Recognition: unknown
Understanding Communication Backends in Cross-Silo Federated Learning
Pith reviewed 2026-05-10 14:57 UTC · model grok-4.3
The pith
A hybrid gRPC+S3 backend achieves up to 3.8 times faster end-to-end performance than gRPC for transmitting large models in geo-distributed cross-silo federated learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that gRPC+S3, a hybrid backend designed to overcome the limitations of existing approaches, particularly for transmitting large models across geo-distributed deployments, achieves up to 3.8× end-to-end speedup over gRPC. Its benchmarks examine point-to-point and end-to-end performance for a broad range of model sizes running under realistic network conditions, providing practical insights for selecting and configuring suitable communication backends tailored to specific federated learning tasks and network configurations.
What carries the argument
The gRPC+S3 hybrid backend, which uses gRPC for control and coordination while offloading large model parameter transfers to S3 object storage.
Load-bearing premise
The tested network conditions, model sizes, and geo-distributed setups are representative of production cross-silo federated learning workloads.
What would settle it
Running identical benchmarks on real production geo-distributed clusters with models larger than those tested and finding no speedup or a slowdown for gRPC+S3 would falsify the central performance claim.
Figures




read the original abstract
Federated learning (FL) has emerged as a practical means for privacy-preserving distributed machine learning. FL's versatile design makes it suitable for various training settings, from IoT edge devices in cross-device FL to powerful servers in cross-silo FL. A key consequence of this versatility is the high level of diversity found in the networking configuration of FL applications. Coupled with the rising demand for large-scale models such as large language models, well-informed selection and configuration of communication backends become crucial for ensuring optimal performance in FL systems. This work focuses on cross-silo federated learning, presenting in-depth benchmarks of various communication backends, including MPI, gRPC, and PyTorch RPC. In addition, we introduce gRPC+S3, a hybrid backend designed to overcome the limitations of existing approaches, particularly for transmitting large models across geo-distributed deployments, achieving up to $3.8\times$ end-to-end speedup over gRPC. Our benchmarks examine point-to-point and end-to-end performance for a broad range of model sizes running under realistic network conditions. Our findings provide practical insights for selecting and configuring suitable communication backends tailored to the specific federated learning tasks and network configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks communication backends (MPI, gRPC, PyTorch RPC) for cross-silo federated learning and introduces a hybrid gRPC+S3 backend. It reports up to 3.8× end-to-end speedup for transmitting large models in geo-distributed settings, based on point-to-point and end-to-end measurements across model sizes under realistic network conditions, and provides practical guidance for backend selection in FL workloads.
Significance. If the results are representative of production conditions, the work supplies concrete performance data and a hybrid design that addresses a practical gap in scaling cross-silo FL to large models. The empirical comparisons can inform system builders facing diverse network topologies, though the value hinges on how closely the tested latencies, bandwidths, and geo-distribution patterns match real deployments.
