Recognition: unknown
CLASP: Closed-loop Asynchronous Spatial Perception for Open-vocabulary Desktop Object Grasping
Pith reviewed 2026-05-10 16:37 UTC · model grok-4.3
The pith
CLASP uses decoupled perception and closed-loop feedback to reach 87% success in open-vocabulary robot grasping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that a Dual-Pathway Hierarchical Perception module, which decouples semantic intent from geometric grounding to direct inference outputs, combined with an Asynchronous Closed-Loop Evaluator that produces diagnostic feedback from pre- and post-execution state comparisons, enables an 87% overall success rate. The system shows strong generalization across objects and robustness in cluttered scenes while bridging sim-to-real transfer through automatically synthesized spatial annotations.
What carries the argument
Dual-Pathway Hierarchical Perception module that decouples high-level semantic intent from geometric grounding to reduce spatial hallucinations, together with an Asynchronous Closed-Loop Evaluator that compares states and supplies text-based corrective feedback.
If this is right
- The framework outperforms prior baselines in overall grasping success.
- Performance holds across diverse objects without task-specific fine-tuning.
- Automatic synthesis of spatial annotations and reasoning templates removes the need for human teleoperation data.
- Robustness increases in cluttered scenes and categories with difficult geometry.
Where Pith is reading between the lines
- The same decoupling-plus-feedback pattern could support other language-guided manipulation skills beyond single-object grasping.
- Closed-loop text feedback may let models compensate for perception gaps that open-loop systems cannot recover from.
- Data engines that generate annotations from mixed real and synthetic scenes could speed development of grounded models for additional physical tasks.
Load-bearing premise
The perception module reliably removes spatial hallucinations and the evaluator always supplies accurate enough feedback to correct errors in changing real environments.
What would settle it
A sequence of trials in which objects shift position or lighting varies after the first grasp attempt, and the state-comparison step produces incorrect or missing diagnostic text, causing the robot to repeat the same error.
Figures



read the original abstract
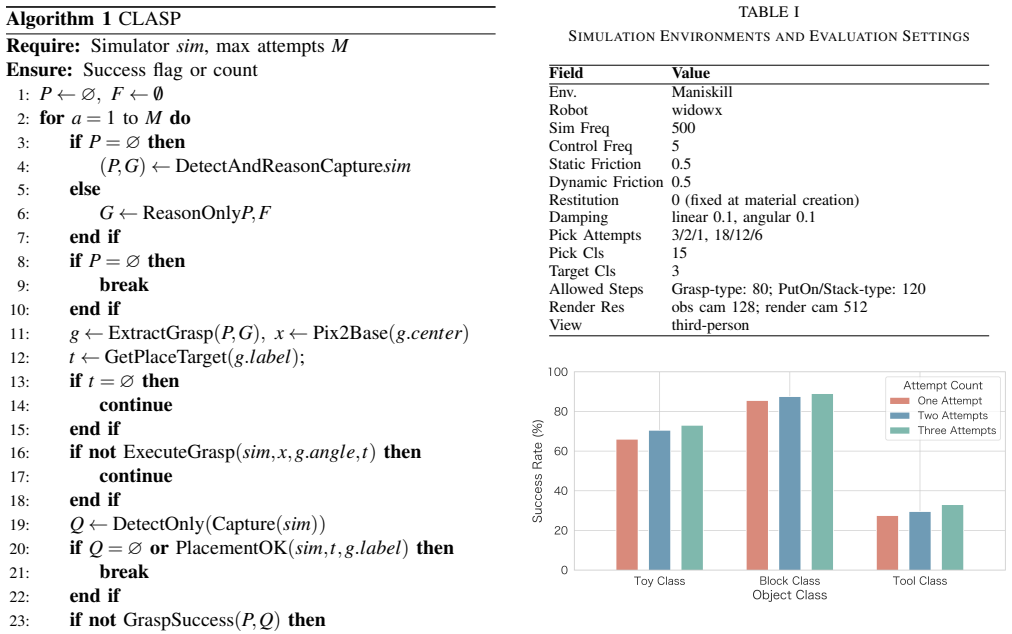
Robot grasping of desktop object is widely used in intelligent manufacturing, logistics, and agriculture.Although vision-language models (VLMs) show strong potential for robotic manipulation, their deployment in low-level grasping faces key challenges: scarce high-quality multimodal demonstrations, spatial hallucination caused by weak geometric grounding, and the fragility of open-loop execution in dynamic environments. To address these challenges, we propose Closed-Loop Asynchronous Spatial Perception(CLASP), a novel asynchronous closed-loop framework that integrates multimodal perception, logical reasoning, and state-reflective feedback. First, we design a Dual-Pathway Hierarchical Perception module that decouples high-level semantic intent from geometric grounding. The design guides the output of the inference model and the definite action tuples, reducing spatial illusions. Second, an Asynchronous Closed-Loop Evaluator is implemented to compare pre- and post-execution states, providing text-based diagnostic feedback to establish a robust error-correction loop and improving the vulnerability of traditional open-loop execution in dynamic environments. Finally, we design a scalable multi-modal data engine that automatically synthesizes high-quality spatial annotations and reasoning templates from real and synthetic scenes without human teleoperation. Extensive experiments demonstrate that our approach significantly outperforms existing baselines, achieving an 87.0% overall success rate. Notably, the proposed framework exhibits remarkable generalization across diverse objects, bridging the sim-to-real gap and providing exceptional robustness in geometrically challenging categories and cluttered scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CLASP, a closed-loop asynchronous framework for open-vocabulary desktop object grasping with vision-language models. It introduces a Dual-Pathway