Recognition: unknown
Transactional Attention: Semantic Sponsorship for KV-Cache Retention
Pith reviewed 2026-05-10 15:06 UTC · model grok-4.3
The pith
Transactional Attention retains 100% of credentials at 16 tokens by sponsoring value tokens with structural anchors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
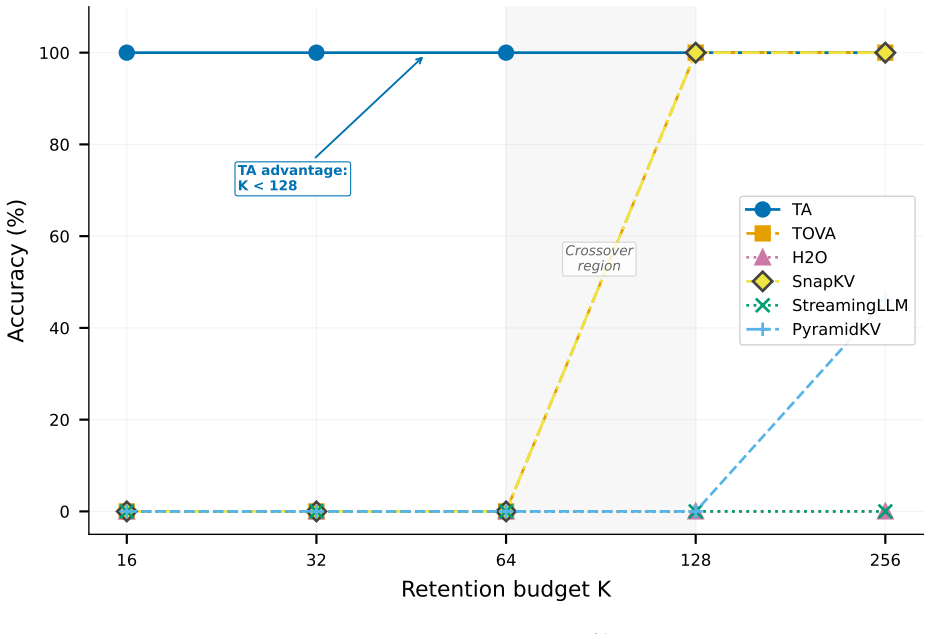
Transactional Attention (TA) sponsors value-bearing tokens that sit next to recognizable structural anchor patterns, keeping them in the KV cache regardless of their low attention scores. At K=16 tokens TA recovers 100% of credentials while H2O, TOVA, SnapKV, StreamingLLM, PyramidKV and DynamicKV recover none. The method sustains 100% accuracy over 200 function-calling trials, and its TA-Fast variant cuts memory overhead by 52% while remaining compatible with SDPA and FlashAttention and adding less than 1% latency.
What carries the argument
Transactional Attention, a sponsorship mechanism that marks structural anchor patterns to shield adjacent value tokens from KV-cache eviction.
If this is right
- 100% credential retrieval at K=16 tokens (0.4% of a 4K context)
- 100% accuracy sustained across 200 function-calling trials
- TA-Fast variant reduces memory overhead by 52%
- Compatible with SDPA and FlashAttention with under 1% added latency
- Orthogonal to existing attention-score or reconstruction-loss compression methods
Where Pith is reading between the lines
- The sponsorship idea could be applied to other low-attention but high-future-value tokens in long-context reasoning or tool-use scenarios.
- Performance would likely degrade on prompts lacking the expected anchors, suggesting the need for prompt templates that guarantee their presence.
- Hybrid policies combining statistical eviction with a small set of semantic rules may offer a practical path to higher compression ratios without task-specific retraining.
Load-bearing premise
Structural anchor patterns such as 'key:' and 'password:' appear consistently in user prompts and correctly identify the locations of critical value tokens.
What would settle it
Credential retrieval accuracy falling below 100% on prompts that contain no explicit anchor patterns or that place anchors next to non-critical tokens.
