Recognition: unknown
PaperScope: A Multi-Modal Multi-Document Benchmark for Agentic Deep Research Across Massive Scientific Papers
Pith reviewed 2026-05-10 15:48 UTC · model grok-4.3
The pith
PaperScope benchmark shows current AI deep research systems have limited ability to integrate evidence from multiple scientific papers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
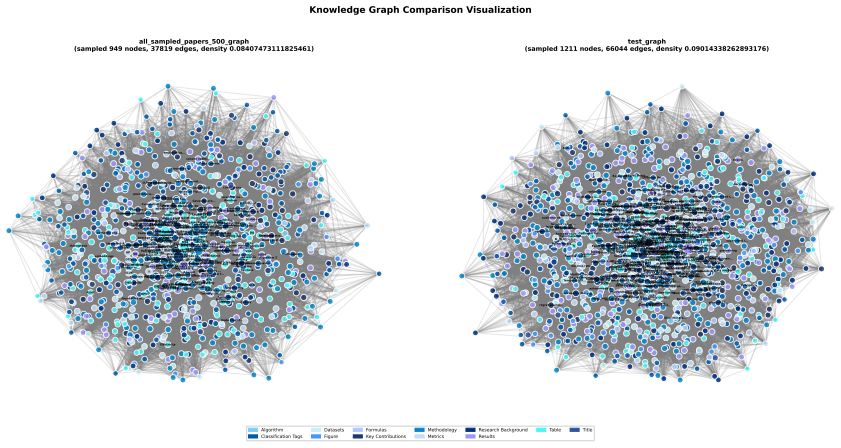
PaperScope is a benchmark for agentic deep research that grounds queries in a knowledge graph of over 2,000 AI papers, constructs semantically dense multi-document sets through optimized random-walk selection, and provides over 2,000 QA pairs for multi-task evaluation of scientific reasoning, retrieval, summarization, and problem solving, with results indicating limited performance by advanced multi-modal systems on long-context multi-source tasks.
What carries the argument
The PaperScope benchmark construction pipeline, which combines a knowledge graph of AI papers with random-walk based article selection to generate thematically coherent multi-document evaluation sets.
Load-bearing premise
That the selected sets of papers from the knowledge graph using random walks accurately mirror the kind of multi-document integration needed in actual scientific research.
What would settle it
Observing high performance scores from multiple advanced AI systems on the PaperScope tasks or finding that the paper sets do not require cross-document reasoning would indicate the benchmark does not capture the intended difficulty.
Figures











read the original abstract
Leveraging Multi-modal Large Language Models (MLLMs) to accelerate frontier scientific research is promising, yet how to rigorously evaluate such systems remains unclear. Existing benchmarks mainly focus on single-document understanding, whereas real scientific workflows require integrating evidence from multiple papers, including their text, tables, and figures. As a result, multi-modal, multi-document scientific reasoning remains underexplored and lacks systematic evaluation. To address this gap, we introduce PaperScope, a multi-modal multi-document benchmark designed for agentic deep research. PaperScope presents three advantages: (1) Structured scientific grounding. It is built on a knowledge graph of over 2,000 AI papers spanning three years, providing a structured foundation for research-oriented queries. (2) Semantically dense evidence construction. It integrates semantically related key information nodes and employs optimized random-walk article selector to sample thematically coherent paper sets, thereby ensuring adequate semantic density and task complexity. (3) Multi-task evaluation of scientific reasoning. It contains over 2,000 QA pairs across reasoning, retrieval, summarization, and problem solving, enabling evaluation of multi-step scientific reasoning. Experimental results show that even advanced systems such as OpenAI Deep Research and Tongyi Deep Research achieve limited scores on PaperScope, highlighting the difficulty of long-context retrieval and deep multi-source reasoning. PaperScope thus provides a rigorous benchmark alongside a scalable pipeline for constructing large-scale multi-modal, multi-source deep research datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
