Recognition: unknown
LiveGesture Streamable Co-Speech Gesture Generation Model
Pith reviewed 2026-05-10 16:43 UTC · model grok-4.3
The pith
LiveGesture generates full-body co-speech gestures in real time with zero look-ahead while matching offline state-of-the-art performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
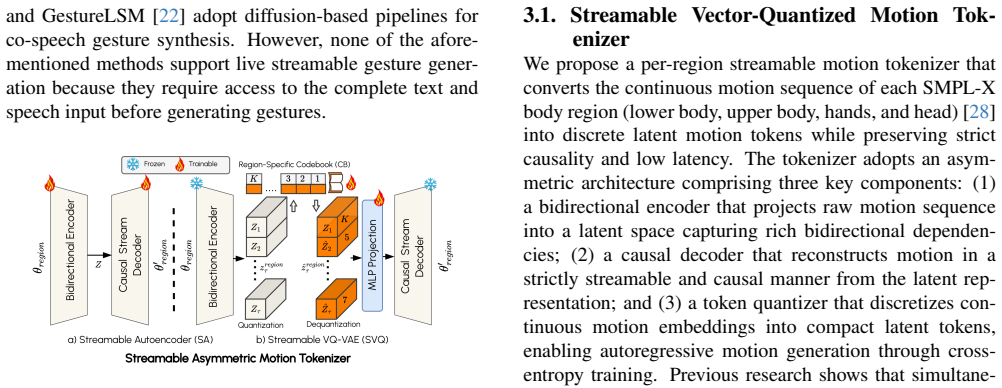
LiveGesture is the first fully streamable, speech-driven full-body gesture generation framework that operates with zero look-ahead and supports arbitrary sequence length. It consists of a Streamable Vector Quantized Motion Tokenizer that converts each body region's motion sequence into causal discrete tokens, a Hierarchical Autoregressive Transformer that uses region-expert autoregressive modules plus a causal spatio-temporal fusion layer conditioned on continuously arriving audio, and autoregressive masking training that applies uncertainty-guided token masking and random region masking to build robustness against imperfect histories. On the BEAT2 dataset this produces coherent, diverse, be
What carries the argument
The Streamable Vector Quantized Motion Tokenizer (SVQ) that produces causal discrete motion tokens per body region, paired with the Hierarchical Autoregressive Transformer (HAR) that runs region-expert xAR transformers and a causal xAR Fusion module, all conditioned on a streamable causal audio encoder.
If this is right
- Full-body gesture sequences of any length can be produced causally from continuous speech input without fixed windows or future frames.
- Region-specific motion dynamics are modeled separately yet coordinated through causal fusion, preserving both fine-grained detail and inter-region consistency.
- Performance on the BEAT2 benchmark reaches or exceeds offline methods even when the model receives only past and present audio under true zero look-ahead conditions.
- The system remains robust to streaming noise because training explicitly exposes it to partially erroneous token histories.
Where Pith is reading between the lines
- The causal architecture could be adapted to other incremental generation tasks such as live facial animation or sign-language synthesis from speech.
- Deployment in real-time applications like virtual meetings would require only the addition of an audio buffer and motion renderer, since the model already supports arbitrary lengths.
- If the masking strategy generalizes, similar uncertainty-guided training could improve robustness in other autoregressive streaming models for motion or video.
Load-bearing premise
The autoregressive masking training with uncertainty-guided token masking and random region masking sufficiently prepares the model for the kinds of prediction errors and incomplete histories that occur during actual live streaming inference.
What would settle it
Running the trained model in a true end-to-end streaming pipeline on long unseen speech sequences from BEAT2 or a similar dataset and measuring whether gesture beat synchronization, diversity, and naturalness scores remain comparable to offline baselines when evaluated against ground-truth motion.
