Recognition: unknown
From Answers to Arguments: Toward Trustworthy Clinical Diagnostic Reasoning with Toulmin-Guided Curriculum Goal-Conditioned Learning
Pith reviewed 2026-05-10 16:25 UTC · model grok-4.3
The pith
Curriculum learning with Toulmin argument structure trains LLMs to generate trustworthy clinical diagnostic arguments efficiently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
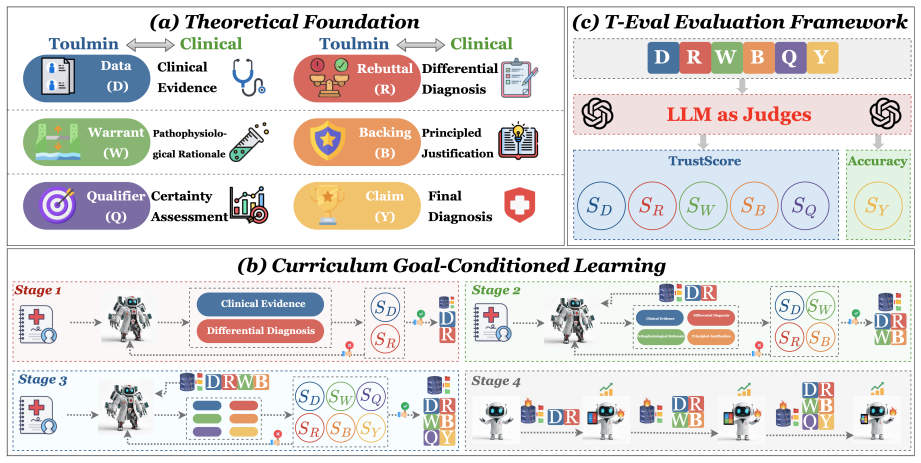
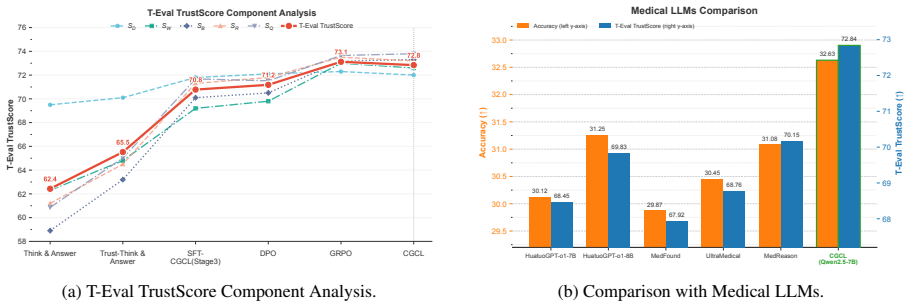
By mapping the Toulmin model onto clinical diagnosis, Curriculum Goal-Conditioned Learning progressively conditions an LLM on goals that build explicit arguments: first extracting facts and generating differentials, then justifying a core hypothesis while rebutting alternatives, and finally synthesizing into a qualified conclusion. This produces diagnostic reasoning whose integrity can be measured quantitatively with T-Eval, yielding accuracy and quality comparable to resource-heavy reinforcement learning while providing greater training stability and efficiency.
What carries the argument
Curriculum Goal-Conditioned Learning (CGCL), a three-stage progressive training pipeline that conditions the LLM on Toulmin-derived goals to construct clinical arguments step by step.
Load-bearing premise
The Toulmin model maps directly onto clinical diagnosis and the three-stage curriculum will build robust, generalizable arguments without introducing new failure modes or needing extensive human oversight.
What would settle it
A controlled test set of complex cases in which CGCL-trained models produce correct diagnoses but exhibit flawed reasoning chains, or repeated training runs that show instability comparable to reinforcement learning baselines, would undermine the central claim.
