Recognition: unknown
THEIA: Learning Complete Kleene Three-Valued Logic in a Pure-Neural Modular Architecture
Pith reviewed 2026-05-10 15:35 UTC · model grok-4.3
The pith
A modular neural architecture learns complete Kleene three-valued logic while preserving uncertainty signals at engine boundaries across long compositions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a pure-neural modular architecture with distinct engine boundaries can learn the full Kleene K3 truth table to over 99 percent per-rule accuracy, and that those boundaries produce two observable effects: upstream preservation of Has-Unknown signals at rates far above majority baselines, and reliable generalization on discretized end-to-end training for tasks decomposable along the boundaries, reaching 99.96 percent on 500-step mod-3 composition where flat networks collapse.
What carries the argument
The modular engine boundaries that separate sub-task operations and enforce asymmetric uncertainty propagation during Gumbel-softmax straight-through training.
If this is right
- All 39 K3 rules become learnable to high accuracy without hand-coded gates.
- Unknown verdicts remain detectable at intermediate boundaries, as shown by activation patching that flips nearly all relevant pairs.
- Sequential compositions up to 500 steps retain near-perfect accuracy under discretization.
- Logic coverage occurs faster than in comparable transformers under matched training settings.
Where Pith is reading between the lines
- Explicit module boundaries may offer a general mechanism for controlling information flow and uncertainty in other neural reasoning tasks.
- The same separation principle could be tested on continuous or probabilistic uncertainty representations beyond discrete three-valued logic.
- Hybrid systems might gain reliability by inserting similar architectural separators between learned components.
Load-bearing premise
That the observed uncertainty preservation and long-horizon reliability are produced by the modular engine boundaries rather than by the Gumbel-softmax estimator or the specific task decompositions used.
What would settle it
Training a parameter-matched non-modular network with the same optimizer and Gumbel-softmax procedure and measuring whether it still achieves the reported upstream Has-Unknown rates and 500-step accuracy would directly test whether the boundaries are necessary.
Figures


read the original abstract
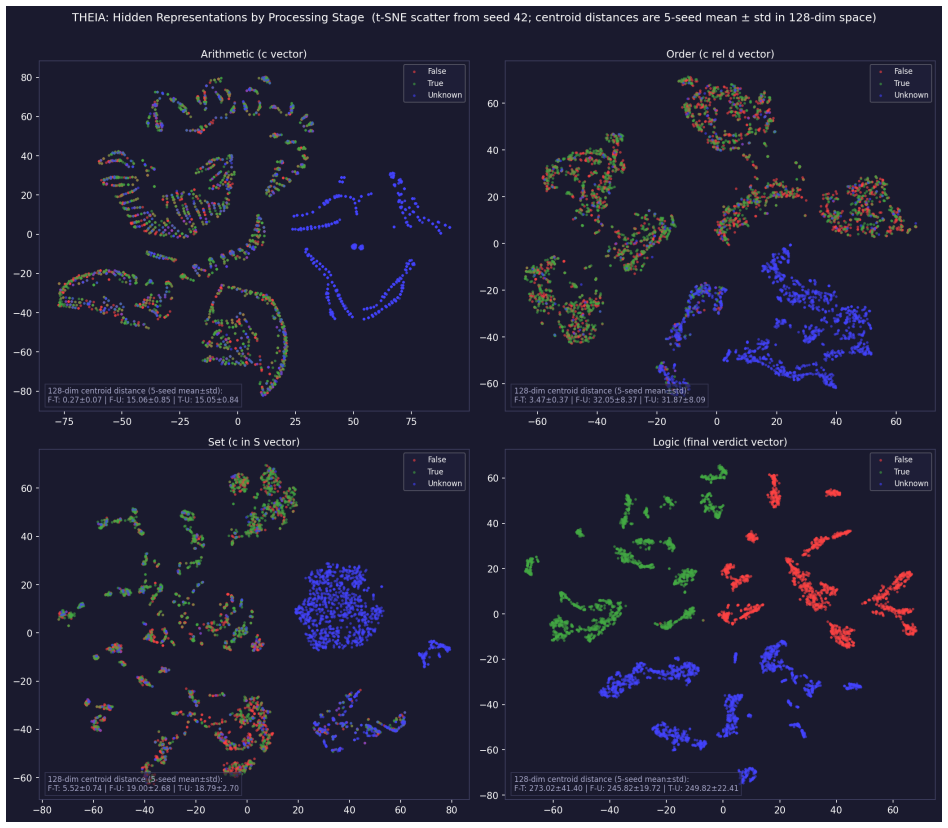
