Recognition: unknown
NeuVolEx: Implicit Neural Features for Volume Exploration
Pith reviewed 2026-05-10 15:40 UTC · model grok-4.3
The pith
Features learned during implicit neural representation training on volumes can be augmented to classify regions of interest accurately even with sparse user labels and to suggest complementary viewpoints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NeuVolEx establishes that the feature representations learned during implicit neural representation training, when augmented by a structural encoder and a multi-task learning scheme, provide a robust basis for volume exploration. This supports accurate ROI classification under sparse user supervision for image-based transfer function design and unsupervised clustering to identify compact complementary viewpoints that reveal different ROI clusters, with validation on diverse volume datasets showing improved effectiveness and usability over prior methods.
What carries the argument
The feature representations learned during INR training, augmented with a structural encoder and multi-task scheme to improve spatial coherence for ROI characterization.
Load-bearing premise
The feature representations learned during INR training remain robust for ROI characterization after augmentation by a structural encoder and multi-task scheme even when user supervision is limited and across diverse volume modalities.
What would settle it
A test on a complex volume where ROI classification accuracy with 5 percent user labels falls below that of explicit local feature baselines would show the central claim does not hold.
Figures






read the original abstract
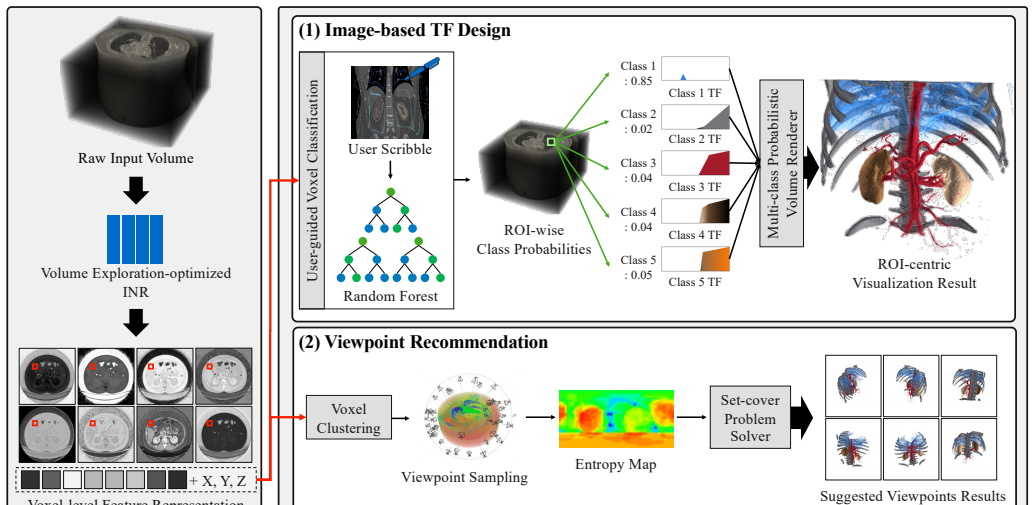
Direct volume rendering (DVR) aims to help users identify and examine regions of interest (ROIs) within volumetric data, and feature representations that support effective ROI classification and clustering play a fundamental role in volume exploration. Existing approaches typically rely on either explicit local feature representations or implicit convolutional feature representations learned from raw volumes. However, explicit local feature representations are limited in capturing broader geometric patterns and spatial correlations, while implicit convolutional feature representations do not necessarily ensure robust performance in practice, where user supervision is typically limited. Meanwhile, implicit neural representations (INRs) have recently shown strong promise in DVR for volume compression, owing to their ability to compactly parameterize continuous volumetric fields. In this work, we propose NeuVolEx, a neural volume exploration approach that extends the role of INRs beyond volume compression. Unlike prior compression methods that focus on INR outputs, NeuVolEx leverages feature representations learned during INR training as a robust basis for volume exploration. To better adapt these feature representations to exploration tasks, we augment a base INR with a structural encoder and a multi-task learning scheme that improve spatial coherence for ROI characterization. We validate NeuVolEx on two fundamental volume exploration tasks: image-based transfer function (TF) design and viewpoint recommendation. NeuVolEx enables accurate ROI classification under sparse user supervision for image-based TF design and supports unsupervised clustering to identify compact complementary viewpoints that reveal different ROI clusters. Experiments on diverse volume datasets with varying modalities and ROI complexities demonstrate NeuVolEx improves both effectiveness and usability over prior methods
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NeuVolEx, which extends implicit neural representations (INRs) for volume exploration in direct volume rendering. It uses features learned during INR training, augmented by a structural encoder and multi-task learning scheme, to support ROI classification for image-based transfer function design under sparse supervision and unsupervised clustering for identifying complementary viewpoints. Validation is performed on diverse volume datasets with varying modalities, showing improvements over prior methods in effectiveness and usability.
