Recognition: unknown
LumiMotion: Improving Gaussian Relighting with Scene Dynamics
Pith reviewed 2026-05-10 15:27 UTC · model grok-4.3
The pith
Scene motion supplies independent lighting variations that let Gaussian Splatting separate albedo from illumination more accurately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
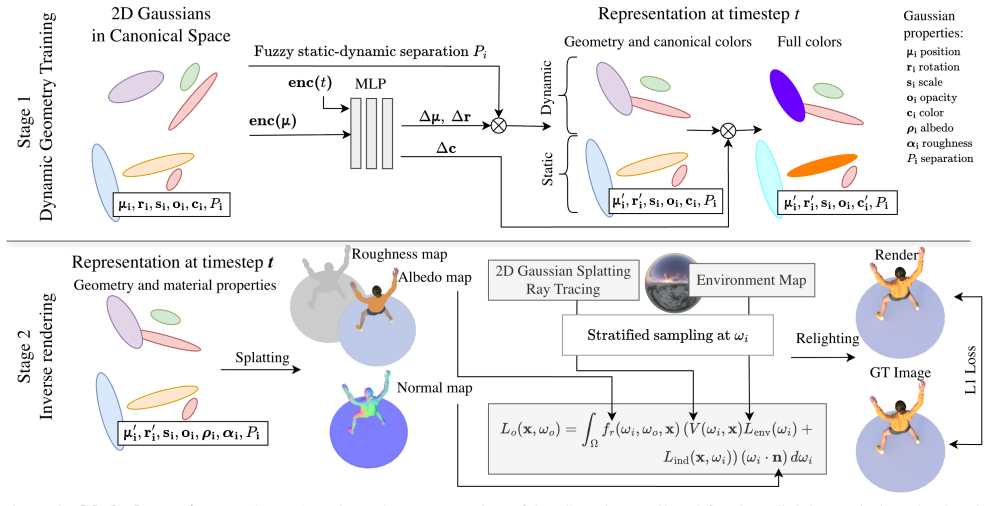
LumiMotion learns a dynamic 2D Gaussian Splatting representation that employs novel constraints to encourage deformation only in moving parts of the scene while keeping static parts stable, thereby using observed motion to provide independent lighting variations on the same surfaces and improve the separation of albedo from illumination in arbitrary dynamic environments.
What carries the argument
A dynamic 2D Gaussian Splatting representation together with novel constraints that separate deforming regions from stable ones so motion can act as a lighting-variation signal during inverse rendering.
If this is right
- Albedo estimation improves by 23 percent in LPIPS relative to the next-best baseline.
- Scene relighting improves by 15 percent in LPIPS relative to the next-best baseline.
- The method works in arbitrary dynamic scenes without requiring simplified or moderate lighting assumptions.
- A released synthetic benchmark of five scenes under four lighting conditions, each in static and dynamic variants, enables systematic evaluation of inverse rendering under motion.
Where Pith is reading between the lines
- The same motion-based separation could be inserted into existing video reconstruction pipelines that already track dynamic elements.
- Relighting of animated content may see reduced shadow leakage once the deformation constraints are combined with explicit shadow modeling.
- The benchmark scenes could be extended with real captured motion to test whether the reported gains hold when deformation is less clean than in synthetic data.
Load-bearing premise
Motion supplies independent lighting variations on the same surfaces without creating irresolvable new entanglements among deformation, shadows, and material appearance.
What would settle it
A controlled test scene in which moving objects produce shadows whose motion is perfectly correlated with surface deformation, such that applying the method yields no gain or a loss in albedo or relighting accuracy.
