Recognition: no theorem link
Learning to Adapt: In-Context Learning Beyond Stationarity
Pith reviewed 2026-05-10 16:26 UTC · model grok-4.3
The pith
Gated linear attention reduces errors in non-stationary in-context learning by learning a recency bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
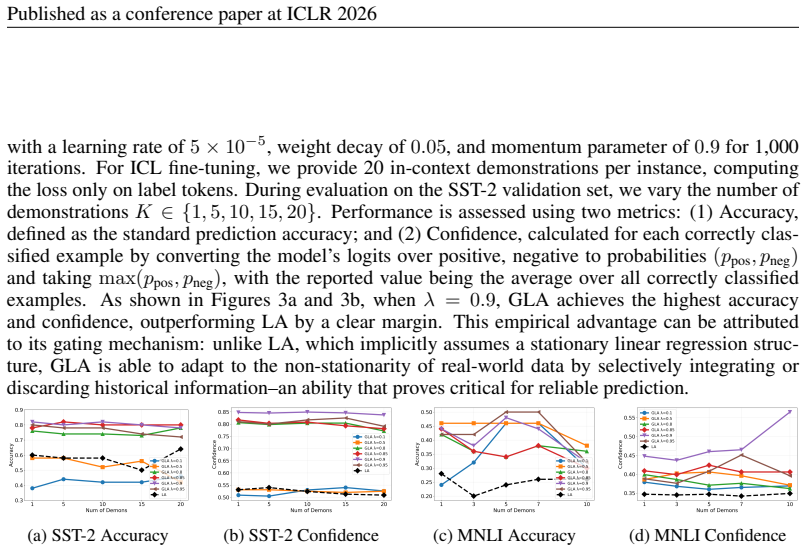
In non-stationary regression problems where the target function follows a first-order autoregressive process, the gated linear attention mechanism achieves lower training and testing errors than standard linear attention by adaptively modulating the influence of past inputs, thereby implementing a learnable recency bias.
What carries the argument
Gated linear attention (GLA), which inserts a learned gate to control how much each past input contributes to the current prediction.
Load-bearing premise
Non-stationarity is adequately captured by a first-order autoregressive process on the target function.
What would settle it
Running the same regression task with sudden, non-autoregressive jumps in the target function and finding that GLA no longer shows lower error than linear attention.
Figures


read the original abstract
Transformer models have become foundational across a wide range of scientific and engineering domains due to their strong empirical performance. A key capability underlying their success is in-context learning (ICL): when presented with a short prompt from an unseen task, transformers can perform per-token and next-token predictions without any parameter updates. Recent theoretical efforts have begun to uncover the mechanisms behind this phenomenon, particularly in supervised regression settings. However, these analyses predominantly assume stationary task distributions, which overlook a broad class of real-world scenarios where the target function varies over time. In this work, we bridge this gap by providing a theoretical analysis of ICL under non-stationary regression problems. We study how the gated linear attention (GLA) mechanism adapts to evolving input-output relationships and rigorously characterize its advantages over standard linear attention in this dynamic setting. To model non-stationarity, we adopt a first-order autoregressive process and show that GLA achieves lower training and testing errors by adaptively modulating the influence of past inputs -- effectively implementing a learnable recency bias. Our theoretical findings are further supported by empirical results, which validate the benefits of gating mechanisms in non-stationary ICL tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper provides a theoretical analysis of in-context learning (ICL) in non-stationary supervised regression settings. It models non-stationarity via a first-order autoregressive (AR(1)) process on the target function and analyzes the gated linear attention (GLA) mechanism, claiming that GLA achieves lower training and testing errors than standard linear attention by adaptively modulating the influence of past inputs and thereby implementing a learnable recency bias. The theoretical results are supported by empirical validation on non-stationary ICL tasks.
