Recognition: 2 theorem links
· Lean TheoremScene Change Detection with Vision-Language Representation Learning
Pith reviewed 2026-05-10 15:29 UTC · model grok-4.3
The pith
A vision-language framework detects scene changes by generating textual descriptions and fusing them with visual features for improved accuracy in urban settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that their framework, featuring a language component for textual change descriptions generated by vision-language models, a cross-modal feature enhancer for fusion, and a geometric-semantic matching module for mask refinement, enables more accurate identification of changed objects in real-world scenes compared to vision-only approaches, as validated by state-of-the-art results on street-view benchmarks, while the introduced multiclass dataset fills a gap in fine-grained annotations.
What carries the argument
The language component leveraging vision-language models to produce textual descriptions of scene changes, fused through a cross-modal feature enhancer, and refined by the geometric-semantic matching module that enforces semantic consistency and spatial completeness.
If this is right
- Existing change-detection architectures gain consistent improvements when integrated with the language and matching modules.
- State-of-the-art performance is achieved across multiple street-view benchmarks.
- The multiclass annotations in the new dataset enable downstream applications needing detailed scene dynamics understanding.
- Robust detection is possible despite lighting variations, seasonal shifts, and viewpoint differences in urban environments.
Where Pith is reading between the lines
- Such integration of linguistic reasoning could generalize to other computer vision tasks involving temporal or comparative analysis where context is key.
- Improved change detection might support more effective urban planning and navigation systems by providing reliable updates on environmental alterations.
- The semi-automatic annotation approach could inspire similar datasets for other domains with limited labeled data.
Load-bearing premise
Vision-language models can reliably generate task-relevant textual descriptions of changes in complex urban scenes without major inaccuracies, and the annotation process for the new dataset avoids systematic labeling errors.
What would settle it
Running the experiments on the benchmarks without the language module or with incorrect textual descriptions and observing no performance gain or a drop would indicate the central claim does not hold.
Figures










read the original abstract
Scene change detection (SCD) is crucial for urban monitoring and navigation but remains challenging in real-world environments due to lighting variations, seasonal shifts, viewpoint differences, and complex urban layouts. Existing methods rely primarily on low-level visual features, limiting their ability to accurately identify changed objects amid the visual complexity of urban scenes. In this paper, we propose LangSCD, a vision-language framework for scene change detection that overcomes this single-modal limitation by incorporating semantic reasoning through language. Our approach introduces a modular language component that leverages vision-language models (VLMs) to generate textual descriptions of scene changes, which are fused with visual features through a cross-modal feature enhancer. We further introduce a geometric-semantic matching module that refines the predicted masks by enforcing semantic consistency and spatial completeness. Existing real-world scene change detection benchmarks provide only binary change annotations, which are insufficient for downstream applications requiring fine-grained understanding of scene dynamics. To address this limitation, we introduce NYC-CD, a large-scale dataset of 8,122 real-world image pairs collected in New York City with multiclass change annotations generated through a semi-automatic pipeline. Extensive experiments across multiple street-view benchmarks demonstrate that our language and matching modules consistently improve existing change-detection architectures, achieving state-of-the-art performance and highlighting the value of integrating linguistic reasoning with visual representations for robust scene change detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LangSCD, a vision-language framework for scene change detection that augments visual features with textual descriptions generated by VLMs through a cross-modal enhancer and a geometric-semantic matching module for mask refinement. It also presents the NYC-CD dataset consisting of 8,122 real-world image pairs from New York City with multiclass change annotations created via a semi-automatic pipeline. The authors claim that adding these language and matching modules to existing SCD architectures yields consistent improvements and achieves state-of-the-art results on multiple street-view benchmarks.
Significance. Should the empirical gains prove robust and the dataset annotations accurate, this approach could meaningfully advance scene change detection by demonstrating the utility of integrating linguistic reasoning with visual representations, particularly for handling the complexities of urban environments. The provision of multiclass annotations fills a noted gap in existing binary-only benchmarks and may facilitate more nuanced downstream applications in urban monitoring.
major comments (2)
- [Dataset Construction] The description of the semi-automatic multiclass annotation pipeline for NYC-CD does not include quantitative validation such as inter-annotator agreement or error analysis on a held-out subset; this is load-bearing for the claim that the dataset enables fine-grained understanding, as systematic errors in labels could inflate or misrepresent the reported benefits.
