Recognition: unknown
Fast-SegSim: Real-Time Open-Vocabulary Segmentation for Robotics in Simulation
Pith reviewed 2026-05-10 16:08 UTC · model grok-4.3
The pith
Fast-SegSim delivers real-time open-vocabulary 3D segmentation at over 40 FPS for robotics simulation using optimized 2D Gaussian splatting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fast-SegSim realizes real-time, high-fidelity, and 3D-consistent open-vocabulary segmentation reconstruction by replacing the standard high-channel feature accumulation step in 2D Gaussian splatting with a pipeline that uses Precise Tile Intersection to remove rasterization redundancy and Top-K Hard Selection to simplify accumulation according to geometric sparsity, thereby reaching render rates above 40 FPS and supplying usable labels that double navigation success when used for fine-tuning.
What carries the argument
The optimized rendering pipeline that applies Precise Tile Intersection and Top-K Hard Selection to 2D Gaussian splatting to bypass the bandwidth cost of high-channel feature accumulation.
If this is right
- Supplies high-frequency sensor-style inputs directly to simulation platforms such as Gazebo.
- Produces multi-view 3D-consistent ground-truth labels that can be used to fine-tune perception modules.
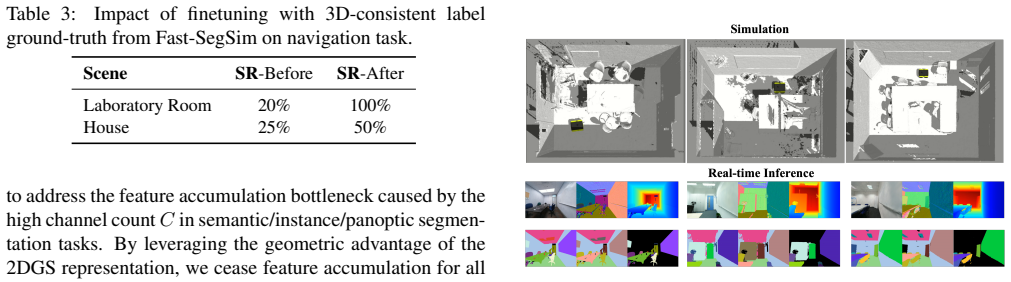
- Raises object-goal navigation success rate by a factor of two when the generated labels are applied to fine-tuning.
Where Pith is reading between the lines
- The same sparsity-driven selection could be tested on other splatting representations that currently face similar feature-channel costs.
- Consistent 3D labels generated at control-loop rates may shorten the data-collection phase needed for sim-to-real transfer in other perception tasks.
- If the speed-accuracy trade-off holds across scenes, the method could support closed-loop planning that uses open-vocabulary queries at each timestep.
Load-bearing premise
The two optimizations keep 3D consistency and segmentation accuracy intact while removing the computational bottleneck of high-channel feature accumulation.
What would settle it
A controlled test that removes the Precise Tile Intersection and Top-K Hard Selection steps and measures whether render speed falls below 40 FPS or whether the generated labels no longer improve navigation success rate when used for fine-tuning.
Figures



read the original abstract
Open-vocabulary panoptic reconstruction is crucial for advanced robotics and simulation. However, existing 3D reconstruction methods, such as NeRF or Gaussian Splatting variants, often struggle to achieve the real-time inference frequency required by robotic control loops. Existing methods incur prohibitive latency when processing the high-dimensional features required for robust open-vocabulary segmentation. We propose Fast-SegSim, a novel, simple, and end-to-end framework built upon 2D Gaussian Splatting, designed to realize real-time, high-fidelity, and 3D-consistent open-vocabulary segmentation reconstruction. Our core contribution is a highly optimized rendering pipeline that specifically addresses the computational bottleneck of high-channel segmentation feature accumulation. We introduce two key optimizations: Precise Tile Intersection to reduce rasterization redundancy, and a novel Top-K Hard Selection strategy. This strategy leverages the geometric sparsity inherent in the 2D Gaussian representation to greatly simplify feature accumulation and alleviate bandwidth limitations, achieving render rates exceeding 40 FPS. Fast-SegSim provides critical value in robotic applications: it serves both as a high-frequency sensor input for simulation platforms like Gazebo, and its 3D-consistent outputs provide essential multi-view 'ground truth' labels for fine-tuning downstream perception tasks. We demonstrate this utility by using the generated labels to fine-tune the perception module in object goal navigation, successfully doubling the navigation success rate. Our superior rendering speed and practical utility underscore Fast-SegSim's potential to bridge the sim-to-real gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Fast-SegSim, a framework built on 2D Gaussian Splatting for real-time open-vocabulary panoptic reconstruction in robotics simulation. It introduces two optimizations—Precise Tile Intersection and Top-K Hard Selection—to address the computational cost of high-dimensional feature accumulation, claiming render rates exceeding 40 FPS while maintaining high-fidelity and 3D-consistent outputs. The work further demonstrates utility by using the generated labels to fine-tune a perception module, doubling success rate in object-goal navigation.
