Recognition: unknown
Learning Preference-Based Objectives from Clinical Narratives for Sequential Treatment Decision-Making
Pith reviewed 2026-05-10 15:33 UTC · model grok-4.3
The pith
Clinical narratives supply preference signals that train rewards yielding better recovery in sequential treatment policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that treating discharge summaries as sources of trajectory quality scores and pairwise preferences, processed through a large language model and weighted by narrative confidence, allows training of a reward function via a structured preference objective. This reward correlates with trajectory quality and supports policies that increase organ support-free days, accelerate shock resolution, and maintain comparable mortality performance, with the gains persisting in external validation.
What carries the argument
The Clinical Narrative-informed Preference Rewards (CN-PR) framework, which derives trajectory quality scores and pairwise preferences from discharge summaries to train a weighted preference-based reward objective for reinforcement learning.
If this is right
- Policies trained with the learned reward produce measurable gains in recovery-related outcomes such as organ support-free days and time to shock resolution.
- Mortality rates remain comparable to those achieved by baseline reward designs.
- The alignment between the learned reward and trajectory quality reaches a Spearman correlation of 0.63.
- Performance improvements hold when the policies are tested on external data.
- Narrative-based supervision offers a scalable substitute for handcrafted or purely outcome-driven reward functions in dynamic treatment regimes.
Where Pith is reading between the lines
- The same narrative preference pipeline could be adapted to encode explicit patient or family goals by modifying the preference construction step.
- Narrative rewards might complement rather than replace physiological data, creating hybrid objectives that capture both numeric stability and overall trajectory quality.
- Testing the framework on non-ICU datasets or with different language models would reveal how sensitive the gains are to narrative style and model choice.
- If the method generalizes, it could reduce the data engineering burden when moving reinforcement learning from research cohorts to new clinical sites.
Load-bearing premise
Large language model assessments of trajectory quality drawn from discharge summaries accurately and without bias capture true clinical effectiveness and patient experience.
What would settle it
A prospective trial in which policies trained on the learned reward fail to produce statistically significant gains in organ support-free days or shock resolution time compared with standard or outcome-based rewards.
Figures





read the original abstract
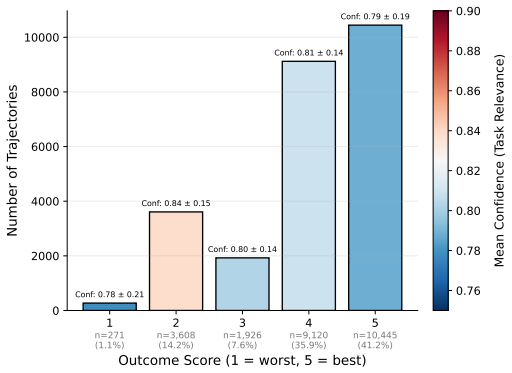
Designing reward functions remains a central challenge in reinforcement learning (RL) for healthcare, where outcomes are sparse, delayed, and difficult to specify. While structured data capture physiological states, they often fail to reflect the overall quality of a patient's clinical trajectory, including recovery dynamics, treatment burden, and stability. Clinical narratives, in contrast, summarize longitudinal reasoning and implicitly encode evaluations of treatment effectiveness. We propose Clinical Narrative-informed Preference Rewards (CN-PR), a framework for learning reward functions directly from discharge summaries by treating them as scalable supervision for trajectory-level preferences. Using a large language model, we derive trajectory quality scores (TQS) and construct pairwise preferences over patient trajectories, enabling reward learning via a structured preference-based objective. To account for variability in narrative informativeness, we incorporate a confidence signal that weights supervision based on its relevance to the decision-making task. The learned reward aligns strongly with trajectory quality (Spearman rho = 0.63) and enables policies that are consistently associated with improved recovery-related outcomes, including increased organ support-free days and faster shock resolution, while maintaining comparable performance on mortality. These effects persist under external validation. Our results demonstrate that narrative-derived supervision provides a scalable and expressive alternative to handcrafted or outcome-based reward design for dynamic treatment regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Clinical Narrative-informed Preference Rewards (CN-PR), a method to learn reward functions for reinforcement learning in clinical sequential decision-making by extracting trajectory quality scores (TQS) and pairwise preferences from discharge summaries using a large language model. The approach incorporates a confidence signal to weight the supervision and reports a Spearman rank correlation of 0.63 between the learned reward and trajectory quality, along with policies that improve recovery outcomes such as organ support-free days and shock resolution in both internal and external validation.
