Recognition: unknown
Bootstrapping Video Semantic Segmentation Model via Distillation-assisted Test-Time Adaptation
Pith reviewed 2026-05-10 16:16 UTC · model grok-4.3
The pith
A pre-trained image segmentation model becomes a video segmentation model by distilling SAM2's temporal knowledge in a single annotation-free test-time adaptation pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DiTTA distills SAM2's temporal segmentation knowledge into a pre-trained image semantic segmentation model during a brief single-pass initialization phase on unlabeled video, then augments the model with a lightweight temporal fusion module to aggregate cross-frame context, enabling robust video semantic segmentation that generalizes well even from partial video inputs.
What carries the argument
The DiTTA framework, which performs distillation-assisted test-time adaptation to transfer temporal knowledge from SAM2 to an image model in one pass, combined with a temporal fusion module for cross-frame aggregation.
Load-bearing premise
That SAM2's temporal segmentation knowledge transfers reliably to any pre-trained image segmentation model via a single annotation-free adaptation pass and produces robust generalization across different videos and limited inputs.
What would settle it
Running the adapted model on a held-out set of video frames and finding its accuracy drops below that of the original frame-by-frame image model, or below zero-shot SAM2 refinement methods.
Figures

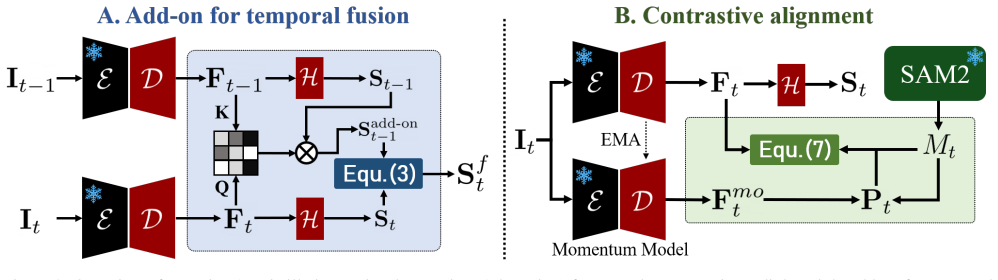


read the original abstract
Fully supervised Video Semantic Segmentation (VSS) relies heavily on densely annotated video data, limiting practical applicability. Alternatively, applying pre-trained Image Semantic Segmentation (ISS) models frame-by-frame avoids annotation costs but ignores crucial temporal coherence. Recent foundation models such as SAM2 enable high-quality mask propagation yet remain impractical for direct VSS due to limited semantic understanding and computational overhead. In this paper, we propose DiTTA (Distillation-assisted Test-Time Adaptation), a novel framework that converts an ISS model into a temporally-aware VSS model through efficient test-time adaptation (TTA), without annotated videos. DiTTA distills SAM2's temporal segmentation knowledge into the ISS model during a brief, single-pass initialization phase, complemented by a lightweight temporal fusion module to aggregate cross-frame context. Crucially, DiTTA achieves robust generalization even when adapting with highly limited partial video snippets (e.g., initial 10%), significantly outperforming zero-shot refinement approaches that repeatedly invoke SAM2 during inference. Extensive experiments on VSPW and Cityscapes demonstrate DiTTA's effectiveness, achieving competitive or superior performance relative to fully-supervised VSS methods, thus providing a practical and annotation-free solution for real-world VSS tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiTTA, a framework that converts a pre-trained image semantic segmentation (ISS) model into a video semantic segmentation (VSS) model via distillation-assisted test-time adaptation (TTA) from SAM2 on unlabeled partial video snippets (e.g., initial 10%), augmented by a lightweight temporal fusion module for cross-frame context aggregation. It claims robust generalization to full videos and other domains, outperforming zero-shot SAM2 refinement approaches, and achieving competitive or superior results to fully-supervised VSS methods on VSPW and Cityscapes without requiring annotations.
