Recognition: unknown
Multi-Faceted Continual Knowledge Graph Embedding for Semantic-Aware Link Prediction
Pith reviewed 2026-05-10 16:30 UTC · model grok-4.3
The pith
Separating old and new knowledge of each entity into distinct embedding spaces improves lifelong link prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MF-CKGE separates temporal old and new knowledge into distinct embedding spaces to prevent knowledge entanglement, employs semantic decoupling to reduce redundancy, and during online inference adaptively identifies semantically query-relevant entity embeddings by quantifying their semantic importance, thereby improving space efficiency and reducing interference from query-irrelevant noise in continual link prediction.
What carries the argument
The MF-CKGE framework that maintains distinct temporal embedding spaces for entities and performs adaptive semantic selection of facets at inference time.
If this is right
- Old and new knowledge of entities remain distinguishable rather than entangled in one vector.
- Semantic redundancy is reduced through decoupling, freeing up embedding capacity.
- Inference focuses only on query-relevant facets, cutting noise from irrelevant temporal aspects.
- Ranking metrics for link prediction rise consistently across successive graph snapshots.
Where Pith is reading between the lines
- The separation technique could extend to other continual learning tasks where single objects play multiple shifting roles over time.
- Single-vector entity representations may be fundamentally limited in any dynamic graph where context alters meaning.
- Automatic determination of the number of facets per entity could be explored as a follow-on direction.
Load-bearing premise
Entities inherently exhibit multi-faceted semantics that evolve dynamically as their relational contexts change over time, and a shared embedding fails to capture these variations.
What would settle it
A controlled experiment on the same eight datasets in which single shared embeddings achieve equal or higher MRR and Hits@10 than the multi-space version after matching total parameter counts would falsify the central claim.
Figures






read the original abstract
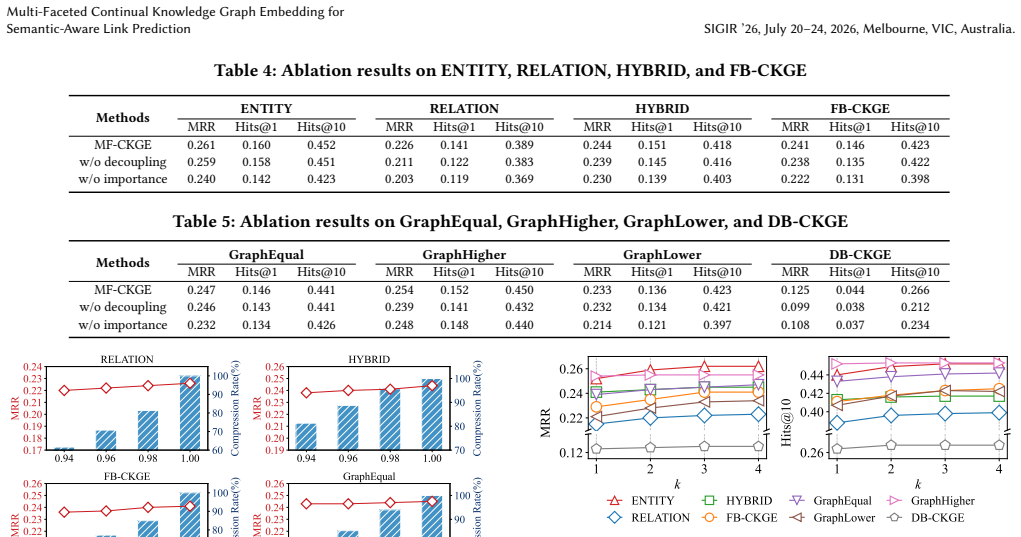
Continual Knowledge Graph Embedding (CKGE) aims to continually learn embeddings for new knowledge, i.e., entities and relations, while retaining previously acquired knowledge. Most existing CKGE methods mitigate catastrophic forgetting via regularization or replaying old knowledge. They conflate new and old knowledge of an entity within the same embedding space to seek a balance between them. However, entities inherently exhibit multi-faceted semantics that evolve dynamically as their relational contexts change over time. A shared embedding fails to capture and distinguish these temporal semantic variations, degrading lifelong link prediction accuracy across snapshots. To address this, we propose a Multi-Faceted CKGE framework (MF-CKGE) for semantic-aware link prediction. During offline learning, MF-CKGE separates temporal old and new knowledge into distinct embedding spaces to prevent knowledge entanglement and employs semantic decoupling to reduce semantic redundancy, thereby improving space efficiency. During online inference, MF-CKGE adaptively identifies semantically query-relevant entity embeddings by quantifying their semantic importance, reducing interference from query-irrelevant noise. Experiments on eight datasets show that MF-CKGE achieves an average (maximum) improvement of 1.7% (2.7%) and 1.4% (3.8%) in MRR and Hits@10, respectively, over the best baseline. Our source code and datasets are available at: https://anonymous.4open.science/r/MF-CKGE-04E5.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MF-CKGE, a continual knowledge graph embedding framework that separates old and new temporal knowledge into distinct embedding spaces during offline training to avoid entanglement, applies semantic decoupling to reduce redundancy and improve efficiency, and uses an adaptive semantic importance quantifier during online inference to select query-relevant entity embeddings. Experiments across eight datasets report average (maximum) gains of 1.7% (2.7%) in MRR and 1.4% (3.8%) in Hits@10 over the strongest baseline for semantic-aware link prediction.