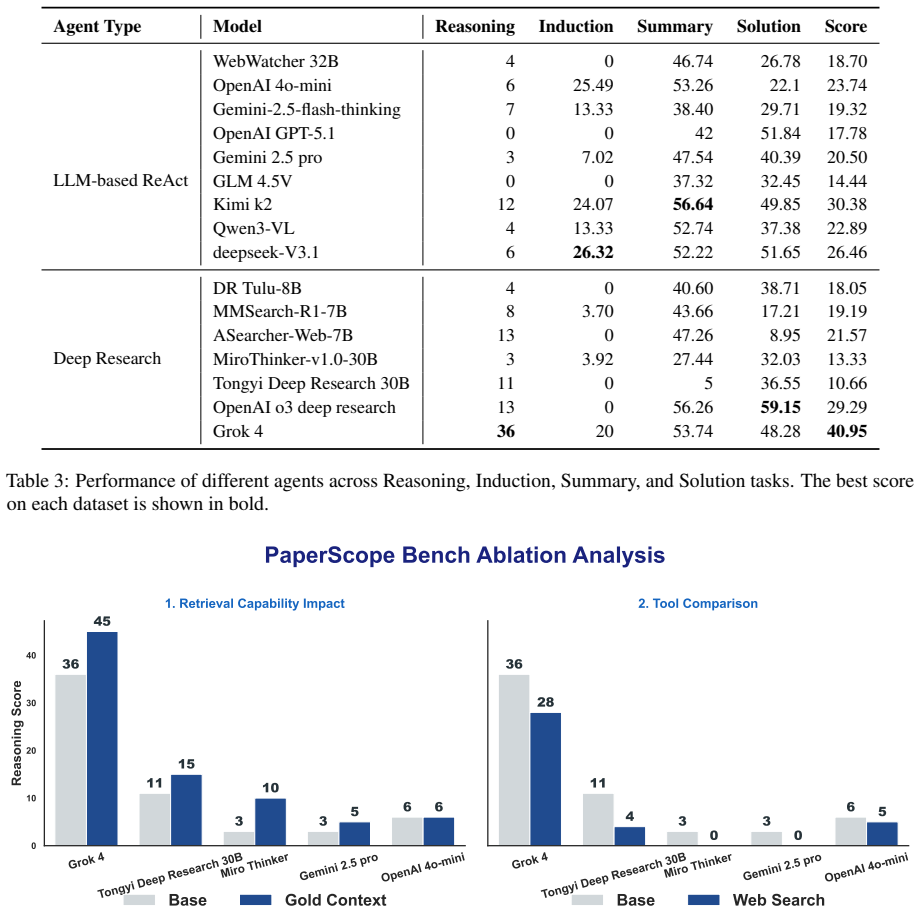
Summary. The paper introduces PaperScope, a multi-modal multi-document benchmark for evaluating agentic deep research on scientific papers. It is constructed from a knowledge graph of over 2,000 AI papers spanning three years; an optimized random-walk selector is used to sample thematically coherent paper sets with semantically dense evidence; and it provides over 2,000 QA pairs spanning reasoning, retrieval, summarization, and problem-solving tasks. Experiments indicate that even advanced systems such as OpenAI Deep Research and Tongyi Deep Research achieve only limited scores, which the authors interpret as evidence of the difficulty of long-context retrieval and deep multi-source reasoning. A scalable pipeline for constructing such datasets is also presented.
Significance. If the sampled paper collections are shown to be genuinely thematically coherent and representative of real multi-document scientific workflows, PaperScope would fill a clear gap between existing single-document benchmarks and the multi-modal, multi-source integration demands of frontier research. The scalable construction pipeline and the emphasis on agentic evaluation are strengths that could support reproducible progress in this area.
major comments (2)
- [Abstract] Abstract, advantage (2): the assertion that the optimized random-walk article selector produces 'thematically coherent paper sets' and 'adequate semantic density' is load-bearing for the central claim that low model scores demonstrate reasoning difficulty rather than benchmark artifacts. No quantitative validation (e.g., intra-set embedding similarity vs. random baselines, citation density, or expert coherence ratings) is described.
- [Abstract] Abstract, experimental results paragraph: the headline finding that advanced systems achieve 'limited scores' is presented without any description of the scoring rubrics, inter-annotator agreement, error analysis, or verification that the QA pairs actually require the intended multi-step, multi-modal reasoning. These details are required to interpret whether the benchmark supports the claimed difficulty.
minor comments (1)
- [Abstract] The abstract refers to 'multi-modal' elements (text, tables, figures) but does not specify how figures and tables are represented or retrieved in the QA pairs; a brief clarification in the methods would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which identifies key areas where additional evidence and clarity are needed to support the central claims of PaperScope. We address each major comment below and commit to revisions that strengthen the manuscript without misrepresenting our current results.
read point-by-point responses
-
Referee: [Abstract] Abstract, advantage (2): the assertion that the optimized random-walk article selector produces 'thematically coherent paper sets' and 'adequate semantic density' is load-bearing for the central claim that low model scores demonstrate reasoning difficulty rather than benchmark artifacts. No quantitative validation (e.g., intra-set embedding similarity vs. random baselines, citation density, or expert coherence ratings) is described.