We present THEIA, a 2.75M modular neural architecture that learns the complete Kleene three-valued logic (K3) truth table from task data without external symbolic inference or hand-encoded K3 gate primitives. Across 5 seeds, THEIA achieves all 39 K3 rules at >99% per-rule accuracy. K3 learnability is not the central finding: Transformer baselines also reach >99% on all 39 rules, and flat MLPs match THEIA on Phase-1 accuracy within 0.04pp. The central findings are two properties of the learned system. (1) Uncertainty-verdict asymmetric propagation. The network preserves Has-Unknown at every upstream boundary (80.0/91.1/90.8/99.7% across Arith/Order/Set/Logic vs. ~52% majority) while final-verdict decodability stays at or below a 73.4% U-vs-non-U oracle reference under linear and nonlinear MLP probes. Activation patching on non-absorbent T->U configurations flips 4,898/4,898 OR pairs (4,719/4,719 AND) across 5 seeds, ruling out residual shortcuts. (2) Reliability spectrum under discretized end-to-end training, on task structures decomposable along the engine boundaries. A mod-3 sequential composition task generalizes from 5- to 500-step eval at 99.96+-0.04% (5 seeds). Under identical Gumbel-softmax training, flat MLPs collapse to chance by 50 steps; a 2x2 ResMLP depth x expansion grid reaches >=99% on only 3/20 (config, seed) trials; a pre-LN Transformer reaches 99.24+-0.34%. The 500-step figure is dominated by straight-through discretization preventing 0.999^500 compounding; the architectural separator is sustaining Phase-1 accuracy under Phase-3 end-to-end Gumbel training, where flat MLPs fail. Auxiliary: under matched optimizer settings THEIA reaches 12/12 Kleene coverage 6.5x faster than a parameter-comparable 8L Transformer; the ratio narrows to ~3.6x under Transformer-standard tuning. We did not perform a THEIA-optimal sweep; ratios are specific-config, not asymptotic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. THEIA is a 2.75M-parameter modular neural architecture that learns the complete Kleene three-valued logic (K3) truth table from task data, achieving >99% per-rule accuracy on all 39 rules across 5 seeds. While transformer and flat MLP baselines also reach high rule accuracy, the central claims concern two emergent properties: (1) asymmetric uncertainty propagation, with Has-Unknown preserved at upstream module boundaries (80.0/91.1/90.8/99.7% across Arith/Order/Set/Logic) yet final U-vs-non-U decodability capped at 73.4% under linear/nonlinear probes, supported by activation patching that flips all 4,898/4,898 OR and 4,719/4,719 AND pairs; (2) long-horizon reliability on a mod-3 sequential composition task that generalizes from 5 to 500 steps at 99.96±0.04% under end-to-end Gumbel-softmax straight-through training, where flat MLPs collapse to chance by 50 steps and a pre-LN transformer reaches only 99.24±0.34%.