Significance. If the empirical gains hold under rigorous verification, the work offers a targeted architectural response to the multi-faceted, time-varying semantics of entities in lifelong KG settings, an issue that shared-embedding CKGE methods have not explicitly addressed. The open release of code and datasets is a clear positive for reproducibility.
major comments (1)
- [Experimental Evaluation] Experimental Evaluation section: The central claim of consistent improvements rests on the reported MRR and Hits@10 gains, yet no statistical significance tests, standard deviations across runs, details on baseline re-implementations, or hyperparameter search protocols are provided. Without these, it is impossible to determine whether the 1.7% average MRR lift is robust or attributable to implementation choices or variance.
Simulated Author's Rebuttal
Thank you for your constructive feedback on our manuscript. We appreciate the emphasis on strengthening the experimental evaluation to better support the reported performance gains. We address the major comment point-by-point below and commit to revisions that enhance the rigor and transparency of our results.
read point-by-point responses
-
Referee: Experimental Evaluation section: The central claim of consistent improvements rests on the reported MRR and Hits@10 gains, yet no statistical significance tests, standard deviations across runs, details on baseline re-implementations, or hyperparameter search protocols are provided. Without these, it is impossible to determine whether the 1.7% average MRR lift is robust or attributable to implementation choices or variance.
Authors: We agree that the current presentation of results would be strengthened by greater statistical rigor and implementation transparency. In the revised manuscript, we will augment the Experimental Evaluation section as follows: (1) conduct all experiments over multiple random seeds (at least 5 runs per setting) and report both mean MRR/Hits@10 values and their standard deviations across the eight datasets; (2) include statistical significance testing (paired t-tests with p-values) between MF-CKGE and the strongest baseline on each dataset to verify that the observed average gains of 1.7% MRR and 1.4% Hits@10 are unlikely to arise from variance alone; (3) provide explicit details on baseline re-implementations, including any adaptations required for the continual KG setting, the exact hyperparameter values used, and the source of original implementations where applicable; and (4) describe the full hyperparameter search protocol, encompassing the explored ranges, search strategy (e.g., grid or Bayesian optimization), validation procedure, and final selected values for MF-CKGE and all baselines. These additions will be supported by updated tables and, where space permits, an expanded appendix. We believe this directly resolves the concern while preserving the manuscript's core claims and contributions. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes MF-CKGE by introducing distinct embedding spaces to separate temporal knowledge, semantic decoupling to reduce redundancy, and adaptive query-relevant selection at inference time. These are motivated directly by the stated assumption that entities have evolving multi-faceted semantics not capturable by a single shared embedding. No load-bearing equation, loss term, or performance claim reduces by construction to a fitted parameter renamed as a prediction, nor to a self-citation chain or uniqueness theorem imported from the authors' prior work. The reported MRR/Hits@10 gains are presented as empirical results on eight datasets rather than derived tautologically from the inputs. The central architecture therefore remains independent and self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- per-space embedding dimension
- decoupling and importance scoring weights
axioms (2)
- standard math Knowledge graphs can be represented via vector embeddings of entities and relations.