Figures




read the original abstract
We propose LiveGesture, the first fully streamable, speech-driven full-body gesture generation framework that operates with zero look-ahead and supports arbitrary sequence length. Unlike existing co-speech gesture methods, which are designed for offline generation and either treat body regions independently or entangle all joints within a single model, LiveGesture is built from the ground up for causal, region-coordinated motion generation. LiveGesture consists of two main modules: the Streamable Vector Quantized Motion Tokenizer (SVQ) and the Hierarchical Autoregressive Transformer (HAR). The SVQ tokenizer converts the motion sequence of each body region into causal, discrete motion tokens, enabling real-time, streamable token decoding. On top of SVQ, HAR employs region-expert autoregressive (xAR) transformers to model expressive, fine-grained motion dynamics for each body region. A causal spatio-temporal fusion module (xAR Fusion) then captures and integrates correlated motion dynamics across regions. Both xAR and xAR Fusion are conditioned on live, continuously arriving audio signals encoded by a streamable causal audio encoder. To enhance robustness under streaming noise and prediction errors, we introduce autoregressive masking training, which leverages uncertainty-guided token masking and random region masking to expose the model to imperfect, partially erroneous histories during training. Experiments on the BEAT2 dataset demonstrate that LiveGesture produces coherent, diverse, and beat-synchronous full-body gestures in real time, matching or surpassing state-of-the-art offline methods under true zero look-ahead conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LiveGesture, the first fully streamable speech-driven full-body gesture generation framework with zero look-ahead and arbitrary sequence length. It introduces a Streamable Vector Quantized Motion Tokenizer (SVQ) for causal discrete motion tokens per body region and a Hierarchical Autoregressive Transformer (HAR) using region-expert autoregressive (xAR) transformers plus a causal xAR Fusion module, both conditioned on a streamable causal audio encoder. Training incorporates autoregressive masking (uncertainty-guided token masking and random region masking) to build robustness to imperfect histories. Experiments on BEAT2 claim coherent, diverse, beat-synchronous gestures matching or surpassing offline SOTA under true streaming conditions.
Significance. If the streaming performance claims hold with rigorous quantitative support, the work would be significant for enabling practical real-time applications in virtual agents, VR, and HCI by closing the gap between high-quality offline co-speech gesture models and causal online requirements. The causal architecture and masking strategy represent a targeted engineering contribution, though its robustness to closed-loop error accumulation remains to be fully validated.
major comments (1)
- [Description of autoregressive masking training and inference procedure] The autoregressive masking training (uncertainty-guided token masking and random region masking) is presented as the mechanism to handle prediction errors in live streaming. However, these strategies are applied to ground-truth sequences with artificial masks rather than to the model's own accumulated predictions in closed-loop inference. This leaves open whether the training distribution matches the error patterns arising from the xAR and xAR Fusion modules when feeding generated tokens back as history, which is load-bearing for the central claim of matching offline SOTA under true zero look-ahead streaming.
minor comments (2)
- [Abstract] The abstract states that experiments 'demonstrate' matching or surpassing SOTA but provides no numerical metrics, ablation results, or error analysis; these quantitative details should be summarized in the abstract or introduction for immediate assessment of the claims.
- [Hierarchical Autoregressive Transformer (HAR) section] Notation for the xAR Fusion module and its conditioning on live audio should be clarified with explicit equations showing causality constraints, as the current description leaves the exact integration of region correlations ambiguous.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the insightful comment on our training procedure. We address the concern directly below and propose revisions to improve clarity.
read point-by-point responses
-
Referee: The autoregressive masking training (uncertainty-guided token masking and random region masking) is presented as the mechanism to handle prediction errors in live streaming. However, these strategies are applied to ground-truth sequences with artificial masks rather than to the model's own accumulated predictions in closed-loop inference. This leaves open whether the training distribution matches the error patterns arising from the xAR and xAR Fusion modules when feeding generated tokens back as history, which is load-bearing for the central claim of matching offline SOTA under true zero look-ahead streaming.