Significance. If the performance and generalization claims hold, the work offers a practical annotation-free pathway to temporally coherent VSS by leveraging foundation models like SAM2 for efficient single-pass distillation, which could reduce reliance on dense video labeling in applications such as autonomous driving. The partial-snippet adaptation highlights computational efficiency gains over repeated inference-time SAM2 calls.
major comments (3)
- [§3.2] §3.2 (TTA initialization procedure): the single-pass adaptation on the initial 10% snippet lacks any described regularization, temporal consistency loss over the full sequence, or anti-overfitting term; without such a mechanism the claimed robust transfer of temporal coherence to remaining frames risks fitting transient snippet-specific statistics (lighting, camera motion) rather than generalizable semantics.
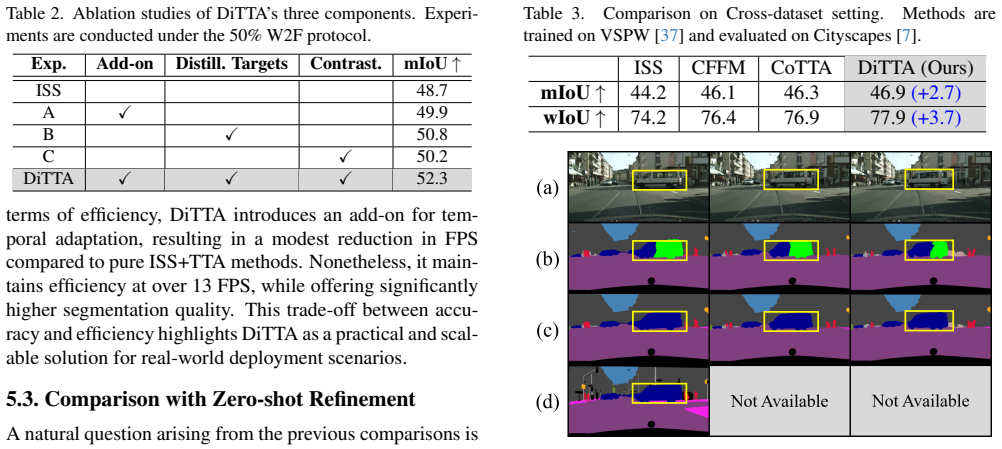
- [§4.2] §4.2 and Table 2 (quantitative comparisons): the reported competitive/superior mIoU versus fully-supervised VSS baselines requires explicit confirmation that those baselines use identical backbones and comparable training regimes; otherwise the interpretation of annotation-free gains is undermined.
- [§4.3] §4.3 (ablations): the contribution of the temporal fusion module versus pure SAM2 distillation must be isolated under the 10%-snippet regime, including controls for overfitting, to substantiate that the observed gains stem from the proposed components rather than dataset-specific artifacts.
minor comments (2)
- [§2] §2 (related work): a brief discussion of recent video-specific TTA techniques would strengthen the positioning of the distillation-assisted approach.
- [Figure 5] Figure 5 (qualitative results): adding error analysis or challenging cases (e.g., fast motion, occlusions) would provide a more balanced assessment of limitations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and outline revisions to strengthen the manuscript while preserving its core contributions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (TTA initialization procedure): the single-pass adaptation on the initial 10% snippet lacks any described regularization, temporal consistency loss over the full sequence, or anti-overfitting term; without such a mechanism the claimed robust transfer of temporal coherence to remaining frames risks fitting transient snippet-specific statistics (lighting, camera motion) rather than generalizable semantics.
Authors: We agree that the current description of the TTA procedure does not include explicit regularization or a temporal consistency loss over the full sequence. The single-pass adaptation relies on the pre-trained ISS model's generalization combined with SAM2 distillation and the lightweight fusion module to promote coherence. However, to mitigate concerns about snippet-specific overfitting, we will revise §3.2 to include a brief discussion of this risk and add a new ablation (in §4.3) that incorporates a simple temporal consistency regularizer during the 10% initialization phase. This will demonstrate that performance remains stable without such terms but improves modestly with them, supporting the robustness claim. revision: partial
-
Referee: [§4.2] §4.2 and Table 2 (quantitative comparisons): the reported competitive/superior mIoU versus fully-supervised VSS baselines requires explicit confirmation that those baselines use identical backbones and comparable training regimes; otherwise the interpretation of annotation-free gains is undermined.
