Recognition: unknown
A Faster Path to Continual Learning
Pith reviewed 2026-05-10 15:20 UTC · model grok-4.3
The pith
C-Flat Turbo speeds up continual learning optimization by skipping redundant gradient computations through direction-invariant flatness components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
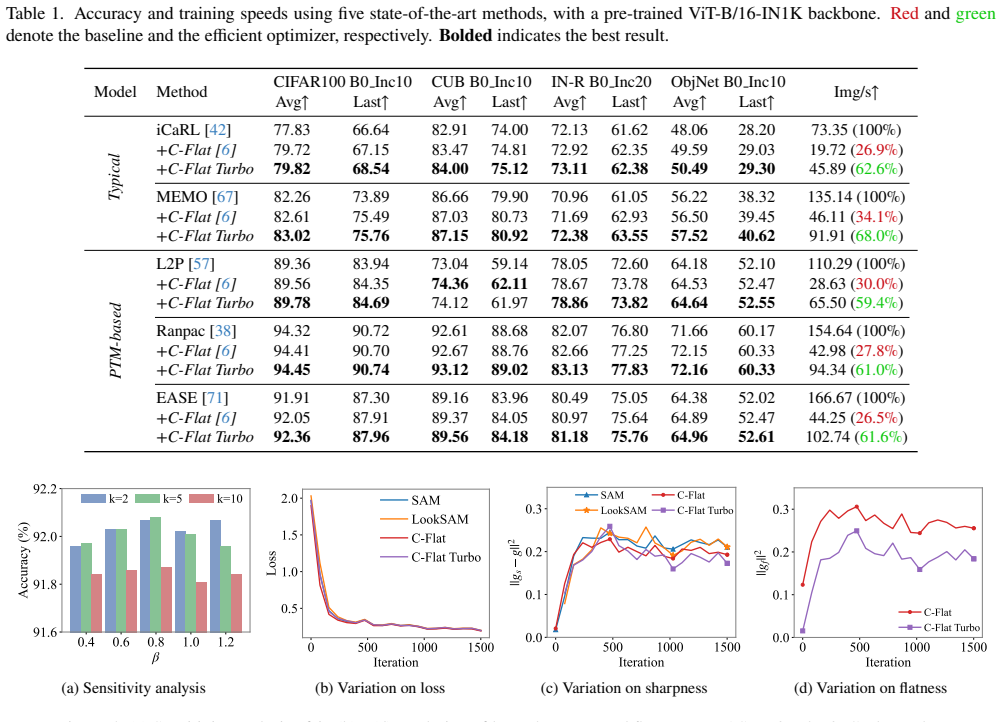
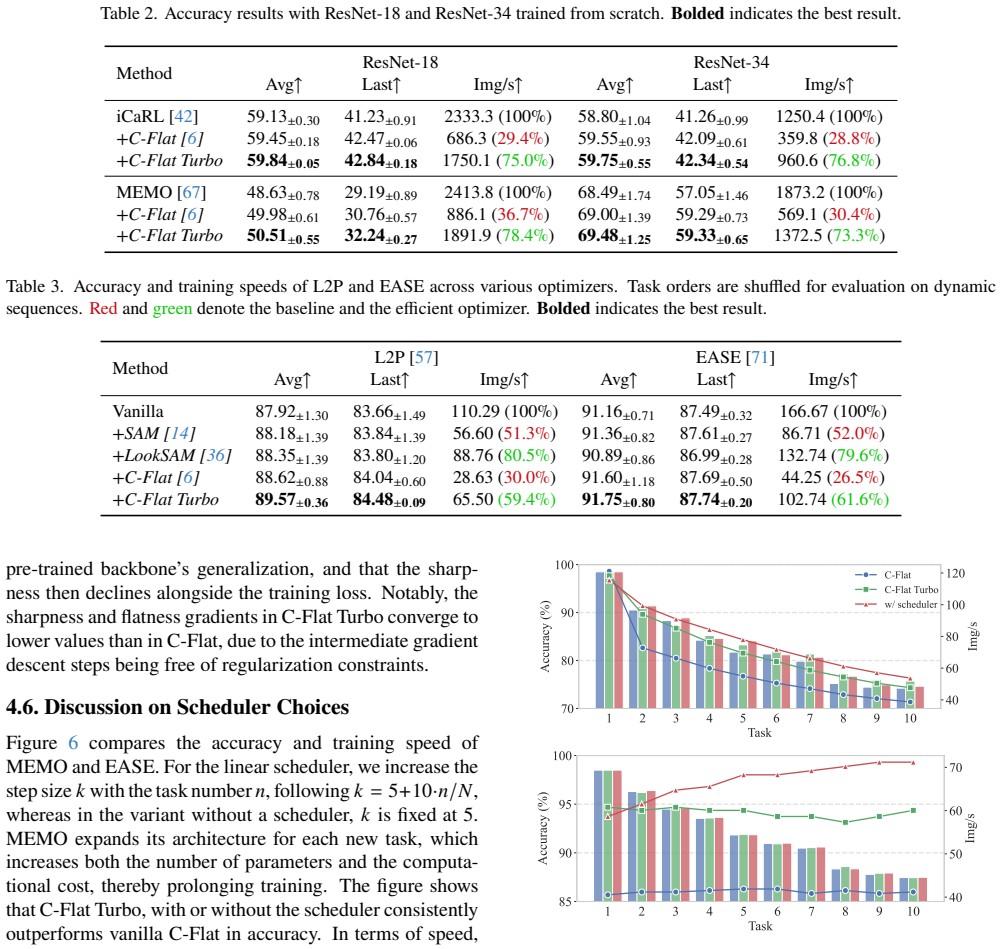
The gradients associated with first-order flatness contain direction-invariant components relative to the proxy-model gradients, enabling us to skip redundant gradient computations in the perturbed ascent steps. Moreover, these flatness-promoting gradients progressively stabilize across tasks, which motivates a linear scheduling strategy with an adaptive trigger to allocate larger turbo steps for later tasks. Experiments show that C-Flat Turbo is 1.0× to 1.25× faster than C-Flat across a wide range of CL methods, while achieving comparable or even improved accuracy.