major comments (2)
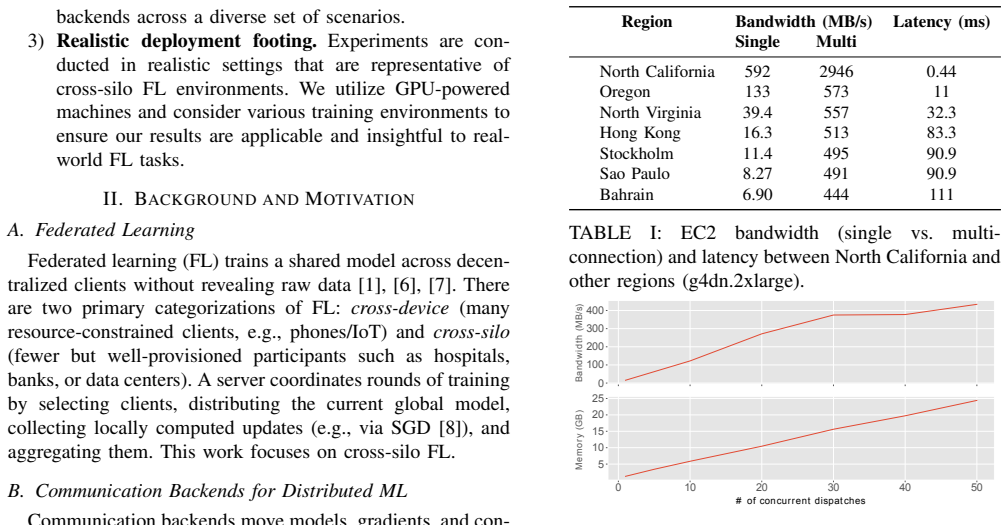
- [Evaluation] Evaluation section (benchmarks of end-to-end performance): The central 3.8× speedup claim rests on the tested network conditions being representative of production cross-silo FL. The manuscript states that experiments use 'realistic network conditions' but provides no explicit validation, such as comparison to measured inter-silo RTT distributions, tail latencies, or bandwidth traces from actual deployments. This directly affects whether the reported gains generalize beyond the simulated environment.
- [Design of gRPC+S3] § on gRPC+S3 hybrid design and point-to-point benchmarks: The hybrid backend is presented as overcoming limitations of pure gRPC for large models, yet the paper does not quantify the additional overhead (e.g., S3 upload/download latency or metadata costs) introduced by the object-store path versus a pure point-to-point approach. Without these measurements, it is unclear whether the net speedup holds under varying model-partitioning strategies or more frequent small-gradient exchanges typical in some FL workloads.
minor comments (2)
- [Abstract] Abstract and evaluation: The abstract mentions 'a broad range of model sizes' and 'realistic network conditions' but does not list the exact parameter counts, model architectures, or the precise latency/bandwidth values used in the simulations.
- [Evaluation] The manuscript should include error bars, number of runs, and statistical methods for the reported speedups to allow readers to assess variability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to provide additional validation and measurements.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (benchmarks of end-to-end performance): The central 3.8× speedup claim rests on the tested network conditions being representative of production cross-silo FL. The manuscript states that experiments use 'realistic network conditions' but provides no explicit validation, such as comparison to measured inter-silo RTT distributions, tail latencies, or bandwidth traces from actual deployments. This directly affects whether the reported gains generalize beyond the simulated environment.
Authors: We agree that explicit validation would strengthen the generalizability of the results. In the revised manuscript we have added a new paragraph in the Evaluation section that directly compares our chosen RTT and bandwidth values to published inter-region measurements from major cloud providers (AWS, GCP) that are representative of cross-silo deployments. We also include a sensitivity analysis showing how the reported speedups vary across a range of realistic latency/bandwidth combinations drawn from the literature. While we do not have access to proprietary production traces, the added material makes the basis for our “realistic” label transparent. revision: yes
-
Referee: [Design of gRPC+S3] § on gRPC+S3 hybrid design and point-to-point benchmarks: The hybrid backend is presented as overcoming limitations of pure gRPC for large models, yet the paper does not quantify the additional overhead (e.g., S3 upload/download latency or metadata costs) introduced by the object-store path versus a pure point-to-point approach. Without these measurements, it is unclear whether the net speedup holds under varying model-partitioning strategies or more frequent small-gradient exchanges typical in some FL workloads.
