Recognition: unknown
Tensor-based Multi-layer Decoupling
Pith reviewed 2026-05-10 14:58 UTC · model grok-4.3
The pith
Tensor decompositions allow multi-layer decoupling of multivariate functions by coupling Jacobian and value data in bilevel optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Multi-layer decoupling of multivariate functions admits a faithful parameterization by ParaTuck-type tensor decompositions; these can be recovered by a structured coupled matrix-tensor factorization that incorporates both Jacobian and function evaluations and is solved by a bilevel optimization procedure that balances first- and zeroth-order information.
What carries the argument
ParaTuck-type tensor decomposition, which supplies the structural parameterization for the multi-layer case inside a constrained coupled matrix-tensor factorization solved by bilevel optimization.
If this is right
- The same factorization and bilevel scheme can be applied to nonlinear system identification tasks that involve cascaded nonlinearities.
- The approach yields a concrete procedure for compressing neural networks by decoupling successive layers.
- Both derivative information and direct function values are jointly used, improving conditioning over methods that rely on only one type of data.
- Theoretical justification for the tensor form supports its use as a modeling assumption in other multi-layer problems.
Where Pith is reading between the lines
- If the parameterization scales without extra error, the method could be tested on deeper networks to see whether layer count remains tractable.
- The bilevel balancing of orders might be reused in other engineering tasks where both gradients and values are available but noisy.
- Success on the identification benchmark suggests the framework could be compared directly against existing multi-layer neural or Volterra models on the same data.
Load-bearing premise
That ParaTuck-type tensor decompositions can represent the multi-layer decoupling problem accurately enough that the subsequent bilevel optimization recovers the correct factors without large unmodeled structural errors.
What would settle it
On a synthetic multi-layer function whose exact layer structure is known to match the assumed tensor form, the recovered factors produce large reconstruction error or fail to match the true Jacobians.
Figures



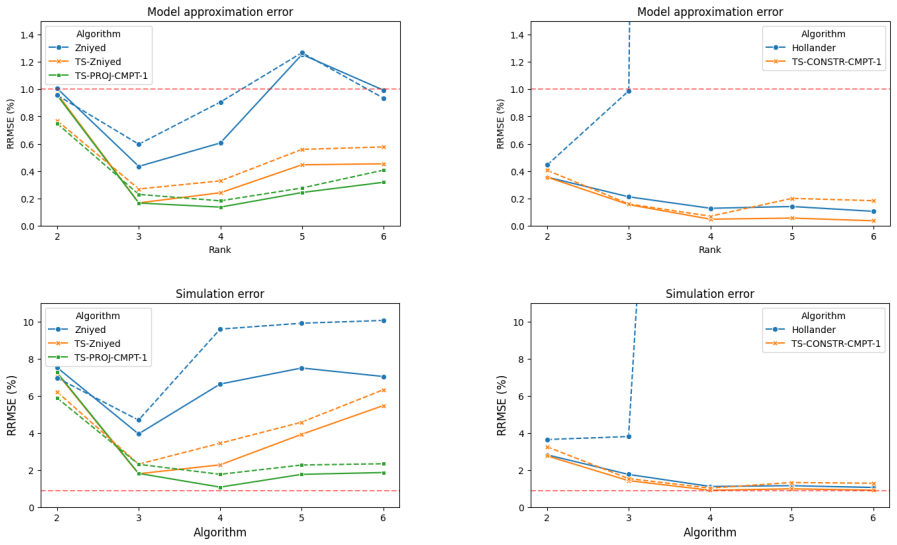





read the original abstract
The decoupling of multivariate functions is a powerful modeling paradigm for learning multivariate input-output relations from data. For the single-layer case, established CPD-based methods are available, but the multi-layer case remained largely unexplored. This work introduces a tensor-based framework for multi-layer decoupling, which is based on ParaTuck-type tensor decompositions and constrained optimization. We provide theoretical justification behind the considered tensor decompositions and parameterizations. Furthermore, we formulate a structured coupled matrix-tensor factorization that incorporates both Jacobian and function evaluations, together with a bilevel optimization approach for adaptively balancing first- and zeroth-order information. The feasibility of the proposed methodology is illustrated on synthetic systems, a nonlinear system identification benchmark and neural network compression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a tensor-based framework for multi-layer decoupling of multivariate functions, extending single-layer CPD methods via ParaTuck-type tensor decompositions and constrained optimization. It provides theoretical justification for the decompositions and parameterizations, formulates a structured coupled matrix-tensor factorization incorporating both Jacobian and function evaluations, and proposes a bilevel optimization approach to adaptively balance first- and zeroth-order information. Feasibility is illustrated on synthetic systems, a nonlinear system identification benchmark, and neural network compression.
