Recognition: unknown
Quality-Sensitive Matrix Factorization for Community Notes: Towards Sample Efficiency and Manipulation Resistance
Pith reviewed 2026-05-10 16:02 UTC · model grok-4.3
The pith
Adding a single quality-sensitivity parameter per rater to Community Notes' matrix factorization lets the model reach accurate note quality scores with fewer ratings and hold up better against coordinated attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing and jointly estimating a scalar quality-sensitivity parameter for each rater, QSMF connects the standard ideology-adjusted matrix factorization to peer-prediction principles, assigning higher weight to raters whose ratings are more consistent with the aggregate note-quality estimates learned from all data, without requiring any external ground truth on note accuracy.
What carries the argument
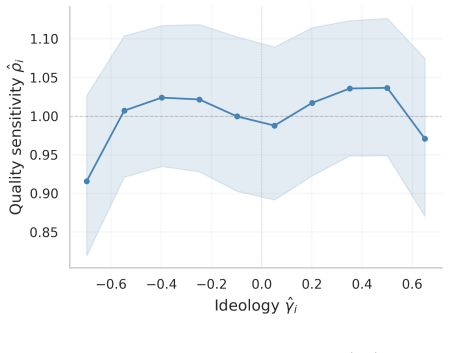
The per-rater quality-sensitivity parameter ρ̂_i, estimated jointly with all other model parameters and used to modulate each rater's influence on note quality based on consistency with the learned estimates.
If this is right
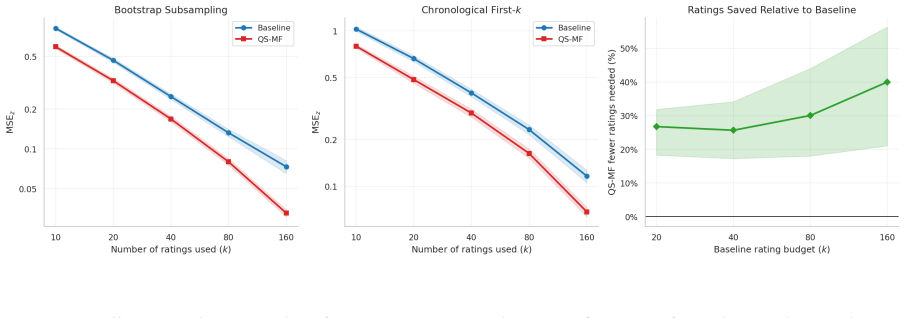
- QSMF reaches the baseline level of accuracy on high-traffic notes with 26-40 percent fewer ratings.
- In semi-synthetic tests of coordinated attacks, QSMF produces substantially smaller shifts in the quality estimates of targeted notes.
- On synthetic data with known ground truth, the estimated ρ̂_i separates good from bad raters with AUC above 0.94 and recovers true note quality with lower error than the baseline.
- All improvements are obtained from one additional scalar per rater and require no external labels or manual moderation.
Where Pith is reading between the lines
- The approach could allow accurate notes to be surfaced earlier in their lifecycle on platforms where rating volume grows slowly.
- Downweighting inconsistent raters may gradually reduce the payoff for strategic behavior in the rating pool.
- Similar per-rater sensitivity terms could be added to other crowdsourced rating systems that already use matrix factorization to separate quality from user traits.
- Over longer periods, the recovered ρ̂_i values might serve as a lightweight signal for identifying raters who systematically contribute reliable signals.
Load-bearing premise
That a rater's quality-sensitivity is a stable individual trait that can be recovered accurately from their ratings pattern alone, without external verification of note quality and without creating new instabilities in the estimates.
What would settle it
A large-scale split-half test on fresh Community Notes data in which the ρ̂_i values estimated from the first half fail to predict which raters remain consistent in the second half, or in which QSMF quality scores diverge from the baseline after the same number of ratings accumulate.