Significance. If the reported results hold, this contribution is significant as it repurposes INR training features for practical volume exploration tasks, overcoming limitations of explicit local and implicit convolutional features in low-supervision scenarios. The paper explicitly credits the use of sparse-supervision protocols and unsupervised clustering metrics across multiple modalities, providing reproducible experimental support for the claims. This could advance the field by offering more robust feature representations for DVR applications.
minor comments (3)
- [Abstract] Abstract: the final sentence is grammatically incomplete ('demonstrate NeuVolEx improves' should be 'demonstrate that NeuVolEx improves').
- [Method] Method section: provide the precise formulation of the multi-task objective and structural encoder architecture (including layer counts and activation functions) to enable exact reproduction of the augmented INR features.
- [Experiments] Experiments: include a table summarizing quantitative metrics (accuracy for TF design, clustering metrics such as silhouette score or purity for viewpoints) against all baselines on each dataset.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of NeuVolEx, including recognition of its significance in repurposing INR training features for ROI classification and viewpoint clustering under limited supervision. The recommendation for minor revision is noted, and we will incorporate any such changes in the revised manuscript. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The manuscript describes an applied neural architecture (INR base + structural encoder + multi-task objective) for two downstream tasks: sparse-supervised ROI classification and unsupervised viewpoint clustering. No equations, derivations, or first-principles claims appear; success is measured by standard external metrics (classification accuracy, clustering quality) on held-out data rather than by any quantity defined from the fitted parameters themselves. The method is presented as an empirical extension of prior INR volume work, with no load-bearing self-citation that substitutes for independent verification and no renaming of known patterns as novel results. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ac- cessed: 2026-03-30
The V olume Library.http://volume.open-terrain.org/, 2012. Ac- cessed: 2026-03-30. 5
2012
-
[2]
http://klacansky.com/ open-scivis-datasets/, 2026
Open Scientific Visualization. http://klacansky.com/ open-scivis-datasets/, 2026. Accessed: 2026-03-30. 5
2026
-
[3]
U. D. Bordoloi and H.-W. Shen. View selection for volume rendering. In Proc. IEEE Vis., pp. 487–494, 2005. doi: 10.1109/VISUAL.2005.1532833 2
-
[5]
J. J. Caban and P. Rheingans. Texture-based transfer functions for direct volume rendering.IEEE transactions on Visualization and Computer Graphics, 14(6):1364–1371, 2008. doi: 10.1109/TVCG.2008.169 1, 2
- [6]
- [7]
-
[8]
C. Correa and K.-L. Ma. Size-based transfer functions: A new volume exploration technique.IEEE transactions on visualization and computer graphics, 14(6):1380–1387, 2008. doi: 10.1109/TVCG.2008.162 1, 2
-
[9]
R. A. Drebin, L. Carpenter, and P. Hanrahan. V olume rendering. InProc. SIGGRAPH, pp. 65–74. New York, NY , USA, 1988. doi: 10.1145/54852. 378484 5, 6
-
[10]
D. Engel, L. Sick, and T. Ropinski. Leveraging self-supervised vision transformers for segmentation-based transfer function design.IEEE Trans- actions on Visualization and Computer Graphics, 31(8):4357–4368, 2024. doi: 10.1109/TVCG.2024.3401755 1, 2
-
[11]
COSTA: Multi-center and multi-vendor TOF-MRA Cere- brOvascular SegmenTAtion database
iMED. COSTA: Multi-center and multi-vendor TOF-MRA Cere- brOvascular SegmenTAtion database. https://zenodo.org/records/ 11025761, 2024. Accessed: 2026-03-30. 5
2024
-
[12]
Respiratory cycle 3D-IRCADb-02
IRCAD. Respiratory cycle 3D-IRCADb-02. https://www.ircad.fr/ research/data-sets/respiratory-cycle-3d-ircadb-02/ , 2021. Accessed: 2026-03-30. 5
2021
-
[13]
G. Ji and H.-W. Shen. Dynamic view selection for time-varying volumes. IEEE Transactions on Visualization and Computer Graphics, 12(5):1109– 1116, 2006. doi: 10.1109/TVCG.2006.137 2
