Recognition: unknown
Contexty: Capturing and Organizing In-situ Thoughts for Context-Aware AI Support
Pith reviewed 2026-05-10 15:59 UTC · model grok-4.3
The pith
Contexty lets users capture and refine their in-situ thoughts as inspectable context for AI support.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Contexty supports in-situ snippet memoing to capture cognitive moves during tasks and supplies inspection and refinement tools so users can align accumulated contexts with their understanding, producing AI responses grounded in those user-controlled contexts and yielding higher task awareness plus preference for grounded outputs.
What carries the argument
In-situ snippet memoing to record cognitive traces, followed by user inspection and refinement interfaces that turn scattered notes into structured, revisable AI context.
If this is right
- AI responses become directly linked to specific user-captured thoughts rather than inferred summaries.
- Users retain authorship and control by editing the context the AI sees.
- Explicit capture and organization steps improve users' own task awareness and thought structure.
- Most users favor responses built from their snippets, indicating higher perceived relevance.
Where Pith is reading between the lines
- The same capture-and-refine loop could extend to creative or programming work where thoughts evolve over hours or days.
- If contexts are saved across sessions, they might serve as personal knowledge bases that grow with the user.
- Providing explicit user-verified context could lower the rate of AI responses that misalign with the user's actual intent.
Load-bearing premise
Users will capture meaningful thoughts as snippets without major task interruption and will inspect and refine the contexts to keep them accurate.
What would settle it
A controlled comparison in which Contexty users show no gain in task awareness or report higher interruption than users of ordinary AI chat tools.
Figures







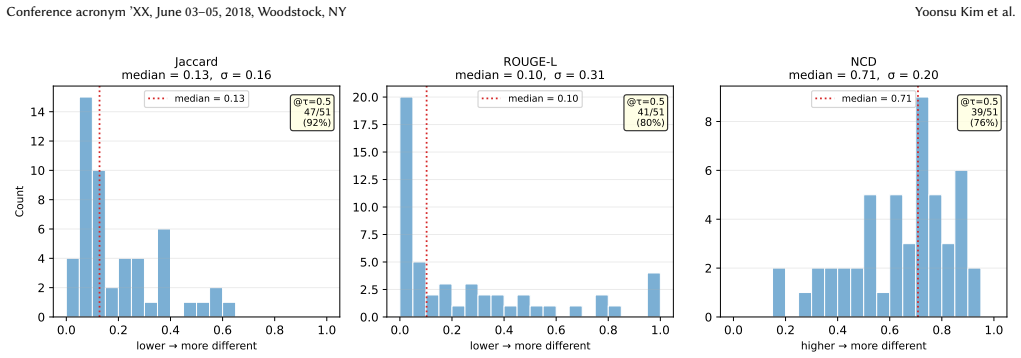
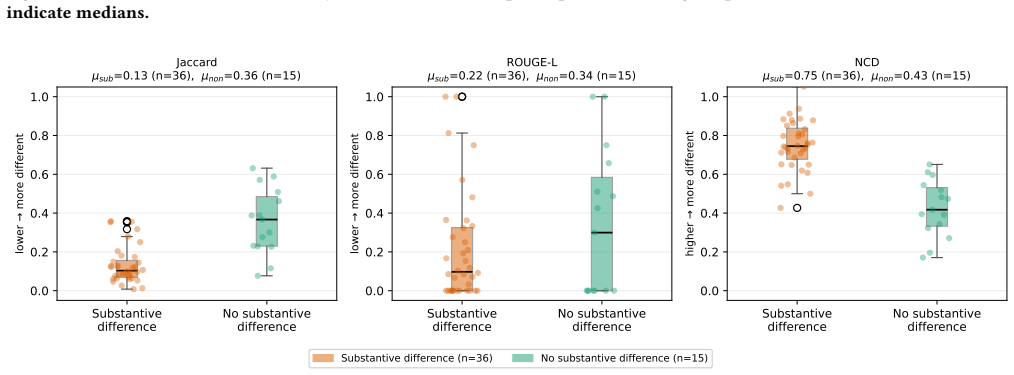

read the original abstract
During complex knowledge work, people engage in iterative sensemaking: interpreting information, connecting ideas, and refining their understanding. Yet in current human-AI collaboration, these cognitive processes are difficult to share and organize for AI. They arise in situ and are rarely captured without interrupting the task, and even when expressed, remain scattered or reduced to system-generated summaries that fail to reflect users' cognitive processes. We address this challenge by enabling AI context that is grounded in users' cognitive traces and can be directly inspected and revised by the user. We first explore this through a probe system that supports in-situ snippet memoing, allowing users to easily share their cognitive moves. Our study (N=10) highlights the value of capturing such context and the challenge of organizing it once accumulated. We then present Contexty, which supports users in inspecting and refining these contexts to better reflect their understanding of the task. Our evaluation (N=12) showed that Contexty improved task awareness, thought structuring, and users' sense of authorship and control, with participants