Figures

















read the original abstract
In 3D reconstruction, the problem of inverse rendering, namely recovering the illumination of the scene and the material properties, is fundamental. Existing Gaussian Splatting-based methods primarily target static scenes and often assume simplified or moderate lighting to avoid entangling shadows with surface appearance. This limits their ability to accurately separate lighting effects from material properties, particularly in real-world conditions. We address this limitation by leveraging dynamic elements - regions of the scene that undergo motion - as a supervisory signal for inverse rendering. Motion reveals the same surfaces under varying lighting conditions, providing stronger cues for disentangling material and illumination. This thesis is supported by our experimental results which show we improve LPIPS by 23% for albedo estimation and by 15% for scene relighting relative to next-best baseline. To this end, we introduce LumiMotion, the first Gaussian-based approach that leverages dynamics for inverse rendering and operates in arbitrary dynamic scenes. Our method learns a dynamic 2D Gaussian Splatting representation that employs a set of novel constraints which encourage the dynamic regions of the scene to deform, while keeping static regions stable. As we demonstrate, this separation is crucial for correct optimization of the albedo. Finally, we release a new synthetic benchmark comprising five scenes under four lighting conditions, each in both static and dynamic variants, for the first time enabling systematic evaluation of inverse rendering methods in dynamic environments and challenging lighting. Link to project page: https://joaxkal.github.io/LumiMotion/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LumiMotion, a method extending 2D Gaussian Splatting to dynamic scenes for inverse rendering. It uses scene motion as a supervisory signal to disentangle material properties (albedo) from illumination by learning a dynamic 2D Gaussian representation with novel constraints that promote deformation only in moving regions while stabilizing static ones. The approach is evaluated on a new synthetic benchmark with five scenes under four lighting conditions in both static and dynamic variants, reporting 23% LPIPS improvement for albedo estimation and 15% for scene relighting over the next-best baseline. The manuscript positions this as the first Gaussian-based inverse rendering method operating in arbitrary dynamic scenes.
Significance. If the disentanglement holds under the proposed constraints, the work addresses a genuine gap in Gaussian Splatting-based inverse rendering by exploiting dynamics for stronger lighting variation cues on identical surfaces. The new benchmark enabling systematic static-vs-dynamic comparisons is a clear strength and could support future research. The idea of motion-induced supervision is promising for real-world conditions where static assumptions fail, though its impact depends on whether the constraints sufficiently isolate deformation from visibility and shadow effects.
major comments (2)
- [§4] §4 (Method), novel constraints paragraph: the formulation encourages deformation in moving regions and stability in static ones but does not specify explicit terms for 3D consistency, shadow-aware losses, or visibility penalties. This is load-bearing for the central disentanglement claim, because motion simultaneously alters surface orientation, casts new shadows, and changes occlusions; without isolating these couplings the optimizer can still attribute lighting variations to albedo or BRDF, eroding the reported LPIPS gains.
- [Experiments] Experiments section, quantitative results: the 23% albedo and 15% relighting LPIPS improvements are stated relative to the next-best baseline, yet no error bars, data-split details, or ablation isolating the novel constraints versus the base dynamic 2DGS representation are provided. This undermines verification that the gains stem from the motion-based supervision rather than other implementation choices.
minor comments (2)
- [Abstract / Experiments] The abstract and introduction refer to 'arbitrary dynamic scenes' but the benchmark is entirely synthetic with engineered lighting; the manuscript should clarify the domain gap and include at least one real-world sequence with qualitative results.
- [Figures] Figure captions and the project page link are helpful, but the manuscript would benefit from a failure-case analysis showing when motion-induced entanglements are not resolved.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the method and experiments.
read point-by-point responses
-
Referee: [§4] §4 (Method), novel constraints paragraph: the formulation encourages deformation in moving regions and stability in static ones but does not specify explicit terms for 3D consistency, shadow-aware losses, or visibility penalties. This is load-bearing for the central disentanglement claim, because motion simultaneously alters surface orientation, casts new shadows, and changes occlusions; without isolating these couplings the optimizer can still attribute lighting variations to albedo or BRDF, eroding the reported LPIPS gains.
Authors: We appreciate the referee highlighting the need for explicit handling of 3D consistency, shadows, and visibility. Our novel constraints comprise a motion-detection-guided deformation regularizer that applies higher penalties to static regions (enforcing appearance constancy) and a lower penalty in dynamic regions (allowing deformation), together with a cross-frame photometric loss on the same surface points. This design leverages the fact that static surfaces must retain consistent albedo across frames despite changing illumination, discouraging the optimizer from folding shadow or occlusion effects into albedo. We acknowledge that the current text does not explicitly derive 3D consistency or shadow-aware terms; we will expand §4 with the full mathematical formulation of the constraints, add a paragraph discussing their implicit effect on visibility and orientation changes, and include a brief limitations note on residual shadow entanglement. No new loss terms will be introduced, but the clarification will make the load-bearing mechanism transparent. revision: partial
-
Referee: [Experiments] Experiments section, quantitative results: the 23% albedo and 15% relighting LPIPS improvements are stated relative to the next-best baseline, yet no error bars, data-split details, or ablation isolating the novel constraints versus the base dynamic 2DGS representation are provided. This undermines verification that the gains stem from the motion-based supervision rather than other implementation choices.
