Recognition: unknown
The xPU-athalon: Quantifying the Competition of AI Acceleration
Pith reviewed 2026-05-10 14:56 UTC · model grok-4.3
The pith
No single AI accelerator wins across all conditions; the optimal platform shifts with batch size, sequence length, and model size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Evaluating end-to-end LLM workloads and individual computational primitives across the listed platforms shows that the best hardware choice varies with batch size, sequence length, and model size, exposing a large optimization space. Detailed measurements during prefill and decode phases of inference quantify power and communication energy costs. Cerebras, SambaNova, and Gaudi draw 10-60% more idle power than the NVIDIA and AMD GPUs, making high utilization necessary to realize efficiency advantages. Programmability is compared via compilation times and software maturity observed in the experiments.
What carries the argument
Side-by-side benchmarking of latency, throughput, power, and energy efficiency on end-to-end workloads plus primitives, parameterized by batch size, sequence length, and model size.
If this is right
- Hardware selection for AI inference and training must be made dynamically based on current workload parameters rather than fixed in advance.
- Platforms with higher idle power deliver efficiency gains only when kept at high utilization.
- Communication energy costs between devices should be included when comparing platforms for distributed workloads.
- Programmability differences, visible in compilation time and stack maturity, affect how quickly promised performance can be reached in practice.
- Phase-specific power data for prefill versus decode can guide targeted optimizations in LLM serving systems.
Where Pith is reading between the lines
- Cloud operators might gain from maintaining pools of heterogeneous accelerators and routing jobs to the best match for each request.
- Accelerator designers could prioritize lower idle power or greater flexibility across workload sizes to reduce the need for platform switching.
- The observed variation suggests room for hybrid execution strategies that split a single model across multiple accelerator types.
- Wider use of these parameterized benchmarks could move industry comparisons beyond vendor-reported peak numbers.
Load-bearing premise
The chosen end-to-end workloads and individual primitives are representative enough of typical production AI usage to support general statements about which platform is optimal.
What would settle it
Running the same measurements on a wider collection of production models and workloads that instead shows one platform remaining optimal across nearly all batch sizes and scales would undermine the claim of a large optimization space.
Figures



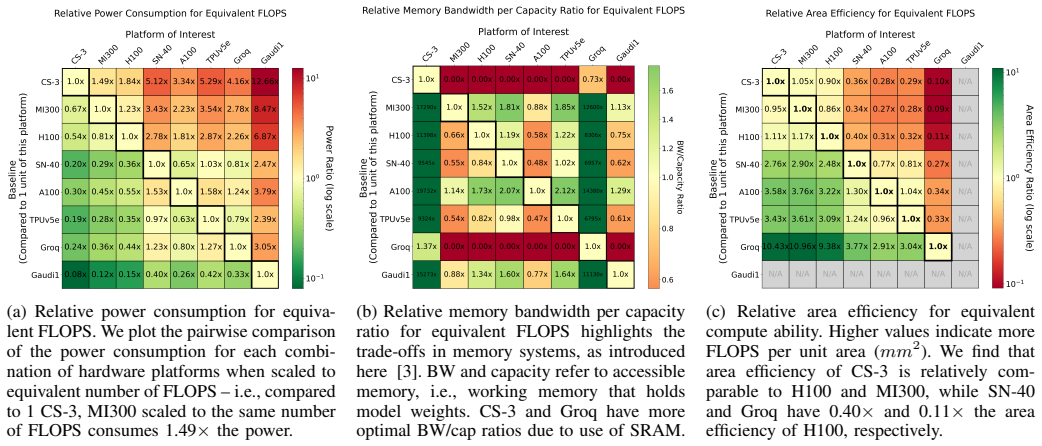

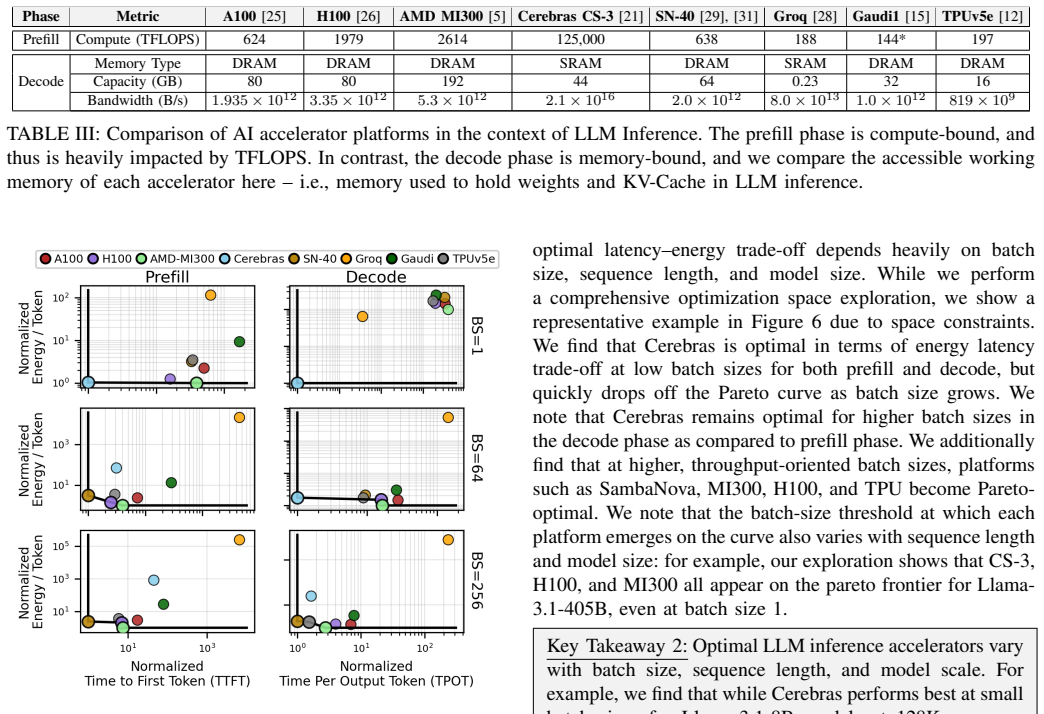






read the original abstract
