Recognition: unknown
Sparse Hypergraph-Enhanced Frame-Event Object Detection with Fine-Grained MoE
Pith reviewed 2026-05-10 15:15 UTC · model grok-4.3
The pith
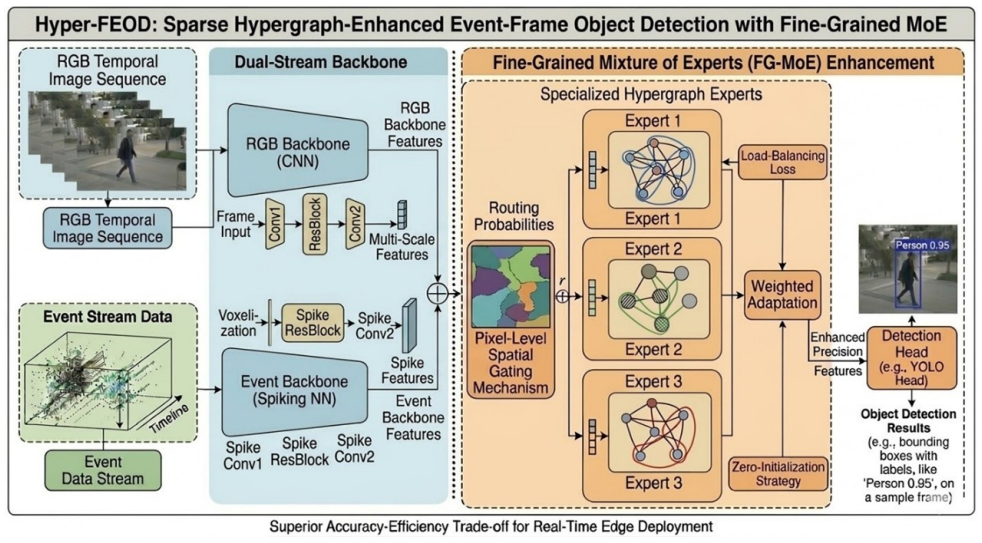
Hyper-FEOD fuses RGB frames and event streams by selecting sparse motion tokens for hypergraph modeling and routing features to region-specific experts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hyper-FEOD achieves superior accuracy-efficiency trade-offs on RGB-Event benchmarks by pairing Sparse Hypergraph-enhanced Cross-Modal Fusion, which constructs an event-guided activity map and performs hypergraph modeling only on selected motion-critical tokens, with a Fine-Grained Mixture of Experts module that deploys specialized hypergraph experts for object boundaries, internal textures and backgrounds, controlled by pixel-level spatial gating plus load-balancing loss and zero-initialization to preserve the pre-trained backbone.
What carries the argument
Sparse Hypergraph-enhanced Cross-Modal Fusion (S-HCF) that selects motion-critical tokens via event sparsity and applies hypergraph modeling only to them, together with Fine-Grained Mixture of Experts (FG-MoE) that routes pixels to boundary, texture or background experts through spatial gating.
If this is right
- Detection accuracy rises on standard RGB-Event benchmarks while model size and latency stay low enough for real-time edge use.
- High-order non-local dependencies between RGB and event data are captured without the quadratic cost of full hypergraph computation.
- Feature refinement remains stable because load-balancing loss and zero-initialization prevent expert collapse or backbone drift.
- Different semantic regions receive tailored enhancement rather than uniform processing across the image.
Where Pith is reading between the lines
- The same sparsity-plus-expert pattern could be tested on other sparse-plus-dense sensor pairs such as LiDAR-camera fusion.
- If the activity map selection threshold proves sensitive, an adaptive version that learns the sparsity level from data might further improve robustness.
- The approach implicitly treats event data as a cheap motion prior; swapping in other cheap priors such as optical flow could be checked as a direct extension.
Load-bearing premise
Event sparsity can reliably pick motion-critical tokens without discarding detection-critical information, and pixel-level gating can route features to the right experts without shifting the distribution of the pre-trained backbone.
What would settle it
A controlled ablation that replaces the event-guided sparse token selection with uniform or random sampling and shows no accuracy gain or an increase in missed detections on the same RGB-Event test sets.
