Recognition: unknown
How Robust Are Large Language Models for Clinical Numeracy? An Empirical Study on Numerical Reasoning Abilities in Clinical Contexts
Pith reviewed 2026-05-10 15:37 UTC · model grok-4.3
The pith
Large language models retrieve clinical values accurately but struggle with comparisons and aggregations, and medical fine-tuning often reduces their numeracy performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
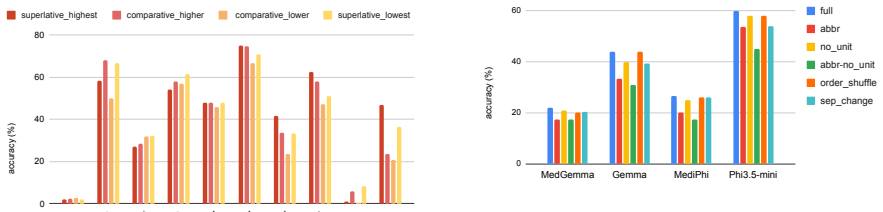
ClinicNumRobBench evaluates four types of clinical numeracy—value retrieval, arithmetic computation, relational comparison, and aggregation—across 1,624 instances built from longitudinal MIMIC-IV vital-sign records presented in three semantically equivalent formats, one derived from real Open Patients notes. Experiments on 17 LLMs demonstrate that value retrieval generally exceeds 85 percent accuracy, relational comparison and aggregation remain challenging with some models below 15 percent, fine-tuning on medical data reduces numeracy relative to base models by over 30 percent, and note-style variation produces clear performance drops that indicate sensitivity to input format.
What carries the argument
ClinicNumRobBench, a benchmark of 1,624 context-question instances using 42 templates and three representations of MIMIC-IV and Open Patients data to test robustness of numerical reasoning across clinical note formats.
Load-bearing premise
The 42 question templates and three semantically equivalent representations fully capture real clinical numeracy demands without introducing biases during ground-truth generation from the source datasets.
What would settle it
Evaluating the same 17 models on an independent set of clinical notes containing numerical questions outside the 42 templates and checking whether the observed gaps between task types and format effects still appear.
Figures




read the original abstract
Large Language Models (LLMs) are increasingly being explored for clinical question answering and decision support, yet safe deployment critically requires reliable handling of patient measurements in heterogeneous clinical notes. Existing evaluations of LLMs for clinical numerical reasoning provide limited operation-level coverage, restricted primarily to arithmetic computation, and rarely assess the robustness of numerical understanding across clinical note formats. We introduce ClinicNumRobBench, a benchmark of 1,624 context-question instances with ground-truth answers that evaluates four main types of clinical numeracy: value retrieval, arithmetic computation, relational comparison, and aggregation. To stress-test robustness, ClinicNumRobBench presents longitudinal MIMIC-IV vital-sign records in three semantically equivalent representations, including a real-world note-style variant derived from the Open Patients dataset, and instantiates queries using 42 question templates. Experiments on 17 LLMs show that value retrieval is generally strong, with most models exceeding 85% accuracy, while relational comparison and aggregation remain challenging, with some models scoring below 15%. Fine-tuning on medical data can reduce numeracy relative to base models by over 30%, and performance drops under note-style variation indicate LLM sensitivity to format. ClinicNumRobBench offers a rigorous testbed for clinically reliable numerical reasoning. Code and data URL are available on https://github.com/MinhVuong2000/ClinicNumRobBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ClinicNumRobBench, a benchmark of 1,624 context-question instances derived from MIMIC-IV vital-sign records and the Open Patients dataset. It evaluates 17 LLMs on four clinical numeracy operations (value retrieval, arithmetic computation, relational comparison, aggregation) using 42 question templates across three semantically equivalent representations, including a note-style variant. Key findings are that value retrieval exceeds 85% accuracy for most models, relational comparison and aggregation remain difficult (some models below 15%), medical fine-tuning reduces performance by over 30% relative to base models, and note-style formats cause measurable drops, demonstrating format sensitivity.
Significance. If the benchmark faithfully reflects clinical demands, the results would be significant for informing safe LLM deployment in clinical decision support, where numerical reasoning errors could affect patient care. The open release of code and data on GitHub is a clear strength, supporting reproducibility and enabling independent verification or extension of the empirical measurements.
major comments (2)
- [Benchmark construction] Benchmark construction (abstract and §3): The central claims about performance gaps and format sensitivity rest on the assumption that the 42 templates and three representations (including note-style from Open Patients) are unbiased and representative of real clinical numeracy. No coverage analysis, human validation of semantic equivalence, or assessment of potential artifacts in ground-truth derivation (e.g., unit handling or temporal scoping) is described; this is load-bearing because unaddressed biases could make the reported >85% retrieval vs. <15% relational/aggregation split and the >30% fine-tuning drop benchmark-specific rather than clinically meaningful.