Authors: We appreciate this clarification request. The baselines in Table 2 follow the standard configurations reported in their original papers (e.g., ResNet-101 or Swin Transformer backbones with their respective training schedules on VSPW and Cityscapes). To eliminate ambiguity, we will revise the caption of Table 2 and the surrounding text in §4.2 to explicitly list the backbone and training regime for each baseline, confirming they match common fully-supervised setups. This will make the annotation-free performance gains more directly interpretable. revision: yes
-
Referee: [§4.3] §4.3 (ablations): the contribution of the temporal fusion module versus pure SAM2 distillation must be isolated under the 10%-snippet regime, including controls for overfitting, to substantiate that the observed gains stem from the proposed components rather than dataset-specific artifacts.
Authors: We concur that further isolation is valuable. The existing ablations compare variants but do not explicitly break down fusion versus distillation solely under the 10% snippet setting with overfitting controls. We will expand §4.3 with a dedicated table showing: (i) pure distillation (no fusion) on 10% snippets, (ii) full DiTTA with fusion, and (iii) a control varying snippet length (5%, 10%, 20%) to check for overfitting. These additions will confirm that the temporal fusion module provides the primary gains beyond distillation alone. revision: yes
Circularity Check
No circularity: empirical pipeline relies on external SAM2 distillation and standard TTA
full rationale
The paper describes an empirical method (DiTTA) that distills temporal knowledge from the external SAM2 foundation model into a pre-trained image segmentation model via single-pass test-time adaptation on partial video snippets, augmented by a lightweight temporal fusion module. No equations, derivations, or parameter-fitting steps appear in the provided abstract or summary; the approach does not define any quantity in terms of itself, rename fitted inputs as predictions, or rely on self-citation chains for load-bearing uniqueness claims. Results are validated through experiments on VSPW and Cityscapes against fully-supervised baselines, confirming the derivation chain is self-contained and externally grounded.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhaochong An, Guolei Sun, Zongwei Wu, Hao Tang, and Luc Van Gool. Temporal-aware hierarchical mask classi- fication for video semantic segmentation.arXiv preprint arXiv:2309.08020, 2023. 8
-
[2]
Contrastive test-time adaptation
Dian Chen, Dequan Wang, Trevor Darrell, and Sayna Ebrahimi. Contrastive test-time adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 295–305, 2022. 3, 4
2022
-
[3]
Per- pixel classification is not all you need for semantic segmen- tation.Advances in neural information processing systems, 34:17864–17875, 2021
Bowen Cheng, Alex Schwing, and Alexander Kirillov. Per- pixel classification is not all you need for semantic segmen- tation.Advances in neural information processing systems, 34:17864–17875, 2021. 1
2021
-
[4]
Masked-attention mask transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexan- der Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1290–1299, 2022. 2
2022
-
[5]
Finding meaning in points: Weakly super- vised semantic segmentation for event cameras
Hoonhee Cho, Sung-Hoon Yoon, Hyeokjun Kweon, and Kuk-Jin Yoon. Finding meaning in points: Weakly super- vised semantic segmentation for event cameras. InEuropean Conference on Computer Vision, pages 266–286. Springer,
-
[6]
To adapt or not to adapt? real- time adaptation for semantic segmentation
Marc Botet Colomer, Pier Luigi Dovesi, Theodoros Pana- giotakopoulos, Joao Frederico Carvalho, Linus H ¨arenstam- Nielsen, Hossein Azizpour, Hedvig Kjellstr ¨om, Daniel Cre- mers, and Matteo Poggi. To adapt or not to adapt? real- time adaptation for semantic segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 1...