Figures





read the original abstract
Community Notes is X's crowdsourced fact-checking program: contributors write short notes that add context to potentially misleading posts, and other contributors rate whether those notes are helpful. Its algorithm uses a matrix factorization model to separate ideology from note quality, so notes are surfaced only when they receive support across ideological lines. After ideology is accounted for, however, the model gives all raters equal influence on quality estimates. This slows consensus formation and leaves the quality estimate vulnerable to noisy or strategic raters. We propose Quality-Sensitive Matrix Factorization (QSMF), which uses a per-rater quality-sensitivity parameter \(\hat\rho_i\) estimated jointly with all other parameters. This connects QSMF to peer prediction: without external ground truth, it gives more influence to raters whose ideology-adjusted ratings are more consistent with the note-quality estimates learned from all the ratings. We evaluate QSMF on 45M ratings over 365K notes from the six months before the 2024 U.S. presidential election. Split-half tests confirm that quality sensitivity is a stable, empirically recoverable rater trait. In evaluation on high-traffic notes, QSMF requires 26--40\% fewer ratings to match the baseline's accuracy. In semi-synthetic coordinated attacks on notes of opposing ideology, QSMF substantially reduces displacement on the estimated quality estimates of targeted notes relative to the baseline. In synthetic data with known ground truth, \(\hat\rho_i\) separates good from bad raters with an AUC above 0.94, and achieves much lower error in recovering the true note quality estimates in the presence of bad raters. These gains come from a single additional scalar parameter per rater, with no external ground truth and no manual moderation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Quality-Sensitive Matrix Factorization (QSMF) for Community Notes on X. It extends the existing matrix factorization approach by introducing a single per-rater quality-sensitivity parameter ρ̂_i that is estimated jointly with note quality and ideology parameters. Raters whose ideology-adjusted ratings align more closely with the learned note-quality vector receive higher weight. The paper reports evaluations on 45M real ratings, showing 26–40% fewer ratings needed to match baseline accuracy on high-traffic notes, reduced displacement under semi-synthetic coordinated attacks, and strong recovery performance (AUC > 0.94 for rater separation, lower note-quality error) in synthetic data with known ground truth.
Significance. If the empirical claims hold under the joint estimation procedure, the work offers a practical, low-parameter improvement to crowdsourced fact-checking that increases sample efficiency and attack resistance without external ground truth or manual intervention. The combination of large-scale real-data results, attack simulations, and synthetic recovery tests provides concrete evidence of potential impact on deployed systems like Community Notes.
major comments (2)
- [Model definition and optimization procedure] The central modeling choice defines ρ̂_i as the consistency between a rater’s ideology-adjusted ratings and the note-quality vector that is itself learned under weights derived from those same ρ̂_i values. This creates an implicit fixed-point problem. While split-half stability and synthetic AUC > 0.94 are reported, the manuscript does not provide a formal analysis of uniqueness, convergence rate, or sensitivity to initialization/noise for the joint optimum. Because the headline efficiency (26–40%) and attack-resistance claims rest directly on the stability of this fixed point, a dedicated section or appendix deriving or empirically characterizing the optimization landscape is required.
- [Evaluation on real data] The real-data efficiency result is obtained on high-traffic notes only. It is unclear whether the same relative gain holds for the long tail of low-traffic notes that dominate the 365K-note corpus; if the method’s advantage is concentrated on already well-rated items, the practical sample-efficiency benefit for the overall system may be smaller than stated.
minor comments (2)
- [Abstract] The abstract states numerical gains (26–40%, AUC > 0.94) without accompanying standard errors, confidence intervals, or number of independent runs; adding these would allow readers to gauge variability.
- [Model section] Notation for the baseline matrix factorization and the precise form of the QSMF objective (including how ρ̂_i enters the loss) should be written out explicitly in the main text rather than left to supplementary material.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important aspects of the model and evaluation that we address point by point below. We will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Model definition and optimization procedure] The central modeling choice defines ρ̂_i as the consistency between a rater’s ideology-adjusted ratings and the note-quality vector that is itself learned under weights derived from those same ρ̂_i values. This creates an implicit fixed-point problem. While split-half stability and synthetic AUC > 0.94 are reported, the manuscript does not provide a formal analysis of uniqueness, convergence rate, or sensitivity to initialization/noise for the joint optimum. Because the headline efficiency (26–40%) and attack-resistance claims rest directly on the stability of this fixed point, a dedicated section or appendix deriving or empirically characterizing the optimization landscape is required.