Authors: We thank the referee for this observation. The revised version now contains an explicit latency breakdown for the gRPC+S3 hybrid in the point-to-point benchmark subsection, reporting S3 upload/download times and metadata overhead separately for each model size. These data show that the hybrid path yields a net gain once model size exceeds approximately 500 MB; for smaller models or high-frequency small-gradient exchanges we explicitly recommend the pure gRPC backend. We have also added results for partitioned-model transmission to demonstrate that the net benefit persists under different partitioning strategies. revision: yes
Circularity Check
No circularity: purely empirical benchmarks with no derivations or self-referential reductions
full rationale
The paper presents in-depth benchmarks of communication backends (MPI, gRPC, PyTorch RPC) and introduces gRPC+S3 as a hybrid for large models in geo-distributed settings, reporting measured end-to-end speedups up to 3.8×. No equations, derivations, fitted parameters, predictions, or self-citations appear in the abstract or described content. All claims rest on direct experimental measurements under stated network conditions and model sizes, with no load-bearing step that reduces by construction to prior inputs or self-referential definitions. The analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Network latency, bandwidth, and geo-distribution patterns in the testbed match those encountered in real cross-silo deployments
invented entities (1)
-
gRPC+S3 hybrid backend
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ad- vances and open problems in federated learning. arxiv,
P. Kairouz, H. McMahan, B. Avent, A. Bellet, M. Bennis, A. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummingset al., “Ad- vances and open problems in federated learning. arxiv,”arXiv preprint arXiv:1912.04977, 2019
-
[2]
Mpi: A message-passing interface standard,
M. P. Forum, “Mpi: A message-passing interface standard,” 1994
1994
-
[3]
gRPC: A high performance, open source universal rpc framework,
“gRPC: A high performance, open source universal rpc framework,” https://grpc.io, accessed: 2023-09-15
2023
-
[4]
Pytorch rpc: Dis- tributed deep learning built on tensor-optimized remote procedure calls,
P. Damania, S. Li, A. Desmaison, A. Azzolini, B. Vaughan, E. Yang, G. Chanan, G. J. Chen, H. Jia, H. Huanget al., “Pytorch rpc: Dis- tributed deep learning built on tensor-optimized remote procedure calls,” Proceedings of Machine Learning and Systems, vol. 5, 2023
2023
-
[5]
Amazon simple storage service,
“Amazon simple storage service,” https://aws.amazon.com/s3/, accessed: 2023-09-15
2023
-
[6]
Communication-Efficient Learning of Deep Networks from Decen- tralized Data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-Efficient Learning of Deep Networks from Decen- tralized Data,” inProceedings of the 20th International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, A. Singh and J. Zhu, Eds., vol. 54. PMLR, 20–22 Apr 2017, pp. 1273–1282
2017
-
[7]
Federated Learning: Strategies for Improving Communication Efficiency
J. Kone ˇcn`y, H. B. McMahan, F. X. Yu, P. Richt ´arik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communication efficiency,”arXiv preprint arXiv:1610.05492, 2016
work page internal anchor Pith review arXiv 2016
-
[8]
A stochastic approximation method,
H. Robbins and S. Monro, “A stochastic approximation method,”The annals of mathematical statistics, pp. 400–407, 1951
1951
-
[9]
Google landmarks dataset v2-a large-scale benchmark for instance-level recognition and retrieval,
T. Weyand, A. Araujo, B. Cao, and J. Sim, “Google landmarks dataset v2-a large-scale benchmark for instance-level recognition and retrieval,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2575–2584
2020
-
[10]
Newsweeder: Learning to filter netnews,
K. Lang, “Newsweeder: Learning to filter netnews,” inMachine learning proceedings 1995. Elsevier, 1995, pp. 331–339
1995
-
[11]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[12]
Searching for mobilenetv3,