preferring snippet-grounded AI responses over non-grounded ones (78.1%). We discuss how capturing and organizing users' cognitive context enables AI as a context-aware collaborator while preserving user agency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Contexty, a system for capturing users' in-situ cognitive traces via snippet memoing during knowledge work, enabling users to inspect, refine, and organize these contexts for grounding AI responses. A probe study (N=10) explores the value of capture and the challenge of organization; an evaluation study (N=12) reports that Contexty improves task awareness, thought structuring, authorship, and control, with 78.1% preference for snippet-grounded AI responses over non-grounded ones. The work emphasizes preserving user agency in human-AI collaboration.
Significance. If the evaluation findings hold under more rigorous controls, the contribution lies in demonstrating a practical mechanism for user-controlled cognitive context in AI systems, which could support more faithful sensemaking assistance while mitigating risks of opaque or misaligned AI outputs. The probe-to-system progression and focus on inspectability are constructive steps toward context-aware tools that treat users as active authors of their AI context.
major comments (1)
- [Evaluation study] Evaluation (N=12): The headline claims of improved task awareness, thought structuring, authorship/control, and 78.1% preference for grounded responses rest on the untested assumption that in-situ snippet memoing produces faithful cognitive traces without material task interruption or bias. No time-on-task comparisons, error-rate measures, post-hoc fidelity checks (e.g., whether snippets matched actual reasoning), or usage logs of context inspection/revision are reported, so benefits cannot be confidently attributed to Contexty rather than externalization itself.
minor comments (2)
- [Abstract] Abstract and evaluation summary: Specific measures, scales, statistical tests, and potential confounds (e.g., order effects, individual differences in memoing behavior) are not described, which limits assessment of the quantitative preference result.
- [Probe study] The probe study (N=10) is summarized only at a high level; adding even brief quantitative indicators of capture frequency or organization effort would strengthen the motivation for Contexty's design features.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address the major comment on the evaluation study below and will revise the paper to incorporate clarifications and expanded discussion of limitations.
read point-by-point responses
-
Referee: [Evaluation study] Evaluation (N=12): The headline claims of improved task awareness, thought structuring, authorship/control, and 78.1% preference for grounded responses rest on the untested assumption that in-situ snippet memoing produces faithful cognitive traces without material task interruption or bias. No time-on-task comparisons, error-rate measures, post-hoc fidelity checks (e.g., whether snippets matched actual reasoning), or usage logs of context inspection/revision are reported, so benefits cannot be confidently attributed to Contexty rather than externalization itself.