Significance. Should the central results prove robust, the work offers a valuable contribution to reward design in healthcare RL by providing a scalable, narrative-based alternative to hand-engineered rewards. The use of external validation and focus on clinically meaningful outcomes beyond mortality strengthen the potential applicability to real-world dynamic treatment regimes.
major comments (3)
- Abstract: The reported Spearman rho = 0.63 is given without associated p-value, confidence interval, or comparison to alternative reward functions or random baselines, which is necessary to establish that the alignment is not due to chance or trivial correlations.
- Methods: The paper does not sufficiently detail how the LLM-derived pairwise preferences are converted into the structured preference-based objective or how the confidence signal is mathematically incorporated into the reward learning loss; this information is load-bearing for reproducing the claimed alignment and policy improvements.
- Results: The external validation lacks explicit reporting of sample sizes, statistical tests for differences in organ support-free days and shock resolution, and analysis of potential confounders or selection biases in the validation cohort.
minor comments (2)
- Clarify the exact definition of 'trajectory quality' used in the TQS and how it relates to the clinical outcomes measured.
- Provide more information on the RL algorithm and state-action space used for policy learning to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments highlight important areas for improving statistical rigor, methodological transparency, and reporting completeness. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: The reported Spearman rho = 0.63 is given without associated p-value, confidence interval, or comparison to alternative reward functions or random baselines, which is necessary to establish that the alignment is not due to chance or trivial correlations.
Authors: We agree that reporting the p-value, confidence interval, and baseline comparisons is essential for interpreting the Spearman correlation. In the revised manuscript, we will update the abstract and corresponding results section to include the p-value and 95% confidence interval for rho = 0.63. We will also add explicit comparisons to random baselines and alternative reward functions (e.g., those derived from structured physiological data alone) to demonstrate that the observed alignment is not attributable to chance or trivial correlations. revision: yes
-
Referee: Methods: The paper does not sufficiently detail how the LLM-derived pairwise preferences are converted into the structured preference-based objective or how the confidence signal is mathematically incorporated into the reward learning loss; this information is load-bearing for reproducing the claimed alignment and policy improvements.
Authors: We acknowledge that greater mathematical detail is needed for full reproducibility. The pairwise preferences are converted via a structured ranking objective based on the Bradley-Terry model applied at the trajectory level, and the confidence signal is incorporated as a per-preference weight in the loss to modulate supervision strength according to narrative informativeness. We will expand the methods section with the explicit loss formulation, the precise weighting mechanism, and pseudocode for the full reward learning procedure. revision: yes
-
Referee: Results: The external validation lacks explicit reporting of sample sizes, statistical tests for differences in organ support-free days and shock resolution, and analysis of potential confounders or selection biases in the validation cohort.