Figures





read the original abstract
At K=16 tokens (0.4% of a 4K context), every existing KV-cache compression method achieves 0% on credential retrieval. The failure mode is dormant tokens: credentials, API keys, and configuration values that receive near-zero attention but become essential at generation time. Because these tokens lack the statistical signals that eviction policies rely on, no method based on attention scores, reconstruction loss, or learned retention gates retains them. We introduce Transactional Attention (TA), a sponsorship mechanism in which structural anchor patterns (e.g., "key:", "password:") protect adjacent value-bearing tokens from eviction. TA achieves 100% credential retrieval at K=16 where six baselines (H2O, TOVA, SnapKV, StreamingLLM, PyramidKV, DynamicKV) achieve 0%, and sustains 100% accuracy across 200 function-calling trials. TA-Fast, an attention-free variant, reduces memory overhead by 52% and is compatible with SDPA and FlashAttention. TA is orthogonal to existing compression methods and adds less than 1% latency overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Transactional Attention (TA), a KV-cache retention method that uses structural anchor patterns (e.g., 'key:', 'password:') to sponsor and protect adjacent dormant value tokens such as credentials and API keys from eviction. It reports that at K=16 tokens (0.4% of a 4K context), TA achieves 100% credential retrieval where six baselines (H2O, TOVA, SnapKV, StreamingLLM, PyramidKV, DynamicKV) achieve 0%, maintains 100% accuracy across 200 function-calling trials, and offers an attention-free TA-Fast variant with 52% memory reduction that is compatible with SDPA and FlashAttention. The method is presented as orthogonal to existing compression techniques with under 1% latency overhead.
Significance. The work identifies a clear failure mode in attention-score, reconstruction-loss, and learned-gate based KV-cache policies for low-attention but generation-critical tokens. The quantitative gap (100% vs 0%) and low-overhead design, if shown to generalize, would be a practical contribution for reliable compressed inference in function-calling and configuration-heavy tasks. The orthogonality claim and compatibility with optimized attention kernels are noted strengths.
major comments (2)
- [§3] §3 (Transactional Attention mechanism): The sponsorship relies on structural anchor patterns to identify and protect value tokens. The manuscript must specify the exact procedure for anchor selection or detection (hardcoded list, regex, learned component, or otherwise). If anchors require manual specification or task-specific engineering, the 100% retrieval result at K=16 is not guaranteed to hold on prompts lacking these exact patterns, directly affecting the central claim that TA solves the dormant-token problem where attention-based methods fail.
- [§4] §4 (Experimental evaluation): The credential-retrieval and 200 function-calling trials must report how prompts were constructed with respect to anchor presence, the diversity of anchor phrasing, and results on control sets without explicit anchors. The reported 100% vs 0% gap could be an artifact of evaluation data engineered to contain the sponsorship triggers; additional ablations on varied or anchor-free inputs are required to substantiate the general superiority claim.
minor comments (2)
- [Abstract] Abstract and §5: The statements 'reduces memory overhead by 52%' and 'adds less than 1% latency overhead' should reference the specific table, figure, or measurement protocol that supports these numbers.
- [§3] Notation: Define the precise scope of 'structural anchor patterns' and how they interact with the KV-cache eviction policy in the formal description to avoid ambiguity for readers implementing the method.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity on anchor detection and experimental details.
read point-by-point responses
-
Referee: [§3] §3 (Transactional Attention mechanism): The sponsorship relies on structural anchor patterns to identify and protect value tokens. The manuscript must specify the exact procedure for anchor selection or detection (hardcoded list, regex, learned component, or otherwise). If anchors require manual specification or task-specific engineering, the 100% retrieval result at K=16 is not guaranteed to hold on prompts lacking these exact patterns, directly affecting the central claim that TA solves the dormant-token problem where attention-based methods fail.