Authors: We agree that additional statistical detail and targeted ablations are necessary for rigorous verification. In the revised manuscript we will: (i) report LPIPS means accompanied by standard deviations computed over five independent training runs with different random seeds; (ii) explicitly describe the train/test split protocol for each of the five scenes and four lighting conditions; and (iii) add an ablation table that compares the base dynamic 2DGS representation against the full LumiMotion model (with and without the novel constraints). These additions will directly isolate the contribution of the motion-based supervision to the reported 23 % and 15 % gains. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces novel constraints on a dynamic 2D Gaussian Splatting representation to leverage scene motion for disentangling illumination and materials in inverse rendering. These are presented as new supervisory signals, with performance gains validated through comparisons to external baselines on a newly released synthetic benchmark. No equations, parameters, or central claims reduce by construction to fitted inputs or self-citations; the method is self-contained with independent experimental support.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Motion in dynamic regions reveals the same surfaces under varying lighting conditions that are independent of material properties
Reference graph
Works this paper leans on
-
[1]
Re- covering intrinsic scene characteristics.Comput
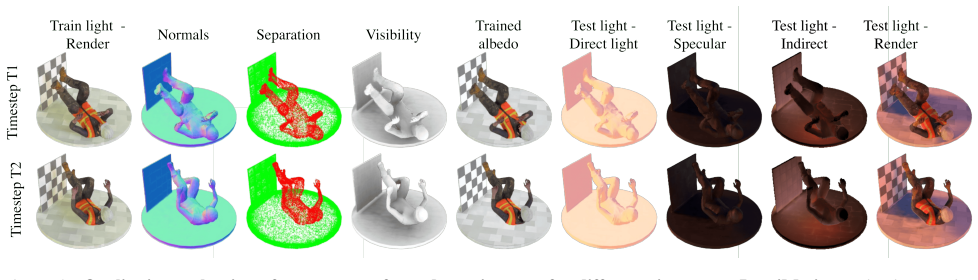
Harry Barrow, J Tenenbaum, A Hanson, and E Riseman. Re- covering intrinsic scene characteristics.Comput. vis. syst, 2 (3-26):2, 1978. 1
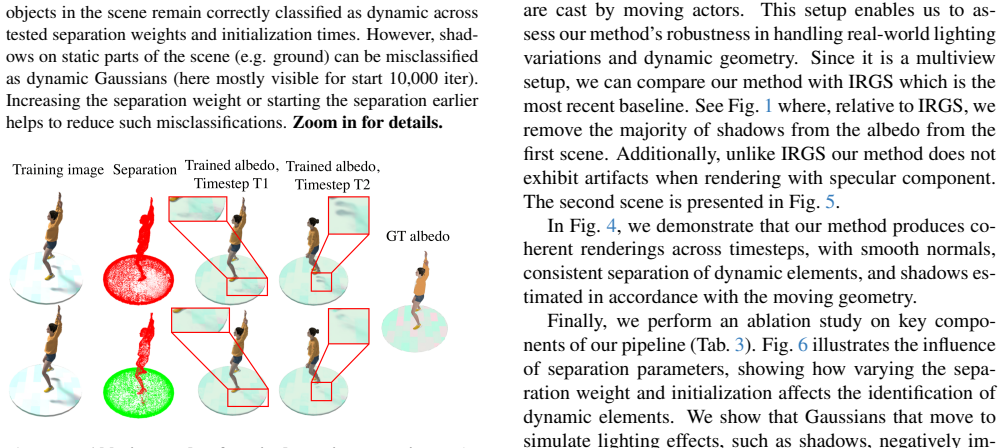
1978
-
[2]
Gs 3: Efficient relighting with triple gaussian splatting
Zoubin Bi, Yixin Zeng, Chong Zeng, Fan Pei, Xiang Feng, Kun Zhou, and Hongzhi Wu. Gs 3: Efficient relighting with triple gaussian splatting. InSIGGRAPH Asia 2024 Confer- ence Papers, SA 2024, Tokyo, Japan, December 3-6, 2024, pages 12:1–12:12. ACM, 2024. 2, 3
2024
-
[3]
Bar- ron, Ce Liu, and Hendrik P