Authors: We thank the referee for identifying these reporting gaps. In the revised results and supplementary materials, we will report the exact sample sizes for the external validation cohort. We will include statistical tests (e.g., Mann-Whitney U or t-tests with p-values and effect sizes) for differences in organ support-free days and shock resolution. We will also add a dedicated subsection analyzing potential confounders and selection biases, including baseline cohort characteristics and any adjustments (such as propensity weighting) applied to mitigate them. revision: yes
Circularity Check
No significant circularity; derivation uses external LLM extraction then validates on independent clinical outcomes
full rationale
The paper extracts TQS and pairwise preferences via LLM from discharge summaries, trains a reward model on those preferences, then evaluates the resulting policies on separate clinical metrics (organ support-free days, shock resolution, mortality) under external validation. The reported Spearman rho=0.63 measures how well the learned reward recovers the LLM-derived TQS, which is a standard reward-model validation step rather than a reduction by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing; the central claims rest on observable downstream outcomes that are not part of the preference inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- confidence signal weights
axioms (1)
- domain assumption Discharge summaries contain scalable, reliable supervision for trajectory-level preferences and quality
Reference graph
Works this paper leans on
-
[1]
Komorowski, L
M. Komorowski, L. A. Celi, O. Badawi, A. C. Gordon, A. A. Faisal, The artificial intelligence clinician learns optimal treatment strategies for sepsis in intensive care, Nature medicine 24 (11) (2018) 1716–1720
2018
-
[2]
Raghu, M
A. Raghu, M. Komorowski, L. A. Celi, P. Szolovits, M. Ghassemi, Continu- ous state-space models for optimal sepsis treatment: a deep reinforcement learning approach, in: Machine learning for healthcare conference, PMLR, 2017, pp. 147–163
2017
-
[3]
Roggeveen, A
L. Roggeveen, A. El Hassouni, J. Ahrendt, T. Guo, L. Fleuren, P. Thoral, A. R. Girbes, M. Hoogendoorn, P. W. Elbers, Transatlantic transferability of a new reinforcement learning model for optimizing haemodynamic treat- ment for critically ill patients with sepsis, Artificial intelligence in medicine 112 (2021) 102003
2021
- [4]
-
[5]
Liang, A
D. Liang, A. K. Paul, D. L. Weir, V. H. Deneer, R. Greiner, A. Siebes, H. Gardarsdottir, Methods in dynamic treatment regimens using obser- vational healthcare data: A systematic review, Computer Methods and Programs in Biomedicine 263 (2025) 108658. 29
2025
-
[6]
Brown, W
D. Brown, W. Goo, P. Nagarajan, S. Niekum, Extrapolating beyond subop- timal demonstrations via inverse reinforcement learning from observations, in: International conference on machine learning, PMLR, 2019, pp. 783– 792
2019
-
[7]
A. E. Johnson, L. Bulgarelli, L. Shen, A. Gayles, A. Shammout, S. Horng, T. J. Pollard, S. Hao, B. Moody, B. Gow, et al., Mimic-iv, a freely accessible electronic health record dataset, Scientific data 10 (1) (2023) 1
2023
-
[8]
Peine, A
A. Peine, A. Hallawa, J. Bickenbach, G. Dartmann, L. B. Fazlic, A. Schmeink, G. Ascheid, C. Thiemermann, A. Schuppert, R. Kindle, et al., Development and validation of a reinforcement learning algorithm to dynamically optimize mechanical ventilation in critical care, NPJ digital medicine 4 (1) (2021) 32
2021
-
[9]
Eghbali, T
N. Eghbali, T. Alhanai, M. M. Ghassemi, Patient-specific sedation manage- ment via deep reinforcement learning, Frontiers in Digital Health 3 (2021) 608893
2021
-
[10]
S.Adams, T.Cody, P.A.Beling, Asurveyofinversereinforcementlearning, Artificial Intelligence Review 55 (6) (2022) 4307–4346
2022
-
[11]
C. Yu, J. Liu, H. Zhao, Inverse reinforcement learning for intelligent me- chanical ventilation and sedative dosing in intensive care units, BMC med- ical informatics and decision making 19 (Suppl 2) (2019) 57