Significance. If the central claims hold, the work could meaningfully extend decoupling techniques to multi-layer settings in nonlinear system identification and function approximation. The structured use of tensor decompositions combined with bilevel balancing of derivative and value data is a novel element that may improve model accuracy and efficiency, particularly for neural network compression tasks. The empirical demonstrations on benchmarks provide a useful starting point for validation.
minor comments (3)
- [Abstract] Abstract: the description of the bilevel optimization could be made more precise by indicating how the adaptive balancing is formulated (e.g., via explicit penalty or constraint terms).
- [Conclusion] The manuscript would benefit from a dedicated limitations section discussing computational scaling of the bilevel solver and sensitivity to initialization of the ParaTuck factors.
- [Numerical Experiments] Figures illustrating benchmark results should include quantitative metrics (e.g., RMSE or fit percentages) alongside qualitative plots for direct comparison with baseline methods.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The recognition of the potential impact in nonlinear system identification and neural network compression is appreciated. No major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The abstract and manuscript description introduce a ParaTuck-based tensor framework for multi-layer decoupling, a coupled matrix-tensor factorization, and bilevel optimization without any quoted equations, parameter fits, or self-citations that reduce the central claims to their own inputs by construction. No self-definitional steps, fitted predictions renamed as outputs, or load-bearing uniqueness theorems from prior author work are exhibited in the provided text. The theoretical justification is asserted as external to the derivation chain, and the approach is presented as self-contained against the stated modeling assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ParaTuck-type tensor decompositions can faithfully represent multi-layer decoupling structures
Reference graph
Works this paper leans on
-
[1]
Dreesen, M
P. Dreesen, M. Schoukens, K. Tiels, J. Schoukens, Decoupling static nonlinearities in a parallel Wiener-Hammerstein system: A first-order approach, in: IEEE International Instrumentation and Measurement Technology Conference (I2MTC) Proceedings, IEEE, 2015, pp. 987–992
2015
-
[2]
Hollander, Multivariate polynomial decoupling in nonlinear system identification, Ph.D
G. Hollander, Multivariate polynomial decoupling in nonlinear system identification, Ph.D. thesis, Vrije Universiteit Brussel (VUB) (2017)
2017
-
[3]
Karami, D
K. Karami, D. Westwick, J. Schoukens, Applying polynomial decoupling methods to the polynomial NARX model, Mechanical Systems and Signal Processing 148 (2021) 107134
2021
-
[4]
Zniyed, K
Y . Zniyed, K. Usevich, S. Miron, D. Brie, A tensor-based approach for training flexible neural networks, in: 55th Asilomar Conference on Signals, Systems, and Computers, IEEE, 2021, pp. 1673–1677
2021
-
[5]
Iarrobino, V
A. Iarrobino, V . Kanev, Power sums, Gorenstein algebras, and determinantal loci, Springer Science & Business Media, 1999
1999
-
[6]
J. M. Landsberg, Tensors: geometry and applications: geometry and applications, V ol. 128, American Mathematical Society, 2011
2011
-
[7]
Dreesen, M
P. Dreesen, M. Ishteva, J. Schoukens, Decoupling multivariate polynomials using first- order information and tensor decompositions, SIAM J Matrix Analysis and Applications 36 (2015) 864–879
2015
-
[8]
Decuyper, K
J. Decuyper, K. Tiels, S. Weiland, M. C. Runacres, J. Schoukens, Decoupling multivariate functions using a nonparametric filtered tensor decomposition, Mechanical Systems and Signal Processing 179 (2022) 109328. 30
2022
-
[9]
Decuyper, P
J. Decuyper, P. Dreesen, J. Schoukens, M. C. Runacres, K. Tiels, Decoupling multivariate polynomials for nonlinear state-space models, IEEE Control Systems Letters 3 (3) (2019) 745–750
2019
-
[10]
Dreesen, J
P. Dreesen, J. De Geeter, M. Ishteva, Decoupling multivariate functions using second- order information and tensors, in: Y . Deville, S. Gannot, R. Mason, M. D. Plumbley, D. Ward (Eds.), Proc. 14th International Conference on Latent Variable Analysis and Signal Separation (LV A/ICA 2018), V ol. 10891 of Lecture Notes on Computer Science (LNCS), Springer, ...