Figures

read the original abstract
The integration of Large Language Models (LLMs) into clinical decision support is critically obstructed by their opaque and often unreliable reasoning. In the high-stakes domain of healthcare, correct answers alone are insufficient; clinical practice demands full transparency to ensure patient safety and enable professional accountability. A pervasive and dangerous weakness of current LLMs is their tendency to produce "correct answers through flawed reasoning." This issue is far more than a minor academic flaw; such process errors signal a fundamental lack of robust understanding, making the model prone to broader hallucinations and unpredictable failures when faced with real-world clinical complexity. In this paper, we establish a framework for trustworthy clinical argumentation by adapting the Toulmin model to the diagnostic process. We propose a novel training pipeline: Curriculum Goal-Conditioned Learning (CGCL), designed to progressively train LLM to generate diagnostic arguments that explicitly follow this Toulmin structure. CGCL's progressive three-stage curriculum systematically builds a solid clinical argument: (1) extracting facts and generating differential diagnoses; (2) justifying a core hypothesis while rebutting alternatives; and (3) synthesizing the analysis into a final, qualified conclusion. We validate CGCL using T-Eval, a quantitative framework measuring the integrity of the diagnosis reasoning. Experiments show that our method achieves diagnostic accuracy and reasoning quality comparable to resource-intensive Reinforcement Learning (RL) methods, while offering a more stable and efficient training pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes adapting the Toulmin model of argumentation to clinical diagnostic reasoning for LLMs. It introduces Curriculum Goal-Conditioned Learning (CGCL), a three-stage progressive curriculum that trains models to extract facts and differentials, justify hypotheses while rebutting alternatives, and synthesize qualified conclusions. The central claim is that CGCL achieves diagnostic accuracy and reasoning quality comparable to resource-intensive RL methods while providing a more stable and efficient training pipeline, as evaluated by the authors' T-Eval metric for reasoning integrity.
Significance. If the experimental results and T-Eval validation hold, the work could meaningfully advance trustworthy LLM deployment in clinical decision support by enforcing structured, transparent argumentation rather than opaque answers. The curriculum-based approach offers a potentially more accessible alternative to RL fine-tuning for high-stakes domains. The manuscript does not include machine-checked proofs or fully reproducible code artifacts, but the explicit Toulmin structuring and staged training represent a clear methodological contribution if substantiated.
major comments (2)
- [§4 (Experiments)] §4 (Experiments) and abstract: The claim that CGCL achieves 'diagnostic accuracy and reasoning quality comparable to resource-intensive Reinforcement Learning (RL) methods' while being 'more stable and efficient' is load-bearing for the paper's contribution, yet no datasets, specific RL baselines, statistical tests, confidence intervals, or ablation results are reported. Without these, it is not possible to evaluate whether the results support the equivalence or efficiency assertions.
- [§3.3 (T-Eval framework)] §3.3 (T-Eval framework): T-Eval is presented as the quantitative validator of 'integrity of the diagnosis reasoning,' but the section supplies no details on its construction, scoring rubric, inter-rater reliability, correlation with expert clinician ratings, or external validation against real clinical outcomes. Because all headline results rest on this metric, the absence is a load-bearing gap for the central claim.
minor comments (2)
- [§3.1] The three-stage curriculum description in §3.1 would benefit from a table or pseudocode listing the exact goal-conditioning objectives and loss terms at each stage to improve reproducibility.
- [Tables in §4] Notation for the Toulmin components (claim, data, warrant, backing, qualifier, rebuttal) is introduced but not consistently used in the experimental result tables; a standardized column header would aid clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas where the manuscript can be strengthened. We address each major comment below and commit to making the necessary revisions to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments) and abstract: The claim that CGCL achieves 'diagnostic accuracy and reasoning quality comparable to resource-intensive Reinforcement Learning (RL) methods' while being 'more stable and efficient' is load-bearing for the paper's contribution, yet no datasets, specific RL baselines, statistical tests, confidence intervals, or ablation results are reported. Without these, it is not possible to evaluate whether the results support the equivalence or efficiency assertions.