2019
-
[12]
C. Yu, G. Ren, J. Liu, Deep inverse reinforcement learning for sepsis treat- ment, in: 2019 IEEE international conference on healthcare informatics (ICHI), IEEE, 2019, pp. 1–3
2019
-
[13]
Zha, Adversarial cooperative imitation learning for dynamic treatment regimes, in: ProceedingsofTheWebConference2020, 2020, pp.1785–1795
L.Wang, W.Yu, X.He, W.Cheng, M.R.Ren, W.Wang, B.Zong, H.Chen, H. Zha, Adversarial cooperative imitation learning for dynamic treatment regimes, in: ProceedingsofTheWebConference2020, 2020, pp.1785–1795
2020
-
[14]
E. S. Berner, M. L. Graber, Overconfidence as a cause of diagnostic error in medicine, The American journal of medicine 121 (5) (2008) S2–S23. 30
2008
-
[15]
Hadfield-Menell, S
D. Hadfield-Menell, S. Milli, P. Abbeel, S. J. Russell, A. Dragan, Inverse re- ward design, Advances in neural information processing systems 30 (2017)
2017
-
[16]
Stiennon, L
N. Stiennon, L. Ouyang, J. Wu, D. Ziegler, R. Lowe, C. Voss, A. Radford, D. Amodei, P. F. Christiano, Learning to summarize with human feedback, Advances in neural information processing systems 33 (2020) 3008–3021
2020
-
[17]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al., Training language models to follow instructions with human feedback, Advances in neural information processing systems 35 (2022) 27730–27744
2022
-
[18]
arXiv preprint arXiv:1904.05342 , year =
K. Huang, J. Altosaar, R. Ranganath, Clinicalbert: Modeling clinical notes and predicting hospital readmission, arXiv preprint arXiv:1904.05342 (2019)
-
[19]
Waechter, A
J. Waechter, A. Kumar, S. E. Lapinsky, J. Marshall, P. Dodek, Y. Arabi, J. E. Parrillo, R. P. Dellinger, A. Garland, C. A. T. of Septic Shock Database Research Group, et al., Interaction between fluids and vasoactive agents on mortality in septic shock: a multicenter, observational study, Critical care medicine 42 (10) (2014) 2158–2168
2014
-
[20]
S. M. Brown, M. J. Lanspa, J. P. Jones, K. G. Kuttler, Y. Li, R. Carlson, R. R. Miller III, E. L. Hirshberg, C. K. Grissom, A. H. Morris, Survival after shock requiring high-dose vasopressor therapy, Chest 143 (3) (2013) 664–671
2013
-
[21]
X. Wu, R. Li, Z. He, T. Yu, C. Cheng, A value-based deep reinforcement learning model with human expertise in optimal treatment of sepsis, NPJ Digital Medicine 6 (1) (2023) 15
2023
-
[22]
Zhang, Y
T. Zhang, Y. Qu, D. Wang, M. Zhong, Y. Cheng, M. Zhang, Optimizing sepsis treatment strategies via a reinforcement learning model, Biomedical Engineering Letters 14 (2) (2024) 279–289. 31
2024
-
[23]
Z. Lu, J. Liu, R. Luo, C. Li, Reinforcement learning with balanced clini- cal reward for sepsis treatment, in: International Conference on Artificial Intelligence in Medicine, Springer, 2024, pp. 161–171
2024
-
[24]
D. R. Hunter, Mm algorithms for generalized bradley-terry models, The annals of statistics 32 (1) (2004) 384–406
2004
-
[25]
S. Tang, M. Makar, M. Sjoding, F. Doshi-Velez, J. Wiens, Leveraging fac- tored action spaces for efficient offline reinforcement learning in healthcare, Advances in neural information processing systems 35 (2022) 34272–34286
2022
- [26]
- [27]
-
[28]
Inada-Kim, E
M. Inada-Kim, E. Nsutebu, News 2: an opportunity to standardise the management of deterioration and sepsis, Bmj 360 (2018)
2018
-
[29]
R. Lin, M. D. Stanley, M. M. Ghassemi, S. Nemati, A deep deterministic policy gradient approach to medication dosing and surveillance in the icu, in: 2018 40th Annual international conference of the IEEE Engineering in Medicine and Biology Society (EMBC), IEEE, 2018, pp. 4927–4931
2018
-
[30]
P. J. Thoral, J. M. Peppink, R. H. Driessen, E. J. Sijbrands, E. J. Kom- panje, L. Kaplan, H. Bailey, J. Kesecioglu, M. Cecconi, M. Churpek, et al., Sharing icu patient data responsibly under the society of critical care medicine/european society of intensive care medicine joint data science collaboration: the amsterdam university medical centers database...