What carries the argument
Direction-invariant components of first-order flatness gradients relative to proxy-model gradients, which permit skipping redundant perturbed ascent steps, combined with progressive stabilization of flatness-promoting gradients across tasks that enables linear scheduling and adaptive turbo triggers.
If this is right
- Existing continual learning methods gain a plug-and-play speedup of up to 25 percent with no accuracy penalty.
- The computational cost of flatness-based optimization decreases as the number of tasks grows due to increasing stabilization.
- The same invariance observation can be applied to other perturbation-based flatness regularizers.
- Adaptive skipping allows training to allocate more compute early and less later without manual tuning.
Where Pith is reading between the lines
- The stabilization pattern could be measured directly during training to decide skip amounts on the fly rather than using a preset linear schedule.
- If the invariance holds for other perturbation sizes, the approach might combine with second-order flatness measures for additional savings.
- Longer task sequences would likely show even larger relative speedups once stabilization saturates.
Load-bearing premise
The direction-invariant components of flatness gradients can be omitted without damaging the uniform low-loss regions for both old and new tasks, and the observed stabilization pattern is consistent enough to support reliable adaptive scheduling.
What would settle it
A direct comparison where C-Flat Turbo produces higher loss on previous tasks or greater catastrophic forgetting than standard C-Flat when the same number of iterations is used.
Figures


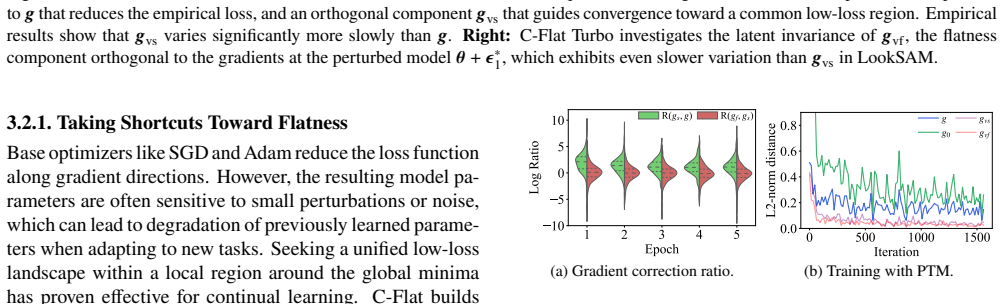


read the original abstract
Continual Learning (CL) aims to train neural networks on a dynamic stream of tasks without forgetting previously learned knowledge. Among optimization-based approaches, C-Flat has emerged as a promising solution due to its plug-and-play nature and its ability to encourage uniformly low-loss regions for both new and old tasks. However, C-Flat requires three additional gradient computations per iteration, imposing substantial overhead on the optimization process. In this work, we propose C-Flat Turbo, a faster yet stronger optimizer that significantly reduces the training cost. We show that the gradients associated with first-order flatness contain direction-invariant components relative to the proxy-model gradients, enabling us to skip redundant gradient computations in the perturbed ascent steps. Moreover, we observe that these flatness-promoting gradients progressively stabilize across tasks, which motivates a linear scheduling strategy with an adaptive trigger to allocate larger turbo steps for later tasks. Experiments show that C-Flat Turbo is 1.0$\times$ to 1.25$\times$ faster than C-Flat across a wide range of CL methods, while achieving comparable or even improved accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes C-Flat Turbo, an accelerated optimizer for continual learning that builds on C-Flat. It claims that first-order flatness gradients contain direction-invariant components relative to proxy-model gradients, allowing redundant gradient computations to be skipped in perturbed ascent steps. It further observes progressive stabilization of these gradients across tasks, motivating a linear scheduling strategy with an adaptive trigger to enable larger 'turbo' steps in later tasks. Experiments report 1.0× to 1.25× speedups over C-Flat while maintaining comparable or improved accuracy across a range of CL methods.