Figures


read the original abstract
Integrating frame-based RGB cameras with event streams offers a promising solution for robust object detection under challenging dynamic conditions. However, the inherent heterogeneity and data redundancy of these modalities often lead to prohibitive computational overhead or suboptimal feature fusion. In this paper, we propose Hyper-FEOD, a high-performance and efficient detection framework, which synergistically optimizes multi-modal interaction through two core components. First, we introduce Sparse Hypergraph-enhanced Cross-Modal Fusion (S-HCF), which leverages the inherent sparsity of event streams to construct an event-guided activity map. By performing high-order hypergraph modeling exclusively on selected motion-critical sparse tokens, S-HCF captures complex non-local dependencies between RGB and event data while overcoming the traditional complexity bottlenecks of hypergraph computation. Second, we design a Fine-Grained Mixture of Experts (FG-MoE) Enhancement module to address the diverse semantic requirements of different image regions. This module employs specialized hypergraph experts tailored for object boundaries, internal textures, and backgrounds, utilizing a pixel-level spatial gating mechanism to adaptively route and enhance features. Combined with a load-balancing loss and zero-initialization strategy, FG-MoE ensures stable training and precise feature refinement without disrupting the pre-trained backbone's distribution. Experimental results on mainstream RGB-Event benchmarks demonstrate that Hyper-FEOD achieves a superior accuracy-efficiency trade-off, outperforming state-of-the-art methods while maintaining a lightweight footprint suitable for real-time edge deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Hyper-FEOD, a framework for RGB-event object detection. It introduces Sparse Hypergraph-enhanced Cross-Modal Fusion (S-HCF) that builds an event-guided activity map to restrict high-order hypergraph modeling to motion-critical sparse tokens, and a Fine-Grained Mixture of Experts (FG-MoE) module that applies pixel-level spatial gating to route features to specialized experts for boundaries, textures, and backgrounds. The authors claim this combination yields a superior accuracy-efficiency trade-off on mainstream RGB-Event benchmarks while remaining lightweight enough for real-time edge deployment.
Significance. If the empirical results and ablations hold, the work would offer a practical route to efficient cross-modal fusion by exploiting event sparsity for hypergraph complexity reduction and conditional expert activation for semantic specialization. This could be relevant for dynamic-scene detection on resource-constrained devices. The approach is technically interesting, but its significance depends on whether the sparsity selection and gating preserve the information required for accurate bounding-box prediction.
major comments (2)
- [S-HCF description] The central accuracy-efficiency claim rests on the event-guided activity map in S-HCF selecting motion-critical tokens without discarding static or low-event semantic content needed for detection. No ablation varying the activity-map threshold or reporting mAP stratified by object motion level is described, leaving open the possibility that aggressive sparsity harms performance on static objects.
- [FG-MoE description] FG-MoE relies on pixel-level gating plus zero-initialization and load-balancing to avoid altering the pre-trained backbone distribution. Without reported feature-statistic comparisons (e.g., activation histograms or KL divergence before/after gating) or an ablation that disables the gating mechanism, it is unclear whether subtle shifts occur that would undermine the stability claim.
minor comments (1)
- [Abstract] The abstract asserts quantitative superiority but supplies no numerical results, error bars, or dataset names; including at least the headline mAP and FPS deltas would improve immediate readability.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive and detailed feedback. The comments highlight important aspects of our experimental validation that we will strengthen in the revision. We address each major comment point by point below.
read point-by-point responses
-
Referee: [S-HCF description] The central accuracy-efficiency claim rests on the event-guided activity map in S-HCF selecting motion-critical tokens without discarding static or low-event semantic content needed for detection. No ablation varying the activity-map threshold or reporting mAP stratified by object motion level is described, leaving open the possibility that aggressive sparsity harms performance on static objects.