Significance. If the derivations hold, the work is significant because it extends existing ICL theory (which has focused on stationary task distributions) to a dynamic setting that better matches many real-world applications. The explicit characterization of how gating produces a recency bias offers a mechanistic explanation that could inform architecture design for adaptive transformers.
major comments (1)
- [Abstract] Abstract: The central claim that GLA 'achieves lower training and testing errors by adaptively modulating the influence of past inputs' is derived under the modeling choice that the target function evolves as a first-order autoregressive process. No indication is given that the error reduction or the recency-bias interpretation extends to higher-order dependence, non-Markovian drifts, or abrupt regime shifts; if the gating equations are tuned to the AR(1) correlation structure, the reported advantage may be an artifact of that specific choice rather than a general property of non-stationary ICL.
minor comments (2)
- [Abstract] The abstract states that the advantages are 'rigorously characterize[d]' yet provides no proof sketches, error bounds, or key intermediate steps; including a brief outline of the main derivation (e.g., how the gating parameters are optimized under the AR(1) assumption) would improve readability.
- [Empirical results] The empirical section is referenced as validating the theory, but without details on the range of non-stationarity strengths tested or ablation on the gating parameters, it is difficult to assess how strongly the experiments probe the claimed generality.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We address the major concern regarding the scope of our theoretical claims below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that GLA 'achieves lower training and testing errors by adaptively modulating the influence of past inputs' is derived under the modeling choice that the target function evolves as a first-order autoregressive process. No indication is given that the error reduction or the recency-bias interpretation extends to higher-order dependence, non-Markovian drifts, or abrupt regime shifts; if the gating equations are tuned to the AR(1) correlation structure, the reported advantage may be an artifact of that specific choice rather than a general property of non-stationary ICL.
Authors: We agree that our analysis is specifically derived for the AR(1) model of task evolution, as explicitly stated in the abstract and Section 2 of the manuscript. This modeling choice is standard for capturing temporal correlations in non-stationary environments and allows for closed-form derivations of the optimal recency bias. The gated linear attention mechanism is not 'tuned' to AR(1) in a restrictive way; rather, the learnable gating parameters enable the model to discover the appropriate decay rate during training, which matches the AR(1) correlation structure in our setting. This leads to the demonstrated error reduction. While we do not analyze higher-order or non-Markovian cases here, the empirical validation includes tasks with varying degrees of non-stationarity, and the mechanistic explanation of recency bias via gating offers insights that could generalize. We will revise the abstract to more explicitly qualify the claims as holding under the AR(1) assumption and add a paragraph in the discussion section addressing potential extensions to other non-stationary models. revision: partial
Circularity Check
No significant circularity; derivation self-contained under explicit AR(1) model
full rationale
The paper explicitly adopts a first-order autoregressive process to model non-stationarity and derives that GLA achieves lower errors via adaptive modulation of past inputs (learnable recency bias). This characterization is presented as a direct theoretical consequence of the gating equations under the stated assumptions, without any reduction of the central result to fitted parameters by construction, self-definitional loops, or load-bearing self-citations. The recency-bias interpretation follows from the model equations rather than being renamed post-hoc, and no ansatz or uniqueness theorem is smuggled in. The analysis remains independent of its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Non-stationarity of the target function is modeled by a first-order autoregressive process
Reference graph
Works this paper leans on
-
[1]