2023
-
[7]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016. 5, 7
2016
-
[8]
Every frame counts: Joint learning of video segmentation and optical flow
Mingyu Ding, Zhe Wang, Bolei Zhou, Jianping Shi, Zhiwu Lu, and Ping Luo. Every frame counts: Joint learning of video segmentation and optical flow. InProceedings of the AAAI conference on artificial intelligence, pages 10713– 10720, 2020. 2
2020
-
[9]
Flownet: Learning optical flow with convolutional networks
Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Hausser, Caner Hazirbas, Vladimir Golkov, Patrick Van Der Smagt, Daniel Cremers, and Thomas Brox. Flownet: Learning optical flow with convolutional networks. InPro- ceedings of the IEEE international conference on computer vision, pages 2758–2766, 2015. 2
2015
-
[10]
Uncertainty reduction for model adaptation in semantic segmentation
Francois Fleuret et al. Uncertainty reduction for model adaptation in semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9613–9623, 2021. 3
2021
-
[11]
Se- mantic video cnns through representation warping
Raghudeep Gadde, Varun Jampani, and Peter V Gehler. Se- mantic video cnns through representation warping. InPro- ceedings of the IEEE International Conference on Computer Vision, pages 4453–4462, 2017. 2, 5
2017
-
[12]
Video segmentation with superpixels
Fabio Galasso, Roberto Cipolla, and Bernt Schiele. Video segmentation with superpixels. InComputer Vision–ACCV 2012: 11th Asian Conference on Computer Vision, Daejeon, Korea, November 5-9, 2012, Revised Selected Papers, Part I 11, pages 760–774. Springer, 2013. 2
2012
-
[13]
Superpixel-based video ob- ject segmentation using perceptual organization and location prior
Daniela Giordano, Francesca Murabito, Simone Palazzo, and Concetto Spampinato. Superpixel-based video ob- ject segmentation using perceptual organization and location prior. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4814–4822, 2015. 2
2015
-
[14]
Vanishing-point-guided video semantic segmentation of driving scenes
Diandian Guo, Deng-Ping Fan, Tongyu Lu, Christos Sakaridis, and Luc Van Gool. Vanishing-point-guided video semantic segmentation of driving scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3544–3553, 2024. 2
2024
-
[15]
Exploiting temporal state space sharing for video se- mantic segmentation
Syed Ariff Syed Hesham, Yun Liu, Guolei Sun, Henghui Ding, Jing Yang, Ender Konukoglu, Xue Geng, and Xudong Jiang. Exploiting temporal state space sharing for video se- mantic segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24211–24221,
-
[16]
Temporally distributed networks for fast video semantic segmentation
Ping Hu, Fabian Caba, Oliver Wang, Zhe Lin, Stan Sclaroff, and Federico Perazzi. Temporally distributed networks for fast video semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8818–8827, 2020. 2
2020
-
[17]
Min- vis: A minimal video instance segmentation framework without video-based training.Advances in Neural Informa- tion Processing Systems, 35:31265–31277, 2022
De-An Huang, Zhiding Yu, and Anima Anandkumar. Min- vis: A minimal video instance segmentation framework without video-based training.Advances in Neural Informa- tion Processing Systems, 35:31265–31277, 2022. 2
2022
-
[18]
Efficient uncertainty estimation for se- mantic segmentation in videos
Po-Yu Huang, Wan-Ting Hsu, Chun-Yueh Chiu, Ting-Fan Wu, and Min Sun. Efficient uncertainty estimation for se- mantic segmentation in videos. InProceedings of the Euro- pean Conference on Computer Vision (ECCV), pages 520– 535, 2018. 2
2018
-
[19]