Authors: We thank the referee for raising this valid concern. The event-guided activity map in S-HCF is constructed from event density to prioritize motion-critical sparse tokens for hypergraph modeling, with the intent of preserving semantic content for detection. However, we acknowledge that explicit validation across motion levels is needed. In the revised manuscript, we will add (i) an ablation varying the activity-map threshold and its effect on mAP, and (ii) mAP results stratified by object motion level (quantified via average event count per bounding box). These results will confirm that the chosen sparsity does not degrade performance on static or low-motion objects. revision: yes
-
Referee: [FG-MoE description] FG-MoE relies on pixel-level gating plus zero-initialization and load-balancing to avoid altering the pre-trained backbone distribution. Without reported feature-statistic comparisons (e.g., activation histograms or KL divergence before/after gating) or an ablation that disables the gating mechanism, it is unclear whether subtle shifts occur that would undermine the stability claim.
Authors: We appreciate this observation on the stability of the pre-trained backbone. The zero-initialization and load-balancing loss are specifically chosen to minimize distribution shift. To provide stronger empirical support, we will include in the revision: (1) an ablation disabling the pixel-level gating (replacing it with uniform or no routing) to quantify its contribution, and (2) feature-statistic comparisons including activation histograms and KL divergence between backbone features before and after FG-MoE. These additions will demonstrate that any shifts are negligible while the specialized experts improve feature refinement. revision: yes
Circularity Check
No circularity: novel modules introduced without self-referential derivations or fitted predictions.
full rationale
The paper introduces Hyper-FEOD via two explicitly new components (S-HCF using event sparsity for token selection and hypergraph fusion, FG-MoE with pixel gating and load-balancing) presented as design choices rather than derived quantities. No equations, parameter fits, or predictions are shown that reduce to inputs by construction; performance is asserted via external benchmark experiments. Absent any self-definitional loops, fitted-input renamings, or load-bearing self-citations in the provided text, the derivation chain is self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pseudo-labels for super- vised learning on dynamic vision sensor data, applied to object detection under ego-motion
[Chen, 2018] Nicholas FY Chen. Pseudo-labels for super- vised learning on dynamic vision sensor data, applied to object detection under ego-motion. InProceedings of the IEEE conference on computer vision and pattern recogni- tion workshops, pages 644–653,
2018
-
[2]
Hyper-YOLO: When Vi- sual Object Detection Meets Hypergraph Computation
[Fenget al., 2024 ] Yifan Feng, Jiangang Huang, Shaoyi Du, Shihui Ying, Jun-Hai Yong, Yipeng Li, Guiguang Ding, Rongrong Ji, and Yue Gao. Hyper-YOLO: When Vi- sual Object Detection Meets Hypergraph Computation. IEEE Transactions on Pattern Analysis and Machine In- telligence,
2024
-
[3]
Hypergraph vision transform- ers: Images are more than nodes, more than edges
[Fixelle, 2025] Joshua Fixelle. Hypergraph vision transform- ers: Images are more than nodes, more than edges. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9751–9761,
2025
-
[4]
HGNN+: General Hypergraph Neural Networks
[Gaoet al., 2023 ] Yue Gao, Yifan Feng, Shuyi Ji, and Ron- grong Ji. HGNN+: General Hypergraph Neural Networks. IEEE Transactions on Pattern Analysis and Machine Intel- ligence, 45(3):3181–3199,
2023
-
[5]
Recurrent Vision Transformers for Object Detection with Event Cameras