The push for greater efficiency in AI computation has given rise to an array of accelerator architectures that increasingly challenge the GPU's long-standing dominance. In this work, we provide a quantitative view of this evolving landscape of AI accelerators, including the Cerebras CS-3, SambaNova SN-40, Groq, Gaudi, and TPUv5e platforms, and compare against both NVIDIA (A100, H100) and AMD (MI-300X) GPUs. We evaluate key trade-offs in latency, throughput, power consumption, and energy-efficiency across both (i) end-to-end workloads and (ii) benchmarks of individual computational primitives. Notably, we find the optimal hardware platform varies across batch size, sequence length, and model size, revealing a large underlying optimization space. Our analysis includes detailed power measurements across the prefill and decode phases of LLM inference, as well as quantification of the energy cost of communication. We additionally find that Cerebras, SambaNova, and Gaudi have 10-60% higher idle power than NVIDIA and AMD GPUs, emphasizing the importance of high utilization in order to realize promised efficiency gains. Finally, we assess programmability across platforms based on our experiments with real profiled workloads, comparing the compilation times and software stack maturity required to achieve promised performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents empirical measurements comparing AI accelerators including Cerebras CS-3, SambaNova SN-40, Groq, Gaudi, TPUv5e against NVIDIA A100/H100 and AMD MI-300X GPUs. Using end-to-end LLM inference workloads and individual computational primitives, it evaluates latency, throughput, power consumption, and energy efficiency. Key findings include variation in optimal platform depending on batch size, sequence length, and model size; detailed power analysis for prefill and decode phases; 10-60% higher idle power for Cerebras, SambaNova, and Gaudi; energy costs of communication; and assessments of programmability through compilation times and software stack maturity.
Significance. If substantiated by representative workloads, the results are significant for the AI hardware community by quantifying trade-offs in the competitive landscape of accelerators and underscoring that no single platform is universally optimal. The power and utilization insights, along with programmability analysis, offer practical guidance for deploying AI systems efficiently. This contributes to the field by moving beyond vendor claims to direct comparisons.
major comments (2)
- [Abstract and Methodology] The claim that 'the optimal hardware platform varies across batch size, sequence length, and model size, revealing a large underlying optimization space' is central but rests on the representativeness of the tested workloads. The description does not specify how the end-to-end workloads and primitives were selected to ensure coverage of production AI usage (e.g., training vs. inference, different model types, or utilization levels), raising the possibility that observed variations are specific to the chosen benchmarks rather than general.