Accel: A corrective fusion network for efficient semantic segmenta- tion on video
Samvit Jain, Xin Wang, and Joseph E Gonzalez. Accel: A corrective fusion network for efficient semantic segmenta- tion on video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8866– 8875, 2019. 2
2019
-
[20]
Talos: Enhancing semantic scene completion via test-time adaptation on the line of sight.Advances in Neural Information Processing Systems, 37:74211–74232, 2024
Hyun-Kurl Jang, Jihun Kim, Hyeokjun Kweon, and Kuk- Jin Yoon. Talos: Enhancing semantic scene completion via test-time adaptation on the line of sight.Advances in Neural Information Processing Systems, 37:74211–74232, 2024. 3
2024
-
[21]
Video scene parsing with predictive feature learn- ing
Xiaojie Jin, Xin Li, Huaxin Xiao, Xiaohui Shen, Zhe Lin, Jimei Yang, Yunpeng Chen, Jian Dong, Luoqi Liu, Zequn Jie, et al. Video scene parsing with predictive feature learn- ing. InProceedings of the IEEE International Conference on Computer Vision, pages 5580–5588, 2017. 2
2017
-
[22]
Improved image boundaries for better video segmentation
Anna Khoreva, Rodrigo Benenson, Fabio Galasso, Matthias Hein, and Bernt Schiele. Improved image boundaries for better video segmentation. InComputer Vision–ECCV 2016 Workshops: Amsterdam, The Netherlands, October 8-10 and 15-16, 2016, Proceedings, Part III 14, pages 773–788. Springer, 2016. 2
2016
-
[23]
Dc-tta: Divide-and-conquer framework for test-time adaptation of interactive segmenta- tion
Jihun Kim, Hoyong Kwon, Hyeokjun Kweon, Wooseong Jeong, and Kuk-Jin Yoon. Dc-tta: Divide-and-conquer framework for test-time adaptation of interactive segmenta- tion. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 23279–23289, 2025. 3
2025
-
[24]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 4015–4026, 2023. 2
2023
-
[25]
From sam to cams: Ex- ploring segment anything model for weakly supervised se- mantic segmentation
Hyeokjun Kweon and Kuk-Jin Yoon. From sam to cams: Ex- ploring segment anything model for weakly supervised se- mantic segmentation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 19499–19509, 2024. 2
2024
-
[26]
Wish: Weakly super- vised instance segmentation using heterogeneous labels
Hyeokjun Kweon and Kuk-Jin Yoon. Wish: Weakly super- vised instance segmentation using heterogeneous labels. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 25377–25387, 2025. 2
2025
-
[27]
Unlocking the potential of ordinary classifier: Class-specific adversarial erasing frame- work for weakly supervised semantic segmentation
Hyeokjun Kweon, Sung-Hoon Yoon, Hyeonseong Kim, Daehee Park, and Kuk-Jin Yoon. Unlocking the potential of ordinary classifier: Class-specific adversarial erasing frame- work for weakly supervised semantic segmentation. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 6994–7003, 2021. 1
2021
-
[28]
Weakly supervised semantic segmentation via adversarial learning of classifier and reconstructor
Hyeokjun Kweon, Sung-Hoon Yoon, and Kuk-Jin Yoon. Weakly supervised semantic segmentation via adversarial learning of classifier and reconstructor. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11329–11339, 2023
2023
-
[29]
Phase concentration and shortcut suppression for weakly supervised semantic segmentation
Hoyong Kwon, Jaeseok Jeong, Sung-Hoon Yoon, and Kuk- Jin Yoon. Phase concentration and shortcut suppression for weakly supervised semantic segmentation. InEuropean Conference on Computer Vision, pages 293–312. Springer,
-
[30]
Gsvnet: Guided spatially-varying convolution for fast semantic seg- mentation on video
