Recognition: unknown
When Meaning Isn't Literal: Exploring Idiomatic Meaning Across Languages and Modalities
Pith reviewed 2026-05-10 15:17 UTC · model grok-4.3
The pith
Mediom and HIDE together form a test bed that exposes literal bias in language and vision models on culturally specific idioms and supplies a hinting method to reduce those errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
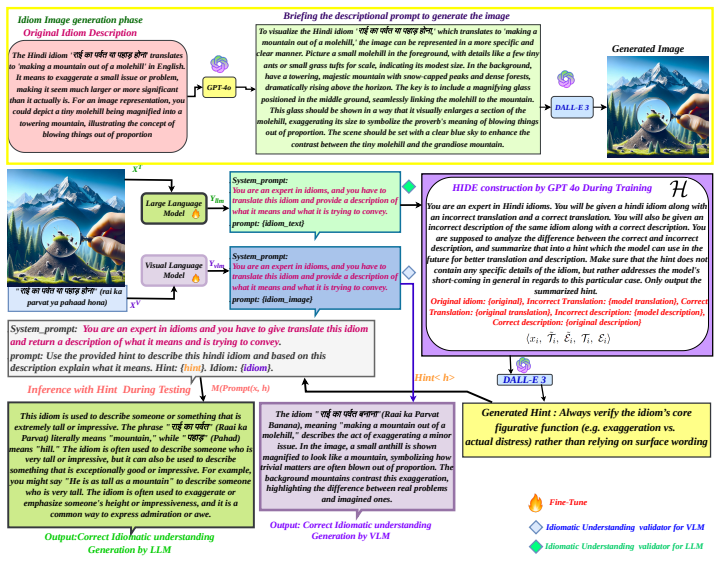
Mediom is a multilingual, multimodal idiom corpus containing 3,533 entries from Hindi, Bengali, and Thai, each paired with gold-standard explanations, translations, and carefully aligned text-image representations. Benchmarks on this corpus reveal systematic failures in both textual reasoning by large language models and figurative disambiguation by vision-language models. HIDE addresses these failures through a hinting-based idiom explanation process that leverages error-feedback retrieval and targeted diagnostic cues to support iterative reasoning refinement.
What carries the argument
The Mediom corpus paired with the HIDE framework, where HIDE uses error-feedback retrieval and diagnostic cues to drive iterative refinement of idiom explanations.
Load-bearing premise
The gold-standard explanations and image alignments accurately capture the intended idiomatic meanings across the three languages, and the observed model failures reflect fixable gaps in metaphor comprehension rather than other limitations.
What would settle it
A held-out collection of idioms where models equipped with HIDE show no accuracy gain over baselines, or where independent native speakers produce explanations that diverge from the Mediom gold standards.
Figures


read the original abstract
Idiomatic reasoning, deeply intertwined with metaphor and culture, remains a blind spot for contemporary language models, whose progress skews toward surface-level lexical and semantic cues. For instance, the Bengali idiom \textit{\foreignlanguage{bengali}{\char"0986\char"0999\char"09CD\char"0997\char"09C1 \char"09B0 \char"09AB\char"09B2 \char"099F\char"0995}} (angur fol tok, ``grapes are sour''): it encodes denial-driven rationalization, yet naive models latch onto the literal fox-and-grape imagery. Addressing this oversight, we present ``Mediom,'' a multilingual, multimodal idiom corpus of 3,533 Hindi, Bengali, and Thai idioms, each paired with gold-standard explanations, cross-lingual translations, and carefully aligned text--image representations. We benchmark both large language models (textual reasoning) and vision-language models (figurative disambiguation) on Mediom, exposing systematic failures in metaphor comprehension. To mitigate these gaps, we propose ``HIDE,'' a Hinting-based Idiom Explanation framework that leverages error-feedback retrieval and targeted diagnostic cues for iterative reasoning refinement. Collectively, Mediom and HIDE establish a rigorous test bed and methodology for culturally grounded, multimodal idiom understanding embedded with reasoning hints in next-generation AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Mediom, a multilingual multimodal corpus of 3,533 idioms from Hindi, Bengali, and Thai, each paired with gold-standard explanations, cross-lingual translations, and aligned text-image representations. It benchmarks LLMs on textual idiomatic reasoning and VLMs on figurative disambiguation, reporting systematic failures in metaphor comprehension. To address these, it proposes HIDE, a Hinting-based Idiom Explanation framework that uses error-feedback retrieval and targeted diagnostic cues for iterative refinement, positioning Mediom and HIDE as a test bed for culturally grounded multimodal idiom understanding.