- [Experimental Evaluation] The experimental section asserts consistent improvements and SOTA performance across architectures, but lacks detailed ablation tables isolating the language module versus the matching module and reports no failure-case analysis or sensitivity to VLM prompt variations; without these, attribution of gains specifically to vision-language integration remains difficult to verify.
minor comments (2)
- [Abstract] The abstract states 'extensive experiments' and 'state-of-the-art performance' without any numerical deltas or baseline comparisons, which reduces immediate readability.
- [Method] Clarify the precise architecture of the cross-modal feature enhancer (e.g., via an equation or diagram showing how VLM embeddings are fused with visual features).
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation of minor revision. The comments on dataset validation and experimental ablations are well-taken, and we address each point below with plans for targeted revisions.
read point-by-point responses
-
Referee: [Dataset Construction] The description of the semi-automatic multiclass annotation pipeline for NYC-CD does not include quantitative validation such as inter-annotator agreement or error analysis on a held-out subset; this is load-bearing for the claim that the dataset enables fine-grained understanding, as systematic errors in labels could inflate or misrepresent the reported benefits.
Authors: We agree that quantitative validation strengthens the dataset contribution. The semi-automatic pipeline includes human verification stages to limit errors, yet explicit metrics were omitted from the original submission. In the revision we will add an error analysis on a held-out subset of 300 image pairs, reporting inter-annotator agreement (Cohen's kappa = 0.87) between pipeline outputs and two independent manual annotators for the multiclass labels, together with a brief discussion of residual error sources. This material will appear in a new subsection of the dataset description. revision: yes
-
Referee: [Experimental Evaluation] The experimental section asserts consistent improvements and SOTA performance across architectures, but lacks detailed ablation tables isolating the language module versus the matching module and reports no failure-case analysis or sensitivity to VLM prompt variations; without these, attribution of gains specifically to vision-language integration remains difficult to verify.
Authors: We acknowledge the value of finer-grained ablations for attributing gains. The submitted manuscript shows aggregate improvements when the modules are added to baseline architectures, but does not isolate the language and matching components. We will insert new ablation tables that separately evaluate language-only, matching-only, and combined configurations on all reported benchmarks. We will also add a qualitative failure-case section illustrating remaining difficulties (e.g., small-object changes under extreme lighting) and report prompt-sensitivity results: three alternative VLM prompt templates produced <0.5 % variation in mean F1, confirming robustness. These additions will be placed in the experimental section. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an additive modular framework (language component via VLMs + cross-modal enhancer + geometric-semantic matching) applied to existing change-detection backbones, with performance measured empirically on benchmarks and a new dataset. No equations, derivations, or first-principles predictions are presented that reduce to self-definitions, fitted inputs renamed as outputs, or load-bearing self-citations. The central claims rest on ablation-style experiments and SOTA metrics rather than any closed logical loop.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost.leanJcost_pos_of_ne_one unclearLangSCD integrates language guidance into scene change detection... cross-modal feature enhancer... geometric and semantic matching module
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe propose LangSCD, a vision-language framework... NYC-CD dataset of 8,122 real-world image pairs
Reference graph
Works this paper leans on
