Recognition: unknown
TRACE: An Experiential Framework for Coherent Multi-hop Knowledge Graph Question Answering
Pith reviewed 2026-05-10 15:13 UTC · model grok-4.3
The pith
TRACE improves multi-hop KGQA coherence by translating reasoning paths into natural language narratives and reusing abstracted exploration priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TRACE is an experiential framework that unifies LLM-driven contextual reasoning with exploration prior integration to enhance the coherence and robustness of multihop KGQA. Specifically, TRACE dynamically translates evolving reasoning paths into natural language narratives to maintain semantic continuity, while abstracting prior exploration trajectories into reusable experiential priors that capture recurring exploration patterns. A dual-feedback re-ranking mechanism further integrates contextual narratives with exploration priors to guide relation selection during reasoning.
What carries the argument
The experiential priors, which abstract recurring patterns from prior exploration trajectories and feed into a dual-feedback re-ranking mechanism alongside natural language narratives of current reasoning paths.
If this is right
- Consistent outperformance over state-of-the-art baselines on multiple KGQA benchmarks.
- Reduced redundant exploration during multi-hop reasoning.
- More robust relation selection through integrated contextual and prior feedback.
- Improved overall coherence across relational paths in complex queries.
Where Pith is reading between the lines
- The reuse of abstracted priors might generalize to other sequential reasoning tasks where similar exploration patterns recur across different queries.
- Performance gains could scale with larger knowledge graphs if the prior abstraction avoids exponential growth in stored patterns.
- The dual-feedback mechanism suggests a template for hybrid systems that blend LLM flexibility with structured memory of past decisions.
Load-bearing premise
Dynamically translating evolving reasoning paths into natural language narratives preserves semantic continuity without introducing LLM hallucinations or information loss that would degrade downstream relation selection.
What would settle it
A controlled test on a benchmark where replacing the natural language narrative translation with direct vector encoding of paths causes measurable drops in relation selection accuracy and overall answer correctness.
Figures

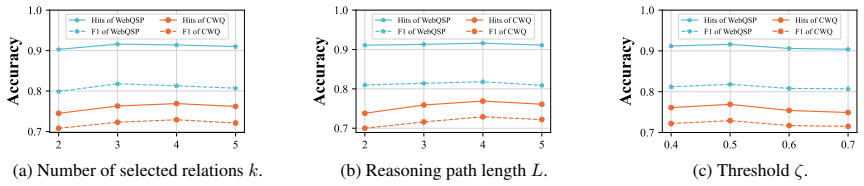





read the original abstract
Multi-hop Knowledge Graph Question Answering (KGQA) requires coherent reasoning across relational paths, yet existing methods often treat each reasoning step independently and fail to effectively leverage experience from prior explorations, leading to fragmented reasoning and redundant exploration. To address these challenges, we propose Trajectoryaware Reasoning with Adaptive Context and Exploration priors (TRACE), an experiential framework that unifies LLM-driven contextual reasoning with exploration prior integration to enhance the coherence and robustness of multihop KGQA. Specifically, TRACE dynamically translates evolving reasoning paths into natural language narratives to maintain semantic continuity, while abstracting prior exploration trajectories into reusable experiential priors that capture recurring exploration patterns. A dualfeedback re-ranking mechanism further integrates contextual narratives with exploration priors to guide relation selection during reasoning. Extensive experiments on multiple KGQA benchmarks demonstrate that TRACE consistently outperforms state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TRACE (Trajectory-aware Reasoning with Adaptive Context and Exploration priors), an experiential framework for multi-hop KGQA. It dynamically translates evolving reasoning paths into natural language narratives to preserve semantic continuity, abstracts prior exploration trajectories into reusable experiential priors, and applies a dual-feedback re-ranking mechanism that integrates contextual narratives with these priors to guide relation selection. The central claim is that this unification yields more coherent and robust reasoning, with extensive experiments demonstrating consistent outperformance over state-of-the-art baselines on multiple KGQA benchmarks.
Significance. If the empirical claims hold after detailed verification, TRACE could meaningfully advance KGQA by explicitly incorporating reusable experiential knowledge from prior explorations alongside LLM contextual reasoning, addressing fragmentation and redundancy that plague step-independent methods. The framework's emphasis on narrative continuity and prior abstraction offers a practical bridge between symbolic KG paths and neural reasoning.
major comments (3)
- [Abstract] Abstract: the claim of 'extensive experiments' and 'consistent outperformance' is unsupported by any reported metrics, baselines, ablation results, error bars, or statistical significance tests. This absence directly undermines verification of the central unification claim, as gains could arise from prompting artifacts rather than the proposed narrative-prior integration.
- [Method overview] Narrative translation component (described in the method overview): no quantitative fidelity metrics, human evaluation, or ablation isolating the LLM-driven path-to-narrative step are provided. Given that this translation is load-bearing for preserving semantic continuity and enabling effective dual-feedback re-ranking, the lack of evidence leaves open the risk that hallucinations or information loss degrade downstream relation selection, as noted in the stress-test concern.
- [Evaluation] Evaluation section: without details on the specific KGQA benchmarks, baseline implementations, or how exploration priors are constructed and reused across queries, it is impossible to assess whether the reported gains are robust or attributable to the experiential framework rather than dataset-specific factors.
minor comments (3)
- [Abstract] The acronym expansion 'Trajectoryaware' is missing a hyphen and should read 'Trajectory-aware' for standard readability.
- [Abstract] Terms such as 'dualfeedback' and 'multihop' appear without hyphens; consistent hyphenation ('dual-feedback', 'multi-hop') would improve clarity.