Shih-Po Lee, Si-Cun Chen, and Wen-Hsiao Peng. Gsvnet: Guided spatially-varying convolution for fast semantic seg- mentation on video. In2021 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2021. 2
2021
-
[31]
Video semantic segmentation via sparse temporal transformer
Jiangtong Li, Wentao Wang, Junjie Chen, Li Niu, Jianlou Si, Chen Qian, and Liqing Zhang. Video semantic segmentation via sparse temporal transformer. InProceedings of the 29th ACM International Conference on Multimedia, pages 59–68,
-
[32]
Low-latency video se- mantic segmentation
Yule Li, Jianping Shi, and Dahua Lin. Low-latency video se- mantic segmentation. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 5997– 6005, 2018. 2
2018
-
[33]
Do we really need to access the source data? source hypothesis transfer for un- supervised domain adaptation
Jian Liang, Dapeng Hu, and Jiashi Feng. Do we really need to access the source data? source hypothesis transfer for un- supervised domain adaptation. InInternational conference on machine learning, pages 6028–6039. PMLR, 2020. 3
2020
-
[34]
Lsvos challenge 3rd place report: Sam2 and cutie based vos.arXiv preprint arXiv:2408.10469, 2024
Xinyu Liu, Jing Zhang, Kexin Zhang, Xu Liu, and Lingling Li. Lsvos challenge 3rd place report: Sam2 and cutie based vos.arXiv preprint arXiv:2408.10469, 2024. 2
-
[35]
Efficient semantic video segmentation with per-frame inference
Yifan Liu, Chunhua Shen, Changqian Yu, and Jingdong Wang. Efficient semantic video segmentation with per-frame inference. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceed- ings, Part X 16, pages 352–368. Springer, 2020. 2
2020
-
[36]
Spatio-temporal pixel- level contrastive learning-based source-free domain adapta- tion for video semantic segmentation
Shao-Yuan Lo, Poojan Oza, Sumanth Chennupati, Alejan- dro Galindo, and Vishal M Patel. Spatio-temporal pixel- level contrastive learning-based source-free domain adapta- tion for video semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10534–10543, 2023. 2
2023
-
[37]
Vspw: A large-scale dataset for video scene parsing in the wild
Jiaxu Miao, Yunchao Wei, Yu Wu, Chen Liang, Guangrui Li, and Yi Yang. Vspw: A large-scale dataset for video scene parsing in the wild. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 4133–4143, 2021. 1, 2, 5, 6, 7, 8
2021
-
[38]
Semantic video segmentation by gated recurrent flow propagation
David Nilsson and Cristian Sminchisescu. Semantic video segmentation by gated recurrent flow propagation. InPro- ceedings of the IEEE conference on computer vision and pat- tern recognition, pages 6819–6828, 2018. 2
2018
-
[39]
Towards stable test-time adaptation in dynamic wild world
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Zhiquan Wen, Yaofo Chen, Peilin Zhao, and Mingkui Tan. Towards stable test-time adaptation in dynamic wild world. InInternetional Conference on Learning Representations, 2023. 3
2023
-
[40]
Feiyu Pan, Hao Fang, Runmin Cong, Wei Zhang, and Xi- ankai Lu. Video object segmentation via sam 2: The 4th solution for lsvos challenge vos track.arXiv preprint arXiv:2408.10125, 2024. 2
-
[41]
Real-time, accurate, and consistent video semantic segmentation via unsupervised adaptation and cross-unit de- ployment on mobile device
Hyojin Park, Alan Yessenbayev, Tushar Singhal, Navin Ku- mar Adhikari, Yizhe Zhang, Shubhankar Mangesh Borse, Hong Cai, Nilesh Prasad Pandey, Fei Yin, Frank Mayer, et al. Real-time, accurate, and consistent video semantic segmentation via unsupervised adaptation and cross-unit de- ployment on mobile device. InProceedings of the IEEE/CVF Conference on Comp...