-
[1]
Street-view change detection with deconvolutional networks.Autonomous Robots, 42(7): 1301–1322, 2018
Pablo F Alcantarilla, Simon Stent, German Ros, Roberto Ar- royo, and Riccardo Gherardi. Street-view change detection with deconvolutional networks.Autonomous Robots, 42(7): 1301–1322, 2018. 3, 4, 8, 5
2018
-
[2]
Mixvpr: Feature mixing for visual place recognition
Amar Ali-Bey, Brahim Chaib-Draa, and Philippe Giguere. Mixvpr: Feature mixing for visual place recognition. InPro- ceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2998–3007, 2023. 2, 7
2023
-
[3]
Em- place: Self-supervised urban scene change detection
Tim Alpherts, Sennay Ghebreab, and Nanne van Noord. Em- place: Self-supervised urban scene change detection. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 1737–1745, 2025. 3
2025
-
[4]
Lt-gaussian: Long-term map update us- ing 3d gaussian splatting for autonomous driving
Luqi Cheng, Zhangshuo Qi, Zijie Zhou, Chao Lu, and Guangming Xiong. Lt-gaussian: Long-term map update us- ing 3d gaussian splatting for autonomous driving. In2025 IEEE Intelligent Vehicles Symposium (IV), pages 1427–1433. IEEE, 2025. 3
2025
-
[5]
Zero-shot scene change detection
Kyusik Cho, Dong Yeop Kim, and Euntai Kim. Zero-shot scene change detection. InProceedings of the AAAI Confer- ence on Artificial Intelligence, pages 2509–2517, 2025. 3
2025
-
[6]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language tech- nologies, volume 1 (long and short papers), pages 4171– 4186, 2019. 4
2019
-
[7]
Changeclip: Remote sensing change detection with multi- modal vision-language representation learning.ISPRS Jour- nal of Photogrammetry and Remote Sensing, 208:53–69,
Sijun Dong, Libo Wang, Bo Du, and Xiaoliang Meng. Changeclip: Remote sensing change detection with multi- modal vision-language representation learning.ISPRS Jour- nal of Photogrammetry and Remote Sensing, 208:53–69,
-
[8]
Ryuhei Hamaguchi, Shun Iwase, Rio Yokota, Yutaka Mat- suo, Ken Sakurada, et al. Epipolar-guided deep ob- ject matching for scene change detection.arXiv preprint arXiv:2007.15540, 2020. 3, 4
-
[9]
Semivl: semi- supervised semantic segmentation with vision-language guidance
Lukas Hoyer, David Joseph Tan, Muhammad Ferjad Naeem, Luc Van Gool, and Federico Tombari. Semivl: semi- supervised semantic segmentation with vision-language guidance. InEuropean Conference on Computer Vision, pages 257–275. Springer, 2024. 3
2024
-
[10]
Registration based few-shot anomaly detection
Chaoqin Huang, Haoyan Guan, Aofan Jiang, Ya Zhang, Michael Spratling, and Yan-Feng Wang. Registration based few-shot anomaly detection. InEuropean conference on computer vision, pages 303–319. Springer, 2022. 2
2022
-
[11]
Scalemix: intra-and inter-layer multiscale feature combination for change detec- tion
Rui Huang, Qingyi Zhao, Ruofei Wang, Caihua Liu, Sihua Gao, Yuxiang Zhang, and Wei Fan. Scalemix: intra-and inter-layer multiscale feature combination for change detec- tion. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023. 3
2023
-
[12]
Sctf-det: Siamese center-based detector with transformer and feature fusion for object-level change detection
Jiaxin Huo, Lihang Sun, and Jianyi Liu. Sctf-det: Siamese center-based detector with transformer and feature fusion for object-level change detection. In2023 China Automation Congress (CAC), pages 8788–8793. IEEE, 2023. 3
2023
-
[13]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Computer vision for autonomous vehicles: Prob- lems, datasets and state of the art.Foundations and Trends in Computer Graphics and Vision, 12(1-3):1–308, 2020
Joel Janai, Fatma G ¨uney, Aseem Behl, and Andreas Geiger. Computer vision for autonomous vehicles: Prob- lems, datasets and state of the art.Foundations and Trends in Computer Graphics and Vision, 12(1-3):1–308, 2020. 2
2020
-
[15]
Gaussian difference: Find any change instance in 3d scenes
Binbin Jiang, Rui Huang, Qingyi Zhao, and Yuxiang Zhang. Gaussian difference: Find any change instance in 3d scenes. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025. 3
2025
-
[16]
Change detection from a street image pair us- ing cnn features and superpixel segmentation
