Recognition: unknown
Emulating Non-Differentiable Metrics via Knowledge-Guided Learning: Introducing the Minkowski Image Loss
Pith reviewed 2026-05-10 16:08 UTC · model grok-4.3
The pith
Constrained neural networks emulate non-differentiable Minkowski measures for precipitation fields without geometric errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formulate the Minkowski image loss as a differentiable equivalent to the integral-geometric measures of surface precipitation fields by training Lipschitz-convolutional neural networks stabilized through spectral normalization and hard geometric constraints, demonstrating high emulation accuracy and complete elimination of geometric violations on the EUMETNET OPERA dataset.
What carries the argument
Lipschitz-constrained convolutional neural networks that enforce geometric principles via spectral normalization and architectural constraints to emulate non-differentiable Minkowski functionals.
Load-bearing premise
That the stability-smoothness trade-off observed in deterministic super-resolution can be resolved by coupling the Lipschitz constraints with stochastic generative architectures to recover localized convective textures.
What would settle it
Running a precipitation super-resolution experiment with the Minkowski image loss inside a stochastic generative model and verifying whether the generated fields recover observed high-frequency convective textures while maintaining geometric consistency.
Figures




read the original abstract
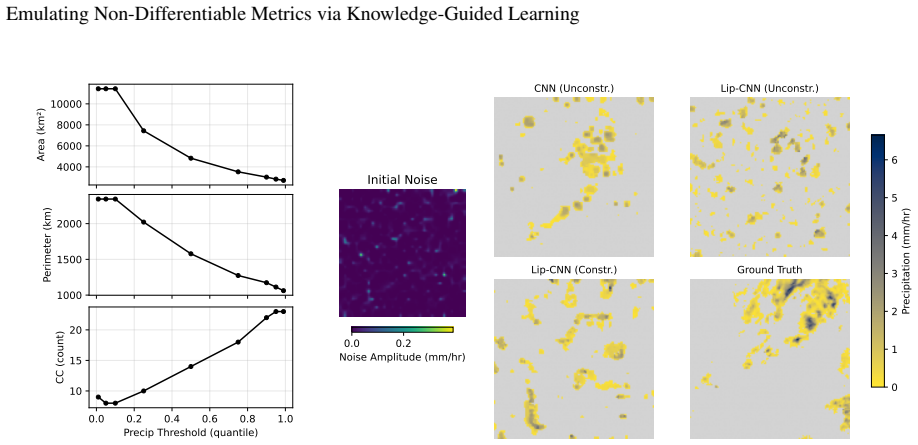
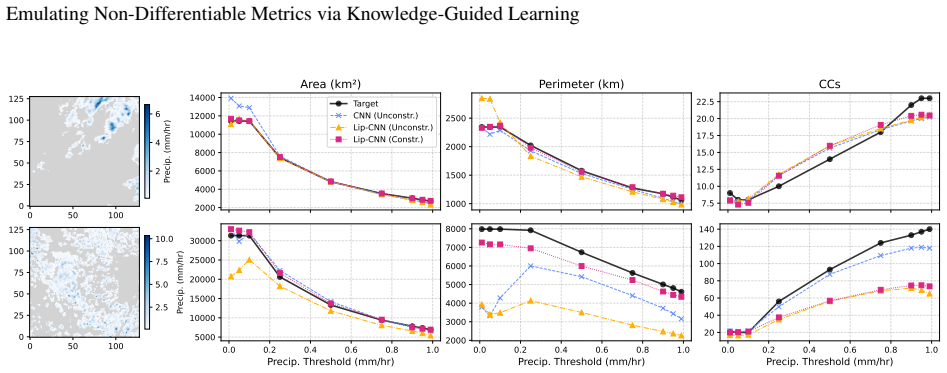
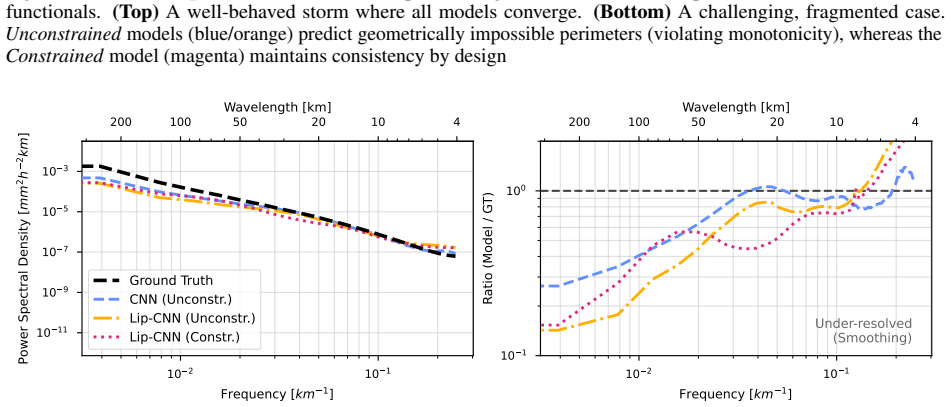
The ``differentiability gap'' presents a primary bottleneck in Earth system deep learning: since models cannot be trained directly on non-differentiable scientific metrics and must rely on smooth proxies (e.g., MSE), they often fail to capture high-frequency details, yielding ``blurry'' outputs. We develop a framework that bridges this gap using two different methods to deal with non-differentiable functions: the first is to analytically approximate the original non-differentiable function into a differentiable equivalent one; the second is to learn differentiable surrogates for scientific functionals. We formulate the analytical approximation by relaxing discrete topological operations using temperature-controlled sigmoids and continuous logical operators. Conversely, our neural emulator uses Lipschitz-convolutional neural networks to stabilize gradient learning via: (1) spectral normalization to bound the Lipschitz constant; and (2) hard architectural constraints enforcing geometric principles. We demonstrate this framework's utility by developing the Minkowski image loss, a differentiable equivalent for the integral-geometric measures of surface precipitation fields (area, perimeter, connected components). Validated on the EUMETNET