Tracking performance and optimal adaptation step-sizes of diffusion-lms networks
Reza Abdolee, Vida Vakilian, and Benoit Champagne. Tracking performance and optimal adaptation step-sizes of diffusion-lms networks. IEEE Transactions on Control of Network Systems, 5 0 (1): 0 67--78, 2016
2016
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Transformers learn to implement preconditioned gradient descent for in-context learning
Kwangjun Ahn, Xiang Cheng, Hadi Daneshmand, and Suvrit Sra. Transformers learn to implement preconditioned gradient descent for in-context learning. Advances in Neural Information Processing Systems, 36: 0 45614--45650, 2023
2023
-
[4]
What learning algorithm is in-context learning? investigations with linear models
Ekin Aky \"u rek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? investigations with linear models. arXiv preprint arXiv:2211.15661, 2022
-
[5]
In- Context Language Learning : Architectures and Algorithms , 2024
Ekin Aky \"u rek, Bailin Wang, Yoon Kim, and Jacob Andreas. In-context language learning: Architectures and algorithms. arXiv preprint arXiv:2401.12973, 2024
-
[6]
Transformers as statisticians: Provable in-context learning with in-context algorithm selection
Yu Bai, Fan Chen, Huan Wang, Caiming Xiong, and Song Mei. Transformers as statisticians: Provable in-context learning with in-context algorithm selection. Advances in neural information processing systems, 36: 0 57125--57211, 2023
2023
-
[7]
arXiv preprint arXiv:2405.00200 , year=
Amanda Bertsch, Maor Ivgi, Emily Xiao, Uri Alon, Jonathan Berant, Matthew R Gormley, and Graham Neubig. In-context learning with long-context models: An in-depth exploration. arXiv preprint arXiv:2405.00200, 2024
-
[8]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 0 1877--1901, 2020
1901
-
[9]
Decision transformer: Reinforcement learning via sequence modeling
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information processing systems, 34: 0 15084--15097, 2021
2021
-
[10]
Behavior sequence transformer for e-commerce recommendation in alibaba
Qiwei Chen, Huan Zhao, Wei Li, Pipei Huang, and Wenwu Ou. Behavior sequence transformer for e-commerce recommendation in alibaba. In Proceedings of the 1st international workshop on deep learning practice for high-dimensional sparse data, pp.\ 1--4, 2019
2019
-
[11]
Siyu Chen, Heejune Sheen, Tianhao Wang, and Zhuoran Yang. Training dynamics of multi-head softmax attention for in-context learning: Emergence, convergence, and optimality. arXiv preprint arXiv:2402.19442, 2024
-
[12]
On the tracking performance of adaptive filters and their combinations
Raffaello Claser and Vitor H Nascimento. On the tracking performance of adaptive filters and their combinations. IEEE Transactions on Signal Processing, 69: 0 3104--3116, 2021
2021
-
[13]
On steady state tracking performance of adaptive networks
Bijit Kumar Das, Luis A Azpicueta Ruiz, Mrityunjoy Chakraborty, and Jer \'o nimo Arenas-Garc \' a. On steady state tracking performance of adaptive networks. In 2015 IEEE International Conference on Digital Signal Processing (DSP), pp.\ 843--847. IEEE, 2015
2015
-
[14]
Causallm is not optimal for in-context learning
Nan Ding, Tomer Levinboim, Jialin Wu, Sebastian Goodman, and Radu Soricut. Causallm is not optimal for in-context learning. In The Twelfth International Conference on Learning Representations
-
[15]
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Tianyu Liu, et al. A survey on in-context learning. arXiv preprint arXiv:2301.00234, 2022
work page internal anchor Pith review arXiv 2022
-
[16]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, G Heigold, S Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2020
2020
-
[17]
Transformers learn to achieve second-order convergence rates for in-context linear regression
Deqing Fu, Tian-qi Chen, Robin Jia, and Vatsal Sharan. Transformers learn to achieve second-order convergence rates for in-context linear regression. Advances in Neural Information Processing Systems, 37: 0 98675--98716, 2024
2024
-
[18]
What can transformers learn in-context? a case study of simple function classes
Shivam Garg, Dimitris Tsipras, Percy S Liang, and Gregory Valiant. What can transformers learn in-context? a case study of simple function classes. Advances in Neural Information Processing Systems, 35: 0 30583--30598, 2022
2022
-
[19]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
In-context convergence of transformers.arXiv preprint arXiv:2310.05249,
