Recognition: unknown
Polyglot Teachers: Evaluating Language Models for Multilingual Synthetic Data Generation
Pith reviewed 2026-05-10 15:27 UTC · model grok-4.3
The pith
Gemma 3 27B and Aya Expanse 32B generate the most effective multilingual synthetic data for training smaller student models, with prompt diversity, length, and response fluency predicting performance better than model scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When language models are used to synthesize supervised fine-tuning data across six languages, Gemma 3 27B and Aya Expanse 32B produce consistently higher-quality examples that improve student performance across different base model families. Model scale alone shows little correlation with teacher quality. Instead, prompt diversity, response length, and fluency together explain more than 93.3 percent of the variance in intrinsic data quality and directly predict how well students perform on multilingual benchmarks.
What carries the argument
The Polyglot Score, a combined metric that links intrinsic measures of generated data (diversity, length, fluency) to extrinsic student model accuracy after training.
If this is right
- Matching the model family of the teacher to the student yields better downstream results than using the largest available teacher regardless of family.
- For lower-resource languages, translating existing English prompts or having the teacher respond in the target language improves data quality and student performance.
- Practitioners can screen candidate teachers by measuring prompt diversity, response length, and fluency on a small sample rather than running full student trainings.
- Scale is not a reliable proxy for teacher quality in multilingual synthetic data generation.
Where Pith is reading between the lines
- The same data-quality signals could be used to filter or rewrite existing synthetic datasets before training.
- The approach may generalize to other data-generation tasks such as preference tuning or reasoning chains if similar quality metrics are defined.
- Developers of new teacher models could optimize directly for the three measured data traits rather than for general capability benchmarks.
Load-bearing premise
The Polyglot Score and the specific set of six languages, ten teacher models, and 240 student trainings accurately reflect how teacher effectiveness would behave in broader real-world multilingual settings.
What would settle it
Retraining the same student architectures on new synthetic data from the same teachers but in additional languages or with different evaluation tasks shows that the top teachers change or that the three data-quality features no longer account for most of the variance in student results.
Figures





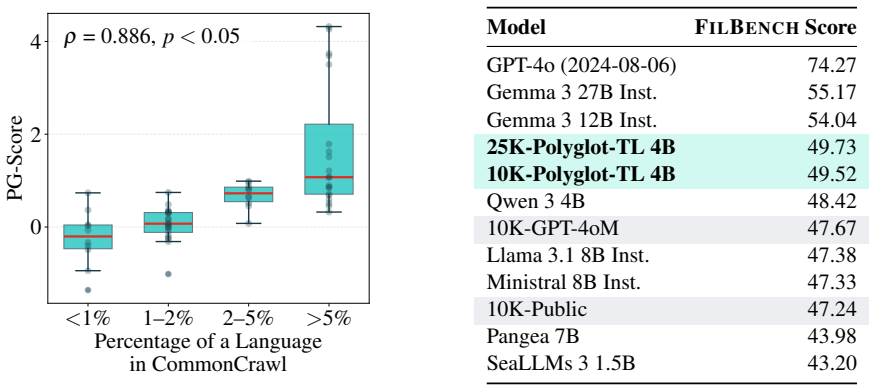
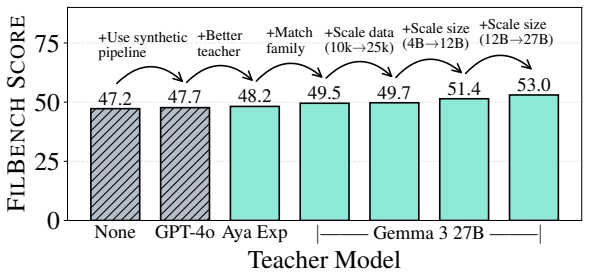




read the original abstract
Synthesizing supervised finetuning (SFT) data from language models (LMs) to teach smaller models multilingual tasks has become increasingly common. However, teacher model selection is often ad hoc, typically defaulting to the largest available option, even though such models may have significant capability gaps in non-English languages. This practice can result in poor-quality synthetic data and suboptimal student downstream performance. In this work, we systematically characterize what makes an effective multilingual teacher. We measure intrinsic measures of data quality with extrinsic student model performance in a metric we call Polyglot Score; evaluating 10 LMs across 6 typologically diverse languages, generating over 1.4M SFT examples and training 240 student models. Among the models tested, Gemma 3 27B and Aya Expanse 32B emerge as consistently effective teachers across different student base model families. Further analyses reveal that model scale alone does not significantly predict teacher effectiveness; instead, data qualities such as prompt diversity, length, and response fluency capture over 93.3% of variance in intrinsic data quality and predict student performance. Finally, we provide practical recommendations, including matching the model families of teacher-student pairs and translating from or responding to existing prompts, which can yield improvements for less-resourced languages. We hope that our work advances data-centric research in multilingual synthetic data and LM development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that by evaluating 10 LMs as teachers for multilingual SFT data generation across 6 typologically diverse languages (producing 1.4M examples and training 240 student models), Gemma 3 27B and Aya Expanse 32B emerge as consistently effective teachers independent of student base model family. Model scale alone does not predict effectiveness; instead, intrinsic data qualities (prompt diversity, length, response fluency) explain over 93.3% of variance in the introduced Polyglot Score and predict student performance. Practical recommendations include matching teacher-student model families and using translation from existing prompts.