Authors: We acknowledge that the current manuscript does not provide the requested quantitative validations for thematic coherence and semantic density. In the revised version, we will add a dedicated analysis section (or appendix) reporting intra-set embedding similarity scores against random baselines, citation density statistics within selected paper sets, and, where feasible, a small-scale expert coherence rating study. These additions will directly support the claim that low model performance reflects genuine multi-document reasoning challenges rather than artifacts of incoherent sampling. revision: yes
-
Referee: [Abstract] Abstract, experimental results paragraph: the headline finding that advanced systems achieve 'limited scores' is presented without any description of the scoring rubrics, inter-annotator agreement, error analysis, or verification that the QA pairs actually require the intended multi-step, multi-modal reasoning. These details are required to interpret whether the benchmark supports the claimed difficulty.
Authors: We agree that the abstract lacks these details and that they are necessary for proper interpretation. The full manuscript describes the evaluation protocol and task categories, but we will revise the abstract to briefly note the scoring approach and inter-annotator agreement. We will also expand the main text with (1) explicit scoring rubrics, (2) reported inter-annotator agreement metrics, (3) a categorized error analysis of model failures, and (4) representative QA examples that illustrate the required multi-step, multi-modal integration. These changes will better substantiate the difficulty claims. revision: yes
Circularity Check
No significant circularity; benchmark construction is methodological
full rationale
The paper introduces PaperScope as a benchmark built from a knowledge graph of >2,000 AI papers and an optimized random-walk selector for thematically coherent sets. No mathematical derivations, equations, fitted parameters, or predictions are presented that reduce to inputs by construction. Claims about semantic density and task complexity are asserted as design outcomes rather than derived results. Evaluation of external systems (OpenAI Deep Research, etc.) is empirical and independent. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. This is a standard benchmark paper whose core contribution is the dataset and pipeline itself, with no internal circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A knowledge graph of over 2,000 AI papers spanning three years provides a structured foundation for research-oriented queries.
- domain assumption Optimized random-walk article selection on semantically related nodes produces thematically coherent paper sets with adequate semantic density and task complexity.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 33rd ACM International Con- ference on Multimedia, pages 9110–9119
Researchpulse: Building method-experiment chains through multi-document scientific inference. InProceedings of the 33rd ACM International Con- ference on Multimedia, pages 9110–9119. Hao Cui, Zahra Shamsi, Gowoon Cheon, Xuejian Ma, Shutong Li, Maria Tikhanovskaya, Peter Norgaard, Nayantara Mudur, Martyna Plomecka, Paul Rac- cuglia, and 1 others. 2025. Cur...
-
[2]
Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl, 2025
Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl. Preprint, arXiv:2508.07976. Xinyu Geng, Peng Xia, Zhen Zhang, Xinyu Wang, Qiuchen Wang, Ruixue Ding, Chenxi Wang, Jia- long Wu, Yida Zhao, Kuan Li, and 1 others
-
[3]
Webwatcher: Breaking new frontier of vision-language deep research agent.arXiv preprint arXiv:2508.05748. Google. 2025a. Deep research is now available on gem- ini 2.5 pro experimental. Google. 2025b. Gemini 2.5 pro. https://deepmind. google/technologies/gemini/pro/. Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, a...
