Recognition: no theorem link
RAG-KT: Cross-platform Explainable Knowledge Tracing with Multi-view Fusion Retrieval Generation
Pith reviewed 2026-05-10 16:26 UTC · model grok-4.3
The pith
RAG-KT lets large language models perform knowledge tracing across different educational platforms by aligning data through question groups and retrieving reliable context for each prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that framing knowledge tracing as reliable context-constrained inference inside large language models, supported by a unified multi-source context created through cross-source alignment via Question Group abstractions and by multi-view fusion retrieval of complementary information, produces grounded predictions and interpretable diagnoses that remain accurate even when the source platforms exhibit substantial distribution shifts.
What carries the argument
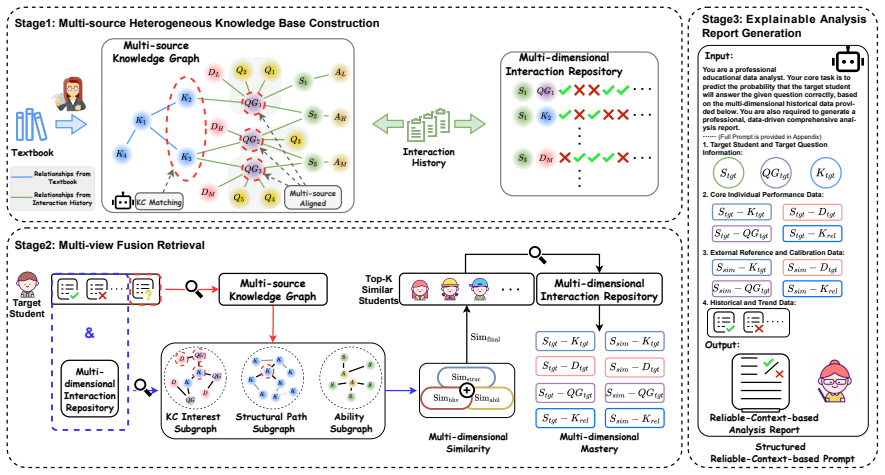
Question Group abstractions that align equivalent questions across heterogeneous platforms, combined with multi-view retrieval that supplies both rich and reliable context to the language model for each prediction.
If this is right
- KT models can be deployed across multiple platforms without retraining or platform-specific identifiers.
- Predictions come with explicit retrieved evidence, supporting diagnosis of why a student is expected to succeed or fail.
- Performance remains stable under realistic distribution shifts between training and deployment data sources.
- The same retrieval pipeline can incorporate additional public or auxiliary educational resources without changing the core model.
Where Pith is reading between the lines
- The same alignment-plus-retrieval pattern could be applied to other student modeling tasks such as skill recommendation or dropout prediction when data arrive from separate apps.
- Reducing reliance on platform-specific training data might lower the barrier to building KT systems for smaller or newer educational tools.
- If question groups prove stable, they could serve as a lightweight ontology for transferring other educational analytics across vendors.
Load-bearing premise
The approach assumes that abstracting questions into groups can create reliable cross-source alignment even when the underlying platforms differ markedly in their question distributions and student populations.
What would settle it
A clear drop in both accuracy and explanation quality when the system is tested on platforms whose question sets share almost no common groups or when the retrieved context is deliberately replaced with mismatched material would falsify the central claim.
Figures




read the original abstract
Knowledge Tracing (KT) infers a student's knowledge state from past interactions to predict future performance. Conventional Deep Learning (DL)-based KT models are typically tied to platform-specific identifiers and latent representations, making them hard to transfer and interpret. Large Language Model (LLM)-based methods can be either ungrounded under prompting or overly domain-dependent under fine-tuning. In addition, most existing KT methods are developed and evaluated under a same-distribution assumption. In real deployments, educational data often arise from heterogeneous platforms with substantial distribution shift, which often degrades generalization. To this end, we propose RAG-KT, a retrieval-augmented paradigm that frames cross-platform KT as reliable context constrained inference with LLMs. It builds a unified multi-source structured context with cross-source alignment via Question Group abstractions and retrieves complementary rich and reliable context for each prediction, enabling grounded prediction and interpretable diagnosis. Experiments on three public KT benchmarks demonstrate consistent gains in accuracy and robustness, including strong performance under cross-platform conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RAG-KT, a retrieval-augmented generation paradigm for knowledge tracing that frames cross-platform KT as LLM inference constrained by unified multi-source context. It introduces Question Group abstractions for cross-source alignment, multi-view retrieval to gather complementary context, and fusion for grounded predictions and interpretable diagnosis. Experiments on three public KT benchmarks report consistent accuracy and robustness gains, including under cross-platform distribution shifts.