Mark Boss, Raphael Braun, Varun Jampani, Jonathan T. Bar- ron, Ce Liu, and Hendrik P. A. Lensch. Nerd: Neural re- flectance decomposition from image collections. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pages 12664–12674. IEEE, 2021. 3
2021
-
[4]
Physically-based shading at disney
Brent Burley and Walt Disney Animation Studios. Physically-based shading at disney. InAcm siggraph, pages 1–7. vol. 2012, 2012. 3
2012
-
[5]
Tensorf: Tensorial radiance fields
Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. Tensorf: Tensorial radiance fields. InComputer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XXXII, pages 333–350. Springer, 2022. 2, 3
2022
-
[6]
Nerv: Neural representations for videos
Hao Chen, Bo He, Hanyu Wang, Yixuan Ren, Ser-Nam Lim, and Abhinav Shrivastava. Nerv: Neural representations for videos. InAdvances in Neural Information Processing Sys- tems 34: Annual Conference on Neural Information Process- ing Systems 2021, NeurIPS 2021, December 6-14, 2021, vir- tual, pages 21557–21568, 2021. 3
2021
-
[7]
GI-GS: global illumination decomposition on gaussian splatting for inverse rendering
Hongze Chen, Zehong Lin, and Jun Zhang. GI-GS: global illumination decomposition on gaussian splatting for inverse rendering. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24- 28, 2025. OpenReview.net, 2025. 2, 3, 4, 6
2025
-
[8]
Gaussianeditor: Swift and controllable 3d editing with gaussian splatting.2024 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 21476–21485, 2023
Yiwen Chen, Zilong Chen, Chi Zhang, Feng Wang, Xiaofeng Yang, Yikai Wang, Zhongang Cai, Lei Yang, Huaping Liu, and Guosheng Lin. Gaussianeditor: Swift and controllable 3d editing with gaussian splatting.2024 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 21476–21485, 2023. 2
2024
-
[9]
Wei Cheng, Ruixiang Chen, Wanqi Yin, Siming Fan, Keyu Chen, Honglin He, Huiwen Luo, Zhongang Cai, Jingbo Wang, Yang Gao, Zhengming Yu, Zhengyu Lin, Daxuan Ren, Lei Yang, Ziwei Liu, Chen Change Loy, Chen Qian, Wayne Wu, Dahua Lin, Bo Dai, and Kwan-Yee Lin. Dna- rendering: A diverse neural actor repository for high-fidelity human-centric rendering.arXiv pre...