Significance. If the central empirical findings hold under further validation, this work is significant for multilingual NLP and data-centric LM research. The scale of the experiments provides a rare systematic comparison that challenges the default to largest models for synthetic data and links specific data qualities to downstream gains. The Polyglot Score and recommendations could offer a practical framework for improving synthetic data quality in low-resource settings, advancing beyond ad-hoc teacher selection.
major comments (2)
- [Further analyses] Further analyses section: the claim that prompt diversity, length, and response fluency capture over 93.3% of variance in intrinsic data quality and predict student performance rests on regression performed on the same 6-language, 10-model, 240-student dataset without reported held-out languages, cross-validation, or out-of-sample testing; this risks the result being an artifact of the specific typological sample and SFT format rather than a general property of teacher effectiveness.
- [Polyglot Score] Polyglot Score definition and validation: the metric aggregates intrinsic qualities and is central to all model rankings and variance claims, yet the manuscript provides no external validation on additional languages, tasks, or real-world downstream applications beyond the experimental pipeline, leaving open whether the 93.3% figure and the superiority of Gemma 3 27B / Aya Expanse 32B generalize.
minor comments (2)
- [Abstract] Abstract: the phrasing 'capture over 93.3% of variance' should be accompanied in the main text by the precise regression specification (e.g., adjusted R², number of predictors, multicollinearity checks) and any statistical significance or error estimates.
- [Experimental setup] The manuscript should clarify how the 240 student trainings were distributed across the 10 teachers and 6 languages to allow assessment of balance and potential confounding in the effectiveness comparisons.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review of our manuscript. We appreciate the emphasis on the need for stronger validation of our regression analyses and the Polyglot Score. We address each major comment below, indicating where we will revise the manuscript to incorporate the feedback while preserving the integrity of our empirical findings.
read point-by-point responses
-
Referee: Further analyses section: the claim that prompt diversity, length, and response fluency capture over 93.3% of variance in intrinsic data quality and predict student performance rests on regression performed on the same 6-language, 10-model, 240-student dataset without reported held-out languages, cross-validation, or out-of-sample testing; this risks the result being an artifact of the specific typological sample and SFT format rather than a general property of teacher effectiveness.
Authors: We acknowledge that the reported regression was fit on the full dataset without explicit cross-validation or held-out evaluation. However, the underlying data already spans 6 typologically diverse languages and 10 teacher models with 240 downstream student evaluations, which provides substantial variation for observing the relationships. To directly address the concern, we will add leave-one-language-out cross-validation in the revised manuscript: the regression will be retrained on five languages and evaluated on the held-out language, with results reported for each fold. This will quantify whether the >93% variance explained and the predictive power for student performance hold across different language subsets rather than being an artifact of the full sample. We will also report the exact regression specification, including the number of observations and the three predictors, to improve transparency. revision: yes
-
Referee: Polyglot Score definition and validation: the metric aggregates intrinsic qualities and is central to all model rankings and variance claims, yet the manuscript provides no external validation on additional languages, tasks, or real-world downstream applications beyond the experimental pipeline, leaving open whether the 93.3% figure and the superiority of Gemma 3 27B / Aya Expanse 32B generalize.