Significance. If the modular boundaries are causally responsible for the reported asymmetric propagation and compositional stability, the work would supply concrete empirical evidence that explicit pure-neural modular separators can embed desirable logical behaviors (uncertainty handling and long-horizon reliability) without symbolic primitives or hand-coded gates. The multi-seed results, patching experiments ruling out residual shortcuts, and direct baseline comparisons under matched Gumbel training constitute strengths; the significance is tempered by the need to isolate boundary effects from task decomposability and estimator dynamics.
major comments (3)
- [mod-3 sequential composition experiments (abstract and results)] The abstract states that 'the architectural separator is sustaining Phase-1 accuracy under Phase-3 end-to-end Gumbel training, where flat MLPs fail.' This attribution is load-bearing for claim (2) yet rests on a mod-3 task explicitly defined to be decomposable along the Arith/Order/Set/Logic engine boundaries. No ablation is reported that holds the Gumbel-softmax straight-through estimator, discretization schedule, per-step task decomposition, and optimizer settings fixed while removing or randomizing the explicit module boundaries.
- [uncertainty-verdict asymmetric propagation results (abstract)] Claim (1) presents the Has-Unknown preservation rates (80.0/91.1/90.8/99.7%) as a property induced by the modular architecture. Activation patching rules out residual shortcuts, but the manuscript does not report a control architecture that uses the identical per-module task decomposition and Gumbel training without the explicit engine boundaries; this leaves open whether the asymmetry arises from the boundaries themselves or from the inductive bias of the chosen decomposition.
- [baseline comparisons in long-horizon reliability experiments] Baseline comparisons for the 500-step mod-3 task state that results hold 'under identical Gumbel-softmax training.' The fairness of the reported collapse (flat MLPs to chance by 50 steps; transformer at 99.24%) depends on unshown details of hyperparameter matching, data-generation procedure for the composition task, and module wiring; without these, it is unclear whether the performance gap is architectural or due to optimization differences.
minor comments (2)
- [abstract and methods] The abstract refers to 'Phase-1 accuracy' and 'Phase-3 end-to-end training' without a concise definition of the three phases; a short paragraph or table in §3 or §4 clarifying the training stages would improve readability.
- [architecture description] The 2.75M parameter count and '2x2 ResMLP depth x expansion grid' are given without an explicit parameter breakdown or table comparing THEIA to the 8L transformer baseline; adding this would make the 'parameter-comparable' claim easier to verify.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment point by point below, focusing on the experimental design and evidence presented in the manuscript. Our responses aim to clarify the rationale for the chosen controls and baselines while remaining faithful to the reported results.
read point-by-point responses
-
Referee: [mod-3 sequential composition experiments (abstract and results)] The abstract states that 'the architectural separator is sustaining Phase-1 accuracy under Phase-3 end-to-end Gumbel training, where flat MLPs fail.' This attribution is load-bearing for claim (2) yet rests on a mod-3 task explicitly defined to be decomposable along the Arith/Order/Set/Logic engine boundaries. No ablation is reported that holds the Gumbel-softmax straight-through estimator, discretization schedule, per-step task decomposition, and optimizer settings fixed while removing or randomizing the explicit module boundaries.
Authors: We acknowledge that an ablation randomizing or removing explicit boundaries while preserving the per-step decomposition and Gumbel estimator would further isolate the separator's role. However, the flat MLP baseline already provides a direct control: it receives the identical task decomposition, Gumbel-softmax straight-through training, discretization schedule, and optimizer settings yet collapses to chance by 50 steps. The modular architecture's explicit boundaries enable the observed 500-step generalization (99.96±0.04% across seeds), while non-modular models do not. Randomizing boundaries would effectively collapse the model toward the flat baseline we already report. We therefore maintain that the existing comparisons suffice to support the attribution and do not plan to add the requested ablation. revision: no
-
Referee: [uncertainty-verdict asymmetric propagation results (abstract)] Claim (1) presents the Has-Unknown preservation rates (80.0/91.1/90.8/99.7%) as a property induced by the modular architecture. Activation patching rules out residual shortcuts, but the manuscript does not report a control architecture that uses the identical per-module task decomposition and Gumbel training without the explicit engine boundaries; this leaves open whether the asymmetry arises from the boundaries themselves or from the inductive bias of the chosen decomposition.