Yu Huang, Yuan Cheng, and Yingbin Liang. In-context convergence of transformers. arXiv preprint arXiv:2310.05249, 2023
-
[21]
In-context convergence of transformers
Yu Huang, Yuan Cheng, and Yingbin Liang. In-context convergence of transformers. In Proceedings of the 41st International Conference on Machine Learning, pp.\ 19660--19722, 2024
2024
-
[22]
Offline reinforcement learning as one big sequence modeling problem
Michael Janner, Qiyang Li, and Sergey Levine. Offline reinforcement learning as one big sequence modeling problem. Advances in neural information processing systems, 34: 0 1273--1286, 2021
2021
-
[23]
From compression to expansion: A layerwise analysis of in-context learning
Jiachen Jiang, Yuxin Dong, Jinxin Zhou, and Zhihui Zhu. From compression to expansion: A layerwise analysis of in-context learning. arXiv preprint arXiv:2505.17322, 2025 a
-
[24]
In-context learning for non-stationary mimo equalization
Jiachen Jiang, Zhen Qin, and Zhihui Zhu. In-context learning for non-stationary mimo equalization. arXiv preprint arXiv:2510.08711, 2025 b
-
[25]
Gateloop: Fully data-controlled linear recurrence for sequence modeling
Tobias Katsch. Gateloop: Fully data-controlled linear recurrence for sequence modeling. arXiv preprint arXiv:2311.01927, 2023
-
[26]
Transformer-based channel parameter acquisition for terahertz ultra-massive mimo systems
Seungnyun Kim, Anho Lee, Hyungyu Ju, Khoa Anh Ngo, Jihoon Moon, and Byonghyo Shim. Transformer-based channel parameter acquisition for terahertz ultra-massive mimo systems. IEEE Transactions on Vehicular Technology, 72 0 (11): 0 15127--15132, 2023
2023
-
[27]
Long-context llms struggle with long in-context learning.arXiv preprint arXiv:2404.02060, 2024
Tianle Li, Ge Zhang, Quy Duc Do, Xiang Yue, and Wenhu Chen. Long-context llms struggle with long in-context learning. arXiv preprint arXiv:2404.02060, 2024 a
-
[28]
Fine-grained analysis of in-context linear estimation: Data, architecture, and beyond
Yingcong Li, Ankit S Rawat, and Samet Oymak. Fine-grained analysis of in-context linear estimation: Data, architecture, and beyond. Advances in Neural Information Processing Systems, 37: 0 138324--138364, 2024 b
2024
-
[29]
Gating is weighting: Understanding gated linear attention through in-context learning
Yingcong Li, Davoud Ataee Tarzanagh, Ankit Singh Rawat, Maryam Fazel, and Samet Oymak. Gating is weighting: Understanding gated linear attention through in-context learning. arXiv preprint arXiv:2504.04308, 2025
-
[30]
Tomography of quantum states from structured measurements via quantum-aware transformer
Hailan Ma, Zhenhong Sun, Daoyi Dong, Chunlin Chen, and Herschel Rabitz. Tomography of quantum states from structured measurements via quantum-aware transformer. IEEE Transactions on Cybernetics, 2025
2025
-
[31]
Arvind Mahankali, Tatsunori B Hashimoto, and Tengyu Ma. One step of gradient descent is provably the optimal in-context learner with one layer of linear self-attention. arXiv preprint arXiv:2307.03576, 2023
-
[32]
One step of gradient descent is provably the optimal in-context learner with one layer of linear self-attention
Arvind V Mahankali, Tatsunori Hashimoto, and Tengyu Ma. One step of gradient descent is provably the optimal in-context learner with one layer of linear self-attention. In The Twelfth International Conference on Learning Representations
-
[33]
arXiv preprint arXiv:2110.15943 , year=
Sewon Min, Mike Lewis, Luke Zettlemoyer, and Hannaneh Hajishirzi. Metaicl: Learning to learn in context. arXiv preprint arXiv:2110.15943, 2021
-
[34]
Eagle and finch: Rwkv with matrix-valued states and dynamic recurrence
Bo Peng, Daniel Goldstein, Quentin Anthony, Alon Albalak, Eric Alcaide, Stella Biderman, Eugene Cheah, Xingjian Du, Teddy Ferdinan, Haowen Hou, et al. Eagle and finch: Rwkv with matrix-valued states and dynamic recurrence. arXiv preprint arXiv:2404.05892, 2024
-
[35]
A proportionate recursive least squares algorithm and its performance analysis
Zhen Qin, Jun Tao, and Yili Xia. A proportionate recursive least squares algorithm and its performance analysis. IEEE Transactions on Circuits and Systems II: Express Briefs, 68 0 (1): 0 506--510, 2020
2020
-
[36]
On the Convergence of Gradient Descent on Learning Transformers with Residual Connections
Zhen Qin, Jinxin Zhou, and Zhihui Zhu. On the convergence of gradient descent on learning transformers with residual connections. arXiv preprint arXiv:2506.05249, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1 0 (8): 0 9, 2019
2019
-
[38]