Authors: The Polyglot Score is validated internally through its strong correlation with extrinsic student performance across 240 models and consistent teacher rankings that hold across multiple student base-model families. We agree that external validation on entirely new languages, tasks, or real-world applications would provide further evidence of generalizability. In the revision we will expand the discussion section to explicitly state this limitation and frame broader validation as important future work. We will also include additional details on the score's construction and its per-language correlations with downstream metrics. Because new large-scale experiments on unseen languages fall outside the scope of the current revision, we view these clarifications and the planned cross-validation as the appropriate response while preserving the scale and internal consistency of the existing results. revision: partial
Circularity Check
No circularity; purely empirical measurements and regression on generated data
full rationale
The paper performs a large-scale experimental evaluation: 10 teacher LMs generate 1.4M SFT examples in 6 languages, 240 student models are trained, intrinsic data qualities are measured, and a composite Polyglot Score is defined to correlate them with extrinsic performance. The reported regression (data qualities capturing 93.3% variance) is an analysis of the collected observations rather than a derivation that reduces to its inputs by construction. No equations, self-citations, uniqueness theorems, or ansatzes are invoked; all claims rest on direct experimental outcomes from the described pipeline. This is self-contained empirical work with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The six typologically diverse languages chosen are representative for evaluating multilingual teacher effectiveness.
- domain assumption Student model training protocols are standardized and comparable across all teacher conditions.
invented entities (1)
-
Polyglot Score
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Multilinguality at the Edge: Developing Language Models for the Global South
A survey of 232 papers on the intersection of multilingual language modeling and edge deployment identifies the 'last mile' challenge for Global South communities and offers recommendations for more inclusive NLP.
Reference graph
Works this paper leans on
-
[1]
On the Diversity of Synthetic Data and its Im- pact on Training Large Language Models.Preprint, arXiv:2410.15226. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman
-
[2]
Training Verifiers to Solve Math Word Prob- lems.Preprint, arXiv:2110.14168. Cohere Team, Aakanksha, Arash Ahmadian, Marwan Ahmed, Jay Alammar, Milad Alizadeh, Yazeed Al- numay, Sophia Althammer, Arkady Arkhangorodsky, Viraat Aryabumi, Dennis Aumiller, Raphaël Avalos, Zahara Aviv, Sammie Bae, Saurabh Baji, Alexan- dre Barbet, Max Bartolo, Björn Bebensee, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 43–58, Vienna, Austria
M-RewardBench: Evaluating Reward Models in Multilingual Settings. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 43–58, Vienna, Austria. Association for Computational Lin- guistics. Nathan Habib, Clémentine Fourrier, Hynek Kydlíˇcek, Thomas Wolf, and Lewis Tunstall. 2023. LightEval:...
2023
-
[4]
InInternational Conference on Learn- ing Representations
Measuring Massive Multitask Language Un- derstanding. InInternational Conference on Learn- ing Representations. Pratik Joshi, Sebastin Santy, Amar Budhiraja, Kalika Bali, and Monojit Choudhury. 2020. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. InProceedings of the 58th Annual Meeting of the Association for Computational Ling...
2020
-
[5]
FastText.zip: Compressing text classification models
FastText.zip: Compressing text classification models.Preprint, arXiv:1612.03651. Armand Joulin, Edouard Grave, Piotr Bojanowski, and Tomas Mikolov. 2017. Bag of Tricks for Efficient Text Classification. InProceedings of the 15th Con- ference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Pa- pers, pages 427–431, ...
work page Pith review arXiv 2017
-
[6]
Pedro Henrique Martins, Patrick Fernandes, João Alves, Nuno M
EuroLLM-9B: Technical Report.Preprint, arXiv:2506.04079. Pedro Henrique Martins, Patrick Fernandes, João Alves, Nuno M. Guerreiro, Ricardo Rei, Duarte M. Alves, José Pombal, Amin Farajian, Manuel Faysse, Ma- teusz Klimaszewski, Pierre Colombo, Barry Haddow, José G. C. de Souza, Alexandra Birch, and André F. T. Martins. 2024. EuroLLM: Multilingual Language...