A. Howard, M. Sandler, G. Chu, L.-C. Chen, B. Chen, M. Tan, W. Wang, Y . Zhu, R. Pang, V . Vasudevanet al., “Searching for mobilenetv3,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 1314–1324
2019
-
[13]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
V . Sanh, L. Debut, J. Chaumond, and T. Wolf, “Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter,”arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review arXiv 1910
-
[14]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations, 2021
2021
-
[15]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations, 2022
2022
-
[16]
Ezzeldin, Qingfeng Liu, Kee- Bong Song, Mostafa El-Khamy, and Salman Avestimehr
S. Babakniya, A. R. Elkordy, Y . H. Ezzeldin, Q. Liu, K.-B. Song, M. El- Khamy, and S. Avestimehr, “Slora: Federated parameter efficient fine- tuning of language models,”arXiv preprint arXiv:2308.06522, 2023
-
[17]
Fedml: A research li- brary and benchmark for federated machine learning,
C. He, S. Li, J. So, X. Zeng, M. Zhang, H. Wang, X. Wang, P. Vepakomma, A. Singh, H. Qiuet al., “Fedml: A research li- brary and benchmark for federated machine learning,”arXiv preprint arXiv:2007.13518, 2020
-
[18]
Open mpi: Goals, concept, and design of a next generation mpi implementation,
E. Gabriel, G. E. Fagg, G. Bosilca, T. Angskun, J. J. Dongarra, J. M. Squyres, V . Sahay, P. Kambadur, B. Barrett, A. Lumsdaineet al., “Open mpi: Goals, concept, and design of a next generation mpi implementation,” inRecent Advances in Parallel Virtual Machine and Message Passing Interface: 11th European PVM/MPI Users’ Group Meeting Budapest, Hungary, Sep...
2004
-
[19]
Ucx: an open source framework for hpc network apis and beyond,
P. Shamis, M. G. Venkata, M. G. Lopez, M. B. Baker, O. Hernandez, Y . Itigin, M. Dubman, G. Shainer, R. L. Graham, L. Lisset al., “Ucx: an open source framework for hpc network apis and beyond,” in2015 IEEE 23rd Annual Symposium on High-Performance Interconnects. IEEE, 2015, pp. 40–43
2015
-
[20]
mpi4py: Status update after 12 years of development,
L. Dalcin and Y .-L. L. Fang, “mpi4py: Status update after 12 years of development,”Computing in Science & Engineering, vol. 23, no. 4, pp. 47–54, 2021
2021
-
[21]
Flower: A friendly federated learning research framework.arXiv preprint arXiv:2007.14390,
D. J. Beutel, T. Topal, A. Mathur, X. Qiu, J. Fernandez-Marques, Y . Gao, L. Sani, K. H. Li, T. Parcollet, P. P. B. de Gusm ˜aoet al., “Flower: A friendly federated learning research framework,”arXiv preprint arXiv:2007.14390, 2020
-
[22]
Fedscale: Benchmarking model and system perfor- mance of federated learning at scale,
F. Lai, Y . Dai, S. Singapuram, J. Liu, X. Zhu, H. Madhyastha, and M. Chowdhury, “Fedscale: Benchmarking model and system perfor- mance of federated learning at scale,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 11 814–11 827
2022
-
[23]
Arm meets cloud: A case study of mpi library performance on aws arm-based hpc cloud with elastic fabric adapter,
S. Xu, A. Shafi, H. Subramoni, and D. K. Panda, “Arm meets cloud: A case study of mpi library performance on aws arm-based hpc cloud with elastic fabric adapter,” in2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE, 2022, pp. 449–456
2022
-
[24]
Qsgd: Communication-efficient sgd via gradient quantization and encoding,
D. Alistarh, D. Grubic, J. Li, R. Tomioka, and M. V ojnovic, “Qsgd: Communication-efficient sgd via gradient quantization and encoding,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[25]
Gradient sparsification for communication-efficient distributed optimization,
J. Wangni, J. Wang, J. Liu, and T. Zhang, “Gradient sparsification for communication-efficient distributed optimization,”Advances in Neural Information Processing Systems, vol. 31, 2018
2018
-
[26]
Throughput-optimal topology design for cross-silo federated learning,
O. Marfoq, C. Xu, G. Neglia, and R. Vidal, “Throughput-optimal topology design for cross-silo federated learning,”Advances in Neural Information Processing Systems, vol. 33, pp. 19 478–19 487, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.