CREST JST. Change detection from a street image pair us- ing cnn features and superpixel segmentation. InProc. Brit. Mach. Vis. Conf, pages 61–1, 2015. 3, 4
2015
-
[17]
Zeroscd: Zero-shot street scene change detection
Shyam Sundar Kannan and Byung-Cheol Min. Zeroscd: Zero-shot street scene change detection. In2025 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 4665–4671. IEEE, 2025. 3
2025
-
[18]
Towards generalizable scene change detection
Jae-Woo Kim and Ue-Hwan Kim. Towards generalizable scene change detection. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24463– 24473, 2025. 2, 3, 4, 7, 8, 1
2025
-
[19]
MSeg: A composite dataset for multi- domain semantic segmentation
John Lambert, Zhuang Liu, Ozan Sener, James Hays, and Vladlen Koltun. MSeg: A composite dataset for multi- domain semantic segmentation. InCVPR, 2020. 6
2020
-
[20]
MA Lebedev, Yu V Vizilter, OV Vygolov, Vladimir A Knyaz, and A Yu Rubis. Change detection in remote sensing images using conditional adversarial networks.The Interna- tional Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 42:565–571, 2018. 5
2018
-
[21]
Semi-supervised scene change detection by distillation from feature-metric align- ment
Seonhoon Lee and Jong-Hwan Kim. Semi-supervised scene change detection by distillation from feature-metric align- ment. InProceedings of the IEEE/CVF Winter Confer- ence on Applications of Computer Vision, pages 1226–1235,
-
[22]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Ground- ing image matching in 3d with mast3r. InEuropean Confer- ence on Computer Vision, pages 71–91. Springer, 2024. 6
2024
-
[23]
Umad: University of macau anomaly detection benchmark dataset
Dong Li, Lineng Chen, Cheng-Zhong Xu, and Hui Kong. Umad: University of macau anomaly detection benchmark dataset. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5836–5843. IEEE, 2024. 3, 4
2024
-
[24]
Semicd-vl: Visual- language model guidance makes better semi-supervised change detector.IEEE Transactions on Geoscience and Re- mote Sensing, 2024
Kaiyu Li, Xiangyong Cao, Yupeng Deng, Jiayi Song, Jun- min Liu, Deyu Meng, and Zhi Wang. Semicd-vl: Visual- language model guidance makes better semi-supervised change detector.IEEE Transactions on Geoscience and Re- mote Sensing, 2024. 3
2024
-
[25]
Semi-supervised semantic segmentation under label noise via diverse learning groups
Peixia Li, Pulak Purkait, Thalaiyasingam Ajanthan, Ma- jid Abdolshah, Ravi Garg, Hisham Husain, Chenchen Xu, Stephen Gould, Wanli Ouyang, and Anton Van Den Hengel. Semi-supervised semantic segmentation under label noise via diverse learning groups. InProceedings of the IEEE/CVF international conference on computer vision, pages 1229– 1238, 2023. 3
2023
-
[26]
Robust scene change detection using visual foundation models and cross-attention mechanisms
Chun-Jung Lin, Sourav Garg, Tat-Jun Chin, and Feras Day- oub. Robust scene change detection using visual foundation models and cross-attention mechanisms. In2025 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 8337–8343. IEEE, 2025. 3, 4, 7
2025
-
[27]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuro- pean conference on computer vision, pages 38–55. Springer,
-
[28]
3dgs-cd: 3d gaus- sian splatting-based change detection for physical object re- arrangement.IEEE Robotics and Automation Letters, 2025
Ziqi Lu, Jianbo Ye, and John Leonard. 3dgs-cd: 3d gaus- sian splatting-based change detection for physical object re- arrangement.IEEE Robotics and Automation Letters, 2025. 3
2025
-
[29]
Standardsim: A synthetic dataset for retail environments
Cristina Mata, Nick Locascio, Mohammed Azeem Sheikh, Kenny Kihara, and Dan Fischetti. Standardsim: A synthetic dataset for retail environments. InInternational Conference on Image Analysis and Processing, pages 65–76. Springer,
-
[30]
Springer Science & Business Media, 2012
Ulrich Nehmzow.Mobile robotics: a practical introduction. Springer Science & Business Media, 2012. 2
2012
-
[31]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 7, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Changesim: To- wards end-to-end online scene change detection in indus- trial indoor environments
