Recognition: unknown
CDPR: Cross-modal Diffusion with Polarization for Reliable Monocular Depth Estimation
Pith reviewed 2026-05-10 15:40 UTC · model grok-4.3
The pith
A diffusion model fuses RGB images with polarization measurements through a learnable gate to improve depth estimates on reflective and transparent surfaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CDPR encodes RGB and polarization (AoLP/DoLP) images into a shared latent space with a pre-trained VAE, then applies a learnable confidence-aware gating mechanism to produce an integrated representation that is denoised into a depth map; this selectively suppresses noisy polarization signals while retaining informative cues near reflective or transparent surfaces.
What carries the argument
The learnable confidence-aware gating mechanism that adaptively fuses RGB and polarization latent features before the diffusion denoising steps.
If this is right
- Depth accuracy improves in textureless, transparent, and specular regions compared with RGB-only diffusion models.
- Performance remains competitive with RGB-only models on ordinary scenes.
- The same gated latent fusion works for surface normal prediction after minimal retraining.
- The framework supports other polarization-guided dense prediction tasks without redesign of the core diffusion pipeline.
Where Pith is reading between the lines
- Similar gating could let polarization improve other single-image tasks such as segmentation or optical flow in adverse lighting.
- If the polarization cues prove robust across cameras, the method could reduce reliance on active sensors like LiDAR for indoor or automotive depth.
- The latent-space fusion pattern may generalize to other cross-modal pairs where one modality is noisier than the other.
Load-bearing premise
Polarization measurements supply stable physical cues in hard regions that a gating network can selectively use without adding new errors or needing extra calibration.
What would settle it
A controlled test on real scenes with ground-truth depth in highly specular or transparent areas that shows the gated model produces larger errors than an RGB-only diffusion baseline.
Figures




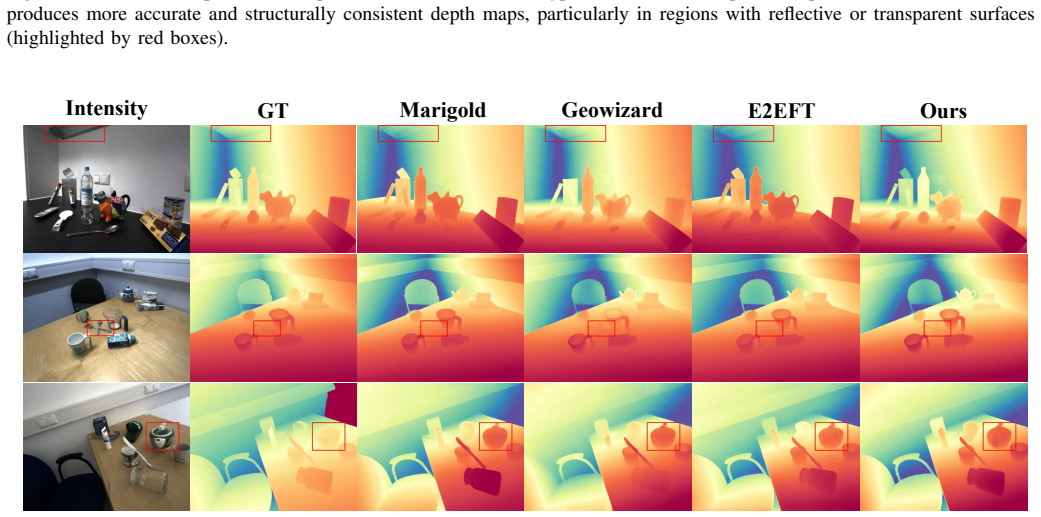
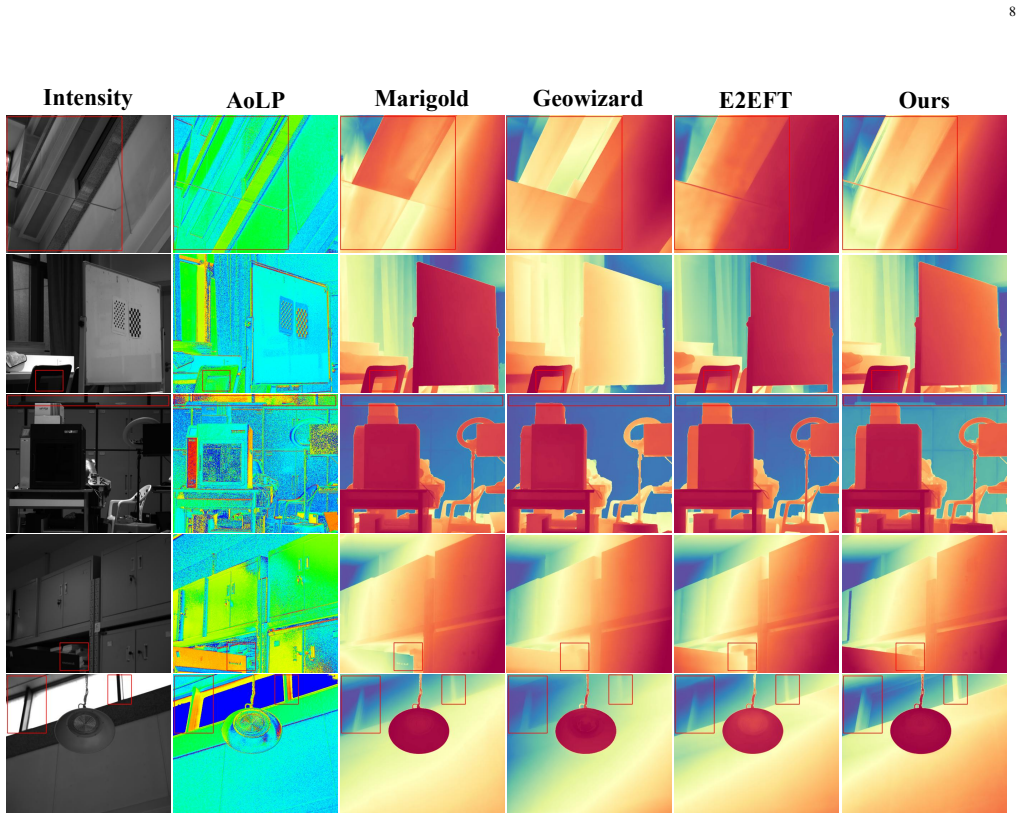


read the original abstract
Monocular depth estimation is a fundamental yet challenging task in computer vision, especially under complex conditions such as textureless surfaces, transparency, and specular reflections. Recent diffusion-based approaches have significantly advanced performance by reformulating depth prediction as a denoising process in the latent space. However, existing methods rely solely on RGB inputs, which often lack sufficient cues in challenging regions. In