-
[10]
Meshgs: Adaptive mesh-aligned gaus- sian splatting for high-quality rendering
Jaehoon Choi, Yonghan Lee, Hyungtae Lee, Heesung Kwon, and Dinesh Manocha. Meshgs: Adaptive mesh-aligned gaus- sian splatting for high-quality rendering. InProceedings of the Asian Conference on Computer Vision (ACCV), pages 3310–3326, 2024. 3
2024
-
[11]
Relightable 3d gaussians: Re- alistic point cloud relighting with brdf decomposition and ray tracing
Jian Gao, Chun Gu, Youtian Lin, Zhihao Li, Hao Zhu, Xun Cao, Li Zhang, and Yao Yao. Relightable 3d gaussians: Re- alistic point cloud relighting with brdf decomposition and ray tracing. InEuropean Conference on Computer Vision, pages 73–89. Springer, 2024. 2, 3
2024
-
[12]
Fastnerf: High-fidelity neu- ral rendering at 200fps
Stephan J Garbin, Marek Kowalski, Matthew Johnson, Jamie Shotton, and Julien Valentin. Fastnerf: High-fidelity neu- ral rendering at 200fps. InProceedings of the IEEE/CVF international conference on computer vision, pages 14346– 14355, 2021. 2
2021
-
[13]
Irgs: Inter-reflective gaussian splatting with 2d gaus- sian ray tracing
Chun Gu, Xiaofei Wei, Zixuan Zeng, Yuxuan Yao, and Li Zhang. Irgs: Inter-reflective gaussian splatting with 2d gaus- sian ray tracing. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10943–10952, 2025. 1, 2, 3, 6, 7, 22
2025
-
[14]
Sugar: Surface- aligned gaussian splatting for efficient 3d mesh reconstruc- tion and high-quality mesh rendering.CVPR, 2024
Antoine Gu ´edon and Vincent Lepetit. Sugar: Surface- aligned gaussian splatting for efficient 3d mesh reconstruc- tion and high-quality mesh rendering.CVPR, 2024. 3
2024
-
[15]
Beam: Bridging physically-based rendering and gaussian modeling for relightable volumetric video
Yu Hong, Yize Wu, Zhehao Shen, Chengcheng Guo, Yuheng Jiang, Yingliang Zhang, Qiang Hu, Jingyi Yu, and Lan Xu. Beam: Bridging physically-based rendering and gaussian modeling for relightable volumetric video. InProceedings of the 33rd ACM International Conference on Multimedia, pages 7968–7977, 2025. 3
2025
-
[16]
2d gaussian splatting for geometrically ac- curate radiance fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically ac- curate radiance fields. InACM SIGGRAPH 2024 Conference Papers, SIGGRAPH 2024, Denver, CO, USA, 27 July 2024- 1 August 2024, page 32. ACM, 2024. 2, 3, 5
2024
-
[17]
SC-GS: sparse-controlled gaussian splatting for editable dynamic scenes
Yi-Hua Huang, Yang-Tian Sun, Ziyi Yang, Xiaoyang Lyu, Yan-Pei Cao, and Xiaojuan Qi. SC-GS: sparse-controlled gaussian splatting for editable dynamic scenes. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 4220–4230. IEEE, 2024. 3
2024
-
[18]
RANA: relightable articu- lated neural avatars
Umar Iqbal, Akin Caliskan, Koki Nagano, Sameh Khamis, Pavlo Molchanov, and Jan Kautz. RANA: relightable articu- lated neural avatars. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 23085–23096. IEEE, 2023. 2
2023
-
[19]
Gaussian- shader: 3d gaussian splatting with shading functions for re- flective surfaces
Yingwenqi Jiang, Jiadong Tu, Yuan Liu, Xifeng Gao, Xi- aoxiao Long, Wenping Wang, and Yuexin Ma. Gaussian- shader: 3d gaussian splatting with shading functions for re- flective surfaces. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 5322–5332, 2024. 3
2024
-
[20]
Tensoir: Tensorial inverse rendering
Haian Jin, Isabella Liu, Peijia Xu, Xiaoshuai Zhang, Song- fang Han, Sai Bi, Xiaowei Zhou, Zexiang Xu, and Hao Su. Tensoir: Tensorial inverse rendering. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 165–
2023
-
[21]