Significance. If the annotations are validated and the failures are reproducible, this work supplies a needed resource for evaluating non-literal language understanding in under-resourced languages and modalities. The HIDE framework offers a concrete, iterative method for injecting reasoning hints that could generalize beyond idioms.
major comments (2)
- [§3] §3 (Mediom corpus construction): The explanations and alignments are repeatedly labeled 'gold-standard,' yet the manuscript supplies no information on annotator count, native-speaker qualifications, idiom expertise, adjudication procedures, or inter-annotator agreement. Because the central claims of 'systematic failures' in LLMs and VLMs rest on the accuracy of these labels, the absence of this validation protocol is load-bearing.
- [§4] §4 (Benchmarking results): The abstract asserts 'systematic failures' and successful mitigation by HIDE, but the manuscript does not report concrete metrics (accuracy, error rates, statistical tests), baseline comparisons, or an error taxonomy. Without these, it is impossible to assess whether the observed shortcomings are systematic or merely anecdotal.
minor comments (1)
- [Abstract] The Bengali idiom in the abstract is rendered with raw LaTeX commands; a parallel transliteration and English gloss would improve readability for non-specialist readers.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which identifies key areas where the manuscript requires greater transparency and rigor. We address each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (Mediom corpus construction): The explanations and alignments are repeatedly labeled 'gold-standard,' yet the manuscript supplies no information on annotator count, native-speaker qualifications, idiom expertise, adjudication procedures, or inter-annotator agreement. Because the central claims of 'systematic failures' in LLMs and VLMs rest on the accuracy of these labels, the absence of this validation protocol is load-bearing.
Authors: We agree that the absence of annotation protocol details is a significant omission. The current manuscript does not describe annotator count, qualifications, expertise, adjudication, or agreement measures. In the revised version we will add a dedicated subsection to §3 that fully documents the annotation process, including these elements, to substantiate the gold-standard labels and support the downstream claims. revision: yes
-
Referee: [§4] §4 (Benchmarking results): The abstract asserts 'systematic failures' and successful mitigation by HIDE, but the manuscript does not report concrete metrics (accuracy, error rates, statistical tests), baseline comparisons, or an error taxonomy. Without these, it is impossible to assess whether the observed shortcomings are systematic or merely anecdotal.