-
[4]
reads but does not understand
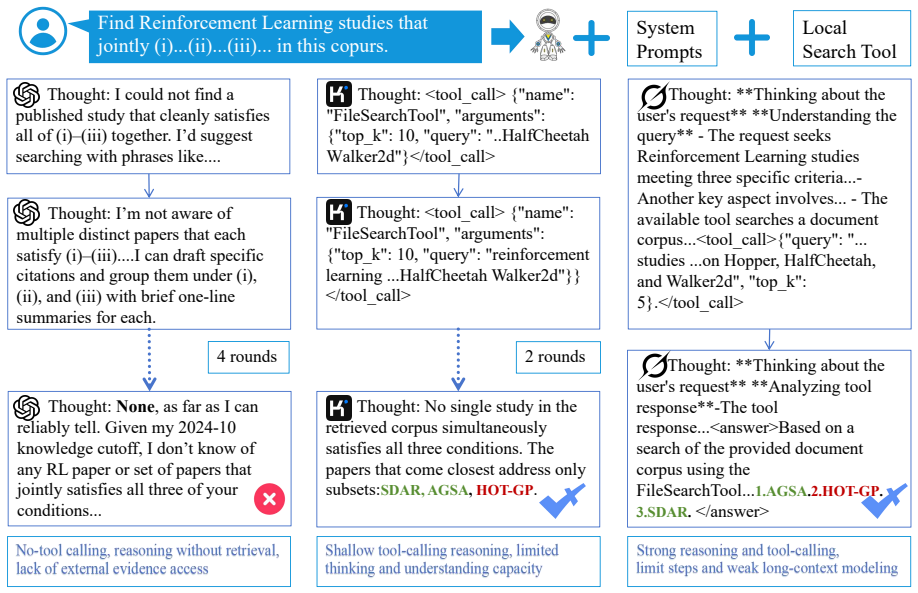
multi-modal Information Extraction is the Primary Weakness (37.5%):Surprisingly, fine-grained visual understanding bottlenecks the pipeline earlier than reasoning. Even when the correct paper is retrieved, the model often "reads but does not understand" (e.g., failing to align rows/columns in complex tables or extracting inaccurate coordinates from line charts)
-
[5]
Small deviations in initial metric extraction compound during comparisons, causing final answers to drift significantly
Error Accumulation in Multi-step Reason- ing (22.5%):In cross-paper synthesis tasks, models frequently err in intermediate steps. Small deviations in initial metric extraction compound during comparisons, causing final answers to drift significantly
-
[6]
The 15% hallucination rate is often a secondary ef- fect—when exact evidence is missed, models tend to generate speculative answers rather than abstaining
Retrieval Granularity and Hallucination (35% combined):Approximately 20% of er- rors stem from broad semantic search scopes failing to pinpoint specific papers. The 15% hallucination rate is often a secondary ef- fect—when exact evidence is missed, models tend to generate speculative answers rather than abstaining. F Usage of LLM In the preparation of thi...
-
[7]
find papers
Explicit Theme Query: - Explicitly ask for papers or prior work. - Clearly reflect the shared research theme implied by the paper titles and common entities. - Must incorporate the core concepts represented by the common entities, but avoid copying exact technical terms or phrases from titles or entities. - Use generalized, abstract, or paraphrased expres...
-
[8]
Find works that can help me process long video
Implicit Theme Query: - Do NOT explicitly ask for papers or literature. - Embed the specific problem within a practical, real-world scenario (e.g., "Find works that can help me process long video"). - The problem description should naturally require the methods, ideas, or solutions addressed collectively by the given papers. - Integrate the core theme imp...
-
[9]
You must evaluate the solution from **two dimensions**: (1) Analysis Score; (2) Technology Score Each score must be an integer between 0 and 100 (inclusive)
-
[10]
You must: - Enumerate each restrictive factor from the Analysis knowledge
Scoring criteria: (2.1) Analysis Score Evaluate whether the <<Model-generated solution>> adequately considers the restrictive factors listed in the Analysis knowledge. You must: - Enumerate each restrictive factor from the Analysis knowledge. - Check whether the solution explicitly or implicitly addresses each factor. - If addressed, determine whether the...
-
[11]
If Analysis knowledge, Technology knowledge, or Golden explanation is missing, base your evaluation primarily on similarity between the model-generated solution and the Golden solution in terms of analytical depth and technical correctness
-
[12]
Only correctness, coverage, and specificity relative to the Judgement reference matter
Length of the solution must not influence the score. Only correctness, coverage, and specificity relative to the Judgement reference matter
-
[13]
Analysis Score
**Output format constraint (strict):** You must output **only** a JSON object in the following format, with no additional text, explanation, or reasoning: {"Analysis Score": int, "Technology Score": int} Solution Evaluation Prompt Figure 11: The prompts used for solution task evaluation. System: System Prompt User Query: Across the ICLR 2025 papers, the m...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.