James T. Kajiya. The rendering equation. InProceedings of the 13th Annual Conference on Computer Graphics and Interactive Techniques, page 143–150, New York, NY , USA,
-
[22]
Association for Computing Machinery. 3
-
[23]
Lumigauss: Relightable gaussian splatting in the wild
Joanna Kaleta, Kacper Kania, Tomasz Trzci ´nski, and Marek Kowalski. Lumigauss: Relightable gaussian splatting in the wild. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1–10. IEEE, 2025. 2
2025
-
[24]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139:1– 139:14, 2023. 1, 2
2023
-
[25]
Stanford-orb: a real-world 3d object inverse rendering benchmark.Advances in Neural Information Processing Systems, 36:46938–46957, 2023
Zhengfei Kuang, Yunzhi Zhang, Hong-Xing Yu, Samir Agar- wala, Elliott Wu, Jiajun Wu, et al. Stanford-orb: a real-world 3d object inverse rendering benchmark.Advances in Neural Information Processing Systems, 36:46938–46957, 2023. 2
2023
-
[26]
Uravatar: Universal relightable gaussian codec avatars
Junxuan Li, Chen Cao, Gabriel Schwartz, Rawal Khirod- kar, Christian Richardt, Tomas Simon, Yaser Sheikh, and Shunsuke Saito. Uravatar: Universal relightable gaussian codec avatars. InSIGGRAPH Asia 2024 Conference Papers, SA 2024, Tokyo, Japan, December 3-6, 2024, pages 128:1– 128:11. ACM, 2024. 3
2024
-
[27]
Gs-ir: 3d gaussian splatting for inverse rendering
Zhihao Liang, Qi Zhang, Ying Feng, Ying Shan, and Kui Jia. Gs-ir: 3d gaussian splatting for inverse rendering. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21644–21653, 2024. 3
2024
-
[28]
Efficient neural radiance fields for interactive free-viewpoint video
Haotong Lin, Sida Peng, Zhen Xu, Yunzhi Yan, Qing Shuai, Hujun Bao, and Xiaowei Zhou. Efficient neural radiance fields for interactive free-viewpoint video. InSIGGRAPH Asia Conference Proceedings, 2022. 7, 12
2022
-
[29]
Openillumination: A multi- illumination dataset for inverse rendering evaluation on real objects.Advances in Neural Information Processing Sys- tems, 36:36951–36962, 2023
Isabella Liu, Linghao Chen, Ziyang Fu, Liwen Wu, Haian Jin, Zhong Li, Chin Ming Ryan Wong, Yi Xu, Ravi Ra- mamoorthi, Zexiang Xu, et al. Openillumination: A multi- illumination dataset for inverse rendering evaluation on real objects.Advances in Neural Information Processing Sys- tems, 36:36951–36962, 2023. 2
2023
-
[30]
Isabella Liu, Hao Su, and Xiaolong Wang. Dynamic gaus- sians mesh: Consistent mesh reconstruction from monocular videos.arXiv preprint arXiv:2404.12379, 2024. 3
-
[31]
Re- lightable neural actor with intrinsic decomposition and pose control
Diogo Carbonera Luvizon, Vladislav Golyanik, Adam Ko- rtylewski, Marc Habermann, and Christian Theobalt. Re- lightable neural actor with intrinsic decomposition and pose control. InComputer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part LIX, pages 465–483. Springer, 2024. 2
2024
-
[32]
The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables
Chris J Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous relaxation of discrete random variables.arXiv preprint arXiv:1611.00712, 2016. 4
work page Pith review arXiv 2016
-
[33]
Jewett, Simon Ven- shtain, Christopher Heilman, Yueh-Tung Chen, Sidi Fu, Mo- hamed Ezzeldin A
Julieta Martinez, Emily Kim, Javier Romero, Timur Bagaut- dinov, Shunsuke Saito, Shoou-I Yu, Stuart Anderson, Michael Zollh ¨ofer, Te-Li Wang, Shaojie Bai, Chenghui Li, Shih-En Wei, Rohan Joshi, Wyatt Borsos, Tomas Simon, Jason Saragih, Paul Theodosis, Alexander Greene, Anjani Josyula, Silvio Mano Maeta, Andrew I. Jewett, Simon Ven- shtain, Christopher He...