Authors: We agree that the masking is performed on ground-truth sequences with artificial perturbations rather than on the model's own closed-loop predictions. This is a standard teacher-forcing approximation chosen to expose the model to imperfect histories while avoiding the severe instability and slow convergence that full closed-loop training often produces in hierarchical autoregressive setups. The uncertainty-guided token masking and random region masking are calibrated to approximate the kinds of local and cross-region errors observed at inference. Our BEAT2 streaming results (matching offline SOTA under true zero-lookahead conditions) provide empirical support that the strategy transfers effectively, but we acknowledge the distribution mismatch remains a valid concern. In the revised manuscript we will (1) expand the method section with an explicit discussion of this training-inference gap and the rationale for the chosen masking schedule, (2) add an ablation that reports error statistics under both artificial masking and a limited closed-loop simulation on validation data, and (3) include a short limitations paragraph noting that full closed-loop robustness validation is left for future work. These changes will make the load-bearing claim more transparent without altering the core architecture or reported numbers. revision: yes
Circularity Check
No circularity: performance claims rest on external empirical evaluation
full rationale
The paper introduces LiveGesture with SVQ tokenizer, HAR (xAR + xAR Fusion), and autoregressive masking training as architectural and training choices. These are then evaluated empirically on the external BEAT2 dataset under streaming conditions. No equations, parameters, or claims reduce by construction to the inputs; the masking strategy is a proposed robustness technique whose effectiveness is tested rather than assumed. No self-citations, uniqueness theorems, or fitted inputs are invoked as load-bearing for the core claims. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- model architecture hyperparameters
invented entities (2)
-
Streamable Vector Quantized Motion Tokenizer (SVQ)
no independent evidence
-
Hierarchical Autoregressive Transformer (HAR) with xAR Fusion
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, Sand- hini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, T. J. Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeff Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz ...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[2]
Everybody Dance Now
Caroline Chan, Shiry Ginosar, Tinghui Zhou, and Alexei A Efros. Everybody Dance Now. InICCV, 2019. 2
2019
-
[3]
Enabling synergistic full-body control in prompt-based co-speech motion generation
Bohong Chen, Yumeng Li, Yao-Xiang Ding, Tianjia Shao, and Kun Zhou. Enabling synergistic full-body control in prompt-based co-speech motion generation. InProceedings of the 32nd ACM International Conference on Multimedia, page 10, New York, NY , USA, 2024. ACM. 2, 7
2024
-
[4]
DiffSHEG: A Diffusion-Based Ap- proach for Real-Time Speech-driven Holistic 3D Expression and Gesture Generation, 2024
Junming Chen, Yunfei Liu, Jianan Wang, Ailing Zeng, Yu Li, and Qifeng Chen. DiffSHEG: A Diffusion-Based Ap- proach for Real-Time Speech-driven Holistic 3D Expression and Gesture Generation, 2024. 2, 7
2024
-
[5]
Diffusion-based co-speech gesture genera- tion using joint text and audio representation
Anna Deichler, Shivam Mehta, Simon Alexanderson, and Jonas Beskow. Diffusion-based co-speech gesture genera- tion using joint text and audio representation. InINTER- NATIONAL CONFERENCE ON MULTIMODAL INTERAC- TION. ACM, 2023. 2
2023
-
[6]
Luca Della Libera, Cem Subakan, and Mirco Ravanelli. Focalcodec-stream: Streaming low-bitrate speech coding via causal distillation.arXiv preprint arXiv:2509.16195, 2025. 8
-
[7]
Tam- ing transformers for high-resolution image synthesis.2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12868–12878, 2020
Patrick Esser, Robin Rombach, and Bj ¨orn Ommer. Tam- ing transformers for high-resolution image synthesis.2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12868–12878, 2020. 2