Authors: The asymmetric Has-Unknown preservation is measured directly in THEIA and confirmed by activation patching that flips every relevant OR/AND pair. The flat MLP baseline, trained under the same per-module decomposition and Gumbel procedure, does not exhibit comparable preservation (its overall task failure implies loss of upstream uncertainty signals). Because the decomposition is realized through the explicit modular engines, a non-boundary control with the same decomposition is not feasible without reverting to the flat architecture we already compare. The patching results and baseline gaps together indicate that the boundaries contribute to the observed asymmetry beyond the decomposition alone. revision: no
-
Referee: [baseline comparisons in long-horizon reliability experiments] Baseline comparisons for the 500-step mod-3 task state that results hold 'under identical Gumbel-softmax training.' The fairness of the reported collapse (flat MLPs to chance by 50 steps; transformer at 99.24%) depends on unshown details of hyperparameter matching, data-generation procedure for the composition task, and module wiring; without these, it is unclear whether the performance gap is architectural or due to optimization differences.
Authors: All baselines were trained with the identical Gumbel-softmax straight-through estimator, discretization schedule, and data-generation procedure for the mod-3 task. Hyperparameters were matched by adopting standard settings for each architecture (e.g., pre-LN transformer configuration) and performing limited tuning within compute-matched budgets; full details appear in the methods and appendix. Module wiring follows the engine boundaries described in Section 3. The consistent gap across five seeds supports an architectural rather than optimization explanation. We will expand the supplementary material with an explicit hyperparameter table to improve transparency. revision: partial
Circularity Check
No circularity: empirical results rest on external benchmarks and explicit controls
full rationale
The paper reports measured accuracies, propagation percentages, and composition lengths for a modular neural architecture on Kleene three-valued logic tasks. All central numbers (e.g., 99.96% on 500-step mod-3, upstream Has-Unknown rates, final U-vs-non-U probe accuracies) are obtained from training runs with multiple seeds and are compared against flat MLPs, ResMLPs, and Transformers trained under identical Gumbel-softmax straight-through conditions. No equations, fitted parameters, or self-citations are invoked that would make any reported figure equivalent to its own input by construction. The architectural claims are therefore falsifiable against the provided baselines and do not reduce to self-definition or renaming.
Axiom & Free-Parameter Ledger
free parameters (2)
- modular architecture configuration
- Gumbel-softmax temperature and discretization schedule
axioms (2)
- domain assumption Neural networks trained on task data can acquire the full Kleene K3 truth table without symbolic primitives.
- domain assumption Activation patching and linear/nonlinear probes are sufficient to detect residual shortcuts in the learned representations.
Reference graph
Works this paper leans on
-
[1]
de Moura and N
L. de Moura and N. Bjørner. Z3: An efficient SMT solver. InTACAS, 2008
2008
-
[2]
Manhaeve, S