- [Power Measurements] The finding that Cerebras, SambaNova, and Gaudi have 10-60% higher idle power is important for the utilization argument. However, details on how idle power was measured (e.g., system state, duration, averaging) and any associated variability should be provided to support the percentage range and its implications.
minor comments (2)
- [Title] The title 'The xPU-athalon' could benefit from a brief explanation or expansion in the abstract to clarify its meaning for readers unfamiliar with the term.
- [Figures] Ensure that all figures plotting performance across parameters include error bars or confidence intervals if multiple runs were performed, to enhance the reliability of the comparisons.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and have revised the paper to incorporate additional details where appropriate.
read point-by-point responses
-
Referee: [Abstract and Methodology] The claim that 'the optimal hardware platform varies across batch size, sequence length, and model size, revealing a large underlying optimization space' is central but rests on the representativeness of the tested workloads. The description does not specify how the end-to-end workloads and primitives were selected to ensure coverage of production AI usage (e.g., training vs. inference, different model types, or utilization levels), raising the possibility that observed variations are specific to the chosen benchmarks rather than general.
Authors: The manuscript focuses exclusively on LLM inference workloads, as stated in the abstract and throughout the text. The end-to-end workloads were selected to span representative production inference scenarios, including batch sizes from 1 to 128, sequence lengths up to 2048 tokens, and model sizes from 7B to 70B parameters, drawn from common transformer-based deployments. The individual primitives isolate core operations (GEMM, attention, reductions) that dominate inference. To address the concern about explicit justification, the revised manuscript adds a dedicated subsection in Methodology that details the selection criteria, their alignment with observed production patterns, and the exclusion of training workloads. revision: yes
-
Referee: [Power Measurements] The finding that Cerebras, SambaNova, and Gaudi have 10-60% higher idle power is important for the utilization argument. However, details on how idle power was measured (e.g., system state, duration, averaging) and any associated variability should be provided to support the percentage range and its implications.
Authors: Idle power was measured by placing each system in a quiescent state (no active user workloads, standard OS background processes only) and recording power draw via platform-native monitoring interfaces for a continuous 5-minute period, with values sampled every second and averaged. Variability was quantified by repeating the procedure across three independent runs per platform and reporting the standard deviation. The revised Power Measurements section now includes these protocol details, the exact system states, and the variability statistics supporting the reported 10-60% range. revision: yes
Circularity Check
No circularity: direct empirical measurements with no derivations or fitted predictions
full rationale
The paper reports hardware benchmarks and power measurements on chosen workloads and primitives. No equations, fitted parameters, self-citations used as uniqueness theorems, or ansatzes appear in the provided abstract or methodology descriptions. All claims (optimal platform variation, idle power differences) rest on direct observation rather than reduction to prior inputs or self-referential definitions. The representativeness concern is a validity issue, not a circularity issue under the defined patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Selected benchmarks and workloads are representative of typical production AI usage patterns
Reference graph
Works this paper leans on
-
[1]
A software-defined tensor streaming multiprocessor for large-scale machine learning,
D. Abts, G. Kimmell, A. Ling, J. Kim, M. Boyd, A. Bitar, S. Parmar, I. Ahmed, R. DiCecco, D. Han, J. Thompson, M. Bye, J. Hwang, J. Fowers, P. Lillian, A. Murthy, E. Mehtabuddin, C. Tekur, T. Sohmers, K. Kang, S. Maresh, and J. Ross, “A software-defined tensor streaming multiprocessor for large-scale machine learning,” in Proceedings of the 49th Annual In...
-
[2]
Think fast: A tensor streaming processor (tsp) for accelerating deep learning workloads,
D. Abts, J. Ross, J. Sparling, M. Wong-VanHaren, M. Baker, T. Hawkins, A. Bell, J. Thompson, T. Kahsai, G. Kimmell, J. Hwang, R. Leslie- Hurd, M. Bye, E. Creswick, M. Boyd, M. Venigalla, E. Laforge, J. Purdy, P. Kamath, D. Maheshwari, M. Beidler, G. Rosseel, O. Ahmad, G. Gagarin, R. Czekalski, A. Rane, S. Parmar, J. Werner, J. Sproch, A. Macias, and B. Ku...