2018
-
[11]
De Jonghe, K
J. De Jonghe, K. Usevich, P. Dreesen, M. Ishteva, Compressing neural networks with two-layer decoupling, in: IEEE 9th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), IEEE, 2023, pp. 226–230
2023
-
[12]
T. G. Kolda, B. W. Bader, Tensor decompositions and applications, SIAM Review 51 (3) (2009) 455–500
2009
-
[13]
Dreesen, J
P. Dreesen, J. De Geeter, M. Ishteva, Decoupling multivariate functions using second- order information and tensors, in: Latent Variable Analysis and Signal Separation: 14th International Conference, LV A/ICA, Guildford, UK, July 2–5, 2018, Springer, 2018, pp. 79–88
2018
-
[14]
Fornasier, J
M. Fornasier, J. Vybíral, I. Daubechies, Robust and resource efficient identification of shallow neural networks by fewest samples., Information & Inference: A Journal of the IMA 10 (2) (2021)
2021
-
[15]
M. Janzamin, H. Sedghi, A. Anandkumar, Beating the perils of non-convexity: Guaran- teed training of neural networks using tensor methods, arXiv preprint arXiv:1506.08473 (2015)
-
[16]
Comon, M
P. Comon, M. Rajih, Blind identification of under-determined mixtures based on the char- acteristic function, Signal Processing 86 (9) (2006) 2271–2281
2006
-
[17]
Giri, E.-W
F. Giri, E.-W. Bai, Block-Oriented Nonlinear System Identification, V ol. 404 of Lecture Notes in Control and Information Sciences, Springer, 2010
2010
-
[18]
Schoukens, L
J. Schoukens, L. Ljung, Nonlinear system identification: A user-oriented road map, IEEE Control Systems Magazine 39 (6) (2019) 28–99. 31
2019
-
[19]
Hollander, P
G. Hollander, P. Dreesen, M. Ishteva, J. Schoukens, Parallel wiener-hammerstein identi- fication: A case study, in: ISMA2016 International Conference on Noise and Vibration Engineering and USD2016 International Conference on Uncertainty on Structural Dy- namics, KU Leuven, 2016, pp. 2647–2656
2016
-
[20]
Dreesen, A
P. Dreesen, A. F. Esfahani, J. Stoev, K. Tiels, J. Schoukens, Decoupling nonlinear state- space models: case studies, in: Proceedings of the International Conference on Noise and Vibration Engineering (ISMA), 2016, pp. 2639–2646
2016
-
[21]
Dreesen, M
P. Dreesen, M. Ishteva, Parameter estimation of parallel wiener-hammerstein systems by decoupling their volterra representations, IFAC-PapersOnLine 54 (7) (2021) 457–462
2021
-
[22]
Decuyper, D
J. Decuyper, D. Westwick, K. Karami, J. Schoukens, Decoupling P-NARX models using filtered CPD, IFAC-PapersOnLine 54 (7) (2021) 661–666
2021
-
[23]
Wigren, J
T. Wigren, J. Schoukens, Three free data sets for development and benchmarking in non- linear system identification, in: European control conference (ECC), IEEE, 2013, pp. 2933–2938
2013
-
[24]
J.-P. Noel, M. Schoukens, Hysteretic benchmark with a dynamic nonlinearity, in: Work- shop on nonlinear system identification benchmarks, 2016, pp. 7–14
2016
-
[25]
Apicella, F
A. Apicella, F. Donnarumma, F. Isgrò, R. Prevete, A survey on modern trainable activation functions, Neural Networks 138 (2021) 14–32
2021
-
[26]
Telgarsky, Neural networks and rational functions, in: International Conference on Machine Learning, PMLR, 2017, pp
M. Telgarsky, Neural networks and rational functions, in: International Conference on Machine Learning, PMLR, 2017, pp. 3387–3393
2017
-
[27]
Boullé, Y
N. Boullé, Y . Nakatsukasa, A. Townsend, Rational neural networks, Advances in Neural Information Processing Systems 33 (2020) 14243–14253
2020
-
[28]
Molina, P
A. Molina, P. Schramowski, K. Kersting, Padé activation units: End-to-end learning of flexible activation functions in deep networks, in: International Conference on Learning Representations, 2000