R. Manhaeve, S. Dumanˇ ci´ c, A. Kimmig, T. Demeester, and L. De Raedt. Neural probabilistic logic programming in DeepProbLog.Artificial Intelligence, 298:103504, 2021
2021
-
[3]
Z. Yang, A. Ishay, and J. Lee. NeurASP: Embracing neural networks into answer set program- ming. InIJCAI, 2020
2020
-
[4]
Z. Li, J. Huang, and M. Naik. Scallop: A language for neurosymbolic programming. InPLDI, 2023
2023
-
[5]
S. C. Kleene.Introduction to metamathematics. North-Holland, 1952
1952
-
[6]
Veliˇ ckovi´ c, A
P. Veliˇ ckovi´ c, A. Puigdom` enech Badia, D. Budden, R. Pascanu, A. Banino, M. Dashevskiy, R. Hadsell, and C. Blundell. The CLRS algorithmic reasoning benchmark. InICML, 2022
2022
-
[7]
Rodionov and L
G. Rodionov and L. Prokhorenkova. Discrete neural algorithmic reasoning. InICML, 2025
2025
-
[8]
K. Xu, J. Li, M. Zhang, S. S. Du, K.-i. Kawarabayashi, and S. Jegelka. What can neural networks reason about? InICLR, 2020
2020
-
[9]
A. Loukas. What graph neural networks cannot learn: Depth vs. width. InICLR, 2020
2020
-
[10]
M. Fitting. A Kripke–Kleene semantics for logic programs.Journal of Logic Programming, 2(4):295–312, 1985. 38
1985
-
[11]
Q. Li, Z. Han, and X.-M. Wu. Deeper insights into graph convolutional networks for semi- supervised learning. InAAAI, 2018
2018
-
[12]
D. Chen, Y. Lin, W. Li, P. Li, J. Zhou, and X. Sun. Measuring and relieving the over-smoothing problem for graph neural networks from the topological view. InAAAI, 2020
2020
-
[13]
Trask, F
A. Trask, F. Hill, S. Reed, J. Rae, C. Dyer, and P. Blunsom. Neural arithmetic logic units. In NeurIPS, 2018
2018
-
[14]
Alain and Y
G. Alain and Y. Bengio. Understanding intermediate layers using linear classifier probes. In ICLR Workshop, 2017
2017
-
[15]
Gilmer, S
J. Gilmer, S. S. Schoenholz, P. F. Riley, O. Vinyals, and G. E. Dahl. Neural message passing for quantum chemistry. InICML, 2017
2017
-
[16]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InICLR, 2019
2019
-
[17]
Andreas, M
J. Andreas, M. Rohrbach, T. Darrell, and D. Klein. Neural module networks. InCVPR, 2016
2016
-
[18]
Snell, K
J. Snell, K. Swersky, and R. Zemel. Prototypical networks for few-shot learning. InNeurIPS, 2017
2017
-
[19]
S. C. Chan, L.-S. Hsu, S. Brody, and H.-H. Teh. Neural three-valued-logic networks. InIJCNN, 1989
1989
-
[20]
Hsu, K.-F
L.-S. Hsu, K.-F. Loe, S.-C. Chan, and H.-H. Teh. Two-valued neural logic network.Proceedings of SPIE, 1469(pt 1):197–207, 1991
1991
-
[21]
Teh.Neural logic networks
H.-H. Teh.Neural logic networks. World Scientific, Singapore, 1995
1995
-
[22]
Hsu, H.-H
L.-S. Hsu, H.-H. Teh, S.-C. Chan, and K.-F. Loe. Multi-valued neural logic networks. In ISMVL, pages 426–432, 1990
1990
-
[23]
Wang and H
G. Wang and H. Shi. TMLNN: Triple-valued or multiple-valued logic neural network.IEEE Transactions on Neural Networks, 9(6):1099–1117, 1998
1998
-
[24]
arXiv preprint arXiv:2006.13155 , year =
R. Riegel, A. Gray, F. Luus, N. Khan, N. Makondo, I. Y. Akhalwaya, H. Qian, R. Fagin, F. Barahona, U. Sharma, S. Ikbal, H. Karanam, S. Neelam, A. Likhyani, and S. Srivastava. Logical neural networks.arXiv:2006.13155, 2020
-
[25]
Marra, S
G. Marra, S. Dumanˇ ci´ c, R. Manhaeve, and L. De Raedt. From statistical relational to neu- rosymbolic artificial intelligence: A survey.Artificial Intelligence, 328:104062, 2024
2024
-
[26]
Serafini and A