2020
-
[3]
Rpu: A reasoning processing unit for low latency inference,
M. Adilletta, D. Brooks, and G.-Y . Wei, “Rpu: A reasoning processing unit for low latency inference,” in32nd IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2026
2026
-
[4]
Amazon ec2 dl1 instances,
Amazon Web Services, “Amazon ec2 dl1 instances,” 2024, accessed: 2025-12-15. [Online]. Available: https://aws.amazon.com/ ec2/instance-types/dl1/
2024
-
[5]
Amd instinct mi300x accelerator datasheet,
AMD, “Amd instinct mi300x accelerator datasheet,” 2023. [On- line]. Available: https://www.amd.com/content/dam/amd/en/documents/ instinct-tech-docs/data-sheets/amd-instinct-mi300x-data-sheet.pdf
2023
-
[6]
Ai hardware benchmarking & performance analysis,
Artificial Analysis, “Ai hardware benchmarking & performance analysis,” Online Resource, 2025. [Online]. Available: https: //artificialanalysis.ai/benchmarks/hardware
2025
-
[7]
Transformer flops,
A. Casson, “Transformer flops,” 2023. [Online]. Available: https: //www.adamcasson.com/posts/transformer-flops
2023
-
[8]
Pipeline parallelism,
DeepSpeed, “Pipeline parallelism,” 2025. [Online]. Available: https: //www.deepspeed.ai/tutorials/pipeline/
2025
-
[9]
A comprehensive performance study of large language models on novel ai accelerators,
M. Emani, S. Foreman, V . Sastry, Z. Xie, S. Raskar, W. Arnold, R. Thakur, V . Vishwanath, and M. E. Papka, “A comprehensive performance study of large language models on novel ai accelerators,”
-
[10]
Available: https://arxiv.org/abs/2310.04607
[Online]. Available: https://arxiv.org/abs/2310.04607
-
[11]
A 4d hybrid algorithm to scale parallel training to thousands of gpus,
S. S. et.al., “A 4d hybrid algorithm to scale parallel training to thousands of gpus,” 2024. [Online]. Available: https://arxiv.org/abs/2305.13525
-
[12]
System architecture for TPU VMs,
Google Cloud, “System architecture for TPU VMs,” Online Documentation, 2025. [Online]. Available: https://docs.cloud.google. com/tpu/docs/system-architecture-tpu-vm
2025
-
[13]
Tpu v5e,
——, “Tpu v5e,” Online Documentation, 2025, accessed: 2025-12-15. [Online]. Available: https://docs.cloud.google.com/tpu/docs/v5e
2025
-
[14]
Why sambanova’s sn40l chip is the best for inference,
M. Gottscho and R. Prabhakar, “Why sambanova’s sn40l chip is the best for inference,” 2024. [Online]. Available: https://sambanova.ai/ blog/sn40l-chip-best-inference-solution
2024
-
[15]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al- Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, A. Korenev, A. Hinsvark, A. Rao, A. Zhang, A. Rodriguez, A. Gregerson, A. Spataru, B. Roziere, B. Biron, B. Tang, B. Chern, C. Caucheteux, C. Nayak, C. Bi, C. Ma...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Gaudi architecture overview,
Habana Labs, “Gaudi architecture overview,” Online Documentation,
-
[17]
Available: https://docs.habana.ai/en/v1.4.0/Gaudi Overview/Gaudi Architecture.html
[Online]. Available: https://docs.habana.ai/en/v1.4.0/Gaudi Overview/Gaudi Architecture.html
-
[18]
Mastering llm techniques: Inference optimiza- tion,
N. V . hashank Verma, “Mastering llm techniques: Inference optimiza- tion,” 2023
2023
-
[19]
Machine learning systems: Principles and practices of engineering artificially intelligent systems,
V . Janapa Reddi, “Machine learning systems: Principles and practices of engineering artificially intelligent systems,” 2025. [Online]. Available: https://mlsysbook.ai/
2025
-
[20]
Scott Gardner, Itay Hubara, Sachin Idgunji, Thomas B
V . Janapa Reddi, C. Cheng, D. Kanter, P. Mattson, G. Schmuelling, C.-J. Wu, B. Anderson, M. Breughe, M. Charlebois, W. Chou, R. Chukka, C. Coleman, S. Davis, P. Deng, G. Diamos, J. Duke, D. Fick, J. S. Gardner, I. Hubara, S. Idgunji, T. B. Jablin, J. Jiao, T. St. John, P. Kanwar, D. Lee, J. Liao, A. Lokhmotov, F. Massa, P. Meng, P. Micikevicius, C. Osbor...