Hierarchical Perception module to separate high-level semantics from geometric grounding and reduce spatial hallucinations, an Asynchronous Closed-Loop Evaluator that compares pre- and post-execution states to generate text-based diagnostic feedback for error correction, and a scalable multi-modal data engine that synthesizes spatial annotations and reasoning templates from real and synthetic scenes without teleoperation. The central empirical claim is an 87.0% overall success rate that significantly outperforms baselines, with strong generalization across objects, sim-to-real transfer, and robustness in cluttered or geometrically challenging scenarios.
Significance. If the performance claims are substantiated with detailed experiments, the work would be significant for VLM-based robotic manipulation. It directly targets three persistent barriers (scarce demonstrations, spatial grounding failures, and open-loop fragility) with an integrated perception-reasoning-feedback architecture and an automated data pipeline. The data engine in particular offers a practical route to scalable training data and could influence downstream work on sim-to-real transfer and closed-loop control.
major comments (2)
- [Abstract and Experimental Results] Abstract and Experimental Results section: the central claim of an 87.0% overall success rate and 'significant' outperformance of baselines is presented without any reported trial counts, baseline descriptions, per-category breakdowns, error analysis, or statistical measures. This information is load-bearing for the generalization and robustness assertions and cannot be evaluated from the current text.
- [§3.2] §3.2 (Asynchronous Closed-Loop Evaluator): the description states that the module 'compares pre- and post-execution states' and supplies 'text-based diagnostic feedback,' yet no concrete state representation, comparison metric, or prompt template is given. Without these details it is impossible to assess whether the evaluator can reliably detect and correct the failure modes claimed in dynamic environments.
minor comments (3)
- [Abstract] Abstract: 'Robot grasping of desktop object is widely used' contains a subject-verb agreement error and should read 'Robot grasping of desktop objects is widely used.'
- [Abstract] Abstract: 'Perception(CLASP)' is missing a space before the parenthesis; it should be 'Perception (CLASP)'.
- [Experimental Results] The manuscript would benefit from a table summarizing the experimental conditions (object categories, clutter levels, success criteria) to make the 87% figure interpretable.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. Where the comments correctly identify insufficient detail in the current manuscript, we have revised the text to incorporate the requested information and clarifications.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] Abstract and Experimental Results section: the central claim of an 87.0% overall success rate and 'significant' outperformance of baselines is presented without any reported trial counts, baseline descriptions, per-category breakdowns, error analysis, or statistical measures. This information is load-bearing for the generalization and robustness assertions and cannot be evaluated from the current text.
Authors: We agree with the referee that the abstract and experimental summary lack the supporting details necessary to fully substantiate the performance claims. In the revised manuscript we have updated the abstract to reference the experimental scale and have expanded the Experimental Results section to explicitly report the total number of trials, provide descriptions of all baselines, include per-category success-rate breakdowns, present a categorized error analysis, and report statistical measures including confidence intervals and significance tests. These additions make the central claims directly evaluable from the text. revision: yes
-
Referee: [§3.2] §3.2 (Asynchronous Closed-Loop Evaluator): the description states that the module 'compares pre- and post-execution states' and supplies 'text-based diagnostic feedback,' yet no concrete state representation, comparison metric, or prompt template is given. Without these details it is impossible to assess whether the evaluator can reliably detect and correct the failure modes claimed in dynamic environments.