Significance. If the central claims hold, this work could meaningfully advance transferable and explainable KT by combining RAG with LLMs to mitigate platform-specific limitations of DL models and ungrounded LLM prompting. The multi-view fusion and alignment approach offers a concrete mechanism for handling distribution shifts, with potential for practical deployment in heterogeneous educational settings. The emphasis on interpretable diagnosis is a clear strength relative to black-box baselines.
major comments (2)
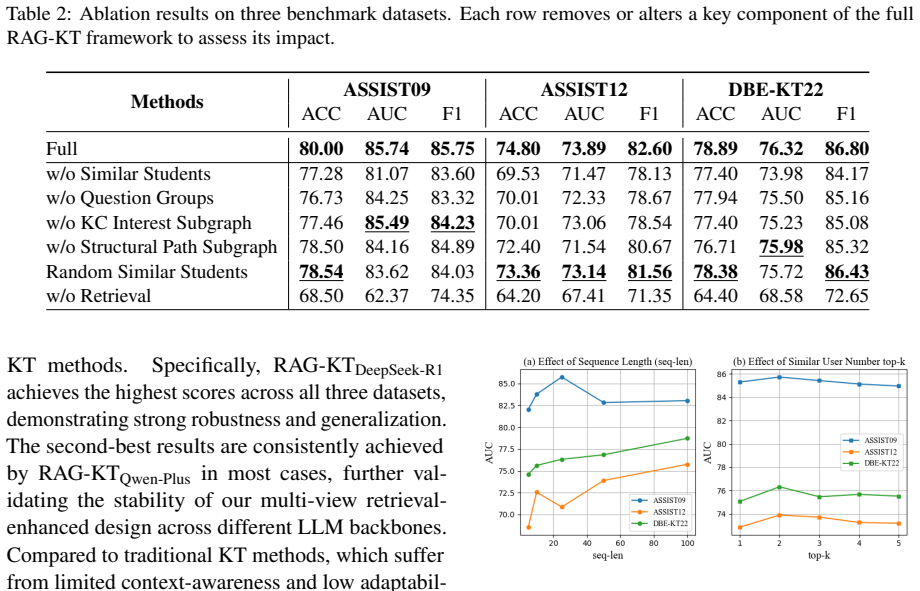
- [§4] §4 (Cross-platform experiments): The manuscript claims consistent gains and strong performance under cross-platform conditions, yet provides no quantitative metrics on Question Group alignment fidelity (e.g., inter-platform group overlap, semantic equivalence rates, or human verification). This is load-bearing for the central claim that the abstractions produce reliable grounded context under substantial distribution shifts.
- [§3.2] §3.2 (Question Group abstractions): The construction of Question Group abstractions is presented as the key enabler of cross-source alignment, but the paper lacks ablation studies or robustness tests isolating this component's contribution versus other retrieval elements. Without such evidence, it remains unclear whether alignment quality degrades under platform-specific variations in phrasing or difficulty, as the skeptic concern highlights.
minor comments (2)
- [Abstract] The abstract references 'three public KT benchmarks' without naming them; this should be stated explicitly for immediate clarity.
- [Figure 2] Figure 2 (pipeline diagram) would benefit from explicit callouts for the multi-view fusion step to aid reader comprehension of the retrieval-generation flow.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments on evaluation of the Question Group abstractions and cross-platform results are well-taken and will improve the manuscript. We address each point below and commit to revisions that provide the requested evidence without altering the core claims.
read point-by-point responses
-
Referee: [§4] §4 (Cross-platform experiments): The manuscript claims consistent gains and strong performance under cross-platform conditions, yet provides no quantitative metrics on Question Group alignment fidelity (e.g., inter-platform group overlap, semantic equivalence rates, or human verification). This is load-bearing for the central claim that the abstractions produce reliable grounded context under substantial distribution shifts.
Authors: We agree that direct quantitative metrics on alignment fidelity would strengthen the central claim. The current cross-platform results demonstrate consistent accuracy and robustness gains under distribution shifts, providing indirect support for the abstractions' effectiveness in producing reliable context. However, to directly address the concern, we will add to the revised §4: (i) inter-platform group overlap ratios computed across the three benchmarks, (ii) embedding-based semantic equivalence rates (e.g., cosine similarity thresholds) between aligned Question Groups, and (iii) results from a small-scale human verification study on sampled groups confirming alignment quality. These additions will make the load-bearing evidence explicit. revision: yes
-
Referee: [§3.2] §3.2 (Question Group abstractions): The construction of Question Group abstractions is presented as the key enabler of cross-source alignment, but the paper lacks ablation studies or robustness tests isolating this component's contribution versus other retrieval elements. Without such evidence, it remains unclear whether alignment quality degrades under platform-specific variations in phrasing or difficulty, as the skeptic concern highlights.