Authors: We acknowledge that the joint estimation of ρ̂_i with the note-quality and ideology parameters forms an implicit fixed-point problem, as the weights depend on the parameters being estimated. The current manuscript relies on empirical evidence—split-half stability of ρ̂_i and strong synthetic recovery (AUC > 0.94)—to support reliability. We agree that a more explicit characterization would better substantiate the efficiency and robustness claims. In the revised manuscript we will add an appendix that empirically characterizes the optimization landscape, including convergence behavior from varied initializations, sensitivity to initialization and additive noise, and stability of recovered parameters across random data splits. While a complete theoretical analysis of uniqueness for this non-convex problem lies beyond the scope of the present work, the added empirical diagnostics will directly address the referee’s concern. revision: yes
-
Referee: [Evaluation on real data] The real-data efficiency result is obtained on high-traffic notes only. It is unclear whether the same relative gain holds for the long tail of low-traffic notes that dominate the 365K-note corpus; if the method’s advantage is concentrated on already well-rated items, the practical sample-efficiency benefit for the overall system may be smaller than stated.
Authors: The referee is correct that the reported 26–40% sample-efficiency gains are measured on high-traffic notes. We focused on this subset because these are the notes that accumulate sufficient ratings to reach the display threshold in the deployed Community Notes system; sample efficiency is therefore most consequential precisely where consensus must form. For the long tail of low-traffic notes, absolute rating counts are small and many never reach visibility, so the relative benefit is less operationally relevant. In the revision we will add a dedicated paragraph clarifying this scope and, using the existing 45 M rating corpus, include supplementary results that stratify efficiency gains by rating volume to show how the advantage behaves for notes with fewer ratings. revision: partial
Circularity Check
No significant circularity in QSMF joint estimation or empirical claims
full rationale
The QSMF model defines per-rater ρ̂_i jointly with note quality via consistency of ideology-adjusted ratings with the learned quality vector, creating an explicit fixed-point interdependence by design. However, this is not a reduction of any claimed prediction or first-principles result to its own inputs; it is the model specification itself. All headline performance claims are evaluated against independent benchmarks: synthetic data supplies known ground-truth rater and note qualities for AUC and error metrics; split-half tests on the 45M-rating corpus assess stability of ρ̂_i without using the same optimization artifacts for validation; and efficiency/attack-resistance numbers compare QSMF to baseline on high-traffic notes and semi-synthetic attacks. No self-citation, uniqueness theorem, or ansatz is invoked to force the result, and the derivation chain remains self-contained against these external checks.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-rater quality-sensitivity parameter ρ̂_i
axioms (1)
- domain assumption Matrix factorization can separate note quality from rater ideology
Reference graph
Works this paper leans on
-
[1]
Arechar, Gordon Pennycook, and David G
Jennifer Allen, Antonio A. Arechar, Gordon Pennycook, and David G. Rand. Scaling up fact- checking using the wisdom of crowds.Science Advances, 7(36):eabf4393, 2021
2021
-
[2]
Baker and Seock-Ho Kim.Item Response Theory: Parameter Estimation Techniques
Frank B. Baker and Seock-Ho Kim.Item Response Theory: Parameter Estimation Techniques. CRC Press, 2nd edition, 2004
2004
-
[3]
Bishop.Pattern Recognition and Machine Learning
Christopher M. Bishop.Pattern Recognition and Machine Learning. Springer, 2006. 20
2006
-
[4]
Vivek S. Borkar. Stochastic approximation with two time scales.Systems & Control Letters, 29(5):291–294, 1997
1997
-
[5]
Request a note: How the request function shapes X’s community notes system, 2025