- domain assumption Entities exhibit multi-faceted semantics that evolve with changing relational contexts.
invented entities (2)
-
Distinct temporal embedding spaces
no independent evidence
-
Semantic importance quantifier
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Project Code and Datasets
2026. Project Code and Datasets. https://anonymous.4open.science/r/MF-CKGE- 04E5. Accessed: 2026-09-20
2026
-
[2]
Tu Ao, Yanhua Yu, Yuling Wang, Yang Deng, Zirui Guo, Liang Pang, Pinghui Wang, Tat-Seng Chua, Xiao Zhang, and Zhen Cai. 2025. Lightprof: A light- weight reasoning framework for large language model on knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 23424–23432
2025
-
[3]
Sören Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyganiak, and Zachary Ives. 2007. Dbpedia: A nucleus for a web of open data. InThe semantic web. Springer, 722–735
2007
-
[4]
Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Ok- sana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data.Advances in neural information processing systems26 (2013)
2013
-
[5]
Antoine Bordes, Jason Weston, and Nicolas Usunier. 2014. Open question an- swering with weakly supervised embedding models. InMachine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2014, Nancy, France, September 15-19, 2014. Proceedings, Part I 14. Springer, 165–180
2014
- [6]
-
[7]
Yuanning Cui, Yuxin Wang, Zequn Sun, Wenqiang Liu, Yiqiao Jiang, Kexin Han, and Wei Hu. 2023. Lifelong embedding learning and transfer for growing knowl- edge graphs. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 4217–4224
2023
-
[8]
Angel Daruna, Mehul Gupta, Mohan Sridharan, and Sonia Chernova. 2021. Con- tinual learning of knowledge graph embeddings.IEEE Robotics and Automation Letters6, 2 (2021), 1128–1135
2021
-
[9]
Xin Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Mur- phy, Thomas Strohmann, Shaohua Sun, and Wei Zhang. 2014. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. InProceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. 601–610
2014
-
[10]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130(2024)
work page internal anchor Pith review arXiv 2024
-
[11]
Xingyue Huang, Miguel Romero, Ismail Ceylan, and Pablo Barceló. 2023. A theory of link prediction via relational weisfeiler-leman on knowledge graphs. Advances in Neural Information Processing Systems36 (2023), 19714–19748
2023
-
[12]
Yantao Jia, Yuanzhuo Wang, Xiaolong Jin, Hailun Lin, and Xueqi Cheng. 2017. Knowledge graph embedding: A locally and temporally adaptive translation- based approach.ACM Transactions on the Web (TWEB)12, 2 (2017), 1–33
2017
-
[13]
Bernal Jimenez Gutierrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su
-
[14]
Hipporag: Neurobiologically inspired long-term memory for large language models.Advances in Neural Information Processing Systems37 (2024), 59532– 59569
2024
-
[15]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. 2017. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences114, 13 (2017), 3521– 3526
2017
- [16]
- [17]
-
[18]
Jiajun Liu, Wenjun Ke, Peng Wang, Ziyu Shang, Jinhua Gao, Guozheng Li, Ke Ji, and Yanhe Liu. 2024. Towards continual knowledge graph embedding via incre- mental distillation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 8759–8768
2024
- [19]
-
[20]
Vincenzo Lomonaco and Davide Maltoni. 2017. Core50: a new dataset and benchmark for continuous object recognition. InConference on robot learning. PMLR, 17–26
2017
-
[21]
David Lopez-Paz and Marc’Aurelio Ranzato. 2017. Gradient episodic memory for continual learning.Advances in neural information processing systems30 (2017)
2017
- [22]
-
[23]
Farimah Poursafaei, Shenyang Huang, Kellin Pelrine, and Reihaneh Rabbany