Authors: We acknowledge that the current description of the Asynchronous Closed-Loop Evaluator remains at a high level and does not supply the concrete implementation details required for assessment. We have revised §3.2 to define the state representation, specify the comparison metrics between pre- and post-execution observations, and include the prompt template used to produce the diagnostic feedback. The revised section also references supporting pseudocode and examples now placed in the appendix. revision: yes
Circularity Check
No significant circularity; empirical system report only
full rationale
The paper describes a proposed robotic grasping framework (Dual-Pathway Hierarchical Perception module and Asynchronous Closed-Loop Evaluator) followed by an empirical performance claim of 87% success rate. No equations, derivations, fitted parameters, or mathematical predictions appear in the abstract or described architecture. The central result is an experimental outcome rather than a derived quantity, so no load-bearing step reduces to its own inputs by construction, self-citation, or renaming. The derivation chain is absent, rendering circularity analysis inapplicable.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vision-language models can be guided via decoupled pathways to reduce spatial hallucinations and provide reliable logical reasoning
- domain assumption Automated synthesis from real and synthetic scenes produces high-quality spatial annotations and reasoning templates comparable to human data
invented entities (2)
-
Dual-Pathway Hierarchical Perception module
no independent evidence
-
Asynchronous Closed-Loop Evaluator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anygrasp: Robust and efficient grasp perception in spatial and temporal domains,
H.-S. Fang, C. Wang, H. Fang, M. Gou, J. Liu, H. Yan, W. Liu, Y . Xie, and C. Lu, “Anygrasp: Robust and efficient grasp perception in spatial and temporal domains,”IEEE Transactions on Robotics, vol. 39, no. 5, pp. 3929–3945, 2023
2023
-
[2]
Graspnet: A large-scale clustered and densely annotated dataset for object grasping,
H.-S. Fang, C. Wang, M. Gou, and C. Lu, “Graspnet: A large-scale clustered and densely annotated dataset for object grasping,”arXiv preprint arXiv:1912.13470, 2019
-
[3]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inCoRL, 2023
2023
-
[4]
Openvla: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuonget al., “Openvla: An open-source vision-language-action model,” inCoRL, 2025
2025
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “π 0: A vision- language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” in Advances in Neural Information Processing Systems, vol. 36, 2023, pp. 34 892–34 916
2023
-
[7]
The dawn of lmms: Preliminary explorations with gpt-4v (ision)
Z. Yang, L. Li, K. Lin, J. Wang, C.-C. Lin, Z. Liu, and L. Wang, “The dawn of lmms: Preliminary explorations with gpt-4v(ision),”arXiv preprint arXiv:2309.17421, 2023
-
[8]
arXiv preprint arXiv:2510.12798 (2025) 3
Q. Jiang, J. Huo, X. Chen, Y . Xiong, Z. Zeng, Y . Chen, T. Ren, J. Yu, and L. Zhang, “Detect anything via next point prediction,”arXiv preprint arXiv:2510.12798, 2025
-
[9]
Dexrepnet: Learning dexterous robotic grasping network with ge- ometric and spatial hand-object representations,
Q. Liu, Y . e. Cui, Q. Ye, Z. Sun, H. Li, G. Li, L. Shao, and J. Chen, “Dexrepnet: Learning dexterous robotic grasping network with ge- ometric and spatial hand-object representations,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023, pp. 3153–3160
2023
-
[10]
Contactdexnet: Multi-fingered robotic hand grasping in cluttered environments through hand-object contact semantic mapping,
L. Zhang, K. Bai, G. Huang, Z. Bing, Z. Chen, A. Knoll, and J. Zhang, “Contactdexnet: Multi-fingered robotic hand grasping in cluttered environments through hand-object contact semantic mapping,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025, pp. 8495–8502
2025
-
[11]
Slip detection for grasp stabiliza- tion with a multifingered tactile robot hand,
J. W. James and N. F. Lepora, “Slip detection for grasp stabiliza- tion with a multifingered tactile robot hand,”IEEE Transactions on Robotics, vol. 37, no. 2, pp. 506–519, 2021
2021
-
[12]
Gat-grasp: Gesture- driven affordance transfer for task-aware robotic grasping,
R. Wang, H. Zhou, X. Yao, G. Liu, and K. Jia, “Gat-grasp: Gesture- driven affordance transfer for task-aware robotic grasping,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025, pp. 1076–1083
2025
-
[13]
Gaze-guided 3d hand motion prediction for detecting intent in egocentric grasping tasks,
Y . He, X. Zhang, and A. H. A. Stienen, “Gaze-guided 3d hand motion prediction for detecting intent in egocentric grasping tasks,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025, pp. 14 580–14 586
2025
-
[14]
Grasp manipulation relationship detection based on graph sample and aggregation,