-
[14]
G. Kindlmann and J. W. Durkin. Semi-automatic generation of transfer functions for direct volume rendering. InProc. IEEE Symp. Volume Vis., pp. 79–86, 1998. doi: 10.1145/288126.288167 2
-
[15]
Y . Lu, K. Jiang, J. A. Levine, and M. Berger. Compressive neural represen- tations of volumetric scalar fields.Computer Graphics Forum, 40(3):135– 146, 2021. doi: 10.1111/cgf.14295 2
- [16]
-
[17]
Instant neural graphics primitives with a multiresolution hash encoding
T. Müller, A. Evans, C. Schied, and A. Keller. Instant neural graphics primitives with a multiresolution hash encoding.ACM transactions on graphics, 41(4):1–15, 2022. doi: 10.1145/3528223.3530127 3
-
[18]
Osirix DICOM image library
OsiriX. Osirix DICOM image library. https://www.osirix-viewer. com/resources/dicom-image-library/ , 2026. Accessed: 2026-03-
2026
-
[19]
FiLM : Visual reasoning with a general conditioning layer
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville. Film: Visual reasoning with a general conditioning layer. InProc. AAAI Conf. Artif. Intell., vol. 32, 2018. doi: 10.1609/aaai.v32i1.11671 3
-
[20]
T. M. Quan, J. Choi, H. Jeong, and W.-K. Jeong. An intelligent system approach for probabilistic volume rendering using hierarchical 3d convo- lutional sparse coding.IEEE transactions on visualization and computer graphics, 24(1):964–973, 2017. doi: 10.1109/TVCG.2017.2744078 1, 2, 5, 6, 7, 8
-
[21]
K. P. Soundararajan and T. Schultz. Learning probabilistic transfer func- tions: A comparative study of classifiers.Computer Graphics Forum, 34(3):111–120, 2015. doi: 10.1111/cgf.12623 1, 2, 5, 6, 7, 8
-
[22]
S. Takahashi, I. Fujishiro, Y . Takeshima, and T. Nishita. A feature-driven approach to locating optimal viewpoints for volume visualization. InProc. IEEE Vis., pp. 495–502, 2005. doi: 10.1109/VISUAL.2005.1532834 2
-
[23]
K. Tang and C. Wang. Stylerf-volvis: Style transfer of neural radiance fields for expressive volume visualization.IEEE Transactions on Visualiza- tion and Computer Graphics, 31(1):613–623, 2025. doi: 10.1109/TVCG. 2024.3456342 3
-
[24]
Y . Tao, H. Lin, H. Bao, F. Dong, and G. Clapworthy. Structure-aware viewpoint selection for volume visualization. InProc. PacificVis, pp. 193–200, 2009. doi: 10.1109/PACIFICVIS.2009.4906856 2
-
[25]
tmquan. PVR. https://github.com/tmquan/PVR, 2018. Accessed: 2026-03-30. 5
2018
-
[26]
Tzeng, E
F.-Y . Tzeng, E. Lum, and K.-L. Ma. An intelligent system approach to higher-dimensional classification of volume data.IEEE Transactions on visualization and computer graphics, 11(3):273–284, 2005. doi: 10. 1109/TVCG.2005.38 2
2005
-
[27]
Weiss and R
S. Weiss and R. Westermann. Differentiable direct volume rendering.IEEE Transactions on Visualization and Computer Graphics, 28(1):562–572,
-
[28]
doi: 10.1109/TVCG.2021.3114769 5
-
[29]
Q. Wu, D. Bauer, M. J. Doyle, and K.-L. Ma. Interactive volume visualiza- tion via multi-resolution hash encoding based neural representation.IEEE Transactions on Visualization and Computer Graphics, 30(8):5404–5418,
-
[30]
doi: 10.1109/TVCG.2023.3293121 2
-
[31]
Q. Wu, J. A. Insley, V . A. Mateevitsi, S. Rizzi, M. E. Papka, and K.-L. Ma. Distributed neural representation for reactive in situ visualization.IEEE Transactions on Visualization and Computer Graphics, 31(9):5199–5214,
-
[32]
doi: 10.1109/TVCG.2024.3432710 2
-
[33]
C. Yang, Y . Li, C. Liu, and X. Yuan. Deep learning-based viewpoint rec- ommendation in volume visualization.Journal of visualization, 22(5):991– 1003, 2019. doi: 10.1007/s12650-019-00583-4 2
-
[34]
M. Yang, K. Tang, and C. Wang. Meta-INR: Efficient encoding of vol- umetric data via meta-learning implicit neural representation. InProc. PacificVis, pp. 246–251, 2025. doi: 10.1109/PacificVis64226.2025.00030 2
- [35]
-
[36]
Zheng, N
Z. Zheng, N. Ahmed, and K. Mueller. iView: A feature clustering frame- work for suggesting informative views in volume visualization.IEEE transactions on visualization and computer graphics, 17(12):1959–1968,
1959
-
[37]
doi: 10.1109/TVCG.2011.218 2, 4 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.