Significance. If the optimizations preserve accuracy and consistency as claimed, the work offers a practical advance for simulation platforms by enabling high-frequency semantic sensing and multi-view label generation for downstream training. This could meaningfully support sim-to-real transfer in robotics perception and control.
major comments (3)
- [Abstract] Abstract: performance numbers (>40 FPS) and the navigation improvement (doubling success rate) are stated without any quantitative metrics, baselines, ablation studies, or error analysis, so the central claims cannot be evaluated from the provided text.
- [Methods (Top-K Hard Selection)] Top-K Hard Selection description: the strategy is asserted to preserve high-fidelity open-vocabulary segmentation and 3D consistency by exploiting 2D Gaussian sparsity, yet no per-channel ablation, mIoU delta, or comparison against full-accumulation baseline is reported to verify that low-magnitude but semantically discriminative features are not discarded.
- [Experiments] Navigation experiment: the claim that generated labels double navigation success rate lacks details on the exact baseline success rate, evaluation protocol, number of trials, or statistical significance, which is load-bearing for the practical-utility argument.
minor comments (2)
- [Abstract] Clarify whether 'panoptic' implies instance-level segmentation or is used interchangeably with semantic segmentation.
- [Introduction] The abstract mentions serving as a sensor for Gazebo; provide at least one concrete integration example or timing measurement in simulation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our results. We address each major comment below and will incorporate revisions to provide the requested details and evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: performance numbers (>40 FPS) and the navigation improvement (doubling success rate) are stated without any quantitative metrics, baselines, ablation studies, or error analysis, so the central claims cannot be evaluated from the provided text.
Authors: We agree that the abstract presents summary claims without supporting numbers or analysis. In the revised manuscript we will expand the experiments section with quantitative FPS measurements (including baselines and hardware details), full ablation results, and complete navigation experiment reporting. The abstract will be updated to reference these results while remaining within length constraints. revision: yes
-
Referee: [Methods (Top-K Hard Selection)] Top-K Hard Selection description: the strategy is asserted to preserve high-fidelity open-vocabulary segmentation and 3D consistency by exploiting 2D Gaussian sparsity, yet no per-channel ablation, mIoU delta, or comparison against full-accumulation baseline is reported to verify that low-magnitude but semantically discriminative features are not discarded.
Authors: The Top-K strategy is motivated by the sparsity of 2D Gaussians, but we acknowledge the absence of direct ablation evidence. We will add a dedicated ablation subsection comparing Top-K Hard Selection against full accumulation, reporting mIoU deltas, per-channel feature retention statistics, and qualitative examples to confirm that semantically discriminative features are preserved. revision: yes
-
Referee: [Experiments] Navigation experiment: the claim that generated labels double navigation success rate lacks details on the exact baseline success rate, evaluation protocol, number of trials, or statistical significance, which is load-bearing for the practical-utility argument.
Authors: We will revise the navigation experiment subsection to report the precise baseline success rate, the full evaluation protocol (including environment setup and episode definitions), the number of trials, and statistical significance tests (e.g., confidence intervals or p-values). This will substantiate the reported doubling of success rate. revision: yes
Circularity Check
No circularity: engineering optimizations without self-referential derivations
full rationale
