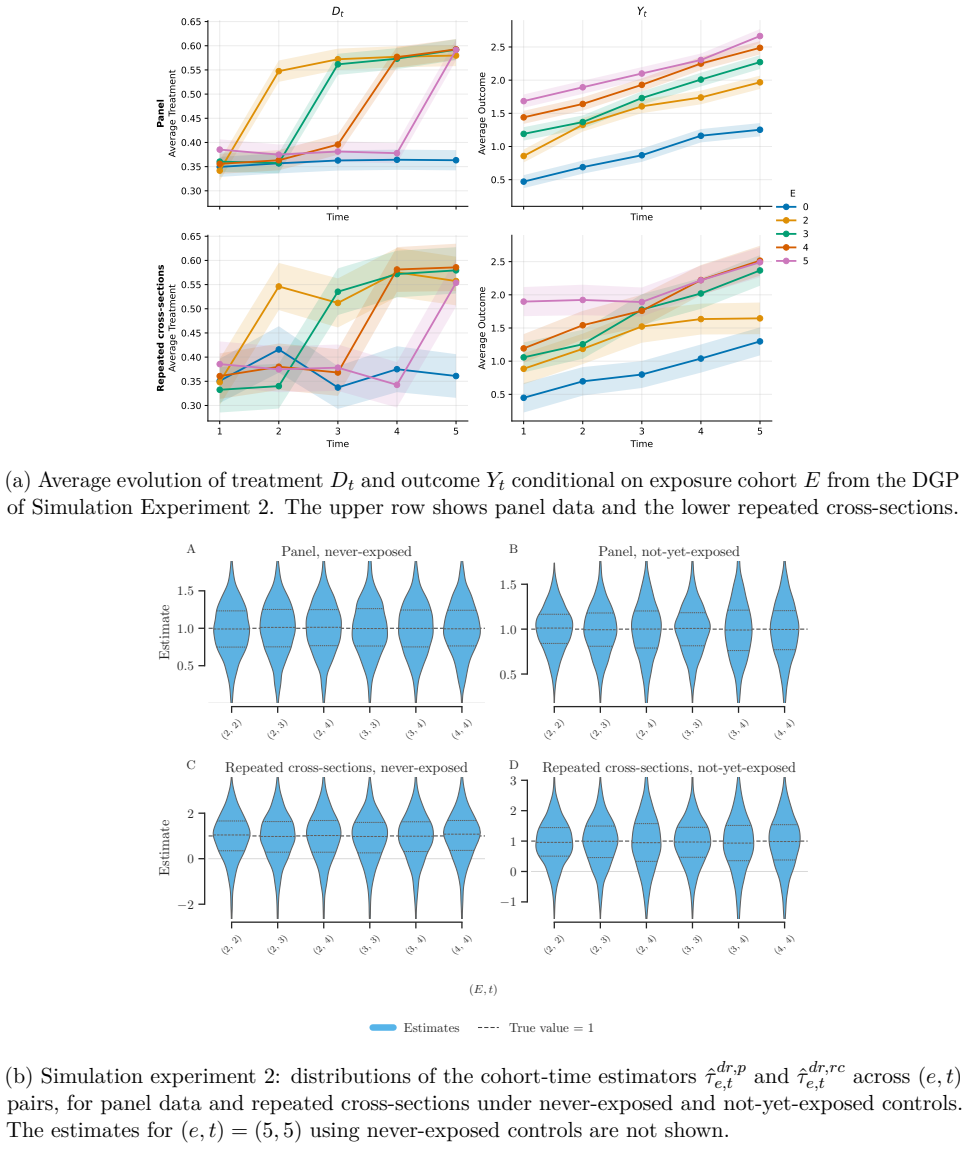
Enterprise hiring systems generate data across multiple disconnected platforms: applicant tracking systems (ATS) record candidate profiles, human resource information systems (HRIS) record performance outcomes, and behavioral assessments capture personality and behavioral dimensions. Each system operates independently, and the reasoning behind hiring decisions is lost when managers retire, transfer, or leave. Decision traces are structured evidence chains connecting screening inputs, assessment signals, and production outcomes. They have been theorized but never operationalized at production scale. We present, to our knowledge, the first such study: a deployment at a Fortune 500 insurance carrier (N=10,765 agents hired, 2022-2025), where connecting three siloed data systems produced three findings. First, of 8,181 unique skills parsed from ATS profiles (3,597 testable), not a single keyword predicts production after Bonferroni correction; 30 are significantly anti-predictive, and the median keyword is associated with 25% lower odds of production. Requiring insurance experience alone would reject 2,863 agents who produced $17.7M in annual premium credit. Second, personality-based behavioral assessment (Predictive Index) achieves AUC=0.647 standalone and AUC=0.735 when fused with ATS and behavioral scoring data. Third, speed-to-production follows a measurable economic constant of $54/day per agent unadjusted, or $35/day controlling for source channel and tenure, moderated by behavioral score: high-scored agents capture $114/day from speed acceleration versus $41/day for low-scored agents. These findings were invisible within any single system. We discuss implications for hiring system design, the limitations of keyword-based screening, and the conditions under which institutional knowledge can be captured and operationalized.
 full image
full image