Authors: We concur that dedicated isolation of the Question Group component is needed. The existing ablations examine the multi-view retrieval and fusion stages as a whole, but do not separately remove or vary the alignment step. In the revision we will add, within or adjacent to §3.2: (i) an ablation replacing Question Group abstractions with direct per-question retrieval and reporting the resulting performance drop, and (ii) robustness tests that introduce controlled phrasing variations and difficulty shifts across platforms while measuring alignment and downstream accuracy. These experiments will quantify the component's isolated contribution and its behavior under platform-specific variations. revision: yes
Circularity Check
No circularity: RAG-KT is a retrieval-based paradigm without self-referential reductions
full rationale
The paper introduces RAG-KT as a new retrieval-augmented framework that constructs multi-source context via Question Group abstractions and uses LLM inference for cross-platform KT predictions. No equations, fitted parameters, or derivations are presented that reduce predictions to quantities defined by the model's own inputs or prior self-citations. The central claims rest on external retrieval mechanisms and experimental evaluation on public benchmarks rather than tautological constructions or load-bearing self-references. The approach is self-contained as an applied methodology relying on independent LLM capabilities and data retrieval, with no evidence of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can perform reliable and interpretable inference when supplied with rich, aligned, and reliable multi-source context
invented entities (1)
-
Question Group abstractions
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwen technical report.arXiv preprint arXiv:2309.16609. Indronil Bhattacharjee and Christabel Wayllace. 2025. Cold start problem: An experimental study of knowl- edge tracing models with new students.arXiv preprint arXiv:2505.21517. Songlin Chen, Weicheng Wang, Xiaoliang Chen, Peng Lu, Zaiyan Yang, and Yajun Du. 2024. Llama-lora neural prompt engineering: ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Mingyu Feng, Neil Heffernan, and Kenneth Koedinger
Hise-kt: Synergizing heterogeneous informa- tion networks and llms for explainable knowledge tracing with meta-path optimization.arXiv preprint arXiv:2511.15191. Mingyu Feng, Neil Heffernan, and Kenneth Koedinger
-
[3]
Dieter Fox, Wolfram Burgard, and Sebastian Thrun
Addressing the assessment challenge with an online system that tutors as it assesses.User modeling and user-adapted interaction, pages 243– 266. Dieter Fox, Wolfram Burgard, and Sebastian Thrun
-
[4]
MiMo-Embodied: X-Embodied Foundation Model Technical Report
The dynamic window approach to collision avoidance.IEEE robotics & automation magazine, pages 23–33. Aritra Ghosh, Neil Heffernan, and Andrew S Lan. 2020. Context-aware attentive knowledge tracing. InPro- ceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2330–2339. Xiaoshuai Hao, Lei Zhou, and 1 others. 2...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[5]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Yunfei Liu, Yang Yang, Xianyu Chen, Jian Shen, Haifeng Zhang, and Yong Yu. 2020. Improving knowledge tracing via pre-training question embed- dings.arXiv preprint arXiv:2012.05031. Zitao Liu, Qiongqiong Liu, Jiahao Chen, Shuyan Huang, Boyu Gao, Weiqi Luo, and Jian Weng. 2023. Enhanc- ing deep k...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
Pedagogical Equivalence: Are the concepts pedagogically equivalent or do they have a very high degree of content overlap?
-
[7]
Syllabus Coherence: Are they typically clas- sified under the same specific module in an educational syllabus?
-
[8]
Core Skill Identity: Do they teach the same fundamental mathematical essence or target the same core skills?
-
[9]
We explicitly evaluate alignment accuracy by first asking domain experts to manually align the KCs between the source and target platforms as ground truth
Exclusion of Weak Relations: The relation- ship must be one of equivalence, not merely topical relevance or partial overlap. We explicitly evaluate alignment accuracy by first asking domain experts to manually align the KCs between the source and target platforms as ground truth. We then run our KC Match proce- dure and compare its outputs against this ex...
-
[10]
- Qualitative Judgment: Based on the accuracy in the core prediction, select the most appropriate level from the five defined categories
Prediction Outcome - Core Prediction: Clearly state the predicted probability of the student answering the question correctly (e.g., Predicted Accuracy: XX%). - Qualitative Judgment: Based on the accuracy in the core prediction, select the most appropriate level from the five defined categories. Use the exact descriptions below: - >80%: Expected to answer...