2021
-
[31]
E. J. Topol, High-performance medicine: the convergence of human and artificial intelligence, Nature medicine 25 (1) (2019) 44–56. 32
2019
-
[32]
M. P. Sendak, W. Ratliff, D. Sarro, E. Alderton, J. Futoma, M. Gao, M. Nichols, M. Revoir, F. Yashar, C. Miller, et al., Real-world integration of a sepsis deep learning technology into routine clinical care: implementation study, JMIR medical informatics 8 (7) (2020) e15182
2020
-
[33]
C. Yu, J. Liu, S. Nemati, G. Yin, Reinforcement learning in healthcare: A survey, ACM Computing Surveys (CSUR) 55 (1) (2021) 1–36
2021
-
[34]
Zhou, Z.-h
Q. Zhou, Z.-h. Chen, Y.-h. Cao, S. Peng, Clinical impact and quality of randomized controlled trials involving interventions evaluating artificial in- telligence prediction tools: a systematic review, NPJ digital medicine 4 (1) (2021) 154
2021
-
[35]
K. L. Kehl, W. Xu, E. Lepisto, H. Elmarakeby, M. J. Hassett, E. M. Van Allen, B. E. Johnson, D. Schrag, Natural language processing to ascer- tain cancer outcomes from medical oncologist notes, JCO Clinical Cancer Informatics 4 (2020) 680–690
2020
-
[36]
C.-Y. Yang, C. Shiranthika, C.-Y. Wang, K.-W. Chen, S. Sumathipala, Re- inforcement learning strategies in cancer chemotherapy treatments: A re- view, Computer Methods and Programs in Biomedicine 229 (2023) 107280
2023
-
[37]
Tejedor, A
M. Tejedor, A. Z. Woldaregay, F. Godtliebsen, Reinforcement learning ap- plication in diabetes blood glucose control: A systematic review, Artificial intelligence in medicine 104 (2020) 101836
2020
-
[38]
Y. Jin, F. Li, V. G. Vimalananda, H. Yu, Automatic detection of hypo- glycemic events from the electronic health record notes of diabetes patients: empirical study, JMIR medical informatics 7 (4) (2019) e14340
2019
-
[39]
R. J. Byrd, S. R. Steinhubl, J. Sun, S. Ebadollahi, W. F. Stewart, Auto- matic identification of heart failure diagnostic criteria, using text analysis of clinical notes from electronic health records, International journal of medical informatics 83 (12) (2014) 983–992. 33
2014
-
[40]
Barak-Corren, V
Y. Barak-Corren, V. M. Castro, S. Javitt, A. G. Hoffnagle, Y. Dai, R. H. Perlis, M. K. Nock, J. W. Smoller, B. Y. Reis, Predicting suicidal behavior from longitudinal electronic health records, American journal of psychiatry 174 (2) (2017) 154–162
2017
-
[41]
Perlis, D
R. Perlis, D. Iosifescu, V. Castro, S. Murphy, V. Gainer, J. Minnier, T. Cai, S.Goryachev, Q.Zeng, P.Gallagher, etal., Usingelectronicmedicalrecords to enable large-scale studies in psychiatry: treatment resistant depression as a model, Psychological medicine 42 (1) (2012) 41–50. 34 Supplementary Information
2012
-
[42]
Supplementary Methods 1.1. Action Discretization Table S1: Action Quantile Thresholds (4-hourly doses) Quantile 0 1 2 3 4 IV Fluids (ml)0 0.00–50.05 50.05–213.33 213.33–520.0>520.0 Vasopressors (mcg/kg)0 0.00–7.20 7.20–17.41 17.41–40.06>40.06 1.2. Outcome Metric Definitions All outcome metrics were computed using a unified discretization of patient tra- j...
-
[43]
Supplementary Tables Table S2: MIMIC-IV Cohort Characteristics Cohort % Female Age (years) ICU Stay (hours) Total (n) Median (IQR) Median (IQR) Overall 42.5 68 (57–79) 63.4 (34.7–123.2) 25370 Non-Survivors 44.0 72 (61–82) 97.1 (46.2–189.4) 3877 Survivors 42.2 68 (56–78) 58.4 (33.2–113.3) 21493 Table S3: AmsterdamUMCdb Cohort Characteristics Cohort % Femal...
-
[44]
Separate models were trained for (a) IV fluids and (b) vasopressors, with importance computed via permutation
Supplementary Figures 0.00 0.05 0.10 0.15 0.20 0.25 0.30 Permutation Importance Urine Output (4-hr) Time since sepsis start Calcium T otal Output Lactate Bicarbonate T emperature PaO2 BUN Hemoglobin Feature (a) Clinician Policy 0.00 0.05 0.10 0.15 0.20 0.25 Permutation Importance Urine Output (4-hr) Time since sepsis start MechVent SOFA Calcium Albumin T ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.