2021
-
[8]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021. 4
2021
-
[9]
Ginosar, A
S. Ginosar, A. Bar, G. Kohavi, C. Chan, A. Owens, and J. Malik. Learning Individual Styles of Conversational Ges- ture. InCVPR. IEEE, 2019. 2
2019
-
[10]
Momask: Generative masked model- ing of 3d human motions
Chuan Guo, Yuxuan Mu, Muhammad Gohar Javed, Sen Wang, and Li Cheng. Momask: Generative masked model- ing of 3d human motions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1900–1910, 2024. 2
1900
-
[11]
Learning speech-driven 3d conversational gestures from video.arXiv preprint arXiv:2102.06837, 2021
Ikhsanul Habibie, Weipeng Xu, Dushyant Mehta, Lingjie Liu, Hans-Peter Seidel, Gerard Pons-Moll, Mohamed El- gharib, and Christian Theobalt. Learning speech-driven 3d conversational gestures from video.arXiv preprint arXiv:2102.06837, 2021. 2
-
[12]
Modeling and driving human body soundfields through acoustic primitives, 2024
Chao Huang, Dejan Markovic, Chenliang Xu, and Alexan- der Richard. Modeling and driving human body soundfields through acoustic primitives, 2024. 2
2024
-
[13]
Motiongpt: Human motion as a foreign language
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign language. ArXiv, abs/2306.14795, 2023. 2
-
[14]
Audio2gestures: Generating diverse gestures from speech audio with conditional varia- tional autoencoders
Jing Li, Di Kang, Wenjie Pei, Xuefei Zhe, Ying Zhang, Zhenyu He, and Linchao Bao. Audio2gestures: Generating diverse gestures from speech audio with conditional varia- tional autoencoders. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 11293– 11302, 2021. 6, 13
2021
-
[15]
AI Choreographer: Music Conditioned 3D Dance Generation with AIST++
Ruilong Li, Shan Yang, David A Ross, and Angjoo Kanazawa. AI Choreographer: Music Conditioned 3D Dance Generation with AIST++. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13401–13412, 2021. 6, 14
2021
-
[16]
DisCo: Disentan- gled Implicit Content and Rhythm Learning for Diverse Co- Speech Gestures Synthesis
Haiyang Liu, Naoya Iwamoto, Zihao Zhu, Zhengqing Li, You Zhou, Elif Bozkurt, and Bo Zheng. DisCo: Disentan- gled Implicit Content and Rhythm Learning for Diverse Co- Speech Gestures Synthesis. InProceedings of the 30th ACM International Conference on Multimedia, pages 3764–3773,
-
[17]
Haiyang Liu, Zihao Zhu, Naoya Iwamoto, Yichen Peng, Zhengqing Li, You Zhou, Elif Bozkurt, and Bo Zheng. BEAT: A Large-Scale Semantic and Emotional Multi-Modal Dataset for Conversational Gestures Synthesis.arXiv preprint arXiv:2203.05297, 2022. 2, 7, 14, 15
-
[18]
Haiyang Liu, Zihao Zhu, Giorgio Becherini, Yichen Peng, Mingyang Su, You Zhou, Naoya Iwamoto, Bo Zheng, and Michael J Black. EMAGE: Towards Unified Holistic Co- Speech Gesture Generation via Masked Audio Gesture Mod- eling.arXiv preprint arXiv:2401.00374, 2023. 2, 6, 7, 14, 15
-
[19]
Haiyang Liu, Xingchao Yang, Tomoya Akiyama, Yuantian Huang, Qiaoge Li, Shigeru Kuriyama, and Takafumi Take- tomi. Tango: Co-speech gesture video reenactment with hi- erarchical audio motion embedding and diffusion interpola- tion.arXiv preprint arXiv:2410.04221, 2024. 2
-
[20]
Semges: Semantics-aware co-speech gesture genera- tion using semantic coherence and relevance learning, 2025
Lanmiao Liu, Esam Ghaleb, Aslı ¨Ozy¨urek, and Zerrin Yu- mak. Semges: Semantics-aware co-speech gesture genera- tion using semantic coherence and relevance learning, 2025
2025
-
[21]
Intentional gesture: Deliver your intentions with gestures for speech, 2025
Pinxin Liu, Haiyang Liu, Luchuan Song, and Chenliang Xu. Intentional gesture: Deliver your intentions with gestures for speech, 2025. 2
2025
-
[22]
Gesturelsm: Latent shortcut based co-speech gesture generation with spatial-temporal modeling
Pinxin Liu, Luchuan Song, Junhua Huang, and Chenliang Xu. Gesturelsm: Latent shortcut based co-speech gesture generation with spatial-temporal modeling. InIEEE/CVF International Conference on Computer Vision, 2025. 2, 3, 7, 14, 15
2025
-
[23]
Contextual gesture: Co- speech gesture video generation through context-aware ges- ture representation, 2025