this work, we present CDPR - Cross-modal Diffusion with Polarization for Reliable Monocular Depth Estimation - a novel diffusion-based framework that integrates physically grounded polarization priors to enhance estimation robustness. Specifically, we encode both RGB and polarization (AoLP/DoLP) images into a shared latent space via a pre-trained Variational Autoencoder (VAE), and dynamically fuse multi-modal information through a learnable confidence-aware gating mechanism. This fusion module adaptively suppresses noisy signals in polarization inputs while preserving informative cues, particularly around reflective or transparent surfaces, and provides the integrated latent representation for subsequent monocular depth estimation. Beyond depth estimation, we further verify that our framework can be easily generalized to surface normal prediction with minimal modification, showcasing its scalability to general polarization-guided dense prediction tasks. Experiments on both synthetic and real-world datasets validate that CDPR significantly outperforms RGB-only baselines in challenging regions while maintaining competitive performance in standard scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CDPR, a cross-modal diffusion framework for monocular depth estimation that encodes RGB and polarization (AoLP/DoLP) images into a shared latent space using a pre-trained VAE, fuses them via a learnable confidence-aware gating mechanism to suppress noise while preserving cues in challenging regions (textureless, specular, transparent surfaces), and performs depth prediction as a denoising process. It claims significant outperformance over RGB-only baselines on synthetic and real datasets in difficult areas while remaining competitive elsewhere, with easy generalization to surface normal prediction.
Significance. If the quantitative results and ablations hold, the work offers a concrete way to inject physically grounded polarization priors into latent diffusion pipelines for more reliable dense prediction, which could benefit downstream tasks in robotics and AR/VR where RGB cues fail. The gating fusion and cross-task generalization are potentially reusable ideas.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the central construction encodes AoLP/DoLP via a pre-trained RGB VAE into the same latent space as RGB before gating and diffusion. Because AoLP is periodic (0–π) and DoLP is bounded [0,1] with statistics far from natural images, the resulting latents are likely distorted; the paper must demonstrate (via latent-space visualizations, reconstruction error, or ablation replacing the VAE) that physical polarization priors survive this mapping rather than being irrecoverably lost before the gating stage.