-
[24]
Towards better evaluation for dynamic link prediction.Advances in Neural Information Processing Systems35 (2022), 32928–32941
2022
-
[25]
Sabbir M. Rashid and Deborah L. Mcguinness. 2025. Designing and Evaluat- ing an Ensemble Reasoning-based Clinical Decision Support System.DATA INTELLIGENCE7, 1 (2025). doi:10.3724/2096-7004.di.2025.0001
-
[26]
Andrea Rossi, Denilson Barbosa, Donatella Firmani, Antonio Matinata, and Paolo Merialdo. 2021. Knowledge graph embedding for link prediction: A comparative analysis.ACM Transactions on Knowledge Discovery from Data (TKDD)15, 2 (2021), 1–49
2021
-
[27]
Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. 2016. Pro- gressive neural networks.arXiv preprint arXiv:1606.04671(2016)
work page internal anchor Pith review arXiv 2016
-
[28]
Stathopoulos, Alexandros Vassiliades, Sotiris Diplaris, Stefanos Vrochidis, and Ioannis Kompatsiaris
Evangelos A. Stathopoulos, Alexandros Vassiliades, Sotiris Diplaris, Stefanos Vrochidis, and Ioannis Kompatsiaris. 2024. Applied logic and semantics on indoor and urban adaptive design through knowledge graphs, reasoning and explainable argumentation.The Knowledge Engineering Review39 (2024), e4. doi:10.1017/S0269888924000043
- [29]
-
[30]
Gu Tang, Xiaoying Gan, Jinghe Wang, Bin Lu, Lyuwen Wu, Luoyi Fu, and Chenghu Zhou. 2024. Editkg: Editing knowledge graph for recommendation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 112–122
2024
-
[31]
Yi Tay, Anh Luu, and Siu Cheung Hui. 2017. Non-parametric estimation of multi- ple embeddings for link prediction on dynamic knowledge graphs. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 31
2017
-
[32]
Théo Trouillon, Johannes Welbl, Sebastian Riedel, Éric Gaussier, and Guillaume Bouchard. 2016. Complex embeddings for simple link prediction. InInternational conference on machine learning. PMLR, 2071–2080
2016
- [33]
-
[34]
Yuxiang Wang, Arijit Khan, Tianxing Wu, Jiahui Jin, and Haijiang Yan. 2020. Semantic Guided and Response Times Bounded Top-k Similarity Search over Knowledge Graphs. In2020 IEEE 36th International Conference on Data Engineering (ICDE). 445–456. doi:10.1109/ICDE48307.2020.00045
-
[35]
Yuxiang Wang, Arijit Khan, Xiaoliang Xu, Jiahui Jin, Qifan Hong, and Tao Fu. 2022. Aggregate Queries on Knowledge Graphs: Fast Approximation with Semantic- aware Sampling. In2022 IEEE 38th International Conference on Data Engineering (ICDE). 2914–2927. doi:10.1109/ICDE53745.2022.00263
-
[36]
Zhen Wang, Jianwen Zhang, Jianlin Feng, and Zheng Chen. 2014. Knowledge graph embedding by translating on hyperplanes. InProceedings of the AAAI conference on artificial intelligence, Vol. 28
2014
-
[37]
Tianxing Wu, Arijit Khan, Melvin Yong, Guilin Qi, and Meng Wang. 2022. Effi- ciently embedding dynamic knowledge graphs.Knowledge-based systems250 (2022), 109124
2022
-
[38]
Jian Xu, Sichun Luo, Xiangyu Chen, Haoming Huang, Hanxu Hou, and Linqi Song. 2025. RALLRec: Improving Retrieval Augmented Large Language Model Recommendation with Representation Learning. InCompanion Proceedings of the ACM on Web Conference 2025. 1436–1440
2025
-
[39]
Friedemann Zenke, Ben Poole, and Surya Ganguli. 2017. Continual learning through synaptic intelligence. InInternational conference on machine learning. PMLR, 3987–3995
2017
-
[40]
Fuzheng Zhang, Nicholas Jing Yuan, Defu Lian, Xing Xie, and Wei-Ying Ma
-
[41]
In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining
Collaborative knowledge base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 353–362
-
[42]
Muhan Zhang and Yixin Chen. 2018. Link prediction based on graph neural networks.Advances in neural information processing systems31 (2018)
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.