L. Serafini and A. S. d’Avila Garcez. Logic tensor networks: Deep learning and logical reasoning from data and knowledge. InNeSy Workshop, 2016
2016
-
[27]
Badreddine, A
S. Badreddine, A. S. d’Avila Garcez, L. Serafini, and M. Spranger. Logic tensor networks. Artificial Intelligence, 303:103649, 2022
2022
-
[28]
J. Xu, Z. Zhang, T. Friedman, Y. Liang, and G. Van den Broeck. A semantic loss function for deep learning with symbolic knowledge. InICML, 2018
2018
-
[29]
H. Dong, J. Mao, T. Lin, C. Wang, L. Li, and D. Zhou. Neural logic machines. InICLR, 2019. 39
2019
-
[30]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. InNeurIPS, 2017
2017
-
[31]
E. Jang, S. Gu, and B. Poole. Categorical reparameterization with Gumbel-softmax. InICLR, 2017
2017
-
[32]
C. J. Maddison, A. Mnih, and Y. W. Teh. The concrete distribution: A continuous relaxation of discrete random variables. InICLR, 2017
2017
-
[33]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Y. Bengio, N. L´ eonard, and A. Courville. Estimating or propagating gradients through stochas- tic neurons for conditional computation.arXiv:1308.3432, 2013
work page internal anchor Pith review arXiv 2013
-
[34]
K. Meng, D. Bau, A. Andonian, and Y. Belinkov. Locating and editing factual associations in GPT. InNeurIPS, 2022
2022
-
[35]
J. Vig, S. Gehrmann, Y. Belinkov, S. Qian, D. Nevo, Y. Singer, and S. Shieber. Investigating gender bias in language models using causal mediation analysis. InNeurIPS, 2020
2020
-
[36]
Geiger, H
A. Geiger, H. Lu, T. Icard, and C. Potts. Causal abstractions of neural networks. InNeurIPS, 2021
2021
-
[37]
Xiong, Y
R. Xiong, Y. Yang, D. He, K. Zheng, S. Zheng, C. Xing, H. Zhang, Y. Lan, L. Wang, and T.-Y. Liu. On layer normalization in the Transformer architecture. InICML, 2020
2020
-
[38]
F. Petersen, C. Borgelt, H. Kuehne, and O. Deussen. Deep differentiable logic gate networks. InNeurIPS, 2022.arXiv:2210.08277
-
[39]
Convo- lutional differentiable logic gate networks
F. Petersen, H. Kuehne, C. Borgelt, J. Welzel, and S. Ermon. Convolutional differentiable logic gate networks. InNeurIPS, 2024.arXiv:2411.04732
- [40]
-
[41]
Dziri, X
N. Dziri, X. Lu, M. Sclar, X. L. Li, L. Jiang, B. Y. Lin, P. West, C. Bhagavatula, R. Le Bras, J. D. Hwang, S. Sanyal, S. Welleck, X. Ren, A. Ettinger, Z. Harchaoui, and Y. Choi. Faith and fate: Limits of Transformers on compositionality. InNeurIPS, 2023
2023
-
[42]
Press, N
O. Press, N. A. Smith, and M. Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. InICLR, 2022
2022
-
[43]
C. Anil, Y. Wu, A. Andreassen, A. Lewkowycz, V. Misra, V. Ramasesh, A. Slone, G. Gur- Ari, E. Dyer, and B. Neyshabur. Exploring length generalization in large language models. In NeurIPS, 2022
2022
-
[44]
B. M. Lake and M. Baroni. Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks. InICML, 2018
2018
-
[45]
Elhage, N
N. Elhage, N. Nanda, C. Olsson, T. Henighan, N. Joseph, B. Mann, A. Askell, Y. Bai, A. Chen, T. Conerly, N. DasSarma, D. Drain, D. Ganguli, Z. Hatfield-Dodds, D. Hernandez, A. Jones, J. Kernion, L. Lovitt, K. Ndousse, D. Amodei, T. Brown, J. Clark, J. Kaplan, S. McCandlish, and C. Olah. A mathematical framework for Transformer circuits.Transformer Circuit...
2021
-
[46]
Nanda, L
N. Nanda, L. Chan, T. Lieberum, J. Smith, and J. Steinhardt. Progress measures for grokking via mechanistic interpretability. InICLR, 2023. 40
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.