2000
- [29]
-
[30]
Unser, A representer theorem for deep neural networks, Journal of Machine Learning Research 20 (110) (2019) 1–30
M. Unser, A representer theorem for deep neural networks, Journal of Machine Learning Research 20 (110) (2019) 1–30
2019
-
[31]
Balestriero, R
R. Balestriero, R. G. Baraniuk, A spline theory of deep learning, in: International Confer- ence on Machine Learning, PMLR, 2018, pp. 374–383
2018
-
[32]
Parhi, R
R. Parhi, R. D. Nowak, Banach space representer theorems for neural networks and ridge splines, Journal of Machine Learning Research 22 (43) (2021) 1–40
2021
-
[33]
Bohra, J
P. Bohra, J. Campos, H. Gupta, S. Aziznejad, M. Unser, Learning activation functions in deep (spline) neural networks, IEEE Open Journal of Signal Processing 1 (2020) 295– 309
2020
-
[34]
Sitzmann, J
V . Sitzmann, J. Martel, A. Bergman, D. Lindell, G. Wetzstein, Implicit neural represen- tations with periodic activation functions, Advances in Neural Information Processing Systems 33 (2020) 7462–7473
2020
-
[35]
L. De Lathauwer, A link between the canonical decomposition in multilinear algebra and simultaneous matrix diagonalization, SIAM Journal on Matrix Analysis and Applications 28 (3) (2006) 642–666
2006
-
[36]
P. M. R. de Oliveira, C. A. R. Fernandes, G. Favier, R. Boyer, PARATUCK semi-blind receivers for relaying multi-hop mimo systems, Digital Signal Processing 92 (2019) 127– 138
2019
-
[37]
R. A. Harshman, M. E. Lundy, Uniqueness proof for a family of models sharing features of Tucker’s three-mode factor analysis and parafac/candecomp, Psychometrika 61 (1996) 133–154
1996
-
[38]
G. G. Lorentz, Bernstein polynomials, American Mathematical Soc., 2012
2012
-
[39]
J. Shi, S. Zhou, X. Liu, Q. Zhang, M. Lu, T. Wang, Stacked deep polynomial network based representation learning for tumor classification with small ultrasound image dataset, Neurocomputing 194 (2016) 87–94
2016
-
[40]
Comon, Y
P. Comon, Y . Qi, K. Usevich, Identifiability of an X-rank decomposition of polynomial maps, SIAM Journal on Applied Algebra and Geometry 1 (1) (2017) 388–414. 33
2017
-
[41]
Usevich, Y
K. Usevich, Y . Zniyed, M. Ishteva, P. Dreesen, A. L. de Almeida, Tensor-based two-layer decoupling of multivariate polynomial maps, in: 2023 31st European Signal Processing Conference (EUSIPCO), IEEE, 2023, pp. 655–659
2023
-
[42]
Liu, Tensors for Data Processing: Theory, Methods, and Applications, Academic Press, 2021
Y . Liu, Tensors for Data Processing: Theory, Methods, and Applications, Academic Press, 2021
2021
-
[43]
Zniyed, K
Y . Zniyed, K. Usevich, S. Miron, D. Brie, Learning nonlinearities in the decoupling prob- lem with structured CPD, IFAC-PapersOnLine 54 (7) (2021) 685–690
2021
-
[44]
Deng, The MNIST database of handwritten digit images for machine learning research, IEEE Signal Processing Magazine 29 (6) (2012) 141–142
L. Deng, The MNIST database of handwritten digit images for machine learning research, IEEE Signal Processing Magazine 29 (6) (2012) 141–142
2012
-
[45]
H. Xiao, K. Rasul, R. V ollgraf, Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms, arXiv preprint arXiv:1708.07747 (2017). 34 Appendix A. Proof of theorem 4.3 Proof.Given an exact decoupling offas in equation (6) with a parameterized representation of the internal functions as outlined in Section 4.3, an equivalent decoupl...
work page internal anchor Pith review arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.