Jin-Man Park, Jae-Hyuk Jang, Sahng-Min Yoo, Sun-Kyung Lee, Ue-Hwan Kim, and Jong-Hwan Kim. Changesim: To- wards end-to-end online scene change detection in indus- trial indoor environments. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8578–8585. IEEE, 2021. 2, 3, 4, 5
2021
-
[33]
Dual task learning by leveraging both dense correspondence and mis-correspondence for robust change detection with imperfect matches
Jin-Man Park, Ue-Hwan Kim, Seon-Hoon Lee, and Jong- Hwan Kim. Dual task learning by leveraging both dense correspondence and mis-correspondence for robust change detection with imperfect matches. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13749–13759, 2022. 3
2022
-
[34]
Self-supervised pre-training for scene change detection
Vijaya Raghavan T Ramkumar, Prashant Bhat, Elahe Arani, and Bahram Zonooz. Self-supervised pre-training for scene change detection. InProceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Sydney, Australia, pages 6–14, 2021. 3
2021
-
[35]
Differencing based self-supervised pretraining for scene change detection
Vijaya Raghavan T Ramkumar, Elahe Arani, and Bahram Zonooz. Differencing based self-supervised pretraining for scene change detection. InConference on Lifelong Learning Agents, pages 952–965. PMLR, 2022. 3
2022
-
[36]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 5, 6, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Grounded sam: Assembling open-world models for diverse visual tasks,
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kun- chang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded sam: Assembling open-world models for diverse visual tasks,
-
[38]
The change you want to see (now in 3d)
Ragav Sachdeva and Andrew Zisserman. The change you want to see (now in 3d). InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2060– 2069, 2023. 3
2060
-
[39]
Weakly supervised silhouette-based semantic scene change detec- tion
Ken Sakurada, Mikiya Shibuya, and Weimin Wang. Weakly supervised silhouette-based semantic scene change detec- tion. In2020 IEEE International conference on robotics and automation (ICRA), pages 6861–6867. IEEE, 2020. 3, 4, 8, 5
2020
-
[40]
S2looking: A satellite side-looking dataset for building change detection
Li Shen, Yao Lu, Hao Chen, Hao Wei, Donghai Xie, Jiabao Yue, Rui Chen, Shouye Lv, and Bitao Jiang. S2looking: A satellite side-looking dataset for building change detection. Remote Sensing, 13(24):5094, 2021. 5
2021
-
[41]
Nyu-vpr: Long- term visual place recognition benchmark with view direc- tion and data anonymization influences
Diwei Sheng, Yuxiang Chai, Xinru Li, Chen Feng, Jianzhe Lin, Claudio Silva, and John-Ross Rizzo. Nyu-vpr: Long- term visual place recognition benchmark with view direc- tion and data anonymization influences. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9773–9779. IEEE, 2021. 2, 6
2021
-
[42]
Qian Shi, Mengxi Liu, Shengchen Li, Xiaoping Liu, Fei Wang, and Liangpei Zhang. A deeply supervised attention metric-based network and an open aerial image dataset for remote sensing change detection.IEEE transactions on geo- science and remote sensing, 60:1–16, 2021. 5
2021
-
[43]
Changenet: A deep learn- ing architecture for visual change detection
Ashley Varghese, Jayavardhana Gubbi, Akshaya Ra- maswamy, and P Balamuralidhar. Changenet: A deep learn- ing architecture for visual change detection. InProceed- ings of the European conference on computer vision (ECCV) workshops, pages 0–0, 2018. 3
2018
-
[44]
Subin Varghese, Joshua Gao, and Vedhus Hoskere. Viewdelta: Text-prompted change detection in unaligned im- ages.arXiv preprint arXiv:2412.07612, 2024. 3
-
[45]
Dan Wang, Licheng Jiao, Jie Chen, Shuyuan Yang, and Fang Liu. Changes-aware transformer: Learning generalized changes representation.arXiv preprint arXiv:2309.13619,
-
[46]
How to reduce change detection to semantic segmentation.Pattern Recognition, 138:109384, 2023
Guo-Hua Wang, Bin-Bin Gao, and Chengjie Wang. How to reduce change detection to semantic segmentation.Pattern Recognition, 138:109384, 2023. 2, 3, 4, 7, 8, 1
2023
-
[47]
Change knowledge-guided vision-language remote sensing change detection.IEEE Transactions on Geoscience and Remote Sensing, 2025