Authors: We agree the anchor detection procedure must be specified explicitly. Anchors are identified via a hardcoded list of common structural patterns (e.g., 'key:', 'password:', 'api_key:', 'token:', 'secret:') detected through simple string matching and regex for colon- or equals-separated key-value structures; this is neither learned nor highly task-specific beyond standard conventions in code and APIs. We will expand §3 with the precise algorithm and full pattern list. The 100% result applies to prompts containing these anchors, which are prevalent in the targeted credential and function-calling use cases. For anchor-free prompts, TA provides no sponsorship and reverts to baseline behavior. We will update the discussion to clearly scope the claim to anchor-present scenarios rather than claiming universal solution to all dormant-token cases. revision: yes
-
Referee: [§4] §4 (Experimental evaluation): The credential-retrieval and 200 function-calling trials must report how prompts were constructed with respect to anchor presence, the diversity of anchor phrasing, and results on control sets without explicit anchors. The reported 100% vs 0% gap could be an artifact of evaluation data engineered to contain the sponsorship triggers; additional ablations on varied or anchor-free inputs are required to substantiate the general superiority claim.
Authors: We will revise §4 to detail prompt construction: credential-retrieval prompts were generated with explicit anchors (e.g., 'password: [value]') in natural contexts, and the 200 function-calling trials used standard formats where parameter names serve as anchors. Anchor phrasing includes variations such as 'key=', 'secret:', 'auth_token:', and 'api_key:'. We acknowledge the evaluation focused on anchor-present cases. Since sponsorship requires anchors, we will add an ablation on anchor-free control inputs showing that TA achieves retrieval rates comparable to baselines (near 0% at K=16). This confirms the 100% vs 0% gap stems from TA exploiting structural signals that attention-based methods ignore, rather than data engineering, and supports the method's value in relevant tasks. revision: yes
Circularity Check
No circularity: empirical heuristic with no derivation chain
full rationale
The paper introduces Transactional Attention as a practical sponsorship heuristic that protects tokens adjacent to explicit structural anchors (e.g., 'key:', 'password:'). No equations, fitted parameters, uniqueness theorems, or self-citations are presented as load-bearing steps in any derivation. The 100% retrieval claim is an empirical observation on chosen evaluation prompts rather than a mathematical reduction to prior inputs. The method is therefore self-contained as an engineering technique whose validity rests on external benchmarking, not on internal definitional closure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Anchor patterns like 'key:' reliably mark the start of value tokens in prompts
invented entities (1)
-
Transactional Attention sponsorship
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Samhruth Ananthanarayanan, Ayan Sengupta, and Tanmoy Chakraborty. Understanding the physics of key-value cache compression for LLMs through attention dynamics. arXiv preprint arXiv:2603.01426, 2026
-
[2]
Chunkkv: Semantic-preserving KV cache compression for efficient long-context LLM inference
Anonymous. ChunkKV : Semantic-preserving KV cache compression for efficient long-context LLM inference. arXiv preprint arXiv:2502.00299, 2025 a
-
[3]
RocketKV : Accelerating long-context LLM inference via two-stage KV cache compression
Anonymous. RocketKV : Accelerating long-context LLM inference via two-stage KV cache compression. In International Conference on Machine Learning, 2025 b
2025
-
[4]
Anonymous. ARKV : Adaptive and resource-efficient KV cache management under limited memory budget. arXiv preprint arXiv:2603.08727, 2026 a
-
[5]
Cache what lasts: Token retention for memory-bounded KV cache in LLMs
Anonymous. Cache what lasts: Token retention for memory-bounded KV cache in LLMs . In International Conference on Learning Representations, 2026 b
2026
-
[6]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench : A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508, 2023. doi:10.48550/arxiv.2308.14508
work page internal anchor Pith review doi:10.48550/arxiv.2308.14508 2023
-