Pinxin Liu, Pengfei Zhang, Hyeongwoo Kim, Pablo Garrido, Ari Sharpio, and Kyle Olszewski. Contextual gesture: Co- speech gesture video generation through context-aware ges- ture representation, 2025. 2
2025
-
[24]
Learning Hierarchical Cross-Modal Association for Co-Speech Gesture Generation
Xian Liu, Qianyi Wu, Hang Zhou, Yinghao Xu, Rui Qian, Xinyi Lin, Xiaowei Zhou, Wayne Wu, Bo Dai, and Bolei Zhou. Learning Hierarchical Cross-Modal Association for Co-Speech Gesture Generation. InCVPR, pages 10462– 10472, 2022. 2, 7
2022
-
[25]
Yifei Liu, Qiong Cao, Yandong Wen, Huaiguang Jiang, and Changxing Ding. Towards variable and coordinated holistic co-speech motion generation.arXiv preprint arXiv:2404.00368, 2024. 7
-
[26]
Vita-audio: Fast interleaved cross-modal token generation for efficient large speech-language model
Zuwei Long, Yunhang Shen, Chaoyou Fu, Heting Gao, Li- jiang Li, Peixian Chen, Mengdan Zhang, Hang Shao, Jian Li, Jinlong Peng, et al. Vita-audio: Fast interleaved cross-modal token generation for efficient large speech-language model. arXiv preprint arXiv:2505.03739, 2025. 8
-
[27]
Retrieving seman- tics from the deep: an rag solution for gesture synthesis
M Hamza Mughal, Rishabh Dabral, Merel CJ Scholman, Vera Demberg, and Christian Theobalt. Retrieving seman- tics from the deep: an rag solution for gesture synthesis. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 16578–16588, 2025. 7
2025
-
[28]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10975–10985, 2019. 3
2019
-
[29]
Bamm: Bidirectional autoregressive motion model
Ekkasit Pinyoanuntapong, Muhammad Usama Saleem, Pu Wang, Minwoo Lee, Srijan Das, and Chen Chen. Bamm: Bidirectional autoregressive motion model. InComputer Vi- sion – ECCV 2024, 2024. 2
2024
-
[30]
Mmm: Generative masked motion model
Ekkasit Pinyoanuntapong, Pu Wang, Minwoo Lee, and Chen Chen. Mmm: Generative masked motion model. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
2024
-
[31]
Zero-Shot Text-to-Image Generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation.ArXiv, abs/2102.12092,
work page internal anchor Pith review arXiv
-
[32]
Talking face video generation with editable expression
Luchuan Song, Bin Liu, and Nenghai Yu. Talking face video generation with editable expression. InImage and Graphics: 11th International Conference, ICIG 2021, Haikou, China, August 6–8, 2021, Proceedings, Part III 11, pages 753–764. Springer, 2021. 2
2021
-
[33]
Fsft-net: face transfer video generation with few-shot views
Luchuan Song, Guojun Yin, Bin Liu, Yuhui Zhang, and Nenghai Yu. Fsft-net: face transfer video generation with few-shot views. In2021 IEEE international conference on image processing (ICIP), pages 3582–3586. IEEE, 2021. 2
2021
-
[34]
Texttoon: Real-time text toonify head avatar from single video
Luchuan Song, Lele Chen, Celong Liu, Pinxin Liu, and Chenliang Xu. Texttoon: Real-time text toonify head avatar from single video. InSIGGRAPH Asia 2024 Conference Pa- pers, pages 1–11, 2024. 2
2024
-
[35]
Tri 2-plane: Thinking head avatar via fea- ture pyramid
Luchuan Song, Pinxin Liu, Lele Chen, Guojun Yin, and Chenliang Xu. Tri 2-plane: Thinking head avatar via fea- ture pyramid. InEuropean Conference on Computer Vision, pages 1–20. Springer, 2024
2024
-
[36]
Adaptive super resolution for one-shot talking-head genera- tion
Luchuan Song, Pinxin Liu, Guojun Yin, and Chenliang Xu. Adaptive super resolution for one-shot talking-head genera- tion. InICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4115–4119, 2024. 2
2024
-
[37]
Yakun Song, Jiawei Chen, Xiaobin Zhuang, Chenpeng Du, Ziyang Ma, Jian Wu, Jian Cong, Dongya Jia, Zhuo Chen, Yuping Wang, et al. Magicodec: Simple masked gaussian- injected codec for high-fidelity reconstruction and genera- tion.arXiv preprint arXiv:2506.00385, 2025. 8
-
[38]
Generative ai for cel- animation: A survey.arXiv preprint arXiv:2501.06250,
Yunlong Tang, Junjia Guo, Pinxin Liu, Zhiyuan Wang, Hang Hua, Jia-Xing Zhong, Yunzhong Xiao, Chao Huang, Luchuan Song, Susan Liang, et al. Generative ai for cel- animation: A survey.arXiv preprint arXiv:2501.06250,
-
[39]
Neural discrete representation learning.Advances in neural information pro- cessing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information pro- cessing systems, 30, 2017. 4