2022
-
[42]
Local memory attention for fast video semantic segmentation
Matthieu Paul, Martin Danelljan, Luc Van Gool, and Radu Timofte. Local memory attention for fast video semantic segmentation. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1102–1109. IEEE, 2021. 2
2021
-
[43]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Motion-state alignment for video semantic segmentation
Jinming Su, Ruihong Yin, Shuaibin Zhang, and Junfeng Luo. Motion-state alignment for video semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 3571–3580, 2023. 2
2023
-
[45]
Coarse-to-fine feature mining for video se- mantic segmentation
Guolei Sun, Yun Liu, Henghui Ding, Thomas Probst, and Luc Van Gool. Coarse-to-fine feature mining for video se- mantic segmentation. Inproceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 3126–3137, 2022. 2, 5, 6, 8
2022
-
[46]
Mining relations among cross-frame affinities for video semantic segmentation
Guolei Sun, Yun Liu, Hao Tang, Ajad Chhatkuli, Le Zhang, and Luc Van Gool. Mining relations among cross-frame affinities for video semantic segmentation. InEuropean Con- ference on Computer Vision, pages 522–539. Springer, 2022. 2, 5
2022
-
[47]
Learning local and global temporal contexts for video semantic segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Guolei Sun, Yun Liu, Henghui Ding, Min Wu, and Luc Van Gool. Learning local and global temporal contexts for video semantic segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 5, 6, 8
2024
-
[48]
Tesla: Test-time self-learning with automatic adversarial augmentation
Devavrat Tomar, Guillaume Vray, Behzad Bozorgtabar, and Jean-Philippe Thiran. Tesla: Test-time self-learning with automatic adversarial augmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20341–20350, 2023. 3
2023
-
[49]
Tuyen Tran. The 2nd solution for lsvos challenge rvos track: Spatial-temporal refinement for consistent semantic segmen- tation.arXiv preprint arXiv:2408.12447, 2024. 2
-
[50]
Unsupervised semantic seg- mentation by contrasting object mask proposals
Wouter Van Gansbeke, Simon Vandenhende, Stamatios Georgoulis, and Luc Van Gool. Unsupervised semantic seg- mentation by contrasting object mask proposals. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 10052–10062, 2021. 4
2021
-
[51]
Multiple hypothesis video segmentation from superpixel flows
Amelio Vazquez-Reina, Shai Avidan, Hanspeter Pfister, and Eric Miller. Multiple hypothesis video segmentation from superpixel flows. InComputer Vision–ECCV 2010: 11th Eu- ropean Conference on Computer Vision, Heraklion, Crete, Greece, September 5-11, 2010, Proceedings, Part V 11, pages 268–281. Springer, 2010. 2
2010
-
[52]
On the road to online adaptation for semantic image segmentation
Riccardo V olpi, Pau De Jorge, Diane Larlus, and Gabriela Csurka. On the road to online adaptation for semantic image segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19184– 19195, 2022. 3
2022
-
[53]
Tent: Fully Test-time Adaptation by Entropy Minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Ol- shausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization.arXiv preprint arXiv:2006.10726,
work page internal anchor Pith review arXiv 2006
-
[54]
Temporal memory attention for video semantic segmentation
Hao Wang, Weining Wang, and Jing Liu. Temporal memory attention for video semantic segmentation. In2021 IEEE International Conference on Image Processing (ICIP), pages 2254–2258. IEEE, 2021. 2
2021
-
[55]
Continual test-time domain adaptation
Qin Wang, Olga Fink, Luc Van Gool, and Dengxin Dai. Continual test-time domain adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7201–7211, 2022. 3, 6, 7, 8
2022
-
[56]
Dynamically instance- guided adaptation: A backward-free approach for test-time domain adaptive semantic segmentation
Wei Wang, Zhun Zhong, Weijie Wang, Xi Chen, Charles Ling, Boyu Wang, and Nicu Sebe. Dynamically instance- guided adaptation: A backward-free approach for test-time domain adaptive semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24090–24099, 2023. 3
2023
-
[57]
Continual test-time domain adaptation via dynamic sample selection