Yuwei Chuai, Gabriele Lenzini, and Nicolas Pr ¨ollochs. Request a note: How the request function shapes X’s community notes system, 2025
2025
-
[6]
Consensus stability of community notes on X.arXiv preprint arXiv:2601.14002, 2026
Yuwei Chuai, Gabriele Lenzini, and Nicolas Pr ¨ollochs. Consensus stability of community notes on X.arXiv preprint arXiv:2601.14002, 2026
-
[7]
The statistical analysis of roll call data
Joshua Clinton, Simon Jackman, and Douglas Rivers. The statistical analysis of roll call data. American Political Science Review, 98(2):355–370, 2004
2004
-
[8]
Crowdsourced judgement elicitation with endogenous pro- ficiency
Anirban Dasgupta and Arpita Ghosh. Crowdsourced judgement elicitation with endogenous pro- ficiency. InProceedings of the 22nd International Conference on World Wide Web, pages 319–330. ACM, 2013
2013
-
[9]
A. P. Dawid and A. M. Skene. Maximum likelihood estimation of observer error-rates using the EM algorithm.Journal of the Royal Statistical Society. Series C (Applied Statistics), 28(1):20–28, 1979
1979
-
[10]
Imprimerie Royale, Paris, 1785
Marquis de Condorcet.Essai sur l’application de l’analyse `a la probabilit´e des d´ecisions rendues `a la pluralit´e des voix. Imprimerie Royale, Paris, 1785
-
[11]
Community notes increase trust in fact-checking on social media.PNAS Nexus, 3(7):pgae217, 2024
Chiara Patricia Drolsbach, Kirill Solovev, and Nicolas Pr¨ollochs. Community notes increase trust in fact-checking on social media.PNAS Nexus, 3(7):pgae217, 2024
2024
-
[12]
Embretson and Steven P
Susan E. Embretson and Steven P. Reise.Item Response Theory for Psychologists. Lawrence Erlbaum Associates, 2000
2000
-
[13]
Guan, Varun Gulshan, Andrew M
Melody Y. Guan, Varun Gulshan, Andrew M. Dai, and Geoffrey E. Hinton. Who said what: Model- ing individual labelers improves classification. InProceedings of the AAAI Conference on Artificial Intelligence, 2018
2018
-
[14]
Hoerl and Robert W
Arthur E. Hoerl and Robert W. Kennard. Ridge regression: Biased estimation for nonorthogonal problems.Technometrics, 12(1):55–67, 1970
1970
-
[15]
Karger, Sewoong Oh, and Devavrat Shah
David R. Karger, Sewoong Oh, and Devavrat Shah. Iterative learning for reliable crowdsourcing systems. InAdvances in Neural Information Processing Systems, 2011
2011
-
[16]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InProceedings of the International Conference on Learning Representations (ICLR), 2015
2015
-
[17]
Matrix factorization techniques for recommender systems
Yehuda Koren, Robert Bell, and Chris Volinsky. Matrix factorization techniques for recommender systems. volume 42, pages 30–37. IEEE, 2009
2009
-
[18]
Cameron Martel, Jennifer Allen, Gordon Pennycook, and David G. Rand. Crowds can effectively identify misinformation at scale.Perspectives on Psychological Science, 2023
2023
-
[19]
Testing begins for community notes on Facebook, Instagram and Threads.https://about
Meta. Testing begins for community notes on Facebook, Instagram and Threads.https://about. fb.com/news/2025/03/testing-begins-community-notes-facebook-instagram-threads/. Updated April 10, 2025
2025
-
[20]
Eliciting informative feedback: The peer- prediction method.Management Science, 51(9):1359–1373, 2005
Nolan Miller, Paul Resnick, and Richard Zeckhauser. Eliciting informative feedback: The peer- prediction method.Management Science, 51(9):1359–1373, 2005
2005
-
[21]
Hyperactive minority alter the stability of community notes
Jacopo Nudo, Eugenio Nerio Nemmi, Edoardo Loru, Alessandro Mei, Walter Quattrociocchi, and Matteo Cinelli. Hyperactive minority alter the stability of community notes. 2026. 21
2026
-
[22]
Bridging systems: Open problems for countering destructive divisiveness across ranking, recommenders, and governance, 2023
Aviv Ovadya and Luke Thorburn. Bridging systems: Open problems for countering destructive divisiveness across ranking, recommenders, and governance, 2023
2023
-
[23]
Poole.Spatial Models of Parliamentary Voting
Keith T. Poole.Spatial Models of Parliamentary Voting. Cambridge University Press, 2005
2005
-
[24]
Poole and Howard Rosenthal.Ideology and Congress
Keith T. Poole and Howard Rosenthal.Ideology and Congress. Transaction Publishers, 2nd edition, 2007
2007
-
[25]
A Bayesian truth serum for subjective data.Science, 306(5695):462–466, 2004