Significance. If the direction-invariance and stabilization claims are rigorously verified, the work offers a practical reduction in the computational overhead of flatness-based CL methods without altering their plug-and-play character. The modest but consistent speedups could improve usability in resource-limited settings. The empirical observation of gradient stabilization across tasks is a potentially useful insight, though its generality remains to be established.
major comments (3)
- [Abstract and §3] Abstract and §3 (core mechanism): The central claim that first-order flatness gradients contain direction-invariant components 'enabling us to skip redundant gradient computations' lacks explicit verification that the uniform low-loss region property for both old and new tasks is preserved after skipping. No comparison of loss surfaces, sharpness metrics, or update directions before versus after the turbo approximation is provided, so it is unclear whether the effective update still matches the original C-Flat objective.
- [§4] §4 (scheduling): The linear scheduling with adaptive trigger relies on the free parameter 'adaptive trigger threshold' whose value is chosen based on observed stabilization. This introduces moderate circularity: the trigger is tuned to the very behavior it is meant to exploit, and no sensitivity analysis or cross-task generalization test is reported to show the schedule remains reliable beyond the evaluated sequences.
- [Experiments] Experiments section: The reported speedups and accuracy parity are load-bearing for the 'faster yet stronger' claim, yet the manuscript provides insufficient controls (e.g., ablations isolating the skipping step, flatness metric comparisons, or runs with fixed versus adaptive scheduling) to confirm that the turbo approximation does not degrade the flatness property on which C-Flat's forgetting resistance depends.
minor comments (2)
- [Abstract] The abstract states speedups as '1.0× to 1.25×' without per-method or per-dataset breakdowns; a table summarizing exact wall-clock or iteration counts would improve clarity.
- [Methods] Notation for the turbo step size and trigger threshold should be introduced with explicit symbols and default values in the methods section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment point by point below. In the revised manuscript we will incorporate additional verification experiments, sensitivity analyses, and ablations as detailed in the responses. These changes directly strengthen the empirical support for the direction-invariance claim and the scheduling strategy without altering the core technical contributions.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (core mechanism): The central claim that first-order flatness gradients contain direction-invariant components 'enabling us to skip redundant gradient computations' lacks explicit verification that the uniform low-loss region property for both old and new tasks is preserved after skipping. No comparison of loss surfaces, sharpness metrics, or update directions before versus after the turbo approximation is provided, so it is unclear whether the effective update still matches the original C-Flat objective.
Authors: We agree that an explicit verification of the preserved low-loss region property would strengthen the presentation. The direction-invariance observation is derived from the fact that the flatness-promoting gradient components orthogonal to the proxy-model direction remain unchanged; therefore the net update direction after skipping is theoretically equivalent up to a scalar. To make this concrete, the revised manuscript will add (i) cosine-similarity measurements between the original and turbo-approximated update vectors across training iterations, and (ii) comparisons of sharpness metrics (Hessian trace and loss curvature on both current and previous tasks) before versus after the approximation. These results will be reported in a new subsection of §3 and will confirm that the uniform low-loss region property is maintained. revision: yes
-
Referee: [§4] §4 (scheduling): The linear scheduling with adaptive trigger relies on the free parameter 'adaptive trigger threshold' whose value is chosen based on observed stabilization. This introduces moderate circularity: the trigger is tuned to the very behavior it is meant to exploit, and no sensitivity analysis or cross-task generalization test is reported to show the schedule remains reliable beyond the evaluated sequences.
Authors: We acknowledge the concern about potential circularity in threshold selection. In the revision we will (a) present a sensitivity study sweeping the adaptive trigger threshold over a wide range and reporting both speedup and accuracy on the same task sequences, and (b) evaluate the resulting schedule on two additional task-order permutations not used during threshold selection. These experiments will be added to §4 and the appendix, demonstrating that the linear schedule with the chosen trigger generalizes reliably. revision: yes
-
Referee: [Experiments] Experiments section: The reported speedups and accuracy parity are load-bearing for the 'faster yet stronger' claim, yet the manuscript provides insufficient controls (e.g., ablations isolating the skipping step, flatness metric comparisons, or runs with fixed versus adaptive scheduling) to confirm that the turbo approximation does not degrade the flatness property on which C-Flat's forgetting resistance depends.