- [Abstract and §4] Abstract and §4 (experiments): the claim of 'significant outperformance' in challenging regions is asserted without any reported metrics, error breakdowns, or ablation tables in the provided abstract. The full experiments section must include quantitative comparisons (e.g., AbsRel, RMSE on textureless/specular subsets), ablation of the gating module, and analysis of polarization noise/calibration effects on real data to substantiate the load-bearing robustness claim.
minor comments (2)
- [Abstract] Abstract: the phrase 'provides the integrated latent representation for subsequent monocular depth estimation' is redundant with the preceding sentence and could be tightened.
- [§3] Notation: AoLP/DoLP are introduced without explicit definition of their ranges or preprocessing steps before VAE encoding; a short paragraph or figure in §3 would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the central construction encodes AoLP/DoLP via a pre-trained RGB VAE into the same latent space as RGB before gating and diffusion. Because AoLP is periodic (0–π) and DoLP is bounded [0,1] with statistics far from natural images, the resulting latents are likely distorted; the paper must demonstrate (via latent-space visualizations, reconstruction error, or ablation replacing the VAE) that physical polarization priors survive this mapping rather than being irrecoverably lost before the gating stage.
Authors: We recognize the referee's concern about potential distortion in the latent space due to the differing statistical properties of polarization images compared to natural RGB images. Our approach relies on the pre-trained VAE to project both modalities into a shared space, allowing the gating mechanism to integrate them effectively. To validate that polarization priors are not lost, we will incorporate latent-space visualizations (e.g., t-SNE or PCA projections of latents from RGB and polarization), report reconstruction errors for DoLP/AoLP inputs, and conduct an ablation where we replace the shared VAE with a polarization-specific encoder. This will demonstrate the survival of physical cues and justify our design choice. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (experiments): the claim of 'significant outperformance' in challenging regions is asserted without any reported metrics, error breakdowns, or ablation tables in the provided abstract. The full experiments section must include quantitative comparisons (e.g., AbsRel, RMSE on textureless/specular subsets), ablation of the gating module, and analysis of polarization noise/calibration effects on real data to substantiate the load-bearing robustness claim.
Authors: The abstract provides a high-level summary, while the detailed quantitative results are presented in Section 4 of the manuscript. To more thoroughly substantiate the claims of outperformance in challenging regions, we will revise the experiments section to include: (1) quantitative metrics (AbsRel, RMSE, etc.) broken down by scene types such as textureless, specular, and transparent surfaces; (2) a comprehensive ablation study isolating the contribution of the confidence-aware gating module; and (3) an analysis of the impact of polarization noise and calibration variations on real-world data performance. These additions will provide stronger evidence for the robustness benefits. revision: yes
Circularity Check
No circularity: framework uses external pre-trained VAE and independent dataset validation
full rationale
The abstract and described method encode RGB and polarization inputs via a pre-trained VAE (external to the current work), apply a learnable gating module, and feed the result into a diffusion denoiser for depth prediction. No equation or step reduces by construction to a fitted parameter renamed as prediction, nor does any load-bearing claim rest on a self-citation chain that itself assumes the target result. Validation occurs on separate synthetic and real-world datasets, keeping the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Polarization images supply physically grounded additional cues for depth estimation around reflective and transparent surfaces.
- domain assumption A pre-trained VAE can encode both RGB and polarization into a shared latent space suitable for diffusion-based prediction.