[Gehrig and Scaramuzza, 2023] Mathias Gehrig and Davide Scaramuzza. Recurrent Vision Transformers for Object Detection with Event Cameras. InProceedings of the IEEE Conference on Computer Vision and Pattern Recog- nition, pages 13884–13893,
2023
-
[6]
Low-Latency Automotive Vision with Event Cameras.Nature, 629(8014):1034–1040,
[Gehrig and Scaramuzza, 2024] Daniel Gehrig and Davide Scaramuzza. Low-Latency Automotive Vision with Event Cameras.Nature, 629(8014):1034–1040,
2024
-
[7]
Vision HGNN: An Im- age is More than a Graph of Nodes
[Hanet al., 2023 ] Yan Han, Peihao Wang, Souvik Kundu, Ying Ding, and Zhangyang Wang. Vision HGNN: An Im- age is More than a Graph of Nodes. InProceedings of the IEEE International Conference on Computer Vision, pages 19878–19888,
2023
-
[8]
Nighttime Traffic Ob- ject Detection via Adaptively Integrating Event and Frame Domains.Fundamental Research,
[Jianget al., 2023 ] Yu Jiang, Yuehang Wang, Minghao Zhao, Yongji Zhang, and Hong Qi. Nighttime Traffic Ob- ject Detection via Adaptively Integrating Event and Frame Domains.Fundamental Research,
2023
-
[9]
arXiv preprint arXiv:2506.17733 (2025)
[Leiet al., 2025a ] Mengqi Lei, Siqi Li, Yihong Wu, Han Hu, You Zhou, Xinhu Zheng, Guiguang Ding, Shaoyi Du, Zongze Wu, and Yue Gao. YOLOv13: Real-Time Ob- ject Detection with Hypergraph-Enhanced Adaptive Vi- sual Perception.arXiv preprint arXiv:2506.17733,
-
[10]
SoftHGNN: Soft Hypergraph Neural Networks for General Visual Recognition
[Leiet al., 2025b ] Mengqi Lei, Yihong Wu, Siqi Li, Xinhu Zheng, Juan Wang, Yue Gao, and Shaoyi Du. Softhgnn: Soft hypergraph neural networks for general visual recog- nition.arXiv preprint arXiv:2505.15325,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Event-based Vision Enhanced: A Joint Detection Framework in Autonomous Driving
[Liet al., 2019 ] Jianing Li, Siwei Dong, Zhaofei Yu, Yonghong Tian, and Tiejun Huang. Event-based Vision Enhanced: A Joint Detection Framework in Autonomous Driving. InProceedings of the IEEE International Con- ference on Multimedia and Expo, pages 1396–1401. IEEE,
2019
-
[12]
SODFormer: Streaming Object Detection with Trans- former using Events and Frames.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(11):14020– 14037,
[Liet al., 2023 ] Dianze Li, Yonghong Tian, and Jianing Li. SODFormer: Streaming Object Detection with Trans- former using Events and Frames.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(11):14020– 14037,
2023
-
[13]
3D Feature Tracking via Event Camera
[Liet al., 2024 ] Siqi Li, Zhikuan Zhou, Zhou Xue, Yipeng Li, Shaoyi Du, and Yue Gao. 3D Feature Tracking via Event Camera. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 18974– 18983,
2024
-
[14]
Microsoft COCO: Com- mon Objects in Context
[Linet al., 2014 ] Tsung-Yi Lin, Michael Maire, Serge Be- longie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft COCO: Com- mon Objects in Context. InProceedings of the European Conference on Computer Vision, pages 740–755. Springer,
2014
-
[15]
Path Aggregation Network for Instance Seg- mentation
[Liuet al., 2018 ] Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia. Path Aggregation Network for Instance Seg- mentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8759– 8768,
2018
-
[16]
Deep learning for generic object detec- tion: A survey.International journal of computer vision, 128(2):261–318,
[Liuet al., 2020 ] Li Liu, Wanli Ouyang, Xiaogang Wang, Paul Fieguth, Jie Chen, Xinwang Liu, and Matti Pietik¨ainen. Deep learning for generic object detec- tion: A survey.International journal of computer vision, 128(2):261–318,
2020
-
[17]
Enhanc- ing Traffic Object Detection in Variable Illumination with Rgb-Event Fusion
[Liuet al., 2024 ] Zhanwen Liu, Nan Yang, Yang Wang, Yuke Li, Xiangmo Zhao, and Fei-Yue Wang. Enhanc- ing Traffic Object Detection in Variable Illumination with Rgb-Event Fusion