- [Abstract] The abstract would benefit from naming the specific benchmarks and at least one quantitative result to ground the outperformance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving the clarity of our claims and methodological details. We address each major comment below and have revised the manuscript to strengthen the presentation of results and component evaluations.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'extensive experiments' and 'consistent outperformance' is unsupported by any reported metrics, baselines, ablation results, error bars, or statistical significance tests. This absence directly undermines verification of the central unification claim, as gains could arise from prompting artifacts rather than the proposed narrative-prior integration.
Authors: We agree that the abstract would benefit from more concrete support for its claims. The full manuscript reports metrics, baselines, ablations, error bars, and statistical significance tests in Section 5 and the appendices. In the revised version, we have updated the abstract to include summary performance highlights (e.g., average improvements across benchmarks) with explicit references to the main result tables and significance testing procedures, allowing readers to immediately evaluate the unification claim. revision: yes
-
Referee: [Method overview] Narrative translation component (described in the method overview): no quantitative fidelity metrics, human evaluation, or ablation isolating the LLM-driven path-to-narrative step are provided. Given that this translation is load-bearing for preserving semantic continuity and enabling effective dual-feedback re-ranking, the lack of evidence leaves open the risk that hallucinations or information loss degrade downstream relation selection, as noted in the stress-test concern.
Authors: The referee is correct that the narrative translation step is central and that dedicated fidelity evaluation would strengthen the paper. The original submission included qualitative examples and an overall framework ablation but lacked isolated quantitative metrics or human evaluation for the translation component. We have added a new subsection with semantic similarity metrics between original paths and generated narratives, results from a small-scale human evaluation of translation quality, and an expanded stress-test analysis demonstrating that the dual-feedback re-ranking mitigates potential information loss or hallucinations. revision: yes
-
Referee: [Evaluation] Evaluation section: without details on the specific KGQA benchmarks, baseline implementations, or how exploration priors are constructed and reused across queries, it is impossible to assess whether the reported gains are robust or attributable to the experiential framework rather than dataset-specific factors.
Authors: We apologize for any lack of explicitness in the original presentation. Section 5 specifies the benchmarks (WebQSP, CWQ, MetaQA), provides implementation details and citations for all baselines (including our re-implementations), and describes prior construction as aggregated trajectory abstractions from the training split with reuse via narrative similarity matching to the current query. To address the concern, we have added a dedicated subsection with pseudocode for prior construction and reuse, plus explicit discussion of how this design isolates the contribution of the experiential framework from dataset artifacts. revision: yes
Circularity Check
No circularity: empirical framework with external benchmark evaluation
full rationale
The paper proposes TRACE as a descriptive experiential framework for multi-hop KGQA, relying on LLM-driven narrative translation of paths, abstraction of priors, and dual-feedback re-ranking. No equations, derivations, or mathematical reductions are present. Claims of improved coherence rest on experimental results against external baselines rather than any self-definitional, fitted-input, or self-citation load-bearing steps. The central unification is presented as an empirical proposal, not a derivation that reduces to its inputs by construction. This matches the absence of any load-bearing internal definitions or renamings.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can translate evolving reasoning paths into natural language narratives that preserve semantic continuity for subsequent reasoning steps
- domain assumption Abstracted exploration trajectories capture recurring patterns that generalize across questions and improve relation selection when reused as priors
invented entities (1)
-
experiential priors
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qingyu Guo, Fuzhen Zhuang, Chuan Qin, Hengshu Zhu, Xing Xie, Hui Xiong, and Qing He
Karpa: A training-free method of adapting knowledge graph as references for large language model’s reasoning path aggregation.arXiv preprint arXiv:2412.20995. Qingyu Guo, Fuzhen Zhuang, Chuan Qin, Hengshu Zhu, Xing Xie, Hui Xiong, and Qing He. 2020. A survey on knowledge graph-based recommender sys- tems.IEEE Transactions on Knowledge and Data Engineering...
-
[2]
Costas Mavromatis and George Karypis
Think-on-graph 2.0: Deep and faithful large language model reasoning with knowledge-guided retrieval augmented generation.arXiv preprint arXiv:2407.10805. Costas Mavromatis and George Karypis. 2024. Gnn- rag: Graph neural retrieval for large language model reasoning.arXiv preprint arXiv:2405.20139. Alexander Miller, Adam Fisch, Jesse Dodge, Amir- Hossein ...
-
[3]
arXiv preprint arXiv:1606.03126 , year=
Key-value memory networks for directly read- ing documents.arXiv preprint arXiv:1606.03126. Liangming Pan, Michael Saxon, Wenda Xu, Deepak Nathani, Xinyi Wang, and William Yang Wang. 2023. Automatically correcting large language models: Sur- veying the landscape of diverse self-correction strate- gies.arXiv preprint arXiv:2308.03188. Luís Roque. 2025. The...
-
[4]
Apoorv Saxena, Aditay Tripathi, and Partha Talukdar
Sequence-to-sequence knowledge graph com- pletion and question answering.arXiv preprint arXiv:2203.10321. Apoorv Saxena, Aditay Tripathi, and Partha Talukdar
-
[5]
Improving multi-hop question answering over knowledge graphs using knowledge base embeddings. InProceedings of the 58th annual meeting of the as- sociation for computational linguistics, pages 4498– 4507. John Schulman, Barret Zoph, Christina Kim, Jacob Hilton, Jacob Menick, Jiayi Weng, Juan Felipe Ceron Uribe, Liam Fedus, Luke Metz, Michael Pokorny, and ...
-
[6]
Where was the director of the movie Titanic born?
Deeppath: A reinforcement learning method for knowledge graph reasoning. InProceedings of the Conference on Empirical Methods in Natural Language Processing, pages 564–573. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. InInternational Conference...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.