Reference graph
Works this paper leans on
-
[1]
Rdfnet: Rgb-d multi-level residual feature fusion for indoor semantic segmentation,
S.-J. Park, K.-S. Hong, and S. Lee, “Rdfnet: Rgb-d multi-level residual feature fusion for indoor semantic segmentation,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 4980– 4989
2017
-
[2]
Deep learning for detecting robotic grasps,
I. Lenz, H. Lee, and A. Saxena, “Deep learning for detecting robotic grasps,”The International Journal of Robotics Research, vol. 34, no. 4-5, pp. 705–724, 2015
2015
-
[3]
Real-time human pose recognition in parts from single depth images,
J. Shotton, A. Fitzgibbon, M. Cook, T. Sharp, M. Finocchio, R. Moore, A. Kipman, and A. Blake, “Real-time human pose recognition in parts from single depth images,” inCVPR 2011. Ieee, 2011, pp. 1297–1304
2011
-
[4]
Metric3d: Towards zero-shot metric 3d prediction from a single image,
W. Yin, C. Zhang, H. Chen, Z. Cai, G. Yu, K. Wang, X. Chen, and C. Shen, “Metric3d: Towards zero-shot metric 3d prediction from a single image,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 9043–9053
2023
-
[5]
Depth anything: Unleashing the power of large-scale unlabeled data,
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth anything: Unleashing the power of large-scale unlabeled data,” inPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 10 371–10 381
2024
-
[6]
Depth anything v2,
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,”Advances in Neural Information Processing Sys- tems, vol. 37, pp. 21 875–21 911, 2024
2024
-
[7]
Moge: Unlocking accurate monocular geometry estimation for open- domain images with optimal training supervision,
R. Wang, S. Xu, C. Dai, J. Xiang, Y . Deng, X. Tong, and J. Yang, “Moge: Unlocking accurate monocular geometry estimation for open- domain images with optimal training supervision,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 5261–5271
2025
-
[8]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
R. Wang, S. Xu, Y . Dong, Y . Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, and J. Yang, “Moge-2: Accurate monocular geometry with metric scale and sharp details,”arXiv preprint arXiv:2507.02546, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
Unsupervised monocular depth estimation using attention and multi-warp reconstruction,
C. Ling, X. Zhang, and H. Chen, “Unsupervised monocular depth estimation using attention and multi-warp reconstruction,”IEEE Trans- actions on Multimedia, vol. 24, pp. 2938–2949, 2021
2021
-
[10]
Excavating the potential capacity of self-supervised monocular depth estimation,
R. Peng, R. Wang, Y . Lai, L. Tang, and Y . Cai, “Excavating the potential capacity of self-supervised monocular depth estimation,” inProceedings of the IEEE/cvf international conference on computer vision, 2021, pp. 15 560–15 569
2021
-
[11]
Self-supervised monocular depth estimation with frequency-based recurrent refinement,
R. Li, D. Xue, Y . Zhu, H. Wu, J. Sun, and Y . Zhang, “Self-supervised monocular depth estimation with frequency-based recurrent refinement,” IEEE Transactions on Multimedia, vol. 25, pp. 5626–5637, 2022
2022
-
[12]
Sc-depthv3: Robust self-supervised monocular depth estimation for dynamic scenes,
L. Sun, J.-W. Bian, H. Zhan, W. Yin, I. Reid, and C. Shen, “Sc-depthv3: Robust self-supervised monocular depth estimation for dynamic scenes,” IEEE transactions on pattern analysis and machine intelligence, vol. 46, no. 1, pp. 497–508, 2023
2023
-
[13]
Vfm-depth: Leveraging vision foun- dation model for self-supervised monocular depth estimation,
S. Yu, M. Wu, and S.-K. Lam, “Vfm-depth: Leveraging vision foun- dation model for self-supervised monocular depth estimation,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[14]
Unsupervised learning of depth and ego-motion from video,
T. Zhou, M. Brown, N. Snavely, and D. G. Lowe, “Unsupervised learning of depth and ego-motion from video,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1851–1858
2017
-
[15]
Unsupervised learning of depth and ego-motion from monocular video using 3d geometric constraints,
R. Mahjourian, M. Wicke, and A. Angelova, “Unsupervised learning of depth and ego-motion from monocular video using 3d geometric constraints,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 5667–5675
2018
-
[16]
Monodiffusion: Self-supervised monocular depth estimation using diffusion model,
S. Shao, Z. Pei, W. Chen, D. Sun, P. C. Chen, and Z. Li, “Monodiffusion: Self-supervised monocular depth estimation using diffusion model,” IEEE Transactions on Circuits and Systems for Video Technology, 2024. 13
2024
-
[17]
Monocular depth prediction using generative adversarial networks,
A. CS Kumar, S. M. Bhandarkar, and M. Prasad, “Monocular depth prediction using generative adversarial networks,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2018, pp. 300–308