The paper describes an end-to-end framework for real-time open-vocabulary segmentation via two engineering optimizations (Precise Tile Intersection and Top-K Hard Selection) on 2D Gaussian Splatting. No equations, parameter fits, or derivations appear that reduce by construction to the paper's own inputs or prior self-citations. Claims of preserved 3D consistency and accuracy are presented as direct consequences of the sparsity-exploiting design choices, supported by empirical robotics demonstrations rather than any load-bearing self-definition or renamed known result. The contribution is a practical rendering pipeline, self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo et al., “Segment anything,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4015–4026
2023
-
[2]
Grounded sam: Assembling open-world models for diverse visual tasks,
T. Ren, S. Liu, A. Zeng, J. Lin, K. Li, H. Cao, J. Chen, X. Huang, Y . Chen, F. Yan, Z. Zeng, H. Zhang, F. Li, J. Yang, H. Li, Q. Jiang, and L. Zhang, “Grounded sam: Assembling open-world models for diverse visual tasks,” 2024
2024
-
[3]
Panoptic vision-language feature fields,
H. Chen, K. Blomqvist, F. Milano, and R. Siegwart, “Panoptic vision-language feature fields,”IEEE Robotics and Automa- tion Letters (RA-L), vol. 9, no. 3, pp. 2144–2151, 2024
2024
-
[4]
Panopticrecon: Leverage open-vocabulary instance segmentation for zero-shot panoptic reconstruction,
X. Yu, Y . Liu, C. Han, S. Mao, S. Zhou, R. Xiong, Y . Liao, and Y . Wang, “Panopticrecon: Leverage open-vocabulary in- stance segmentation for zero-shot panoptic reconstruction,” arXiv preprint arXiv:2407.01349, 2024
-
[5]
Leverage cross-attention for end-to-end open-vocabulary panoptic reconstruction,
X. Yu, Y . Xie, Y . Liu, H. Lu, R. Xiong, Y . Liao, and Y . Wang, “Leverage cross-attention for end-to-end open-vocabulary panoptic reconstruction,”arXiv preprint arXiv:2501.01119, 2025
-
[6]
Panopticsplatting: End-to-end panoptic gaussian splatting,
Y . Xie, X. Yu, C. Jiang, S. Mao, S. Zhou, R. Fan, R. Xiong, and Y . Wang, “Panopticsplatting: End-to-end panoptic gaussian splatting,” 2025. [Online]. Available: https://arxiv.org/abs/2503.18073
-
[7]
Panoptic lifting for 3d scene understanding with neural fields,
Y . Siddiqui, L. Porzi, S. R. Bul `o, N. M ¨uller, M. Nießner, A. Dai, and P. Kontschieder, “Panoptic lifting for 3d scene understanding with neural fields,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023
2023
-
[8]
Decompos- ing nerf for editing via feature field distillation,
S. Kobayashi, E. Matsumoto, and V . Sitzmann, “Decompos- ing nerf for editing via feature field distillation,”Advances in neural information processing systems, vol. 35, pp. 23 311– 23 330, 2022
2022
-
[9]
Gaussian grouping: Segment and edit anything in 3d scenes,
M. Ye, M. Danelljan, F. Yu, and L. Ke, “Gaussian grouping: Segment and edit anything in 3d scenes,” inEuropean Con- ference on Computer Vision. Springer, 2024, pp. 162–179
2024
-
[10]
arXiv preprint arXiv:2406.02058 (2024)
Y . Wu, J. Meng, H. Li, C. Wu, Y . Shi, X. Cheng, C. Zhao, H. Feng, E. Ding, J. Wanget al., “Opengaussian: Towards point-level 3d gaussian-based open vocabulary understand- ing,”arXiv preprint arXiv:2406.02058, 2024
-
[11]
Langsplat: 3d language gaussian splatting,
M. Qin, W. Li, J. Zhou, H. Wang, and H. Pfister, “Langsplat: 3d language gaussian splatting,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20 051–20 060
2024
-
[12]
Plgs: Robust panoptic lifting with 3d gaussian splatting,
Y . Wang, X. Wei, M. Lu, and G. Kang, “Plgs: Robust panoptic lifting with 3d gaussian splatting,”arXiv preprint arXiv:2410.17505, 2024
-
[13]
Kimera: an open-source library for real-time metric-semantic localiza- tion and mapping,
A. Rosinol, M. Abate, Y . Chang, and L. Carlone, “Kimera: an open-source library for real-time metric-semantic localiza- tion and mapping,” in2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 1689– 1696
2020
-
[14]
In- place scene labelling and understanding with implicit scene representation,
S. Zhi, T. Laidlow, S. Leutenegger, and A. J. Davison, “In- place scene labelling and understanding with implicit scene representation,” inProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), 2021
2021
-
[15]
Panoptic neural fields: A semantic object-aware neural scene representation,
A. Kundu, K. Genova, X. Yin, A. Fathi, C. Pantofaru, L. J. Guibas, A. Tagliasacchi, F. Dellaert, and T. Funkhouser, “Panoptic neural fields: A semantic object-aware neural scene representation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 12 871–12 881
2022
-
[16]
Instance neural radiance field,
Y . Liu, B. Hu, J. Huang, Y .-W. Tai, and C.-K. Tang, “Instance neural radiance field,” inProceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV), 2023
2023