OPERA dataset, our constrained neural surrogate achieves high emulation accuracy, completely eliminating the geometric violations observed in unconstrained baselines. However, applying these differentiable surrogates to a deterministic super-resolution task reveals a fundamental trade-off: while strict Lipschitz regularization ensures optimization stability, it inherently over-smooths gradient signals, restricting the recovery of highly localized convective textures. This work highlights the necessity of coupling such topological constraints with stochastic generative architectures to achieve full morphological realism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework to bridge the differentiability gap in Earth system deep learning by emulating non-differentiable Minkowski functionals (area, perimeter, connected components) for precipitation fields. It develops both an analytical approximation via temperature-controlled sigmoids and continuous logical operators, and a neural surrogate using Lipschitz-constrained CNNs with spectral normalization and hard geometric architectural constraints. The resulting Minkowski Image Loss is validated on the EUMETNET OPERA dataset, where the constrained surrogate reports high emulation accuracy and eliminates geometric violations observed in unconstrained baselines. When inserted as a loss in a deterministic super-resolution task, a stability-smoothness trade-off is identified, with the suggestion that stochastic generative architectures are needed to recover localized convective textures.
Significance. If the surrogate gradients prove faithful to the underlying non-differentiable functionals, the work could enable direct optimization on physically interpretable geometric metrics rather than MSE proxies, improving morphological realism in precipitation modeling. Strengths include the explicit dual-method approach (analytical and learned), the use of Lipschitz constraints for stability, and the clear identification of the stability-smoothness trade-off as a direction for future research. The validation on real OPERA data and the focus on integral-geometric measures provide a concrete testbed for knowledge-guided surrogates in scientific ML.
major comments (3)
- [Abstract and §5] Abstract and §5 (super-resolution experiments): The central claim that the Lipschitz-constrained surrogate 'completely eliminating the geometric violations' rests on pointwise emulation accuracy, yet the manuscript does not quantify gradient fidelity (e.g., cosine similarity or L2 distance between surrogate gradients and finite-difference approximations of the true Minkowski functionals). This is load-bearing because the differentiability gap is bridged only if the surrogate supplies usable gradients that recover high-frequency structure; value accuracy alone does not establish this, as noted by the observed over-smoothing.