Authors: We agree that stronger controls are warranted. The revised experiments section will include: (1) an ablation that isolates the gradient-skipping step while keeping the linear schedule fixed, (2) direct comparisons of flatness metrics (e.g., average sharpness on old tasks) with and without the turbo approximation, and (3) side-by-side runs of fixed versus adaptive scheduling. These additions will be placed in §5 and the appendix to explicitly verify that the forgetting-resistance properties of C-Flat are retained. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's speedup claims rest on empirical observations of gradient direction invariance and progressive stabilization across tasks, presented as motivations for skipping computations and adaptive scheduling. No equations or steps in the abstract reduce by construction to fitted inputs renamed as predictions, self-definitional loops, or load-bearing self-citations. The derivation chain is self-contained as a heuristic optimization technique validated through experiments on existing CL methods, without the central result being forced by its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- adaptive trigger threshold
Reference graph
Works this paper leans on
-
[1]
Conditional channel gated networks for task-aware continual learning
Davide Abati, Jakub Tomczak, Tijmen Blankevoort, Simone Calderara, Rita Cucchiara, and Babak Ehteshami Bejnordi. Conditional channel gated networks for task-aware continual learning. InCVPR, 2020. 2
2020
-
[2]
Subspace regularizers for few-shot class incremental learning.ICLR, 2022
Afra Feyza Aky¨ urek, Ekin Aky¨ urek, Derry Tanti Wijaya, and Jacob Andreas. Subspace regularizers for few-shot class incremental learning.ICLR, 2022. 2
2022
-
[3]
Shaping the learning landscape in neural networks around wide flat minima.Proceedings of the National Academy of Sciences, 117(1):161–170, 2020
Carlo Baldassi, Fabrizio Pittorino, and Riccardo Zecchina. Shaping the learning landscape in neural networks around wide flat minima.Proceedings of the National Academy of Sciences, 117(1):161–170, 2020. 2
2020
-
[4]
Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models.Advances in neural information processing systems, 2019
Andrei Barbu, David Mayo, Julian Alverio, William Luo, Christopher Wang, Dan Gutfreund, Josh Tenenbaum, and Boris Katz. Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models.Advances in neural information processing systems, 2019. 6
2019
-
[5]
Task-aware information routing from common representation space in lifelong learning.ICLR, 2023
Prashant Bhat, Bahram Zonooz, and Elahe Arani. Task-aware information routing from common representation space in lifelong learning.ICLR, 2023. 2
2023
-
[6]
Make continual learning stronger via c-flat.Advances in Neural Information Processing Systems, 37:7608–7630, 2024
Ang Bian, Wei Li, Hangjie Yuan, Mang Wang, Zixiang Zhao, Aojun Lu, Pengliang Ji, Tao Feng, et al. Make continual learning stronger via c-flat.Advances in Neural Information Processing Systems, 37:7608–7630, 2024. 1, 2, 3, 6, 7, 8, 5
2024
-
[7]
Cpr: classifier-projection regular- ization for continual learning.ICLR, 2021
Sungmin Cha, Hsiang Hsu, Taebaek Hwang, Flavio P Cal- mon, and Taesup Moon. Cpr: classifier-projection regular- ization for continual learning.ICLR, 2021. 2
2021
-
[8]
Flattening sharpness for dynamic gradient projection memory benefits continual learning
Danruo Deng, Guangyong Chen, Jianye Hao, Qiong Wang, and Pheng-Ann Heng. Flattening sharpness for dynamic gradient projection memory benefits continual learning. NeurIPS, 34, 2021. 1, 2
2021
-
[9]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, 2009. 6
2009
-
[10]
Jiawei Du, Hanshu Yan, Jiashi Feng, Joey Tianyi Zhou, Lian- gli Zhen, Rick Siow Mong Goh, and Vincent YF Tan. Effi- cient sharpness-aware minimization for improved training of neural networks.arXiv preprint arXiv:2110.03141, 2021. 2
-
[11]
Sharpness-aware training for free.Ad- vances in Neural Information Processing Systems, 35:23439– 23451, 2022
Jiawei Du, Daquan Zhou, Jiashi Feng, Vincent Tan, and Joey Tianyi Zhou. Sharpness-aware training for free.Ad- vances in Neural Information Processing Systems, 35:23439– 23451, 2022. 2
2022
-
[12]
Overcoming catastrophic forgetting in incremental object detection via elastic response distillation
Tao Feng, Mang Wang, and Hangjie Yuan. Overcoming catastrophic forgetting in incremental object detection via elastic response distillation. InCVPR, 2022. 2
2022
-
[13]
Zeroflow: Overcoming catas- trophic forgetting is easier than you think
Tao Feng, Wei Li, Didi Zhu, Hangjie Yuan, Wendi Zheng, Dan Zhang, and Jie Tang. Zeroflow: Overcoming catas- trophic forgetting is easier than you think. InForty-second International Conference on Machine Learning, 2025. 1