Authors: We appreciate the referee highlighting the need for stronger evidence on attribution. Our evaluation used a within-subjects design comparing Contexty (with user-authored snippets for grounding) against a baseline without snippet grounding for AI responses. The 78.1% preference directly contrasts the two conditions on the same tasks, isolating the contribution of user-controlled snippets over general externalization. We did not collect time-on-task or error-rate data because the tasks were open-ended knowledge work without objective correctness criteria or fixed endpoints. Snippet fidelity was not post-hoc verified because the system positions users as authors who create and edit snippets themselves; the traces are therefore user-defined by design. We did log snippet creation, editing, and AI query events during the study and can report aggregate usage statistics (e.g., frequency of context inspection) in a revision. We will add an expanded Limitations subsection that explicitly discusses the absence of these objective measures, potential task-interruption effects, and the exploratory nature of the N=12 study, while clarifying how the preference result helps attribute benefits to the grounded context. revision: partial
Circularity Check
No circularity: system description and user study results are independent of any self-referential derivation
full rationale
The paper describes a probe system and Contexty tool for capturing cognitive traces via in-situ snippet memoing, followed by two user studies (N=10 and N=12) reporting qualitative improvements and a 78.1% preference rate. No equations, fitted parameters, uniqueness theorems, or self-citations appear as load-bearing steps in the provided text. Evaluation outcomes rest on direct participant feedback rather than any reduction of predictions to inputs by construction. The central claims about improved awareness and agency are externally anchored in the study data and do not collapse into definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption During complex knowledge work, people engage in iterative sensemaking that is difficult to share with current AI systems.
- ad hoc to paper In-situ snippet memoing can capture cognitive processes without major task interruption.
invented entities (1)
-
Contexty system
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2022.How to take smart notes: One simple technique to boost writing, learning and thinking
Sönke Ahrens. 2022.How to take smart notes: One simple technique to boost writing, learning and thinking. Sönke Ahrens
2022
-
[2]
Anthropic. 2025. How Claude Code works - Claude Code Docs. https://code. claude.com/docs/en/how-claude-code-works [Accessed 2026-03-31]
2025
-
[3]
Stephen Brade, Bryan Wang, Mauricio Sousa, Sageev Oore, and Tovi Gross- man. 2023. Promptify: Text-to-image generation through interactive prompt exploration with large language models. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. 1–14
2023
-
[4]
Janis A Cannon-Bowers, Eduardo Salas, and Sharolyn Converse. 1993. Shared mental models in expert team decision making. (1993)
1993
-
[5]
James M Clark and Allan Paivio. 1991. Dual coding theory and education.Edu- cational psychology review3, 3 (1991), 149–210
1991
-
[6]
Dia. [n. d.]. Dia Browser | AI Chat With Your Tabs. https://www.diabrowser.com/ [Accessed 2026-03-31]
2026
-
[7]
[Accessed 2026-03-31]
Electron. [n. d.]. Build cross-platform desktop apps with JavaScript, HTML, and CSS | Electron. https://www.electronjs.org/ "[Accessed 2026-03-31]"
2026
-
[8]
Frederic Gmeiner, Nicolai Marquardt, Michael Bentley, Hugo Romat, Michel Pahud, David Brown, Asta Roseway, Nikolas Martelaro, Kenneth Holstein, Ken Hinckley, and Nathalie Riche. 2025. Intent Tagging: Exploring Micro-Prompting Interactions for Supporting Granular Human-GenAI Co-Creation Workflows. In Proceedings of the 2025 CHI Conference on Human Factors ...