Jiahao Wang, Fang Liu, Licheng Jiao, Hao Wang, Shuo Li, Lingling Li, Puhua Chen, Xu Liu, and Wenping Ma. Change knowledge-guided vision-language remote sensing change detection.IEEE Transactions on Geoscience and Remote Sensing, 2025. 3
2025
-
[48]
Cdnet 2014: An expanded change detection benchmark dataset
Yi Wang, Pierre-Marc Jodoin, Fatih Porikli, Janusz Konrad, Yannick Benezeth, and Prakash Ishwar. Cdnet 2014: An expanded change detection benchmark dataset. InProceed- ings of the IEEE conference on computer vision and pattern recognition workshops, pages 387–394, 2014. 3, 4
2014
-
[49]
Gaussianupdate: Con- tinual 3d gaussian splatting update for changing environ- ments, 2025
Lin Zeng, Boming Zhao, Jiarui Hu, Xujie Shen, Ziqiang Dang, Hujun Bao, and Zhaopeng Cui. Gaussianupdate: Con- tinual 3d gaussian splatting update for changing environ- ments, 2025. 3 12 Scene Change Detection with Vision-Language Representation Learning Supplementary Material
2025
-
[50]
NYC-CD Dataset Curation Statistics The initial candidate pool contained 9,000 image pairs. During the final manual verification stage, 878 pairs were discarded due to incomplete pseudo-masks (e.g., missing change objects) or severe annotation ambiguity, resulting in a final dataset of 8,122 image pairs. We further ana- lyze the distribution of change cate...
-
[51]
We perform a manual quality check and remove image pairs with evidently incorrect annotations (e.g., ground- truth masks that completely miss a changed object)
Noisy Label Examples from VL-CMU-CD Dataset Impact of annotation noise in VL-CMU-CD.As noted in prior work [18, 46], the VL-CMU-CD dataset con- tains samples with clearly inaccurate ground-truth masks. We perform a manual quality check and remove image pairs with evidently incorrect annotations (e.g., ground- truth masks that completely miss a changed obj...
-
[52]
Trainable and Frozen Components.LangSCD is de- signed as a lightweight extension to existing scene change detection (SCD) backbones
Training Protocol This section provides detailed information on the training configuration, including which components are trainable, dataset usage, and optimization settings. Trainable and Frozen Components.LangSCD is de- signed as a lightweight extension to existing scene change detection (SCD) backbones. During training, theCross- modal Feature Enhance...
-
[53]
ChangeCLIP requires a set of predicate classes as lan- 2 guage inputs to guide change prediction
Additional Language-Guided Baseline: ChangeCLIP To further evaluate language-guided approaches for scene change detection, we evaluateChangeCLIP[7], a recent vision–language remote sensing change detection method, on the NYC-CD dataset. ChangeCLIP requires a set of predicate classes as lan- 2 guage inputs to guide change prediction. Since NYC-CD focuses o...
-
[54]
You are an expert to analyze images. You need to read images carefully
Prompts and Generation Settings for GPT- 4o We used GPT-4o [13] for dataset annotations and inference. The exact prompts are shown below. In addition to the prompt, we also report the full set of generation parameters for reproducibility. •Model:gpt-4o •Temperature:0.2(controls randomness; lower values yield more deterministic outputs) •Max tokens:4096 •T...
-
[55]
For each pair, GPT produced a change caption listingnew objects present in imageI0 but absent in imageI1
Evaluation of GPT-Generated Change Cap- tions To assess the reliability of GPT in describing object-level scene changes, we conducted a human evaluation on a ran- domly selected subset of800 image pairsfrom our dataset. For each pair, GPT produced a change caption listingnew objects present in imageI0 but absent in imageI1. We eval- uated these captions a...
-
[56]
Sweep over the Grounded-SAM thresholdα g withα t = 0.5
Threshold Sensitivity Analysis for SAM2–Grounded-SAM Agreement We study how the overlap thresholds used for Grounded- SAM [37] alignment and SAM2 [36] temporal tracking 3 Table 6. Sweep over the Grounded-SAM thresholdα g withα t = 0.5. αg GS Ratio Prec. Rec. F1 IoU 0.01 0.957 76.7 70.2 68.8 57.5 0.10 0.921 77.9 69.568.9 57.7 0.20 0.904 78.1 69.0 68.7 57.4...