Authors: We concur that the benchmarking section lacks the quantitative detail needed to demonstrate systematicity. Although some results are presented, the manuscript does not include explicit accuracy/error rates, statistical tests, baseline comparisons, or an error taxonomy. We will revise §4 to incorporate these elements, enabling a clear assessment of the failures and the effectiveness of HIDE. revision: yes
Circularity Check
No significant circularity; new dataset and framework introduced without self-referential derivations
full rationale
The paper's core contributions are the creation of the Mediom corpus (3,533 idioms with explanations, translations, and alignments) and the proposal of the HIDE framework for iterative reasoning. No equations, parameters, or derivation chains appear in the provided text. Claims rest on new data and methodology rather than reducing to fitted inputs, self-citations as uniqueness theorems, or ansatzes smuggled from prior author work. The absence of any load-bearing self-referential steps makes the derivation self-contained; external validation of gold labels is a separate correctness concern, not circularity.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Mediom
no independent evidence
-
HIDE
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Honeck, A Proverb in Mind: The Cognitive Science of Proverbial Wit and Wisdom, Lawrence Erlbaum Associates, Mahwah, NJ, USA, 1997
Richard P . Honeck, A Proverb in Mind: The Cognitive Science of Proverbial Wit and Wisdom, Lawrence Erlbaum Associates, Mahwah, NJ, USA, 1997
1997
-
[2]
Large language models are human-like internally,
Tatsuki Kuribayashi, Y ohei Oseki, Souhaib Ben Taieb, Kentaro Inui, and Timothy Baldwin, “Large language models are human-like internally,” Trans. Assoc. Comput. Linguist., vol. 13, pp. 1743–1766, 2025
2025
-
[3]
Training language models to follow instructions with human feedback,
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wain- wright, Pamela Mishkin, Chong Zhang, et al., “Training language models to follow instructions with human feedback,” in Advances in Neural Information Processing Systems, 2022, vol. 35, pp. 27730– 27744
2022
-
[4]
WildVision: Evaluating vision-language models in the wild with human preferences,
Yujie Lu, Dongfu Jiang, Wenhu Chen, William Y ang Wang, Y ejin Choi, and Bill Yuchen Lin, “WildVision: Evaluating vision-language models in the wild with human preferences,” in Advances in Neural Information Processing Systems, 2024, vol. 38
2024
-
[5]
A hard nut to crack: Idiom detection with conversational large language models,
Francesca De Luca Fornaciari, Begoña Altuna, Itziar Gonzalez-Dios, and Maite Melero, “A hard nut to crack: Idiom detection with conversational large language models,” in The Workshop on Figurative Language Processing, 2024, pp. 35–44
2024
-
[6]
MAGPIE: A large corpus of potentially idiomatic expressions,
Hessel Haagsma, Johan Bos, and Malvina Nissim, “MAGPIE: A large corpus of potentially idiomatic expressions,” in The Language Resources and Evaluation Conference, 2020, pp. 279–287
2020
-
[7]
Critic-V: VLM critics help catch VLM errors in multimodal reasoning,
Di Zhang, Junxian Li, Jingdi Lei, Xunzhi Wang, Yujie Liu, Zonglin Y ang, Jiatong Li, et al., “Critic-V: VLM critics help catch VLM errors in multimodal reasoning,” in The IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[8]
Neural simile recognition with cyclic multitask learning and local attention,
Jiali Zeng, Linfeng Song, Jinsong Su, Jun Xie, Wei Song, and Jiebo Luo, “Neural simile recognition with cyclic multitask learning and local attention,” in The AAAI Conference on Artificial Intelligence, 2020, pp. 9515–9522
2020
-
[9]
MERMAID: Metaphor generation with symbolism and discriminative decoding,
Tuhin Chakrabarty, Xurui Zhang, Smaranda Muresan, and Nanyun Peng, “MERMAID: Metaphor generation with symbolism and discriminative decoding,” in The Conference of the North American Chapter of the ACL, 2021, pp. 4250–4261
2021
-
[10]
Collecting diverse natural language inference problems for sentence representation evaluation,
Adam Poliak, Aparajita Haldar, Rachel Rudinger, J. Edward Hu, Ellie Pavlick, Aaron Steven White, and Benjamin Van Durme, “Collecting diverse natural language inference problems for sentence representation evaluation,” in The Conference on Empirical Methods in Natural Language Processing, 2018, pp. 67–81
2018
-
[11]
Quote recommendation in dialogue using deep neural network,