-
[11]
- Knowledge Mastery Structure: - Target Knowledge Point: Clearly assess the student's mastery of the target knowledge point
Student Ability Analysis - Overall Ability Assessment: - Briefly describe the student’s ability level (e.g., high, above average) and compare it to peer groups, clearly stating their relative position (e.g., at the average level, slightly above, slightly below). - Knowledge Mastery Structure: - Target Knowledge Point: Clearly assess the student's mastery ...
-
[12]
strong knowledge mastery but low ability bottleneck
Prediction Attribution and Decision - Key Positive Factors: List 1–2 core pieces of evidence supporting the student’s likelihood of answering the question correctly, with corresponding data. - Key Risk Factors: List 1–2 core risks that may lead to an incorrect answer, with corresponding data. - Final Decision Logic: This is the core of the report and must...
-
[13]
Target Student and Target Question Information: - Target student's ability estimate: - Target student's ability level: - Target question's associated question group: - Target question's difficulty: - Target question's discrimination: - Knowledge point assessed by the target question:
-
[14]
Core Individual Performance Data: - Performance on target knowledge point: - Performance by difficulty level: - Performance on target question group: - Performance on related knowledge points:
-
[15]
External Reference and Calibration Data: - List of similar students: - Similar students' performance on the target knowledge point: - Similar students' performance at the target difficulty level: - Similar students' performance on the target question group: - Similar students' performance on related knowledge points: - Performance on the target question g...
-
[16]
Historical and Trend Data: - Target student’s answer history: Figure 5: Structured Reliable-Context-based Prompt
-
[17]
D_2 difficulty: 6 attempts, all incorrect
x-y graph reading (K_150) - Attempts: 13 questions - Performance: - D_1 difficulty: 3 attempts, all incorrect. D_2 difficulty: 6 attempts, all incorrect. D_3 difficulty: 4 attempts, 1 correct (most recent), 3 incorrect. - Analysis: - The student struggled consistently across all difficulty levels, with 12 consecutive incorrect responses initially. - The s...
-
[18]
- Analysis: - Strong initial performance (3 correct) but the latest attempt was incorrect, indicating possible inconsistency or lapse in understanding
changes in the direction of figures (K_63) - Attempts: 4 questions - Performance: D_2 difficulty: 3 correct, 1 incorrect (most recent attempt). - Analysis: - Strong initial performance (3 correct) but the latest attempt was incorrect, indicating possible inconsistency or lapse in understanding. - The student handles D_2 questions well generally but may ne...
-
[19]
Greatest common factor
distance formula (K_166) - Attempts: 7 questions - Performance: D_2 difficulty: 3 correct, 4 incorrect (including the most recent attempt). - Analysis: - Inconsistent results: Correct responses interspersed with errors, showing partial understanding but lack of stability. - The final attempt was incorrect, suggesting unresolved gaps or application issues ...
-
[20]
Knowledge points involved in the new question - The new exercise contains: K_13 (greatest common factor)
-
[21]
Link between the new question and previous work - It's a new question. - There is no direct connection between the previous knowledge points (x-y graph reading, changes in direction of figures, distance formula) and this question (greatest common factor). The topic is distinct and has not appeared in the student's history
-
[22]
Student's updated knowledge state Based on historical performance: - K_150 (x-y graph reading): bad (1 correct / 12 attempts; consistent errors, last correct was isolated) - K_63 (changes in direction of figures): fair (3 correct / 4 attempts; mostly successful but one recent error) - K_166 (distance formula): bad (3 correct / 7 attempts; inconsistent, la...
-
[23]
- Reasons: - The student has no recorded history with K_13 (greatest common factor), indicating no prior exposure or practice
Analysis of student's performance on the new question -The student gets it wrong, likely because of incorrect mastery. - Reasons: - The student has no recorded history with K_13 (greatest common factor), indicating no prior exposure or practice. - Given the student’s overall struggle with math topics (e.g., K_150 and K_166 at "bad" mastery), it is unlikel...
-
[24]
Prediction Outcome - Core Prediction: Predicted Accuracy: 57.00% - Qualitative Judgment: Equal chance of correct and incorrect
-
[25]
Student Ability Analysis - Overall Ability Assessment: The target student's ability estimate is 0.38, at the MIDDLE level, which is consistent with the average level of peer groups with similar ability. - Knowledge Mastery Structure: Target Knowledge Point (S_13, greatest common factor): There is no direct performance data (Dynamic Weighted Accuracy, Accu...
-
[26]
Prediction Attribution and Decision - Key Positive Factors: - Students with similar ability to the target student have a 74.42% accuracy on QG_13_2 (sample size 13564), providing strong positive reference due to the large sample. - A similar student (U_asst12190138, similarity 95.23) has a 57.52% DWA on S_13 (8 attempts, Confidence 77.35), reflecting reli...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.