Authors: We agree that the experimental validation requires more detailed reporting to support the central claims. In the revised version, we will expand Section 4 to include: (1) explicit descriptions of the datasets used for training and evaluation, (2) specific RL baselines with implementation details, (3) statistical tests along with confidence intervals for accuracy and T-Eval scores, and (4) ablation studies on the curriculum stages. This will provide a clearer basis for comparing CGCL to RL methods in terms of performance, stability, and efficiency. We will also update the abstract to reflect these additions if necessary. revision: yes
-
Referee: [§3.3 (T-Eval framework)] §3.3 (T-Eval framework): T-Eval is presented as the quantitative validator of 'integrity of the diagnosis reasoning,' but the section supplies no details on its construction, scoring rubric, inter-rater reliability, correlation with expert clinician ratings, or external validation against real clinical outcomes. Because all headline results rest on this metric, the absence is a load-bearing gap for the central claim.
Authors: We acknowledge the importance of providing full transparency on the T-Eval framework. In the revision, we will elaborate on Section 3.3 by detailing: the construction process of T-Eval, including how Toulmin components are scored; the scoring rubric with examples; any inter-rater reliability measures if multiple annotators were involved; and discussions of its correlation with expert ratings or limitations regarding real clinical outcomes. If additional validation is feasible, we will include preliminary results or note it as future work. This will strengthen the justification for using T-Eval as the primary metric. revision: yes
Circularity Check
No significant circularity; claims rest on external experimental validation
full rationale
The paper's central claims concern empirical performance of the proposed CGCL pipeline (three-stage curriculum adapting Toulmin structure) on diagnostic accuracy and reasoning quality, measured via T-Eval and compared to RL baselines. No equations, fitted parameters, or self-citations are presented as load-bearing derivations that reduce to inputs by construction. The Toulmin mapping and curriculum stages are forward-defined training procedures whose outputs are evaluated externally rather than tautologically redefined. This is a standard empirical ML methods paper whose derivation chain is self-contained against the reported experiments.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Toulmin model of argumentation is an appropriate and sufficient structure for clinical diagnostic reasoning.
- ad hoc to paper A three-stage progressive curriculum will build solid clinical arguments that generalize beyond the training distribution.
invented entities (2)
-
Curriculum Goal-Conditioned Learning (CGCL)
no independent evidence
-
T-Eval
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Learning to reach goals via iterated supervised learning.arXiv preprint arXiv:1912.06088, 2019
Tapping into argumentation: Developments in the application of toulmin’s argument pattern for studying science discourse.Science education, 88(6):915–933. Hamzah Noori Fejer, Ali Hadi Hasan, and Ahmed T Sadiq. 2022. A survey of toulmin argumentation ap- proach for medical applications.International Jour- nal of Online & Biomedical Engineering, 18(2). Diby...
-
[2]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others
Pmlr. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek- r1 incentivizes reasoning in llms through reinforce- ment learning.Nature, 645(8081):633–638. Paul Hager, Friederike Jungmann, Robbie Holland, Ku- nal Bhagat, Inga Hubrecht, Manuel Knauer, Jakob Vielhau...
2025
-
[3]
ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission
Clinicalbert: Modeling clinical notes and predicting hospital readmission.arXiv preprint arXiv:1904.05342. Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2020. What dis- ease does this patient have? a large-scale open do- main question answering dataset from medical exams. Preprint, arXiv:2009.13081. Qiao Jin, Bhuwan...
work page internal anchor Pith review arXiv 1904
-
[4]
Measuring Faithfulness in Chain-of-Thought Reasoning
Do medical students generate sound argu- ments during small group discussions in problem- based learning?: an analysis of preclinical medical students’ argumentation according to a framework of hypothetico-deductive reasoning.Korean journal of medical education, 29(2):101. Timo Kaufmann, Paul Weng, Viktor Bengs, and Eyke Hüllermeier. 2024. A survey of rei...
work page Pith review arXiv 2024
-
[5]
Bioinformatics, 36(4):1234–1240
Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240. Yunxiang Li, Zihan Li, Kai Zhang, Ruilong Dan, Steve Jiang, and You Zhang. 2023. Chatdoctor: A medical chat model fine-tuned on a large language model meta-ai (llama) using medical domain knowledge. Cureus, 15(6). Hunter Lightman, V...