- [§4.2] §4.2 (validation on OPERA data): The reported 'high emulation accuracy' lacks accompanying quantitative details such as per-functional MAE or RMSE with error bars, ablation results isolating spectral normalization versus hard geometric constraints, and direct comparison of geometric violation rates (e.g., number of disconnected components or perimeter errors) against the true non-differentiable measures. Without these, the strength of the 'complete elimination' claim relative to unconstrained baselines cannot be fully assessed.
- [§3.1] §3.1 (analytical approximation): The temperature parameter controlling the sigmoid relaxations is treated as a tunable hyperparameter; this introduces an additional degree of freedom whose effect on gradient quality and approximation error is not systematically characterized, which may limit the parameter-free character of the analytical path and interact with the Lipschitz constraints in the learned path.
minor comments (2)
- [§2] Notation for the Minkowski functionals (area, perimeter, connected components) should be consistently defined with symbols and referenced to the integral-geometry literature in the methods section.
- [Figure 4] Figure captions for the super-resolution results should explicitly state the quantitative metrics used to illustrate the stability-smoothness trade-off (e.g., which gradient norm or texture measure is plotted).
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which identify key areas for strengthening the validation of our Minkowski Image Loss framework. We address each major comment point by point below, providing clarifications and committing to specific revisions that will enhance the manuscript's rigor without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (super-resolution experiments): The central claim that the Lipschitz-constrained surrogate 'completely eliminating the geometric violations' rests on pointwise emulation accuracy, yet the manuscript does not quantify gradient fidelity (e.g., cosine similarity or L2 distance between surrogate gradients and finite-difference approximations of the true Minkowski functionals). This is load-bearing because the differentiability gap is bridged only if the surrogate supplies usable gradients that recover high-frequency structure; value accuracy alone does not establish this, as noted by the observed over-smoothing.
Authors: We agree that gradient fidelity is a critical aspect for validating the surrogate's ability to bridge the differentiability gap, particularly given the stability-smoothness trade-off observed in the super-resolution experiments. Our current claims of 'completely eliminating the geometric violations' are grounded in the surrogate outputs satisfying the integral-geometric properties (e.g., no spurious disconnected components or perimeter inconsistencies) on the OPERA validation set, which we view as indirect evidence of faithful emulation. However, we acknowledge that explicit quantification of gradient alignment would provide stronger support for the usability of these gradients in optimization. In the revised manuscript, we will add direct comparisons using cosine similarity and L2 distance between the surrogate gradients and finite-difference approximations of the true Minkowski functionals, computed on held-out precipitation fields. This analysis will be presented alongside the existing pointwise accuracy results to better contextualize the over-smoothing behavior. revision: yes
-
Referee: [§4.2] §4.2 (validation on OPERA data): The reported 'high emulation accuracy' lacks accompanying quantitative details such as per-functional MAE or RMSE with error bars, ablation results isolating spectral normalization versus hard geometric constraints, and direct comparison of geometric violation rates (e.g., number of disconnected components or perimeter errors) against the true non-differentiable measures. Without these, the strength of the 'complete elimination' claim relative to unconstrained baselines cannot be fully assessed.
Authors: We appreciate this observation, as the current manuscript relies on qualitative descriptions and the absence of violations in the constrained model to support the 'high emulation accuracy' statement. To enable a more rigorous assessment, the revised version will include detailed quantitative metrics: per-functional MAE and RMSE (for area, perimeter, and connected components) with error bars derived from multiple random seeds or cross-validation folds on the EUMETNET OPERA dataset. We will also add ablation experiments that isolate the effects of spectral normalization from the hard geometric architectural constraints. Finally, we will report explicit geometric violation rates—such as the mean number of disconnected components and perimeter deviation errors—for the constrained surrogate, unconstrained baselines, and the ground-truth non-differentiable computations, allowing direct comparison of the 'complete elimination' claim. revision: yes
-
Referee: [§3.1] §3.1 (analytical approximation): The temperature parameter controlling the sigmoid relaxations is treated as a tunable hyperparameter; this introduces an additional degree of freedom whose effect on gradient quality and approximation error is not systematically characterized, which may limit the parameter-free character of the analytical path and interact with the Lipschitz constraints in the learned path.