Yanshuo Wang, Jie Hong, Ali Cheraghian, Shafin Rahman, David Ahmedt-Aristizabal, Lars Petersson, and Mehrtash Harandi. Continual test-time domain adaptation via dynamic sample selection. InProceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision, pages 1701–1710, 2024. 3
2024
-
[58]
Mask propagation for efficient video semantic segmentation
Yuetian Weng, Mingfei Han, Haoyu He, Mingjie Li, Lina Yao, Xiaojun Chang, and Bohan Zhuang. Mask propagation for efficient video semantic segmentation. InNeurIPS, 2023. 2
2023
-
[59]
Segformer: Simple and efficient design for semantic segmentation with transform- ers.Advances in neural information processing systems, 34: 12077–12090, 2021
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transform- ers.Advances in neural information processing systems, 34: 12077–12090, 2021. 1, 5, 6, 8
2021
-
[60]
Xin Yang, Yan Wending, Michael Bi Mi, Yuan Yuan, and Robby Tan. End-to-end video semantic segmentation in adverse weather using fusion blocks and temporal-spatial teacher-student learning.Advances in Neural Information Processing Systems, 37:141000–141020, 2024. 2
2024
-
[61]
Entitysam: Segment everything in video
Mingqiao Ye, Seoung Wug Oh, Lei Ke, and Joon-Young Lee. Entitysam: Segment everything in video. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24234–24243, 2025. 2
2025
-
[62]
Adversarial erasing frame- work via triplet with gated pyramid pooling layer for weakly supervised semantic segmentation
Sung-Hoon Yoon, Hyeokjun Kweon, Jegyeong Cho, Shin- jeong Kim, and Kuk-Jin Yoon. Adversarial erasing frame- work via triplet with gated pyramid pooling layer for weakly supervised semantic segmentation. InEuropean conference on computer vision, pages 326–344. Springer, 2022. 1
2022
-
[63]
Diffusion-guided weakly super- vised semantic segmentation
Sung-Hoon Yoon, Hoyong Kwon, Jaeseok Jeong, Daehee Park, and Kuk-Jin Yoon. Diffusion-guided weakly super- vised semantic segmentation. InEuropean Conference on Computer Vision, pages 393–411. Springer, 2024
2024
-
[64]
Class tokens infusion for weakly supervised semantic segmentation
Sung-Hoon Yoon, Hoyong Kwon, Hyeonseong Kim, and Kuk-Jin Yoon. Class tokens infusion for weakly supervised semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3595–3605, 2024. 1
2024
-
[65]
Jieming Yu, An Wang, Wenzhen Dong, Mengya Xu, Mo- barakol Islam, Jie Wang, Long Bai, and Hongliang Ren. Sam 2 in robotic surgery: An empirical evaluation for ro- bustness and generalization in surgical video segmentation. arXiv preprint arXiv:2408.04593, 2024. 2
-
[66]
Object- contextual representations for semantic segmentation
Yuhui Yuan, Xilin Chen, and Jingdong Wang. Object- contextual representations for semantic segmentation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VI 16, pages 173–190. Springer, 2020. 1, 8
2020
-
[67]
Towards underwater camouflaged ob- ject tracking: An experimental evaluation of sam and sam 2
Chunhui Zhang, Li Liu, Guanjie Huang, Hao Wen, Xi Zhou, and Yanfeng Wang. Towards underwater camouflaged ob- ject tracking: An experimental evaluation of sam and sam 2. arXiv preprint arXiv:2409.16902, 2024. 2
-
[68]
Yichi Zhang and Zhenrong Shen. Unleashing the potential of sam2 for biomedical images and videos: A survey.arXiv preprint arXiv:2408.12889, 2024. 2
-
[69]
Auxadapt: Stable and efficient test-time adaptation for temporally consistent video semantic segmentation
Yizhe Zhang, Shubhankar Borse, Hong Cai, and Fatih Porikli. Auxadapt: Stable and efficient test-time adaptation for temporally consistent video semantic segmentation. In Proceedings of the IEEE/CVF Winter Conference on Appli- cations of Computer Vision, pages 2339–2348, 2022. 3, 7
2022
-
[70]
Scene parsing through ade20k dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 633–641,
-
[71]
When sam2 meets video camouflaged object segmentation: A comprehensive evaluation and adaptation
Yuli Zhou, Guolei Sun, Yawei Li, Luca Benini, and Ender Konukoglu. When sam2 meets video camouflaged object segmentation: A comprehensive evaluation and adaptation. arXiv preprint arXiv:2409.18653, 2024. 2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.