J. Luo, Y . Liu, H. Wang, M. Ding, and X. Lan, “Grasp manipulation relationship detection based on graph sample and aggregation,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 4098–4104
2024
-
[15]
Hybrid robotic grasping with a soft multimodal gripper and a deep multistage learning scheme,
F. Liu, F. Sun, B. Fang, X. Li, S. Sun, and H. Liu, “Hybrid robotic grasping with a soft multimodal gripper and a deep multistage learning scheme,”IEEE Transactions on Robotics, vol. 39, no. 3, pp. 2379– 2399, 2023
2023
-
[16]
Motion planning for robotic manipulation of deformable linear objects,
M. Saha and P. Isto, “Motion planning for robotic manipulation of deformable linear objects,” in2006 IEEE International Conference on Robotics and Automation (ICRA), 2006, pp. 2478–2484
2006
-
[17]
Robotic pick-and-place with uncertain object instance segmentation and shape completion,
M. Gualtieri and R. Platt, “Robotic pick-and-place with uncertain object instance segmentation and shape completion,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 1753–1760, 2021
2021
-
[18]
A reconfigurable gripper for robotic au- tonomous depalletizing in supermarket logistics,
G. A. Fontanelliet al., “A reconfigurable gripper for robotic au- tonomous depalletizing in supermarket logistics,”IEEE Robotics and Automation Letters, vol. 5, no. 3, pp. 4612–4617, 2020
2020
-
[19]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[20]
Blip: Bootstrapping language- image pre-training for unified vision-language understanding and gen- eration,
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language- image pre-training for unified vision-language understanding and gen- eration,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 12 888–12 900
2022
-
[21]
Affordgrasp: In-context affordance reasoning for open-vocabulary task-oriented grasping in clutter,
Y . Tang, S. Zhang, X. Hao, P. Wang, J. Wu, Z. Wang, and S. Zhang, “Affordgrasp: In-context affordance reasoning for open-vocabulary task-oriented grasping in clutter,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 9433–9439
2025
-
[22]
arXiv preprint arXiv:2404.11000 (2024)
E. Tong, A. Opipari, S. Lewis, Z. Zeng, and O. C. Jenkins, “Oval-prompt: Open-vocabulary affordance localization for robot manipulation through llm affordance-grounding,”arXiv preprint arXiv:2404.11000, 2024
-
[23]
Thinkgrasp: A vision-language system for strategic part grasping in clutter,
Y . Qian, X. Zhu, O. Biza, S. Jiang, L. Zhao, H. Huang, Y . Qi, and R. Platt, “Thinkgrasp: A vision-language system for strategic part grasping in clutter,”arXiv preprint arXiv:2407.11298, 2024
-
[24]
Dexvlg: Dexterous vision-language-grasp model at scale,
J. He, D. Li, X. Yu, Z. Qi, W. Zhang, J. Chen, Z. Zhang, Z. Zhang, L. Yi, and H. Wang, “Dexvlg: Dexterous vision-language-grasp model at scale,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 14 248–14 258
2025
-
[25]
Dexgrasp anything: Towards universal robotic dexterous grasping with physics awareness,
Y . Zhong, Q. Jiang, J. Yu, and Y . Ma, “Dexgrasp anything: Towards universal robotic dexterous grasping with physics awareness,” inPro- ceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22 584–22 594
2025
-
[26]
Understanding 3d object interaction from a single image,
S. Qian and D. F. Fouhey, “Understanding 3d object interaction from a single image,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 21 753–21 763
2023
-
[27]
Egoobjects: A large-scale egocentric dataset for fine-grained object understanding,
C. Zhu, F. Xiao, A. Alvarado, Y . Babaei, J. Hu, H. El-Mohri, S. Cula- tana, R. Sumbaly, and Z. Yan, “Egoobjects: A large-scale egocentric dataset for fine-grained object understanding,” inProceedings of the IEEE/CVF international conference on computer vision (ICCV), 2023, pp. 20 110–20 120
2023
-
[28]
Open x-embodiment: Robotic learning datasets and rt-x models,
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jainet al., “Open x-embodiment: Robotic learning datasets and rt-x models,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 6892–6903
2024
-
[29]
Rlbench: The robot learning benchmark & learning environment,
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison, “Rlbench: The robot learning benchmark & learning environment,”IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 3019–3026, 2020
2020
-
[30]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Geet al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
D. Guo, F. Wu, F. Zhu, F. Leng, G. Shi, Chenet al., “Seed1.5-VL Technical Report,” 2025, arXiv:2505.07062 [cs]
work page internal anchor Pith review arXiv 2025
-
[32]
Affordancenet: An end-to-end deep learning approach for object affordance detection,
T.-T. Do, A. Nguyen, and I. Reid, “Affordancenet: An end-to-end deep learning approach for object affordance detection,” in2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 5882–5889
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.