[7]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Baobao Chang, Junjie Hu, and Wen Xiao. PyramidKV : Dynamic KV cache compression based on pyramidal information funneling. arXiv preprint arXiv:2406.02069, 2024. doi:10.48550/arxiv.2406.02069
work page internal anchor Pith review doi:10.48550/arxiv.2406.02069 2024
-
[8]
R-KV : Redundancy-aware KV cache compression for reasoning models
Zefan Cai et al. R-KV : Redundancy-aware KV cache compression for reasoning models. In Advances in Neural Information Processing Systems, volume 38, 2025
2025
-
[9]
StructKV : Preserving the structural skeleton for scalable long-context inference
Zhirui Chen, Peiyang Liu, and Ling Shao. StructKV : Preserving the structural skeleton for scalable long-context inference. In Findings of the Association for Computational Linguistics: ACL 2026, 2026
2026
-
[10]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher R \'e . FlashAttention : Fast and memory-efficient exact attention with IO -awareness. In Advances in Neural Information Processing Systems, volume 35, pages 16344--16359, 2022. doi:10.48550/arxiv.2205.14135
work page internal anchor Pith review doi:10.48550/arxiv.2205.14135 2022
-
[11]
Ada-KV : Optimizing KV cache eviction by adaptive budget allocation for efficient LLM inference
Yuan Feng et al. Ada-KV : Optimizing KV cache eviction by adaptive budget allocation for efficient LLM inference. In Advances in Neural Information Processing Systems, volume 38, 2025
2025
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mber, Arzoo Amit, Arya Saez, Ashutosh Agarwal, Ashutosh Ganapathy, et al. The Llama 3 herd of models. arXiv preprint arXiv:24...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[13]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units ( GELUs ). arXiv preprint arXiv:1606.08415, 2016. doi:10.48550/arxiv.1606.08415
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1606.08415 2016
-
[14]
KVzip : Query-agnostic KV cache compression with context reconstruction
Hyun Jang et al. KVzip : Query-agnostic KV cache compression with context reconstruction. In Advances in Neural Information Processing Systems, volume 38, 2025. Oral presentation
2025
-
[15]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L \'e lio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth \'e e Lacroix, and William El Sayed. Mistral 7B . arXiv preprint...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825 2023
-
[16]
Sanjay Kariyappa and G. Edward Suh. SideQuest : Model-driven KV cache management for long-horizon agentic reasoning. arXiv preprint arXiv:2602.22603, 2026
-
[17]
SnapKV: LLM Knows What You are Looking for Before Generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. SnapKV : LLM knows what you are looking for before generation. arXiv preprint arXiv:2404.14469, 2024. doi:10.48550/arxiv.2404.14469
work page internal anchor Pith review doi:10.48550/arxiv.2404.14469 2024
-
[18]
Transformers are multi- state rnns
Matanel Oren, Michael Hassid, Yossi Adi, and Roy Schwartz. Transformers are multi-state RNNs . arXiv preprint arXiv:2401.06104, 2024. doi:10.48550/arxiv.2401.06104
-
[19]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dess \`i , Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer : Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761, 2023. doi:10.48550/arxiv.2302.04761
work page internal anchor Pith review doi:10.48550/arxiv.2302.04761 2023
-
[20]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453, 2023. doi:10.48550/arxiv.2309.17453
work page internal anchor Pith review doi:10.48550/arxiv.2309.17453 2023
-
[21]
ReAct : Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct : Synergizing reasoning and acting in language models. In International Conference on Learning Representations, 2023
2023
-
[22]
H2O : Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R \'e , Clark Barrett, Zhiru Wang, and Beidi Chen. H2O : Heavy-hitter oracle for efficient generative inference of large language models. In Advances in Neural Information Processing Systems, volume 36, pages 34661--34710, 2023
2023
-
[23]
DynamicKV : Task-aware adaptive KV cache compression for long context LLMs
Xiabin Zhou, Wenbin Wang, Minyan Zeng, Jiaxian Guo, Xuebo Liu, Li Shen, Min Zhang, and Liang Ding. DynamicKV : Task-aware adaptive KV cache compression for long context LLMs . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 8042--8057, 2025. doi:10.18653/v1/2025.findings-emnlp.426
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.