2025
-
[14]
Sharpness-Aware Minimization for Efficiently Improving Generalization
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-aware minimization for efficiently im- proving generalization.arXiv preprint arXiv:2010.01412,
work page internal anchor Pith review arXiv 2010
-
[15]
Decorate the newcomers: Vi- sual domain prompt for continual test time adaptation
Yulu Gan, Yan Bai, Yihang Lou, Xianzheng Ma, Renrui Zhang, Nian Shi, and Lin Luo. Decorate the newcomers: Vi- sual domain prompt for continual test time adaptation. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 7595–7603, 2023. 2
2023
-
[16]
R-dfcil: Relation-guided representation learning for data-free class incremental learning
Qiankun Gao, Chen Zhao, Bernard Ghanem, and Jian Zhang. R-dfcil: Relation-guided representation learning for data-free class incremental learning. InECCV, 2022. 2
2022
-
[17]
A unified continual learn- ing framework with general parameter-efficient tuning
Qiankun Gao, Chen Zhao, Yifan Sun, Teng Xi, Gang Zhang, Bernard Ghanem, and Jian Zhang. A unified continual learn- ing framework with general parameter-efficient tuning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11483–11493, 2023. 2
2023
-
[18]
Embracing change: Continual learning in deep neural networks.Trends in cognitive sciences, 24(12):1028– 1040, 2020
Raia Hadsell, Dushyant Rao, Andrei A Rusu, and Razvan Pascanu. Embracing change: Continual learning in deep neural networks.Trends in cognitive sciences, 24(12):1028– 1040, 2020. 1, 2
2020
-
[19]
Asymmetric val- leys: Beyond sharp and flat local minima.NeurIPS, 32, 2019
Haowei He, Gao Huang, and Yang Yuan. Asymmetric val- leys: Beyond sharp and flat local minima.NeurIPS, 32, 2019. 1, 2
2019
-
[20]
The many faces of robust- ness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kada- vath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robust- ness: A critical analysis of out-of-distribution generalization. InProceedings of the IEEE/CVF international conference on computer vision, 2021. 6
2021
-
[21]
Dense network expansion for class incre- mental learning
Zhiyuan Hu, Yunsheng Li, Jiancheng Lyu, Dashan Gao, and Nuno Vasconcelos. Dense network expansion for class incre- mental learning. InCVPR, 2023. 2
2023
-
[22]
Birt: Bio-inspired replay in vision transformers for continual learning.ICML, 2023
Kishaan Jeeveswaran, Prashant Bhat, Bahram Zonooz, and Elahe Arani. Birt: Bio-inspired replay in vision transformers for continual learning.ICML, 2023. 2
2023
-
[23]
Vi- sual prompt tuning
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Vi- sual prompt tuning. InEuropean Conference on Computer Vision, pages 709–727. Springer, 2022. 1, 2
2022
-
[24]
An adaptive policy to employ sharpness-aware minimization
Weisen Jiang, Hansi Yang, Yu Zhang, and James Kwok. An adaptive policy to employ sharpness-aware minimization. arXiv preprint arXiv:2304.14647, 2023. 5, 2
-
[25]
Generating instance-level prompts for rehearsal-free continual learning
Dahuin Jung, Dongyoon Han, Jihwan Bang, and Hwanjun Song. Generating instance-level prompts for rehearsal-free continual learning. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 11847–11857,
-
[26]
Introducing language guidance in prompt-based continual learning
Muhammad Gul Zain Ali Khan, Muhammad Ferjad Naeem, Luc Van Gool, Didier Stricker, Federico Tombari, and Muhammad Zeshan Afzal. Introducing language guidance in prompt-based continual learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11463–11473, 2023. 1, 2
2023
-
[27]
Self-regulating prompts: Foundational model adap- tation without forgetting
Muhammad Uzair Khattak, Syed Talal Wasim, Muzammal Naseer, Salman Khan, Ming-Hsuan Yang, and Fahad Shahbaz Khan. Self-regulating prompts: Foundational model adap- tation without forgetting. InProceedings of the IEEE/CVF 9 International Conference on Computer Vision, pages 15190– 15200, 2023. 1, 2
2023
-
[28]
Warping the space: Weight space rotation for class- incremental few-shot learning
Do-Yeon Kim, Dong-Jun Han, Jun Seo, and Jaekyun Moon. Warping the space: Weight space rotation for class- incremental few-shot learning. InICLR, 2022. 2
2022
-
[29]
Overcoming catastrophic forgetting in neural networks
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. PNAS, 2017. 2
2017
-
[30]
Yajing Kong, Liu Liu, Huanhuan Chen, Janusz Kacprzyk, and Dacheng Tao. Overcoming catastrophic forgetting in continual learning by exploring eigenvalues of hessian ma- trix.IEEE Transactions on Neural Networks and Learning Systems, 35(11):16196–16210, 2024. 1
2024
-
[31]
Learning multiple layers of features from tiny images.Technical report, 2009