2023
-
[6]
InThe Twelfth Inter- national Conference on Learning Representations
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Xiao-huan Liu, Zhen-hua Lu, Tao Wang, and Fei Liu
-
[7]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Large language models facilitating mod- ern molecular biology and novel drug development. Frontiers in Pharmacology, 15:1458739. Xiaohong Liu, Hao Liu, Guoxing Yang, Zeyu Jiang, Shuguang Cui, Zhaoze Zhang, Huan Wang, Liyuan Tao, Yongchang Sun, Zhu Song, and 1 others. 2025. A generalist medical language model for disease di- agnosis assistance.Nature medic...
work page internal anchor Pith review arXiv 2025
-
[8]
Martin Riedmiller, Roland Hafner, Thomas Lampe, Michael Neunert, Jonas Degrave, Tom Wiele, Vlad Mnih, Nicolas Heess, and Jost Tobias Springenberg
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Martin Riedmiller, Roland Hafner, Thomas Lampe, Michael Neunert, Jonas Degrave, Tom Wiele, Vlad Mnih, Nicolas Heess, and Jost Tobias Springenberg
-
[9]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Learning by playing solving sparse reward tasks from scratch. InInternational conference on machine learning, pages 4344–4353. PMLR. Tom Schaul, Daniel Horgan, Karol Gregor, and David Silver. 2015. Universal value function approxima- tors. InInternational conference on machine learn- ing, pages 1312–1320. PMLR. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin ...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
Erlan Yu, Xuehong Chu, Wanwan Zhang, Xiangbin Meng, Yaodong Yang, Xunming Ji, and Chuanjie Wu
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Erlan Yu, Xuehong Chu, Wanwan Zhang, Xiangbin Meng, Yaodong Yang, Xunming Ji, and Chuanjie Wu
-
[11]
Large language models in medicine: Applica- tions, challenges, and future directions.International Journal of Medical Sciences, 22(11):2792. Zhenghang Yuan, Lichao Mou, Qi Wang, and Xiao Xi- ang Zhu. 2022. From easy to hard: Learning language-guided curriculum for visual question an- swering on remote sensing data.IEEE transactions on geoscience and remot...
-
[12]
Do NOT fabricate evidence or citations
-
[13]
If a prompt requests only specific field(s), out- put ONLY those field(s) and omit all others. E.3 Stage-wise Candidate Generation The prompt template below defines the generic in- terface for stage-wise candidate generation across different curriculum stages: Stage 1 populates D and R; Stage 2 populates W and B conditioned on Stage-1 context; Stage 3 pop...
-
[14]
Output MUST be valid JSON and MUST con- tain ONLY the requested field(s)
-
[15]
Do NOT add any other keys
-
[16]
Do NOT invent evidence or diagnoses not sup- ported by the case/context
-
[17]
Keep the output concise, factual, and clinically grounded
-
[18]
Use double quotes for all strings and keys. Case: {CASE} Stage context (may be empty): {STAGE_CONTEXT} Output format: {OUTPUT_FORMAT} E.4 Fusion Prompt Fusion consolidates selected best candidates into a single coherent trajectory under the fixed schema. The fusion prompt below defines the consolida- tion procedure for merging selected candidates into a s...
-
[19]
Do NOT add new evidence beyond the provided D list
-
[20]
Do NOT introduce any diagnosis not already present in the provided R list
-
[21]
The final claim Y must be consistent with D and the reasoning (W, B)
-
[22]
Do NOT fabricate citations or new facts not supported by the case
-
[23]
B” MUST be a string. • “Q
Output ONLY valid JSON. No extra text. Typing constraints (must hold exactly): • “B” MUST be a string. • “Q” MUST contain ONLY {“confidence”, “un- certainty”, “missing_info”}. Revision encoding (no extra fields allowed): If Y differs from the top diagnosis in R (rank = 1), Q.uncertainty MUST begin with: “[Evidence-Based Revision] Initial hy- pothesis: . ....
-
[24]
data_score
Static Structure Assessment (Toulmin-style) — Score 1.0–5.0 • data_score: Are all key facts correctly ex- tracted without errors or omissions? • warrant_score: Is the chain from data to hy- pothesis clear, sound, and medically valid? • backing_score: Are cited guidelines or medical knowledge accurate and relevant? • rebuttal_score: Are the major alternati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.