2018
-
[18]
Generative adversarial networks for unsupervised monocular depth prediction,
F. Aleotti, F. Tosi, M. Poggi, and S. Mattoccia, “Generative adversarial networks for unsupervised monocular depth prediction,” inProceedings of the European conference on computer vision (ECCV) workshops, 2018, pp. 0–0
2018
-
[19]
Repurposing diffusion-based image generators for monoc- ular depth estimation,
B. Ke, A. Obukhov, S. Huang, N. Metzger, R. C. Daudt, and K. Schindler, “Repurposing diffusion-based image generators for monoc- ular depth estimation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 9492–9502
2024
-
[20]
Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image,
X. Fu, W. Yin, M. Hu, K. Wang, Y . Ma, P. Tan, S. Shen, D. Lin, and X. Long, “Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 241–258
2024
-
[21]
Fine-tuning image-conditional diffusion models is easier than you think,
G. M. Garcia, K. Abou Zeid, C. Schmidt, D. De Geus, A. Hermans, and B. Leibe, “Fine-tuning image-conditional diffusion models is easier than you think,” in2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). IEEE, 2025, pp. 753–762
2025
-
[22]
Depthfm: Fast generative monocular depth estimation with flow matching,
M. Gui, J. Schusterbauer, U. Prestel, P. Ma, D. Kotovenko, O. Grebenkova, S. A. Baumann, V . T. Hu, and B. Ommer, “Depthfm: Fast generative monocular depth estimation with flow matching,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 3, 2025, pp. 3203–3211
2025
-
[23]
Lotus: Diffusion-based visual foundation model for high-quality dense prediction
J. He, H. Li, W. Yin, Y . Liang, L. Li, K. Zhou, H. Zhang, B. Liu, and Y .-C. Chen, “Lotus: Diffusion-based visual foundation model for high-quality dense prediction,”arXiv preprint arXiv:2409.18124, 2024
-
[24]
Deep shape from polarization,
Y . Ba, A. Gilbert, F. Wang, J. Yang, R. Chen, Y . Wang, L. Yan, B. Shi, and A. Kadambi, “Deep shape from polarization,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 554–571
2020
-
[25]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding,
M. Roberts, J. Ramapuram, A. Ranjan, A. Kumar, M. A. Bautista, N. Paczan, R. Webb, and J. M. Susskind, “Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 912–10 922
2021
-
[26]
Depth map prediction from a single image using a multi-scale deep network,
D. Eigen, C. Puhrsch, and R. Fergus, “Depth map prediction from a single image using a multi-scale deep network,”Advances in neural information processing systems, vol. 27, 2014
2014
-
[27]
Vision transformers for dense prediction,
R. Ranftl, A. Bochkovskiy, and V . Koltun, “Vision transformers for dense prediction,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 12 179–12 188
2021
-
[28]
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross- dataset transfer,
R. Ranftl, K. Lasinger, D. Hafner, K. Schindler, and V . Koltun, “Towards robust monocular depth estimation: Mixing datasets for zero-shot cross- dataset transfer,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 3, pp. 1623–1637, 2020
2020
-
[29]
Monocular depth estimation using laplacian pyramid-based depth residuals,
M. Song, S. Lim, and W. Kim, “Monocular depth estimation using laplacian pyramid-based depth residuals,”IEEE transactions on circuits and systems for video technology, vol. 31, no. 11, pp. 4381–4393, 2021
2021
-
[30]
Diffusion models trained with large data are transferable visual models
G. Xu, Y . Ge, M. Liu, C. Fan, K. Xie, Z. Zhao, H. Chen, and C. Shen, “What matters when repurposing diffusion models for general dense perception tasks?”arXiv preprint arXiv:2403.06090, 2024
-
[31]
Omnidata: A scalable pipeline for making multi-task mid-level vision datasets from 3d scans,
A. Eftekhar, A. Sax, J. Malik, and A. Zamir, “Omnidata: A scalable pipeline for making multi-task mid-level vision datasets from 3d scans,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 786–10 796
2021
-
[32]
Collett,Field guide to polarization
E. Collett,Field guide to polarization. SPIE press Bellingham, 2005, vol. 15
2005
-
[33]
Polarization-based inverse rendering from a single view,
Miyazaki, Tan, Hara, and Ikeuchi, “Polarization-based inverse rendering from a single view,” inProceedings Ninth IEEE International Confer- ence on Computer Vision. IEEE, 2003, pp. 982–987
2003
-
[34]
Polarisation photometric stereo,
G. A. Atkinson, “Polarisation photometric stereo,”Computer Vision and Image Understanding, vol. 160, pp. 158–167, 2017
2017
-
[35]
Reconstruction of specular surfaces using polarization imaging,
S. Rahmann and N. Canterakis, “Reconstruction of specular surfaces using polarization imaging,” inProceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, vol. 1. IEEE, 2001, pp. I–I
2001
-
[36]
Simultaneous acquisition of polarimetric svbrdf and normals