-
[21]
Sambanova sn40l rdu for tril- lion parameter ai models,
P. Kennedy, “Sambanova sn40l rdu for tril- lion parameter ai models,” Aug. 2024, serveThe- Home. [Online]. Available: https://www.servethehome.com/ sambanova-sn40l-rdu-for-trillion-parameter-ai-models/
2024
-
[22]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[23]
Hot chips 2024 symposium (hc2024). wafer-scale ai: Enabling unprecedented ai compute performance,
S. Lie, “Hot chips 2024 symposium (hc2024). wafer-scale ai: Enabling unprecedented ai compute performance,” 2024. [Online]. Available: https://hc2024.hotchips.org/assets/program/conference/day2/ 72 HC2024.Cerebras.Sean.v03.final.pdf
2024
-
[24]
Inside the lpu: Deconstructing groq’s speed,
A. Ling, “Inside the lpu: Deconstructing groq’s speed,” 2025. [Online]. Available: https://groq.com/blog/ inside-the-lpu-deconstructing-groq-speed
2025
-
[25]
Efficient large- scale language model training on gpu clusters using megatron- lm,
D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V . A. Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro, A. Phanishayee, and M. Zaharia, “Efficient large- scale language model training on gpu clusters using megatron- lm,” inProceedings of the International Conference for High Performance Computing, Networking, Storage, a...
2021
-
[26]
Nvidia nccl repo
Nvidia, “Nvidia nccl repo.” [Online]. Available: https://github.com/ NVIDIA/nccl/issues/866?utm source=chatgpt.com
-
[27]
Nvidia a100 tensor core gpu datasheet,
——, “Nvidia a100 tensor core gpu datasheet,” 2020. [Online]. Avail- able: https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/ a100/pdf/nvidia-a100-datasheet-nvidia-us-2188504-web.pdf
2020
-
[28]
Nvidia h100 tensor core gpu datasheet,
——, “Nvidia h100 tensor core gpu datasheet,” 2022. [Online]. Available: https://resources.nvidia.com/en-us-gpu-resources/ h100-datasheet-24306
2022
-
[29]
Amd and openai announce strategic partnership to deploy 6 gigawatts of amd gpus,
OpenAI, “Amd and openai announce strategic partnership to deploy 6 gigawatts of amd gpus,” OpenAI, 2025. [Online]. Available: https://openai.com/index/openai-amd-strategic-partnership/
2025
-
[30]
Groq inference tokenomics: Speed but at what cost?
D. Patel, “Groq inference tokenomics: Speed but at what cost?” SemiAnalysis Newsletter, 2024. [Online]. Available: https://newsletter. semianalysis.com/p/groq-inference-tokenomics-speed-but
2024
-
[31]
R. Prabhakar, R. Sivaramakrishnan, D. Gandhi, Y . Du, M. Wang, X. Song, K. Zhang, T. Gao, A. Wang, X. Li, Y . Sheng, J. Brot, D. Sokolov, A. Vivek, C. Leung, A. Sabnis, J. Bai, T. Zhao, M. Gottscho, D. Jackson, M. Luttrell, M. K. Shah, Z. Chen, K. Liang, S. Jain, U. Thakker, D. Huang, S. Jairath, K. J. Brown, and K. Olukotun, “Sambanova sn40l: Scaling the...
-
[32]
Intelligence per watt: Measuring intelligence efficiency of local ai,
J. Saad-Falcon, A. Narayan, H. O. Akengin, J. W. Griffin, H. Shandilya, A. Gamarra Lafuente, M. Goel, R. Joseph, S. Natarajan, E. K. Guha, S. Zhu, B. Athiwaratkun, J. Hennessy, A. Mirhoseini, and C. Re, “Intelligence per watt: Measuring intelligence efficiency of local ai,”
-
[33]
Available: https://arxiv.org/abs/2511.07885
[Online]. Available: https://arxiv.org/abs/2511.07885
-
[34]
Sambarack sn40l-16 hardware system data sheet,
SambaNova Systems, “Sambarack sn40l-16 hardware system data sheet,” 2025. [Online]. Available: https://sambanova.ai/hubfs/ SambaRack%20data%20sheet%20template%2007%2009%2025.pdf
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.