Authors: We concur that treating the temperature as a tunable hyperparameter introduces an extra degree of freedom that warrants further examination, especially for assessing its influence on gradient quality and any potential interactions with the learned Lipschitz-constrained path. The analytical approximation is intended as a complementary, interpretable alternative rather than a strictly parameter-free method, but we agree that its sensitivity has not been fully documented. In the revision, we will incorporate a systematic sensitivity study, including tables or figures that vary the temperature across a range of values and report the resulting changes in approximation error (MAE to true functionals) and gradient characteristics (e.g., norm and alignment with finite differences). This will clarify the trade-offs and strengthen the presentation of both the analytical and learned approaches. revision: yes
Circularity Check
No significant circularity; empirical surrogate training on external data
full rationale
The paper's core contribution is an empirical neural surrogate trained directly against the target non-differentiable Minkowski functionals (area, perimeter, connected components) on the external EUMETNET OPERA dataset, using spectral normalization and hard geometric constraints. No derivation step reduces a claimed prediction or uniqueness result to a fitted parameter, self-citation chain, or input by construction. The stability-smoothness trade-off is explicitly flagged as an open limitation rather than resolved tautologically. All load-bearing claims rest on held-out validation accuracy and baseline comparisons, which are falsifiable outside the model's own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- temperature parameter for sigmoid relaxations
axioms (1)
- domain assumption Lipschitz continuity of the emulator guarantees gradient stability during back-propagation
Reference graph
Works this paper leans on
-
[1]
AghaKouchak, A., Behrangi, A., Sorooshian, S., Hsu, K., and Amitai, E. (2011). Evaluation of satellite-retrieved extreme precipitation rates across the central united states.Journal of Geophysical Research: Atmospheres, 116(D2). Akiba, T., Sano, S., Yanase, T., Ohta, T., and Koyama, M. (2019). Optuna: A next-generation hyperparameter optimization framewor...
-
[2]
Gaussian Error Linear Units (GELUs)
Hadwiger, H. (1957).Vorlesungen über Inhalt, Oberfläche und Isoperimetrie. Springer. Hendrycks, D. and Gimpel, K. (2016). Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415. Hu, X., Li, F., Samaras, D., and Chen, C. (2019). Topology-preserving deep image segmentation. InAdvances in Neural Information Processing Systems, volume
work page internal anchor Pith review Pith/arXiv arXiv 1957
-
[3]
Jang, E., Gu, S., and Poole, B. (2017). Categorical reparameterization with gumbel-softmax. Karpatne, A., Atluri, G., Faghmous, J. H., Kumar, V ., et al. (2017). Theory-guided data science: A new paradigm for scientific discovery from data.IEEE Transactions on Knowledge and Data Engineering, 29(10):2318–2331. Maria, C., Boissonnat, J.-D., Glisse, M., and ...
2017
-
[4]
signal" (stable storm cells) from
states that the area of the set of points within a distance𝑟from𝐾(for sufficiently small𝑟≥0) is given by: 𝐴𝐾⊕𝑟 =𝐴 𝐾 +𝑃 𝐾 𝑟+𝜒 𝐾 𝜋𝑟 2 (3) where 𝐴𝐾 is the area, 𝑃𝐾 is the perimeter, and 𝜒𝐾 is the Euler characteristic of 𝐾. This formula holds not only for convex sets, but for any set with positive reach (Thäle, 2008), a condition satisfied by sufficiently reg...
2008
-
[5]
The claim follows almost immediately from the fundamental lemma of persistent homology (Edelsbrunner and Harer, 2010, p. 181). The rank of the 0th persistent homology group of the excursion setH 0(𝐸 𝑢) is given by the Betti number 𝛽𝑢,𝑢 0 =rank H0 (𝐸 𝑢)={# connected components of𝐸 𝑢}. Now, as a consequence of the fundamental lemma, 𝛽𝑢,𝑢 0 , which is the nu...
2010
-
[6]
checkerboard
Additionally, we explicitly handle the infinite-persistence feature (representing the global background component); this feature is included in the count only for low-intensity thresholds (𝑢≤0.01 mm h −1) to ensure consistent topology at the field boundaries. To generate the complete 𝜸-matrix for the entire dataset, we execute a rigorous offline target ge...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.