- [9]
-
[10]
Kostas Hatalis, Despina Christou, Joshua Myers, Steven Jones, Keith Lambert, Adam Amos-Binks, Zohreh Dannenhauer, and Dustin Dannenhauer. 2023. Mem- ory matters: The need to improve long-term memory in llm-agents. InProceedings of the AAAI Symposium Series, Vol. 2. 277–280
2023
-
[11]
James Hollan, Edwin Hutchins, and David Kirsh. 2000. Distributed cognition: toward a new foundation for human-computer interaction research.ACM Trans. Comput.-Hum. Interact.7, 2 (June 2000), 174–196. https://doi.org/10.1145/353485. 353487
-
[12]
Jeremy Howard. [n. d.]. The /llms.txt file – llms-txt. https://llmstxt.org/ [Accessed 2026-03-31]
2026
-
[13]
Peiling Jiang, Jude Rayan, Steven P Dow, and Haijun Xia. 2023. Graphologue: Exploring large language model responses with interactive diagrams. InProceed- ings of the 36th annual ACM symposium on user interface software and technology. 1–20
2023
- [14]
- [15]
-
[16]
Lasecki, Tovi Grossman, and George Fitzmaurice
Rebecca Krosnick, Fraser Anderson, Justin Matejka, Steve Oney, Walter S. Lasecki, Tovi Grossman, and George Fitzmaurice. 2021. Think-aloud computing: Sup- porting rich and low-effort knowledge capture. InProceedings of the 2021 CHI conference on human factors in computing systems. 1–13
2021
-
[17]
Andrew Kuznetsov, Joseph Chee Chang, Nathan Hahn, Napol Rachatasumrit, Bradley Breneisen, Julina Coupland, and Aniket Kittur. 2022. Fuse: In-Situ sense- making support in the browser. InProceedings of the 35th Annual ACM Symposium on User Interface Software and Technology. 1–15
2022
-
[18]
Michelle S Lam, Fred Hohman, Dominik Moritz, Jeffrey P Bigham, Kenneth Hol- stein, and Mary Beth Kery. 2025. Policy Maps: Tools for Guiding the Unbounded Space of LLM Behaviors. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. 1–24
2025
- [19]
- [20]
- [21]
- [22]
-
[23]
Catherine C Marshall. 1997. Annotation: from paper books to the digital library. InProceedings of the second ACM international conference on Digital libraries. 131–140
1997
-
[24]
John E Mathieu, Tonia S Heffner, Gerald F Goodwin, Eduardo Salas, and Janis A Cannon-Bowers. 2000. The influence of shared mental models on team process and performance.Journal of applied psychology85, 2 (2000), 273
2000
-
[25]
Lingrui Mei, Jiayu Yao, Yuyao Ge, Yiwei Wang, Baolong Bi, Yujun Cai, Jiazhi Liu, Mingyu Li, Zhong-Zhi Li, Duzhen Zhang, et al. 2025. A survey of context engineering for large language models.arXiv preprint arXiv:2507.13334(2025)
work page internal anchor Pith review arXiv 2025
-
[26]
1991.Cognitive Artifacts
Donald Norman. 1991.Cognitive Artifacts. 333
1991
-
[27]
OpenAI. [n. d.]. ChatGPT Atlas. https://chatgpt.com/atlas/ [Accessed 2026-03- 31]
2026
- [28]
-
[29]
Perplexity. [n. d.]. Comet Browser: a Personal AI Assistant. https://www. perplexity.ai/comet [Accessed 2026-03-31]
2026
-
[30]
Schön.The Reflective Practitioner: How Professionals Think in Action
Donald A Schön. 1992.The reflective practitioner: How professionals think in action. Routledge. https://doi.org/10.4324/9781315237473
-
[31]
Omar Shaikh, Shardul Sapkota, Shan Rizvi, Eric Horvitz, Joon Sung Park, Diyi Yang, and Michael S. Bernstein. 2025. Creating General User Models from Com- puter Use. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology (UIST ’25). Association for Computing Machinery, New York, NY, USA, Article 35, 23 pages. https://doi.o...