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images.Technical report, 2009. 6
2009
-
[32]
Learning without forgetting
Zhizhong Li and Derek Hoiem. Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell., 40(12):2935–2947,
-
[33]
Pcr: Proxy-based contrastive replay for online class-incremental continual learning
Huiwei Lin, Baoquan Zhang, Shanshan Feng, Xutao Li, and Yunming Ye. Pcr: Proxy-based contrastive replay for online class-incremental continual learning. InCVPR, 2023. 2
2023
-
[34]
Trgp: Trust region gradient projection for continual learning.arXiv preprint arXiv:2202.02931, 2022
Sen Lin, Li Yang, Deliang Fan, and Junshan Zhang. Trgp: Trust region gradient projection for continual learning.arXiv preprint arXiv:2202.02931, 2022. 2
-
[35]
Adaptive ag- gregation networks for class-incremental learning
Yaoyao Liu, Bernt Schiele, and Qianru Sun. Adaptive ag- gregation networks for class-incremental learning. InCVPR,
-
[36]
Towards efficient and scalable sharpness-aware minimization
Yong Liu, Siqi Mai, Xiangning Chen, Cho-Jui Hsieh, and Yang You. Towards efficient and scalable sharpness-aware minimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12360– 12370, 2022. 1, 2, 4, 5, 8
2022
-
[37]
Continual gui agents.arXiv preprint arXiv:2601.20732, 2026
Ziwei Liu, Borui Kang, Hangjie Yuan, Zixiang Zhao, Wei Li, Yifan Zhu, and Tao Feng. Continual gui agents.arXiv preprint arXiv:2601.20732, 2026. 1
-
[38]
McDonnell, Dong Gong, Amin Parvaneh, Ehsan Abbasnejad, and Anton van den Hengel
Mark D. McDonnell, Dong Gong, Amin Parvaneh, Ehsan Abbasnejad, and Anton van den Hengel. Ranpac: Random projections and pre-trained models for continual learning. In Advances in Neural Information Processing Systems, pages 12022–12053. Curran Associates, Inc., 2023. 2, 6, 7
2023
-
[39]
An empirical investigation of the role of pre-training in lifelong learning.J
Sanket Vaibhav Mehta, Darshan Patil, Sarath Chandar, and Emma Strubell. An empirical investigation of the role of pre-training in lifelong learning.J. Mach. Learn. Res., 2023. 1
2023
-
[40]
Alife: Adaptive logit regularizer and feature replay for incremental semantic segmentation.NeurIPS, 2022
Youngmin Oh, Donghyeon Baek, and Bumsub Ham. Alife: Adaptive logit regularizer and feature replay for incremental semantic segmentation.NeurIPS, 2022. 2
2022
-
[41]
Train with perturbation, infer after merging: A two-stage framework for continual learning
Haomiao Qiu, Miao Zhang, Ziyue Qiao, and Liqiang Nie. Train with perturbation, infer after merging: A two-stage framework for continual learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 1
2025
-
[42]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InCVPR, 2017. 2, 6, 7, 8
2017
-
[43]
Experience replay for continual learning
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy Lil- licrap, and Gregory Wayne. Experience replay for continual learning. InNeurIPS, 2019. 2
2019
-
[44]
Continual learning via sequential function-space variational inference
Tim GJ Rudner, Freddie Bickford Smith, Qixuan Feng, Yee Whye Teh, and Yarin Gal. Continual learning via sequential function-space variational inference. InInter- national Conference on Machine Learning, pages 18871– 18887. PMLR, 2022. 2
2022
-
[45]
Gradient pro- jection memory for continual learning
Gobinda Saha, Isha Garg, and Kaushik Roy. Gradient pro- jection memory for continual learning. InInternational Con- ference on Learning Representations, 2020. 2
2020
-
[46]
Overcoming catastrophic forgetting with hard attention to the task
Joan Serr `a, Didac Suris, Marius Miron, and Alexandros Karatzoglou. Overcoming catastrophic forgetting with hard attention to the task. InICML, pages 4555–4564, 2018. 2
2018
-
[47]
Overcoming catastrophic forget- ting in incremental few-shot learning by finding flat minima
Guangyuan Shi, Jiaxin Chen, Wenlong Zhang, Li-Ming Zhan, and Xiao-Ming Wu. Overcoming catastrophic forget- ting in incremental few-shot learning by finding flat minima. NeurIPS, 2021. 1, 2
2021
-
[48]
Woodfisher: Efficient second-order approximation for neural network compres- sion.Advances in Neural Information Processing Systems, 33:18098–18109, 2020
Sidak Pal Singh and Dan Alistarh. Woodfisher: Efficient second-order approximation for neural network compres- sion.Advances in Neural Information Processing Systems, 33:18098–18109, 2020. 3
2020
-
[49]
Coda-prompt: Contin- ual decomposed attention-based prompting for rehearsal-free continual learning
James Seale Smith, Leonid Karlinsky, Vyshnavi Gutta, Paola Cascante-Bonilla, Donghyun Kim, Assaf Arbelle, Rameswar Panda, Rogerio Feris, and Zsolt Kira. Coda-prompt: Contin- ual decomposed attention-based prompting for rehearsal-free continual learning. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 11909–1191...