-
[7]
Global MMLU: Understanding and Address- ing Cultural and Linguistic Biases in Multilingual Evaluation. InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 18761–18799, Vi- enna, Austria. Association for Computational Lin- guistics. Shivalika Singh, Freddie Vargus, Daniel D’souza, Börje...
-
[8]
synthetic dataset to compute PG-SCORE
and thestaticvectorslibrary. synthetic dataset to compute PG-SCORE. ResultsFigure 6 shows the PG-SCOREand aver- age benchmark performance of the student model for each translation method across Arabic, Ger- man, and Indonesian. We find thatLM-Translate outperforms both NLLB-based approaches, achiev- ing an average PG-SCORE of 1.36 compared to 0.85 forNLLB...
2025
-
[9]
10K-Public: we sample 10k Tagalog prompt- response pairs from the seed dataset. This base- line aims to simulate a non-synthetic data ap- 22 NLLB Translate Both NLLB Translate then Respond LM Translate0.00 0.25 0.50 0.75 1.00 1.25 1.50 Average PG-Score 0.85 0.80 1.36 NLLB Translate Both NLLB Translate then Respond LM Translate0.0 0.5 1.0 1.5 2.0 PG-Score ...
-
[10]
This baseline simulates a typical data generation approach of choosing a teacher in an ad hoc manner due to its perceived strength (size or benchmark performance) or ease of use
10K-GPT-4oM: we synthesize 10k instances using an off-the-shelf teacher model (GPT-4o- mini). This baseline simulates a typical data generation approach of choosing a teacher in an ad hoc manner due to its perceived strength (size or benchmark performance) or ease of use. For all methods, we finetune a Gemma 3 4B base model using the same training setting...
2024
-
[11]
For each teacher model, we check whether the model provider recommended best settings for usage
and Curator (Marten et al., 2025) for infer- ence. For each teacher model, we check whether the model provider recommended best settings for usage. If not, then we set a default configuration (temperature=0.8, top_p=0.9). Table 17 summa- rizes the inference settings we used for each teacher model. 25 Generate:samplekprompt-response pairs fromD seed,ℓ and ...
2025
-
[12]
The task should be very challenging yet solvable
A "prompt" specifying a task to be completed or a question to be answered (what, where, when, how, who, why). The task should be very challenging yet solvable
-
[13]
response
A "response" representing a valid completion of that task in natural language. If the "response" does not satisfy the "prompt", then you have failed at your job. Do not provide unnecessary details, beyond what is explicitly needed to satisfy the instruction you generated. Hard constraint: The generated task MUST belong to exactly one of the following cate...
-
[14]
Logical reasoning / error analysis
-
[15]
Math or quantitative reasoning with explanation
-
[16]
Classification or labeling
-
[17]
Dialogue or role-play
-
[18]
Translation or paraphrasing with constraints
-
[19]
Procedural instructions (step-by-step)
-
[20]
Grammar correction or linguistic analysis
-
[21]
Short-form creative output (≤50 words)
-
[22]
Knowledge recall with verification or correction
-
[23]
prompt”]}} Response: {{example[“response
Cultural or pragmatic judgment Add diversity to your generations by varying the types of tasks you create, the styles and tones of the responses, and the complexity of the language used. This will help ensure a rich and varied dataset. For example, you might create tasks that involve answering knowledge-based questions, answering math questions, providing...
-
[24]
Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general
-
[25]
You should refer to the score rubric
After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric
-
[26]
The output should contain the score and feedback only
-
[27]
Please do not generate any other opening, closing, and explanations. The instruction to evaluate: {{instruction}} Response to evaluate: {{response}} Score Rubrics: [Is the model proficient in language{lang_name}, including its cultural nuance and gram- matical usage, and responds in a helpful and harmless manner according to the instruction?] Score 1: The...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.