2024
-
[18]
[Liuet al., 2025 ] Mingjie Liu, Hanqing Liu, and Chuang Zhu. Beyond RGB and Events: Enhancing Object De- tection under Adverse Lighting with Monocular Normal Maps.arXiv preprint arXiv:2508.02127,
-
[19]
Imbalance problems in object detection: A review.IEEE transactions on pattern analy- sis and machine intelligence, 43(10):3388–3415,
[Oksuzet al., 2020 ] Kemal Oksuz, Baris Can Cam, Sinan Kalkan, and Emre Akbas. Imbalance problems in object detection: A review.IEEE transactions on pattern analy- sis and machine intelligence, 43(10):3388–3415,
2020
-
[20]
[Penget al., 2024 ] Yansong Peng, Hebei Li, Peixi Wu, Yueyi Zhang, Xiaoyan Sun, and Feng Wu. D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement.arXiv preprint arXiv:2410.13842,
-
[21]
Learning to detect objects with a 1 megapixel event camera.Pro- ceedings of the Advances in Neural Information Process- ing Systems, 33:16639–16652,
[Perotet al., 2020 ] Etienne Perot, Pierre De Tournemire, Da- vide Nitti, Jonathan Masci, and Amos Sironi. Learning to detect objects with a 1 megapixel event camera.Pro- ceedings of the Advances in Neural Information Process- ing Systems, 33:16639–16652,
2020
-
[22]
Event-based Fusion for Motion Deblurring with Cross-modal Attention
[Sunet al., 2022 ] Lei Sun, Christos Sakaridis, Jingyun Liang, Qi Jiang, Kailun Yang, Peng Sun, Yaozu Ye, Kai- wei Wang, and Luc Van Gool. Event-based Fusion for Motion Deblurring with Cross-modal Attention. InPro- ceedings of the European Conference on Computer Vision, pages 412–428. Springer,
2022
-
[23]
Fusing event-based and rgb camera for robust object detection in adverse conditions
[Tomyet al., 2022 ] Abhishek Tomy, Anshul Paigwar, Khushdeep S Mann, Alessandro Renzaglia, and Christian Laugier. Fusing event-based and rgb camera for robust object detection in adverse conditions. InIEEE Inter- national Conference on Robotics and Automation, pages 933–939. IEEE,
2022
-
[24]
Attention is All You Need
[Vaswaniet al., 2017 ] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is All You Need. InProceedings of the Advances in Neural Informa- tion Processing Systems, volume 30,
2017
-
[25]
Towards Robust Keypoint De- tection and Tracking: A Fusion Approach with Event- aligned Image Features.IEEE Robotics and Automation Letters,
[Wanget al., 2024 ] Xiangyuan Wang, Huai Yu, Lei Yu, Wen Yang, and Gui-Song Xia. Towards Robust Keypoint De- tection and Tracking: A Fusion Approach with Event- aligned Image Features.IEEE Robotics and Automation Letters,
2024
-
[26]
Masked Gen- erative Distillation
[Yanget al., 2022 ] Zhendong Yang, Zhe Li, Mingqi Shao, Dachuan Shi, Zehuan Yuan, and Chun Yuan. Masked Gen- erative Distillation. InProceedings of the European Con- ference on Computer Vision, pages 53–69. Springer,
2022
-
[27]
Frame-Event Alignment and Fusion Network for High Frame Rate Tracking
[Zhanget al., 2023 ] Jiqing Zhang, Yuanchen Wang, Wenxi Liu, Meng Li, Jinpeng Bai, Baocai Yin, and Xin Yang. Frame-Event Alignment and Fusion Network for High Frame Rate Tracking. InProceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition, pages 9781–9790,
2023
-
[28]
[Zhanget al., 2024 ] Haitian Zhang, Xiangyuan Wang, Chang Xu, Xinya Wang, Fang Xu, Huai Yu, Lei Yu, and Wen Yang. Frequency-Adaptive Low-Latency Object Detection Using Events and Frames.arXiv preprint arXiv:2412.04149,
-
[29]
Rgb-Event Fusion for Moving Object Detection in Autonomous Driving.Proceedings of the IEEE Interna- tional Conference on Robotics and Automation, 2023
[Zhouet al., 2023 ] Zhuyun Zhou, Zongwei Wu, R´emi Bout- teau, Fan Yang, C´edric Demonceaux, and Dominique Gin- hac. Rgb-Event Fusion for Moving Object Detection in Autonomous Driving.Proceedings of the IEEE Interna- tional Conference on Robotics and Automation, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.