- [Methods] Methods and experimental setup: Details on exact data processing pipelines, template instantiation rules, and metric computation from structured vital-sign records are insufficient to verify the reported accuracy numbers and trends. This affects confidence in all quantitative claims, including the fine-tuning degradation and format-sensitivity results, as edge cases in MIMIC-IV to note-style conversion could introduce non-equivalences.
minor comments (2)
- [Abstract] The abstract states 'some models scoring below 15%' without identifying the models or providing per-model or per-category breakdowns; a supplementary table would improve clarity.
- [Introduction] Consider adding a brief discussion of how the four numeracy types map to actual clinical workflows to strengthen the motivation for the benchmark design.
Simulated Author's Rebuttal
Thank you for the constructive review of our manuscript introducing ClinicNumRobBench. We appreciate the emphasis on ensuring the benchmark's validity and methodological clarity. We address each major comment below and commit to revisions that strengthen the paper without altering its core claims.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction (abstract and §3): The central claims about performance gaps and format sensitivity rest on the assumption that the 42 templates and three representations (including note-style from Open Patients) are unbiased and representative of real clinical numeracy. No coverage analysis, human validation of semantic equivalence, or assessment of potential artifacts in ground-truth derivation (e.g., unit handling or temporal scoping) is described; this is load-bearing because unaddressed biases could make the reported >85% retrieval vs. <15% relational/aggregation split and the >30% fine-tuning drop benchmark-specific rather than clinically meaningful.
Authors: We agree that explicit validation steps were not detailed in the original submission and that this limits confidence in generalizability. In the revised manuscript, we will add: (1) a coverage analysis mapping the 42 templates to a taxonomy of clinical numeracy tasks drawn from prior literature; (2) results from a human validation study (n=3 clinicians) confirming semantic equivalence across the three representations, including inter-annotator agreement statistics; and (3) a dedicated subsection on ground-truth derivation that explicitly addresses unit normalization, temporal scoping rules, and handling of missing values from MIMIC-IV and Open Patients. These additions will be placed in §3 and the appendix. revision: yes
-
Referee: [Methods] Methods and experimental setup: Details on exact data processing pipelines, template instantiation rules, and metric computation from structured vital-sign records are insufficient to verify the reported accuracy numbers and trends. This affects confidence in all quantitative claims, including the fine-tuning degradation and format-sensitivity results, as edge cases in MIMIC-IV to note-style conversion could introduce non-equivalences.
Authors: We acknowledge the current Methods section lacks sufficient granularity for independent reproduction. In the revision we will expand §3 and add an appendix with: (i) pseudocode for the full MIMIC-IV preprocessing and note-style conversion pipeline; (ii) the complete set of 42 template instantiation rules with examples of edge-case handling; and (iii) the exact formulas and aggregation logic used for each of the four numeracy operations. We will also release the intermediate structured records alongside the existing GitHub repository to allow direct verification of the reported accuracies. revision: yes
Circularity Check
No circularity: direct empirical measurements on external clinical data
full rationale
The paper introduces ClinicNumRobBench as a new benchmark with 1,624 instances derived from MIMIC-IV vital-sign records and Open Patients data, instantiated via 42 templates across three representations. It reports direct accuracy measurements on 17 LLMs for four numeracy types (value retrieval, arithmetic, relational comparison, aggregation), plus effects of fine-tuning and format variation. No equations, fitted parameters, predictions derived from inputs, self-citations as load-bearing premises, or ansatzes are present. All claims reduce to observable performance on held-out external data with code and data released for verification. This is a standard empirical evaluation with no derivation chain that could be circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MIMIC-IV vital sign records and Open Patients dataset provide accurate ground-truth labels for clinical measurements.
Reference graph
Works this paper leans on
-
[1]
MedHELM: Holistic Evaluation of Large Lan- guage Models for Medical Tasks.arXiv preprint arXiv:2505.23802. Hanjie Chen, Zhouxiang Fang, Yash Singla, and Mark Dredze. 2025a. Benchmarking Large Language Mod- els on Answering and Explaining Challenging Med- ical Questions. InProceedings of the 2025 Confer- ence of the Nations of the Americas Chapter of the A...
-
[2]
In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10392–10407
CARER-ClinicAl Reasoning-Enhanced Rep- resentation for Temporal Health Risk Prediction. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10392–10407. Benjamin Nye, Junyi Jessy Li, Roma Patel, Yinfei Yang, Iain Marshall, Ani Nenkova, and Byron C Wallace
2024
-
[3]
InProceed- ings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 197–207
A Corpus with Multi-Level Annotations of Patients, Interventions and Outcomes to Support Lan- guage Processing for Medical Literature. InProceed- ings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 197–207. Juliana Damasio Oliveira, Henrique DP Santos, Ana Helena DPS Ulbrich, Julia Colleoni Couto...
2025
-
[4]
Overview of the TREC 2022 Clinical Trials Track. InTREC. Russell L. Rothman, Victor M. Montori, Andrea L Cher- rington, and Michael Pignone. 2008. Perspective: The Role of Numeracy in Health Care.Journal of Health Communication, 13:583 – 595. Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.