Adaptive filters
Ali H Sayed. Adaptive filters. John Wiley & Sons, 2011
2011
-
[39]
Recursive deep models for semantic compositionality over a sentiment treebank
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pp.\ 1631--1642, 2013
2013
-
[40]
Unraveling the gradient descent dynamics of transformers
Bingqing Song, Boran Han, Shuai Zhang, Jie Ding, and Mingyi Hong. Unraveling the gradient descent dynamics of transformers. Advances in Neural Information Processing Systems, 37: 0 92317--92351, 2024
2024
-
[41]
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models. arXiv preprint arXiv:2307.08621, 2023
work page internal anchor Pith review arXiv 2023
-
[42]
Multimodal transformer for unaligned multimodal language sequences
Yao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov. Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the conference. Association for computational linguistics. Meeting, volume 2019, pp.\ 6558, 2019
2019
-
[43]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
2017
-
[44]
Transformers learn in-context by gradient descent
Johannes Von Oswald, Eyvind Niklasson, Ettore Randazzo, Jo \ a o Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. In International Conference on Machine Learning, pp.\ 35151--35174. PMLR, 2023
2023
-
[45]
Performance analysis of prls-based time-varying sparse system identification
Yu Wang, Zhen Qin, Jun Tao, and Le Yang. Performance analysis of prls-based time-varying sparse system identification. In 2022 IEEE 12th Sensor Array and Multichannel Signal Processing Workshop (SAM), pp.\ 251--255. IEEE, 2022
2022
-
[46]
The learnability of in-context learning
Noam Wies, Yoav Levine, and Amnon Shashua. The learnability of in-context learning. Advances in Neural Information Processing Systems, 36: 0 36637--36651, 2023
2023
-
[47]
A broad-coverage challenge corpus for sentence understanding through inference
Adina Williams, Nikita Nangia, and Samuel Bowman. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long papers), pp.\ 1112--1122, 2018
2018
-
[48]
On the convergence of encoder-only shallow transformers
Yongtao Wu, Fanghui Liu, Grigorios Chrysos, and Volkan Cevher. On the convergence of encoder-only shallow transformers. Advances in Neural Information Processing Systems, 36: 0 52197--52237, 2023
2023
-
[49]
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware-efficient training. arXiv preprint arXiv:2312.06635, 2023
work page internal anchor Pith review arXiv 2023
-
[50]
In-context learning with representations: Contextual generalization of trained transformers
Tong Yang, Yu Huang, Yingbin Liang, and Yuejie Chi. In-context learning with representations: Contextual generalization of trained transformers. arXiv preprint arXiv:2408.10147, 2024
-
[51]
Tracking analyses of m-estimate based lms and nlms algorithms
Yi Yu, Rodrigo C de Lamare, Tao Yang, and Qiangming Cai. Tracking analyses of m-estimate based lms and nlms algorithms. In 2021 IEEE Statistical Signal Processing Workshop (SSP), pp.\ 1--5. IEEE, 2021
2021
-
[52]
Trained transformers learn linear models in-context
Ruiqi Zhang, Spencer Frei, and Peter L Bartlett. Trained transformers learn linear models in-context. Journal of Machine Learning Research, 25 0 (49): 0 1--55, 2024
2024
-
[53]
Inference of time-varying regression models
Ting Zhang and Wei Biao Wu. Inference of time-varying regression models. 2012
2012
-
[54]
Time-varying nonlinear regression models: nonparametric estimation and model selection
Ting Zhang and Wei Biao Wu. Time-varying nonlinear regression models: nonparametric estimation and model selection. 2015
2015
-
[55]
Training dynamics of in-context learning in linear attention
Yedi Zhang, Aaditya K Singh, Peter E Latham, and Andrew Saxe. Training dynamics of in-context learning in linear attention. arXiv preprint arXiv:2501.16265, 2025
-
[56]
What makes good examples for visual in-context learning? Advances in Neural Information Processing Systems, 36: 0 17773--17794, 2023
Yuanhan Zhang, Kaiyang Zhou, and Ziwei Liu. What makes good examples for visual in-context learning? Advances in Neural Information Processing Systems, 36: 0 17773--17794, 2023
2023
-
[57]
Deep interest network for click-through rate prediction
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pp.\ 1059--1068, 2018
2018
-
[58]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[59]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[60]
/;+K9| ӎUD X +Z/77 I 4Q
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.