2024
-
[34]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: representing scenes as neural radiance fields for view synthe- sis.Commun. ACM, 65(1):99–106, 2022. 1, 2, 4
2022
-
[35]
Instant neural graphics primitives with a mul- tiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022
Thomas M ¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a mul- tiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022. 2
2022
-
[36]
D-nerf: Neural radiance fields for dynamic scenes
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-nerf: Neural radiance fields for dynamic scenes. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 10318–10327, 2021. 7, 20
2021
-
[37]
Relightable gaussian codec avatars
Shunsuke Saito, Gabriel Schwartz, Tomas Simon, Junxuan Li, and Giljoo Nam. Relightable gaussian codec avatars. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 130–141. IEEE, 2024. 2, 3
2024
-
[38]
Games: Mesh-based adapting and modification of gaussian splatting.ArXiv, abs/2402.01459, 2024
Joanna Waczy ´nska, Piotr Borycki, Sławomir Konrad Tadeja, Jacek Tabor, and Przemysław Spurek. Games: Mesh-based adapting and modification of gaussian splatting.ArXiv, abs/2402.01459, 2024. 2
-
[39]
Intrinsicavatar: Physically based inverse rendering of dynamic humans from monocular videos via explicit ray tracing
Shaofei Wang, Bozidar Antic, Andreas Geiger, and Siyu Tang. Intrinsicavatar: Physically based inverse rendering of dynamic humans from monocular videos via explicit ray tracing. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 1877–1888. IEEE, 2024. 2
2024
-
[40]
Relightable full-body gaussian codec avatars
Shaofei Wang, Tomas Simon, Igor Santesteban, Timur Bagautdinov, Junxuan Li, Vasu Agrawal, Fabian Prada, Shoou-I Yu, Pace Nalbone, Matt Gramlich, et al. Relightable full-body gaussian codec avatars. InProceedings of the Special Interest Group on Computer Graphics and Interac- tive Techniques Conference Conference Papers, pages 1–12,
-
[41]
Bovik, H.R
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4): 600–612, 2004. 7
2004
-
[42]
4d gaussian splatting for real-time dynamic scene render- ing
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4d gaussian splatting for real-time dynamic scene render- ing. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 20310– 20320, 2024. 3, 4
2024
-
[43]
Deferredgs: Decoupled and editable gaus- sian splatting with deferred shading.ArXiv, abs/2404.09412,
Tong Wu, Jiali Sun, Yu-Kun Lai, Yuewen Ma, Leif Kobbelt, and Lin Gao. Deferredgs: Decoupled and editable gaus- sian splatting with deferred shading.ArXiv, abs/2404.09412,
-
[44]
En- vgs: Modeling view-dependent appearance with environ- ment gaussian
Tao Xie, Xi Chen, Zhen Xu, Yiman Xie, Yudong Jin, Yu- jun Shen, Sida Peng, Hujun Bao, and Xiaowei Zhou. En- vgs: Modeling view-dependent appearance with environ- ment gaussian. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5742–5751, 2025. 2
2025
-
[45]
Renerf: Re- lightable neural radiance fields with nearfield lighting
Yingyan Xu, Gaspard Zoss, Prashanth Chandran, Markus Gross, Derek Bradley, and Paulo Gotardo. Renerf: Re- lightable neural radiance fields with nearfield lighting. In 2023 IEEE/CVF International Conference on Computer Vi- sion (ICCV), pages 22524–22534, 2023. 3
2023
-
[46]
Deformable 3d gaussians for high- fidelity monocular dynamic scene reconstruction
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3d gaussians for high- fidelity monocular dynamic scene reconstruction. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20331–20341, 2024. 3, 4, 22
2024
-
[47]
Neilf: Neural incident light field for physically-based mate- rial estimation
Yao Yao, Jingyang Zhang, Jingbo Liu, Yihang Qu, Tian Fang, David McKinnon, Yanghai Tsin, and Long Quan. Neilf: Neural incident light field for physically-based mate- rial estimation. InEuropean conference on computer vision, pages 700–716. Springer, 2022. 3
2022
-
[48]
Reflective gaussian splatting.arXiv preprint, 2024
Yuxuan Yao, Zixuan Zeng, Chun Gu, Xiatian Zhu, and Li Zhang. Reflective gaussian splatting.arXiv preprint, 2024. 3
2024
-
[49]
3d gaussian splat- ting with deferred reflection
Keyang Ye, Qiming Hou, and Kun Zhou. 3d gaussian splat- ting with deferred reflection. InACM SIGGRAPH 2024 Con- ference Papers, pages 1–10, 2024. 3
2024
-
[50]
Youyi Zhan, Tianjia Shao, He Wang, Yin Yang, and Kun Zhou. Interactive rendering of relightable and animatable gaussian avatars.arXiv preprint arXiv:2407.10707, 2024. 2, 3
-
[51]