-
[17]
Sni-slam: Semantic neural implicit slam,
S. Zhu, G. Wang, H. Blum, J. Liu, L. Song, M. Pollefeys, and H. Wang, “Sni-slam: Semantic neural implicit slam,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21 167–21 177
2024
-
[18]
Dm-nerf: 3d scene geom- etry decomposition and manipulation from 2d images,
B. Wang, L. Chen, and B. Yang, “Dm-nerf: 3d scene geom- etry decomposition and manipulation from 2d images,”arXiv preprint arXiv:2208.07227, 2022
-
[19]
Contrastive lift: 3d object instance segmentation by slow-fast contrastive fusion,
Y . Bhalgat, I. Laina, J. F. Henriques, A. Zisserman, and A. Vedaldi, “Contrastive lift: 3d object instance segmentation by slow-fast contrastive fusion,” inNeurIPS, 2023
2023
-
[20]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learn- ing. PMLR, 2021, pp. 8748–8763
2021
-
[21]
Lerf: Language embedded radiance fields,
J. Kerr, C. M. Kim, K. Goldberg, A. Kanazawa, and M. Tan- cik, “Lerf: Language embedded radiance fields,” inProceed- ings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 19 729–19 739
2023
-
[22]
Decompos- ing nerf for editing via feature field distillation,
S. Kobayashi, E. Matsumoto, and V . Sitzmann, “Decompos- ing nerf for editing via feature field distillation,”Advances in Neural Information Processing Systems, vol. 35, pp. 23 311– 23 330, 2022
2022
-
[23]
Lan- guage embedded 3d gaussians for open-vocabulary scene un- derstanding,
J.-C. Shi, M. Wang, H.-B. Duan, and S.-H. Guan, “Lan- guage embedded 3d gaussians for open-vocabulary scene un- derstanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5333– 5343
2024
-
[24]
Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields,
S. Zhou, H. Chang, S. Jiang, Z. Fan, D. Xu, P. Chari, S. You, Z. Wang, and A. Kadambi, “Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21 676–21 685
2024
-
[25]
Gaussian group- ing: Segment and edit anything in 3d scenes,
M. Ye, M. Danelljan, F. Yu, and L. Ke, “Gaussian group- ing: Segment and edit anything in 3d scenes,”arXiv preprint arXiv:2312.00732, 2023
-
[26]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering.” ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
2023
-
[27]
2d gaus- sian splatting for geometrically accurate radiance fields,
B. Huang, Z. Yu, A. Chen, A. Geiger, and S. Gao, “2d gaus- sian splatting for geometrically accurate radiance fields,” in ACM SIGGRAPH 2024 conference papers, 2024, pp. 1–11
2024
-
[28]
Li-gs: Gaussian splatting with lidar incorporated for accu- rate large-scale reconstruction,
C. Jiang, R. Gao, K. Shao, Y . Wang, R. Xiong, and Y . Zhang, “Li-gs: Gaussian splatting with lidar incorporated for accu- rate large-scale reconstruction,”IEEE Robotics and Automa- tion Letters, 2024
2024
-
[29]
arXiv preprint arXiv:2511.04283 , year=
S. Ren, T. Wen, Y . Fang, and B. Lu, “Fastgs: Train- ing 3d gaussian splatting in 100 seconds,”arXiv preprint arXiv:2511.04283, 2025
-
[30]
A. Hanson, A. Tu, G. Lin, V . Singla, M. Zwicker, and T. Goldstein, “Speedy-splat: Fast 3d gaussian splatting with sparse pixels and sparse primitives,” 2025. [Online]. Available: https://arxiv.org/abs/2412.00578
-
[31]
Scannet: Richly-annotated 3d reconstruc- tions of indoor scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstruc- tions of indoor scenes,” inProceedings of the IEEE confer- ence on computer vision and pattern recognition, 2017, pp. 5828–5839
2017
-
[32]
Scan- net++: A high-fidelity dataset of 3d indoor scenes,
C. Yeshwanth, Y .-C. Liu, M. Nießner, and A. Dai, “Scan- net++: A high-fidelity dataset of 3d indoor scenes,” inPro- ceedings of the IEEE/CVF International Conference on Com- puter Vision, 2023, pp. 12–22
2023
-
[33]
Available: https://arxiv.org/abs/2312.03275
N. Yokoyama, S. Ha, D. Batra, J. Wang, and B. Bucher, “Vlfm: Vision-language frontier maps for zero-shot semantic navigation,” 2023. [Online]. Available: https://arxiv.org/abs/ 2312.03275
-
[34]
arXiv preprint arXiv:2506.17733 (2025)
M. Lei, S. Li, Y . Wu, H. Hu, Y . Zhou, X. Zheng, G. Ding, S. Du, Z. Wu, and Y . Gao, “Yolov13: Real-time object detection with hypergraph-enhanced adaptive visual perception,” 2025. [Online]. Available: https://arxiv.org/abs/ 2506.17733
-
[35]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang, H. Su, J. Zhuet al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detec- tion,”arXiv preprint arXiv:2303.05499, 2023
work page Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.