2023
-
[50]
Decoupling learning and remembering: A bilevel memory framework with knowledge projection for task-incremental learning
Wenju Sun, Qingyong Li, Jing Zhang, Wen Wang, and Yangli-ao Geng. Decoupling learning and remembering: A bilevel memory framework with knowledge projection for task-incremental learning. InCVPR, 2023. 2
2023
-
[51]
Regularizing second-order influences for continual learning
Zhicheng Sun, Yadong Mu, and Gang Hua. Regularizing second-order influences for continual learning. InCVPR,
-
[52]
When prompt-based incremental learning does not meet strong pre- training
Yu-Ming Tang, Yi-Xing Peng, and Wei-Shi Zheng. When prompt-based incremental learning does not meet strong pre- training. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 1706–1716, 2023. 1, 2
2023
-
[53]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Per- ona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011. 6
2011
-
[54]
A comprehensive survey of continual learning: Theory, method and application.IEEE transactions on pattern analysis and machine intelligence, 46(8):5362–5383, 2024
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE transactions on pattern analysis and machine intelligence, 46(8):5362–5383, 2024. 1, 2
2024
-
[55]
S-prompts learning with pre-trained transformers: An occam’s razor for domain incremental learning.Advances in Neural Informa- tion Processing Systems, 35:5682–5695, 2022
Yabin Wang, Zhiwu Huang, and Xiaopeng Hong. S-prompts learning with pre-trained transformers: An occam’s razor for domain incremental learning.Advances in Neural Informa- tion Processing Systems, 35:5682–5695, 2022. 2
2022
-
[56]
Isolation and impartial aggre- gation: A paradigm of incremental learning without interfer- ence
Yabin Wang, Zhiheng Ma, Zhiwu Huang, Yaowei Wang, Zhou Su, and Xiaopeng Hong. Isolation and impartial aggre- gation: A paradigm of incremental learning without interfer- ence. InProceedings of the AAAI Conference on Artificial Intelligence, pages 10209–10217, 2023. 2 10
2023
-
[57]
Learning to prompt for continual learning
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jen- nifer Dy, and Tomas Pfister. Learning to prompt for continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 139–149,
-
[58]
DER: dynam- ically expandable representation for class incremental learn- ing
Shipeng Yan, Jiangwei Xie, and Xuming He. DER: dynam- ically expandable representation for class incremental learn- ing. InCVPR, pages 3014–3023, 2021. 2
2021
-
[59]
Scalable and order-robust continual learning with additive parameter decomposition
Jaehong Yoon, Saehoon Kim, Eunho Yang, and Sung Ju Hwang. Scalable and order-robust continual learning with additive parameter decomposition. InInternational Confer- ence on Learning Representations, 2020. 2
2020
-
[60]
Slca: Slow learner with classifier align- ment for continual learning on a pre-trained model
Gengwei Zhang, Liyuan Wang, Guoliang Kang, Ling Chen, and Yunchao Wei. Slca: Slow learner with classifier align- ment for continual learning on a pre-trained model. InPro- ceedings of the IEEE/CVF International Conference on Com- puter Vision, pages 19148–19158, 2023. 2
2023
-
[61]
Gradient norm aware minimization seeks first-order flatness and improves generalization
Xingxuan Zhang, Renzhe Xu, Han Yu, Hao Zou, and Peng Cui. Gradient norm aware minimization seeks first-order flatness and improves generalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20247–20257, 2023. 1, 3, 6, 4
2023
-
[62]
Penalizing gra- dient norm for efficiently improving generalization in deep learning
Yang Zhao, Hao Zhang, and Xiuyuan Hu. Penalizing gra- dient norm for efficiently improving generalization in deep learning. InInternational Conference on Machine Learning, pages 26982–26992. PMLR, 2022. 3
2022
-
[63]
Yang Zhao, Hao Zhang, and Xiuyuan Hu. Ss-sam: Stochastic scheduled sharpness-aware minimization for efficiently train- ing deep neural networks.ArXiv, abs/2203.09962, 2022. 5, 2
-
[64]
Improving sharpness-aware minimization with fisher mask for better generalization on language models