Neilf++: Inter-reflectable light fields for geometry and material es- timation.International Conference on Computer Vision (ICCV), 2023
Jingyang Zhang, Yao Yao, Shiwei Li, Jingbo Liu, Tian Fang, David McKinnon, Yanghai Tsin, and Long Quan. Neilf++: Inter-reflectable light fields for geometry and material es- timation.International Conference on Computer Vision (ICCV), 2023. 3
2023
-
[52]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018. 7
2018
-
[53]
Srinivasan, Boyang Deng, Paul E
Xiuming Zhang, Pratul P. Srinivasan, Boyang Deng, Paul E. Debevec, William T. Freeman, and Jonathan T. Barron. Ner- factor: neural factorization of shape and reflectance under an unknown illumination.ACM Trans. Graph., 40(6):237:1– 237:18, 2021. 2
2021
-
[54]
Modeling indirect illumination for inverse rendering
Yuanqing Zhang, Jiaming Sun, Xingyi He, Huan Fu, Rongfei Jia, and Xiaowei Zhou. Modeling indirect illumination for inverse rendering. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 18622–18631. IEEE,
2022
-
[55]
Yiqun Zhao, Chenming Wu, Binbin Huang, Yihao Zhi, Chen Zhao, Jingdong Wang, and Shenghua Gao. Surfel-based gaussian inverse rendering for fast and relightable dynamic human reconstruction from monocular video.arXiv preprint arXiv:2407.15212, 2024. 3 LumiMotion: Improving Gaussian Relighting with Scene Dynamics Supplementary Material
-
[56]
Code and data repository Code and data are included in our repository: https://github.com/joaxkal/LumiMotion
-
[57]
Videos Please refer to our attached videos for more results on: •ENeRF dataset [27]: real world data, moving actors with wall background
Additional videos and figures 2.1. Videos Please refer to our attached videos for more results on: •ENeRF dataset [27]: real world data, moving actors with wall background. Actors cast strong shadow. •DNA dataset [9]: real world multiview data, moving ac- tors with additional items like stool, table, hair dryer. •our synthetic scenes. 2.2. Figures We pres...
-
[58]
4 we present extended results, including Novel View Synthesis (NVS) and Roughness
Extended results In Tab. 4 we present extended results, including Novel View Synthesis (NVS) and Roughness. 3.1. Novel View Synthesis We show thatthe dynamic setting we use is significantly more challenging than the static setup for baselines, as reflected in the novel view synthesis metrics. Despite this, LumiMotionachieves strong results for materials a...
-
[59]
16, we illustrate the influence of separation hyperpa- rameters
Separation - additional example of ablation and hyperparameter influence In Fig. 16, we illustrate the influence of separation hyperpa- rameters. Our separation method robustly detects moving parts of jumping actor. Depending on the scene, a delayed start or a separation value that is too low may impair the pe- nalization of static regions. In Fig. 15 we ...
-
[60]
We build 5 synthetic datasets in Blender, using Mixamo 2 platform and simple Blender meshes
Our dataset We provide additional details about our synthetic dataset and its generation process. We build 5 synthetic datasets in Blender, using Mixamo 2 platform and simple Blender meshes. We prepared each scene in two versions: dynamic and static. For dynamic version, we use D-NeRF [35] like setup with different camera view for each timestep, creating ...
-
[61]
Our MLP architecture follows the design proposed in [45], consisting of an 8-layer MLP with a width of 256 units per layer
Implementation details We train each scene in two stages: 35,000 iterations in Stage 1 and 20,000 iterations in Stage 2. Our MLP architecture follows the design proposed in [45], consisting of an 8-layer MLP with a width of 256 units per layer. The learning rate for the MLP is set to 0.0008 and decays exponentially to 0.00008. In Stage 1, we train using a...
2048
-
[62]
20, we illustrate the limitations of our dynamic train- ing strategy
Limitation - example In Fig. 20, we illustrate the limitations of our dynamic train- ing strategy. For more complex and detailed motions, for example near surfaces, simple separation may need to be replaced with more specialized supervision, such as optical flow
-
[63]
Limitations of simple separation strategy
Full affiliations The full affiliations, abbreviated in the author section due to space constraints, are as follows: (1) Warsaw Univer- Figure 20. Limitations of simple separation strategy. Some Gaus- sians between the plate surface and the shoes are neither part of the static plate nor clearly part of the dynamic shoe. sity of Technology, Poland; (2) San...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.