Hanbit Lee, Y eonchan Ahn, Haejun Lee, Seungdo Ha, and Sang goo Lee, “Quote recommendation in dialogue using deep neural network,” in The International ACM SIGIR Conference on Research and Development in Information Retrieval, 2016, pp. 957–960
2016
-
[12]
Continuity of topic, interaction, and query: Learning to quote in online conversations,
Lingzhi Wang, Jing Li, Xingshan Zeng, Haisong Zhang, and Kam-Fai Wong, “Continuity of topic, interaction, and query: Learning to quote in online conversations,” in The Conference on Empirical Methods in Natural Language Processing, 2020, pp. 6640–6650
2020
-
[13]
IBERT: Idiom cloze-style reading comprehension with attention,
Ruiyang Qin, Haozheng Luo, Zheheng Fan, and Ziang Ren, “IBERT: Idiom cloze-style reading comprehension with attention,” arXiv preprint arXiv:2112.02994, 2021
-
[14]
Vector representations of idioms in conversational systems,
Tosin Adewumi, Foteini Liwicki, and Marcus Liwicki, “Vector representations of idioms in conversational systems,” Sci, vol. 4, no. 4, pp. 37, 2022
2022
-
[15]
COMET: Commonsense trans- formers for automatic knowledge graph construction,
Antoine Bosselut, Hannah Rashkin, Maarten Sap, Chaitanya Malaviya, Asli Celikyilmaz, and Y ejin Choi, “COMET: Commonsense trans- formers for automatic knowledge graph construction,” in The Annual Meeting of the ACL, 2019, pp. 4762–4779
2019
-
[16]
SemEval-2013 task 5: Evaluating phrasal semantics,
Ioannis Korkontzelos, Torsten Zesch, Fabio Massimo Zanzotto, and Chris Biemann, “SemEval-2013 task 5: Evaluating phrasal semantics,” in The International Workshop on Semantic Evaluation, 2013, pp. 39– 47
2013
-
[17]
FLUTE: Figurative language understanding through textual explanations,
Tuhin Chakrabarty, Arkadiy Saakyan, Debanjan Ghosh, and Smaranda Muresan, “FLUTE: Figurative language understanding through textual explanations,” in The Conference on Empirical Methods in Natural Language Processing, 2022, pp. 7139–7159
2022
-
[18]
Understanding figurative meaning through explainable visual entailment,
Arkadiy Saakyan, Shreyas Kulkarni, Tuhin Chakrabarty, and Smaranda Muresan, “Understanding figurative meaning through explainable visual entailment,” in The Conference of the Nations of the Americas Chapter of the ACL, 2025, pp. 1–23
2025
-
[19]
Pattana Publishing, 2014
Ekarat Udomporn, 5000 Thai Idioms: From the Past Right on up to Now!, P .S. Pattana Publishing, 2014
2014
-
[20]
Improving image generation with better captions,
OpenAI, “Improving image generation with better captions,” Tech. Rep., OpenAI, 2023
2023
-
[21]
Aaron Hurst, Adam Lerer, Adam P . Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, et al., “GPT-4o system card,” arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Gemma Team, “Gemma,” Kaggle, 2024
2024
-
[23]
arXiv preprint arXiv:2412.03555 (2024) 1
Andreas Steiner, André Susano Pinto, Michael Tschannen, Daniel Keysers, Xiao Wang, Y onatan Bitton, et al., “PaliGemma 2: A family of versatile VLMs for transfer,” arXiv preprint arXiv:2412.03555, 2024
-
[24]
Language models are few-shot learners,
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al., “Language models are few-shot learners,” in Advances in Neural Information Processing Systems, 2020, vol. 33, pp. 1877–1901
2020
-
[25]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bam- ford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, et al., “Mistral 7B,” arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Y asmine Babaei, Nikolay Bashlykov, et al., “Llama 2: Open foundation and fine-tuned chat models,” arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi, “BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” in The International Conference on Machine Learning, 2023, vol. 202, pp. 19730–19742
2023
-
[28]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, et al., “Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution,” arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
SmolVLM-500M-Base,
Hugging Face, “SmolVLM-500M-Base,” https://huggingface.co/ HuggingFaceTB/SmolVLM-500M-Base , 2025
2025
-
[30]
LanguageBind: Extending video-language pretraining to N-modality by language-based semantic alignment,
Bin Zhu, Bin Lin, Munan Ning, Y ang Y an, Jiaxi Cui, Hongfa Wang, Y atian Pang, Wenhao Jiang, Junwu Zhang, et al., “LanguageBind: Extending video-language pretraining to N-modality by language-based semantic alignment,” in The International Conference on Learning Representations, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.