Qihuang Zhong, Liang Ding, Li Shen, Peng Mi, Juhua Liu, Bo Du, and Dacheng Tao. Improving sharpness-aware min- imization with fisher mask for better generalization on lan- guage models.arXiv preprint arXiv:2210.05497, 2022. 1
-
[65]
Pycil: A python toolbox for class-incremental learning,
Da-Wei Zhou, Fu-Yun Wang, Han-Jia Ye, and De-Chuan Zhan. Pycil: A python toolbox for class-incremental learning,
-
[66]
Deep class-incremental learning: A survey.arXiv preprint arXiv:2302.03648, 2023
Da-Wei Zhou, Qi-Wei Wang, Zhi-Hong Qi, Han-Jia Ye, De- Chuan Zhan, and Ziwei Liu. Deep class-incremental learning: A survey.arXiv preprint arXiv:2302.03648, 2023. 1, 6
-
[67]
A model or 603 exemplars: Towards memory-efficient class-incremental learning.ICLR, 2023
Da-Wei Zhou, Qi-Wei Wang, Han-Jia Ye, and De-Chuan Zhan. A model or 603 exemplars: Towards memory-efficient class-incremental learning.ICLR, 2023. 2, 6, 7, 8
2023
-
[68]
Learning without forgetting for vision-language models.arXiv preprint arXiv:2305.19270,
Da-Wei Zhou, Yuanhan Zhang, Jingyi Ning, Han-Jia Ye, De- Chuan Zhan, and Ziwei Liu. Learning without forgetting for vision-language models.arXiv preprint arXiv:2305.19270,
-
[69]
Revisiting class-incremental learning with pre- trained models: Generalizability and adaptivity are all you need.International Journal of Computer Vision, 2024
Da-Wei Zhou, Zi-Wen Cai, Han-Jia Ye, De-Chuan Zhan, and Ziwei Liu. Revisiting class-incremental learning with pre- trained models: Generalizability and adaptivity are all you need.International Journal of Computer Vision, 2024. 2, 6
2024
-
[70]
Continual learning with pre-trained models: A survey.arXiv preprint arXiv:2401.16386,
Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, and De-Chuan Zhan. Continual learning with pre-trained models: A survey.arXiv preprint arXiv:2401.16386, 2024. 1, 2, 6
-
[71]
Da-Wei Zhou, Hai-Long Sun, Han-Jia Ye, and De-Chuan Zhan. Expandable subspace ensemble for pre-trained model-based class-incremental learning.arXiv preprint arXiv:2403.12030, 2024. 2, 6, 7, 8
-
[72]
Zhanpeng Zhou, Mingze Wang, Yuchen Mao, Bingrui Li, and Junchi Yan. Sharpness-aware minimization efficiently selects flatter minima late in training.arXiv preprint arXiv:2410.10373, 2024. 2
-
[73]
Prototype augmentation and self-supervision for incremental learning
Fei Zhu, Xu-Yao Zhang, Chuang Wang, Fei Yin, and Cheng- Lin Liu. Prototype augmentation and self-supervision for incremental learning. InCVPR, pages 5871–5880, 2021. 2
2021
-
[74]
Self-sustaining representation expansion for non-exemplar class-incremental learning
Kai Zhu, Wei Zhai, Yang Cao, Jiebo Luo, and Zheng-Jun Zha. Self-sustaining representation expansion for non-exemplar class-incremental learning. InCVPR, 2022. 2
2022
-
[75]
Surrogate gap minimization improves sharpness-aware training.arXiv preprint arXiv:2203.08065,
Juntang Zhuang, Boqing Gong, Liangzhe Yuan, Yin Cui, Hartwig Adam, Nicha Dvornek, Sekhar Tatikonda, James Duncan, and Ting Liu. Surrogate gap minimization improves sharpness-aware training.arXiv preprint arXiv:2203.08065,
-
[76]
Appendix A.1
1 11 A. Appendix A.1. Symbols and Notations of C-Flat Turbo •model parameter:𝜽; •SAM perturbed model parameter:𝜽+𝝐 ∗ 0 =𝜽+𝜌· ∇ L (𝜽) ∥ ∇ L (𝜽) ∥; •proxy model parameter:𝜽+𝝐 ∗ 1 =𝜽+𝜌· (𝒈 𝑠 −𝒈)/∥𝒈 𝑠 −𝒈∥; •proxy perturbed model parameter:𝜽+𝝐 ∗ 1 +𝜌· ∇L (𝜽+ 𝝐 ∗ 1)/∥∇L (𝜽+𝝐 ∗
-
[77]
∥; •the empirical loss:L (𝜽), with its gradient𝒈; •the SAM loss:L 𝑆 𝐴𝑀 (𝜽)=L (𝜽) + R 0 𝜌 (𝜽)= max∥𝝐 0 ∥ ≤𝜌 L (𝜽+𝝐 0)with its gradient𝒈 𝑠; •the C-Flat loss:L 𝐶𝐹𝑙𝑎𝑡 (𝜽)=L (𝜽) + R 0 𝜌 (𝜽) +𝜆· R 1 𝜌 (𝜽)= max∥𝝐 0 ∥ ≤𝜌 L (𝜽+𝝐 0) +𝜆·𝜌max ∥𝝐 1 ∥ ≤𝜌 ∇L (𝜽+𝝐 1) , with its gradient𝒈 𝑠 +𝜆𝒈 𝑓 ; •the gradient of proxy model:𝒈 0 =∇L (𝜽+𝝐 ∗ 1); •the gradient of proxy per...
-
[78]
∥); •the empirical loss term:𝒈=∇L (𝜽); •the zeroth-order sharpness term:𝒈 𝑠 −𝒈=∇R 0 𝜌 (𝜽); •the first-order flatness term:𝒈 𝑓 =∇R 1 𝜌 (𝜽); •the direction-invariant sharpness component:𝒈 𝑣𝑠 =𝒈 𝑠 − ⟨𝒈 𝑠 ,𝒈⟩ ∥𝒈∥ 2 𝒈; •the direction-invariant flatness component:𝒈 𝑣 𝑓 =𝒈 𝑓 − ⟨𝒈 𝑓 ,𝒈0 ⟩ ∥𝒈 0 ∥2 𝒈0. A.2. Derivation of Equation 5 Following [6, 61], the gradient o...
-
[79]
∥ =𝜌· 𝜕 𝜕𝜽 ∥∇L (𝜽+𝝐 ∗
-
[80]
∥ + 𝜕𝝐 ∗ 1 𝜕𝜽 · ∇𝝐 ∥∇L (𝜽+𝝐) ∥ 𝝐=𝝐 ∗ 1 ≈𝜌· ∇ 𝜽 ∥∇L (𝜽+𝝐 ∗
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.