S.-H. Baek, D. S. Jeon, X. Tong, and M. H. Kim, “Simultaneous acquisition of polarimetric svbrdf and normals.”ACM Trans. Graph., vol. 37, no. 6, p. 268, 2018
2018
-
[37]
Pandora: Polarization-aided neural decomposition of radiance,
A. Dave, Y . Zhao, and A. Veeraraghavan, “Pandora: Polarization-aided neural decomposition of radiance,” inEuropean conference on computer vision. Springer, 2022, pp. 538–556
2022
-
[38]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021
2021
-
[39]
Nersp: Neural 3d reconstruction for reflective objects with sparse polarized images,
Y . Han, H. Guo, K. Fukai, H. Santo, B. Shi, F. Okura, Z. Ma, and Y . Jia, “Nersp: Neural 3d reconstruction for reflective objects with sparse polarized images,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 11 821–11 830
2024
-
[40]
Multi-view azimuth stereo via tangent space consistency,
X. Cao, H. Santo, F. Okura, and Y . Matsushita, “Multi-view azimuth stereo via tangent space consistency,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 825– 834
2023
-
[41]
Polarimetric inverse rendering for transparent shapes reconstruction,
M. Shao, C. Xia, D. Duan, and X. Wang, “Polarimetric inverse rendering for transparent shapes reconstruction,”IEEE Transactions on Multime- dia, vol. 26, pp. 7801–7811, 2024
2024
-
[42]
Transparent shape from a single view polarization image,
M. Shao, C. Xia, Z. Yang, J. Huang, and X. Wang, “Transparent shape from a single view polarization image,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 9277–9286
2023
-
[43]
Neisf: Neural incident stokes field for geometry and material estimation,
C. Li, T. Ono, T. Uemori, H. Mihara, A. Gatto, H. Nagahara, and Y . Moriuchi, “Neisf: Neural incident stokes field for geometry and material estimation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21 434–21 445
2024
-
[44]
Depth from a polarisation+ rgb stereo pair,
D. Zhu and W. A. Smith, “Depth from a polarisation+ rgb stereo pair,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 7586–7595
2019
-
[45]
P2d: a self-supervised method for depth estimation from polarimetry,
M. Blanchon, D. Sidib ´e, O. Morel, R. Seulin, D. Braun, and F. Meri- audeau, “P2d: a self-supervised method for depth estimation from polarimetry,” in2020 25th International Conference on Pattern Recog- nition (ICPR). IEEE, 2021, pp. 7357–7364
2021
-
[46]
Shape from polarization for complex scenes in the wild,
C. Lei, C. Qi, J. Xie, N. Fan, V . Koltun, and Q. Chen, “Shape from polarization for complex scenes in the wild,” inProceedings of the ieee/cvf conference on computer vision and pattern recognition, 2022, pp. 12 632–12 641
2022
-
[47]
Dps-net: Deep polarimetric stereo depth estimation,
C. Tian, W. Pan, Z. Wang, M. Mao, G. Zhang, H. Bao, P. Tan, and Z. Cui, “Dps-net: Deep polarimetric stereo depth estimation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3569–3579
2023
-
[48]
Robust depth enhancement via polarization prompt fusion tuning,
K. Ikemura, Y . Huang, F. Heide, Z. Zhang, Q. Chen, and C. Lei, “Robust depth enhancement via polarization prompt fusion tuning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20 710–20 720
2024
-
[49]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[50]
Laion- 5b: An open large-scale dataset for training next generation image-text models,
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsmanet al., “Laion- 5b: An open large-scale dataset for training next generation image-text models,”Advances in neural information processing systems, vol. 35, pp. 25 278–25 294, 2022
2022
-
[51]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[52]
H. Jung, P. Ruhkamp, G. Zhai, N. Brasch, Y . Li, Y . Verdie, J. Song, Y . Zhou, A. Armagan, S. Ilicet al., “Is my depth ground-truth good enough? hammer–highly accurate multi-modal dataset for dense 3d scene regression,”arXiv preprint arXiv:2205.04565, 2022
-
[53]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[54]
B. Ke, K. Qu, T. Wang, N. Metzger, S. Huang, B. Li, A. Obukhov, and K. Schindler, “Marigold: Affordable adaptation of diffusion-based image generators for image analysis,”arXiv preprint arXiv:2505.09358, 2025
-
[55]
Housecat6d-a large-scale multi-modal category level 6d object perception dataset with household objects in realistic scenarios,
H. Jung, S.-C. Wu, P. Ruhkamp, G. Zhai, H. Schieber, G. Rizzoli, P. Wang, H. Zhao, L. Garattoni, S. Meieret al., “Housecat6d-a large-scale multi-modal category level 6d object perception dataset with household objects in realistic scenarios,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 22 498–22 508
2024
-
[56]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[57]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inInternational Conference on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241
2015
-
[58]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.