Dra ˇzen Prelec. A Bayesian truth serum for subjective data.Science, 306(5695):462–466, 2004
2004
-
[26]
Testing a new feature to enhance content on TikTok.https://newsroom.tiktok
Adam Presser. Testing a new feature to enhance content on TikTok.https://newsroom.tiktok. com/footnotes?lang=en
-
[27]
Community-based fact-checking on Twitter’s Birdwatch platform
Nicolas Pr ¨ollochs. Community-based fact-checking on Twitter’s Birdwatch platform. InProceed- ings of the International AAAI Conference on Web and Social Media (ICWSM), 2022
2022
-
[28]
Radhakrishna Rao
C. Radhakrishna Rao. Large sample tests of statistical hypotheses concerning several parame- ters with applications to problems of estimation. InMathematical Proceedings of the Cambridge Philosophical Society, volume 44, pages 50–57. Cambridge University Press, 1948
1948
-
[29]
Raykar, Shipeng Yu, Linda H
Vikas C. Raykar, Shipeng Yu, Linda H. Zhao, Gerardo Hermosillo Valadez, Charles Florin, Luca Bogoni, and Linda Moy. Learning from crowds.Journal of Machine Learning Research, 11:1297– 1322, 2010
2010
-
[30]
Olesya Razuvayevskaya, Adel Tayebi, Ulrikke Dybdal Sørensen, Kalina Bontcheva, and Richard Rogers. Timeliness, consensus, and composition of the crowd: Community notes on X.arXiv, (2510.12559), 2025
-
[31]
Collaboratively adding context to social media posts reduces the sharing of false news, 2024
Thomas Renault, David Restrepo Amariles, and Aurore Troussel. Collaboratively adding context to social media posts reduces the sharing of false news, 2024
2024
-
[32]
Deep learning from crowds
Filipe Rodrigues and Francisco Pereira. Deep learning from crowds. InProceedings of the AAAI Conference on Artificial Intelligence, 2018
2018
-
[33]
Probabilistic matrix factorization
Ruslan Salakhutdinov and Andriy Mnih. Probabilistic matrix factorization. InAdvances in Neural Information Processing Systems, 2008
2008
-
[34]
Victor Shnayder, Arpit Agarwal, Rafael Frongillo, and David C. Parkes. Informed truthfulness in multi-task peer prediction. InProceedings of the 2016 ACM Conference on Economics and Compu- tation, pages 179–196. ACM, 2016
2016
-
[35]
Community notes on X reduces engagement with misleading posts.Proceedings of the National Academy of Sciences, 122(38):e2503413122, 2025
Isaac Slaughter, Axel Peytavin, Johan Ugander, and Martin Saveski. Community notes on X reduces engagement with misleading posts.Proceedings of the National Academy of Sciences, 122(38):e2503413122, 2025
2025
-
[36]
Doubleday, 2004
James Surowiecki.The Wisdom of Crowds. Doubleday, 2004
2004
-
[37]
Testing new ways to offer viewers more context and information on videos
The YouTube Team. Testing new ways to offer viewers more context and information on videos. https://blog.youtube/news-and-events/new-ways-to-offer-viewers-more-context/
- [38]
-
[39]
Morgan Wack, Patrick Warren, and Mustafa Alam. The laziness of the crowd: Effort aversion among raters risks undermining the efficacy of x’s community notes program.arXiv preprint arXiv:2603.11120, 2026. 22
-
[40]
The multidimensional wisdom of crowds
Peter Welinder, Steve Branson, Serge Belongie, and Pietro Perona. The multidimensional wisdom of crowds. InAdvances in Neural Information Processing Systems, 2010
2010
-
[41]
Movellan, and Paul L
Jacob Whitehill, Ting-Fan Wu, Jacob Bergsma, Javier R. Movellan, and Paul L. Ruvolo. Whose vote should count more: Optimal integration of labels from labelers of unknown expertise. In Advances in Neural Information Processing Systems, 2009
2009
-
[42]
Stefan Wojcik, Sophie Hilgard, Nick Judd, Delia Mocanu, Stephen Ragain, M. B. Fallin Hunzaker, Keith Coleman, and Jay Baxter. Birdwatch: Crowd wisdom and bridging algorithms can inform understanding and reduce the spread of misinformation. 2022
2022
-
[43]
ˆβj ˆδj # = ˆSj +λ β ˆCj ˆCj ˆVj +λ δ −1
X Corp. Community notes data download.https://x.com/i/communitynotes/download-data, 2026. Accessed: 2026-03-03. A Proofs A.1 Exact Conditional Note-Block Update Fix a notej, and hold all parameters except(β j, δj)fixed. Define the partial residualˆyij :=r ij −ˆµ− ˆαi, i∈ I j.Then the note-jsubproblem is min β,δ 1 2 X i∈Ij ˆyij −ˆρiβ−ˆγiδ 2 + λβ 2 β2 + λδ ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.