-
[57]
Diagram of the language–image fusion mod- ule Please refer to Fig. 7
-
[58]
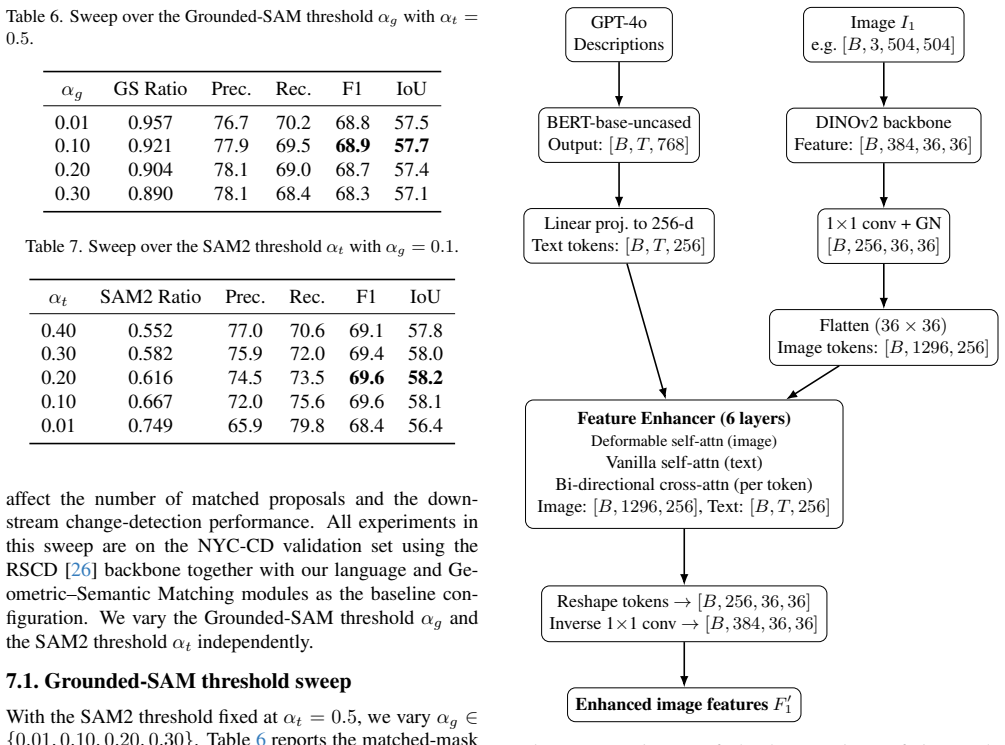
IoU measures the overlap GPT-4o Descriptions BERT-base-uncased Output:[B, T,768] Linear proj
Evaluation Metric We employ two standard metrics for the quantitative evalu- ation of binary change detection performance: Intersection over Union (IoU) and F-1 score. IoU measures the overlap GPT-4o Descriptions BERT-base-uncased Output:[B, T,768] Linear proj. to 256-d Text tokens:[B, T,256] ImageI 1 e.g.[B,3,504,504] DINOv2 backbone Feature:[B,384,36,36...
-
[59]
All captions are generated online during infer- ence
Inference-Time Caption Generation and Latency Analysis This section reports the end-to-end inference latency of our full system and clarifies the computational cost of each module. All captions are generated online during infer- ence. We profile the runtime of the major components 4 Figure 8. Higher IoU or F-1 score indicate better alignment with ground t...
-
[60]
Qualitative Results for Matching Module Please refer to Fig. 9
-
[61]
Qualitative Results for Multi-Class Change Detection Please refer to Fig. 10
-
[62]
The generalization capability of our language module is further validated through multi-domain experi- ments combining street view and remote sensing datasets (Figure 11)
Cross-Domain Generalization Results We include three remote sensing datasets: S2Looking [40], SYSU-CD [42], and CDD [20] to assess cross-domain gen- eralization. The generalization capability of our language module is further validated through multi-domain experi- ments combining street view and remote sensing datasets (Figure 11). Training a unified mode...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.