2017
-
[40]
High-Resolution Im- age Synthesis and Semantic Manipulation with Conditional GANs
Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-Resolution Im- age Synthesis and Semantic Manipulation with Conditional GANs. InCVPR, 2018. 2
2018
-
[41]
Hierarchical quantized au- toencoders.ArXiv, abs/2002.08111, 2020
Will Williams, Sam Ringer, Tom Ash, John Hughes, David Macleod, and Jamie Dougherty. Hierarchical quantized au- toencoders.ArXiv, abs/2002.08111, 2020. 2
-
[42]
Codetalker: Speech-driven 3d facial animation with discrete motion prior
Jinbo Xing, Menghan Xia, Yuechen Zhang, Xiaodong Cun, Jue Wang, and Tien-Tsin Wong. Codetalker: Speech-driven 3d facial animation with discrete motion prior. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12780–12790, 2023. 6, 14
2023
-
[43]
Chain of generation: Multi-modal gesture synthesis via cascaded conditional control, 2023
Zunnan Xu, Yachao Zhang, Sicheng Yang, Ronghui Li, and Xiu Li. Chain of generation: Multi-modal gesture synthesis via cascaded conditional control, 2023. 2
2023
-
[44]
Mambatalk: Ef- ficient holistic gesture synthesis with selective state space models, 2024
Zunnan Xu, Yukang Lin, Haonan Han, Sicheng Yang, Ronghui Li, Yachao Zhang, and Xiu Li. Mambatalk: Ef- ficient holistic gesture synthesis with selective state space models, 2024. 2, 7
2024
-
[45]
Generating Holistic 3D Human Motion from Speech
Hongwei Yi, Hualin Liang, Yifei Liu, Qiong Cao, Yandong Wen, Timo Bolkart, Dacheng Tao, and Michael J Black. Generating Holistic 3D Human Motion from Speech. In CVPR, 2023. 2, 7
2023
-
[46]
Speech Ges- ture Generation from the Trimodal Context of Text, Audio, and Speaker Identity.ACM TOG, 39(6), 2020
Youngwoo Yoon, Bok Cha, Joo-Haeng Lee, Minsu Jang, Jaeyeon Lee, Jaehong Kim, and Geehyuk Lee. Speech Ges- ture Generation from the Trimodal Context of Text, Audio, and Speaker Identity.ACM TOG, 39(6), 2020. 6, 13
2020
-
[47]
Vector-quantized image modeling with improved vqgan.arXiv preprint arXiv:2110.04627, 2021
Jiahui Yu, Xin Li, Jing Yu Koh, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, and Yonghui Wu. Vector-quantized image modeling with improved vqgan.ArXiv, abs/2110.04627, 2021. 2
-
[48]
Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Shaoli Huang, Yong Zhang, Hongwei Zhao, Hongtao Lu, and Xi- aodong Shen. Generating human motion from textual de- scriptions with discrete representations.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14730–14740, 2023. 2
2023
-
[49]
Kinmo: Kinematic-aware human motion understanding and generation, 2024
Pengfei Zhang, Pinxin Liu, Hyeongwoo Kim, Pablo Garrido, and Bindita Chaudhuri. Kinmo: Kinematic-aware human motion understanding and generation, 2024. 2
2024
-
[50]
Chongyang Zhong, Lei Hu, Zihao Zhang, and Shihong Xia. Attt2m: Text-driven human motion generation with multi- perspective attention mechanism.ArXiv, abs/2309.00796,
-
[51]
Supplementary Material A. Overview The supplementary material is organized as follows: • Section B: Implementation Details of the Streamable Vector-Quantized Motion Tokenizer (SVQ) and the Hierarchical Autoregressive Transformer (HAR) • Section C: Evaluation Metrics • Section D: SOTA Comparison: Quantitative Results Without Face Module • Section E: SOTA C...
2048
-
[52]
Higher values indicate more expressive and varied motion under causal token-by-token prediction
(2) Global translation of the SMPL-X body is removed prior to evaluation. Higher values indicate more expressive and varied motion under causal token-by-token prediction. Beat Constancy (BC).. Beat Constancy [15] evaluates the synchrony between motion beats and prosodic beats in the audio. Motion beats are detected from local minima of upper-body joint ve...
-
[53]
causal self- attention
(4) This complements body-motion metrics by evaluating fine-grained facial deformation fidelity. D. SOTA Comparison: Quantitative Results Without Face Module Table 1. Comparison with state-of-the-art methods on BEAT2 without the facial motion module.LiveGestureremains the only zero–look- ahead streaming model while achieving competitive or superior perfor...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.