-
[32]
Omar Shaikh, Valentin Teutschbein, Kanishk Gandhi, Yikun Chi, Nick Haber, Thomas Robinson, Nilam Ram, Byron Reeves, Sherry Yang, Michael S. Bernstein, and Diyi Yang. 2026. Learning Next Action Predictors from Human-Computer Interaction. arXiv:2603.05923 [cs.CL] https://arxiv.org/abs/2603.05923
-
[33]
Frank M Shipman III and Catherine C Marshall. 1999. Spatial hypertext: an alternative to navigational and semantic links.ACM Computing Surveys (CSUR) Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Yoonsu Kim et al. 31, 4es (1999), 14–es
1999
-
[34]
Ben Shneiderman. 1983. Direct manipulation: A step beyond programming languages.Computer16, 08 (1983), 57–69
1983
- [35]
-
[36]
Sangho Suh, Meng Chen, Bryan Min, Toby Jia-Jun Li, and Haijun Xia. 2024. Lumi- nate: Structured generation and exploration of design space with large language models for human-ai co-creation. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–26
2024
-
[37]
Sangho Suh, Bryan Min, Srishti Palani, and Haijun Xia. 2023. Sensecape: En- abling multilevel exploration and sensemaking with large language models. In Proceedings of the 36th annual ACM symposium on user interface software and technology. 1–18
2023
-
[38]
Theodore Sumers, Shunyu Yao, Karthik R Narasimhan, and Thomas L Griffiths
-
[39]
Cognitive architectures for language agents.Transactions on Machine Learning Research(2023)
2023
-
[40]
Haoran Sun, Shaoning Zeng, and Bob Zhang. 2026. H-MEM: Hierarchical Memory for High-Efficiency Long-Term Reasoning in LLM Agents. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 341–350
2026
-
[41]
Craig S. Tashman and W. Keith Edwards. 2011. LiquidText: a flexible, multitouch environment to support active reading. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Vancouver, BC, Canada)(CHI ’11). Association for Computing Machinery, New York, NY, USA, 3285–3294. https: //doi.org/10.1145/1978942.1979430
-
[42]
[Accessed 2026-03-31]
tldraw. [n. d.]. tldraw: Infinite Canvas SDK for React. https://tldraw.dev/ "[Accessed 2026-03-31]"
2026
-
[43]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. 2025. OpenHands: An Open Platform for A...
work page internal anchor Pith review arXiv 2025
-
[44]
Zhijie Wang, Yuheng Huang, Da Song, Lei Ma, and Tianyi Zhang. 2024. PromptCharm: Text-to-Image Generation through Multi-modal Prompting and Refinement. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 185, 21 pages. https://doi.org/10...
-
[45]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang
-
[46]
A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110 (2025)
work page internal anchor Pith review arXiv 2025
-
[47]
Bian Yang, Fan Gu, and Xiamu Niu. 2006. Block mean value based image percep- tual hashing. In2006 International Conference on Intelligent Information Hiding and Multimedia. IEEE, 167–172
2006
- [48]
-
[49]
Saelyne Yang, Jaesang Yu, Yi-Hao Peng, Kevin Qinghong Lin, Jae Won Cho, Yale Song, and Juho Kim. 2026. GUIDE: A Benchmark for Understanding and Assisting Users in Open-Ended GUI Tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). To appear
2026
-
[50]
Jiajie Zhang. 1997. The nature of external representations in problem solving. Cognitive science21, 2 (1997), 179–217
1997
-
[51]
Xiaoyu Zhang, Senthil Chandrasegaran, and Kwan-Liu Ma. 2021. Conceptscope: Organizing and visualizing knowledge in documents based on domain ontology. InProceedings of the 2021 chi conference on human factors in computing systems. 1–13
2021
-
[52]
Xiaoyu Zhang, Jianping Li, Po-Wei Chi, Senthil Chandrasegaran, and Kwan-Liu Ma. 2023. ConceptEVA: Concept-based interactive exploration and customization of document summaries. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–16
2023
-
[53]
Zheng Zhang, Weirui Peng, Xinyue Chen, Luke Cao, and Toby Jia-Jun Li. 2025. LADICA: a large shared display interface for generative AI cognitive assistance in co-located team collaboration. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–22
2025
-
[54]
Add to Chat
Dora Zhao, Diyi Yang, and Michael S Bernstein. 2025. Knoll: Creating a knowledge ecosystem for large language models. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. 1–23. Contexty Conference acronym ’XX, June 03–05, 2018, Woodstock, NY A CONTEXT RETRIEV AL FOR CHAT When a user sends a query 𝑞, the system retrieve...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.