Recognition: unknown
RedShell: A Generative AI-Based Approach to Ethical Hacking
Pith reviewed 2026-05-10 15:27 UTC · model grok-4.3
The pith
RedShell shows a fine-tuned generative model can create syntactically valid malicious PowerShell code with under 10 percent parse errors for ethical hacking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
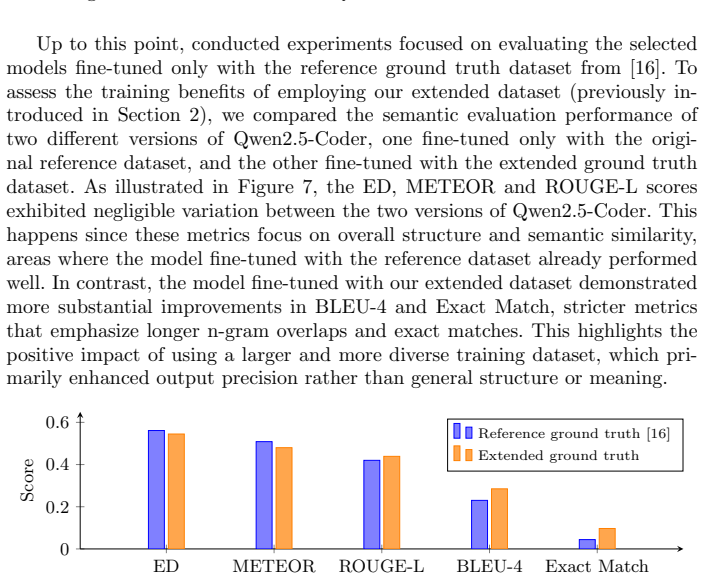
RedShell is a generative AI-based tool for malicious PowerShell code generation that fine-tunes models on a dataset of publicly available malicious snippets, enabling production of syntactically valid samples with fewer than 10 percent parse errors and semantically consistent outputs that exceed 50 percent mean similarity on Edit Distance and 40 percent on METEOR.
What carries the argument
RedShell, the fine-tuned generative model trained on a ground truth dataset of malicious PowerShell code samples, which automates creation of offensive scripts while preserving syntactic validity and semantic consistency with references.
If this is right
- Ethical hackers gain automation for building malicious code generators during pentest audits.
- Red teams can produce semantically consistent offensive PowerShell with reduced manual effort.
- Generative models specialized for malicious code show competitive results on standard similarity metrics.
- The work serves as a foundation for applying similar techniques in controlled ethical hacking environments.
Where Pith is reading between the lines
- Similar datasets could be assembled for other scripting languages to extend the approach beyond PowerShell.
- Real-world deployment in pentests would need additional checks to ensure generated code executes as intended beyond syntactic and similarity metrics.
- Public release of the dataset or model raises questions about preventing non-ethical uses that the paper does not address.
Load-bearing premise
A ground truth dataset assembled from publicly available code samples is sufficient, representative, and free of biases or legal issues for fine-tuning models that produce useful and ethically deployable malicious PowerShell code.
What would settle it
Testing the model on a fresh collection of prompts and observing more than 10 percent parse errors or METEOR similarity below 40 percent on average would falsify the reported performance.
Figures






read the original abstract
The application of Machine Learning techniques in code generation is now a common practice for most developers. Tools such as ChatGPT from OpenAI leverage the natural language processing capabilities of Large Language Models to generate machine code from natural language descriptions. In the cybersecurity field, red teams can also take advantage of generative models to build malicious code generators, providing more automation to Pentest audits. However, the application of Large Language Models in malicious code generation remains challenging due to the lack of data to train and evaluate offensive code generators. In this work, we propose RedShell, a tool that allows ethical hackers to generate malicious PowerShell code. We also introduce a ground truth dataset, combining publicly available code samples to fine-tune models in malicious PowerShell generation. Our experiments demonstrate the strong capabilities of RedShell in generating syntactically valid PowerShell, with fewer than 10% of the generated samples resulting in parse errors. Furthermore, our specialized model was able to produce samples that were semantically consistent with reference snippets, achieving a competitive performance on standard output similarity metrics such as Edit Distance and METEOR, with their mean similarity scores exceeding 50% and 40%, respectively. This work sheds light on the state-of-the-art research in the field of Generative AI applied to Pentesting, and also serves as a steppingstone for future advancements, highlighting the potential benefits these models hold within such controlled environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RedShell, a generative AI-based tool for ethical hacking that generates malicious PowerShell code. It presents a ground truth dataset compiled from publicly available code samples used to fine-tune large language models. The experiments claim that the specialized model generates syntactically valid PowerShell code with fewer than 10% parse errors and produces outputs semantically consistent with reference snippets, achieving mean similarity scores exceeding 50% on Edit Distance and 40% on METEOR.
Significance. If the performance claims hold after adding proper controls, RedShell could provide a practical resource for automating PowerShell generation in controlled penetration testing, addressing data scarcity for offensive security applications. The dataset introduction is a concrete contribution that future work could build upon.
major comments (3)
- [Experiments] Experiments section: the central claims of 'strong capabilities' and 'competitive performance' rest on absolute figures (<10% parse errors, mean Edit Distance >50%, METEOR >40%) with no baseline results reported for an unfine-tuned LLM, a general code model, or a retrieval baseline on the same held-out prompts and references. Without these controls the metrics cannot be attributed to the RedShell fine-tuning procedure.
- [§3] §3 (Dataset Construction): the ground truth dataset is described only as 'combining publicly available code samples' with no reported size, source list, train/test split ratios, or analysis of data leakage risk between training data and the held-out reference snippets used for similarity evaluation.
- [Evaluation] Evaluation subsection: mean similarity scores are given without the number of test samples, number of generations per prompt, standard deviations, or statistical tests, rendering the 'exceeding 50%' and 'exceeding 40%' figures difficult to interpret as evidence of reliable semantic consistency.
minor comments (2)
- [Abstract] Abstract: the phrase 'standard output similarity metrics' is used without defining how Edit Distance and METEOR are normalized or tokenized for PowerShell code snippets.
- Notation for the similarity metrics is introduced without an equation or pseudocode showing the exact implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the experimental rigor, dataset transparency, and evaluation reporting in our manuscript. We have revised the paper to address these points directly.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claims of 'strong capabilities' and 'competitive performance' rest on absolute figures (<10% parse errors, mean Edit Distance >50%, METEOR >40%) with no baseline results reported for an unfine-tuned LLM, a general code model, or a retrieval baseline on the same held-out prompts and references. Without these controls the metrics cannot be attributed to the RedShell fine-tuning procedure.
Authors: We agree that baseline comparisons are required to attribute performance gains specifically to the fine-tuning procedure. In the revised manuscript we have added results for the unfine-tuned base LLM and a general code model (CodeLlama) evaluated on the identical held-out prompts and references. A retrieval baseline is discussed as less applicable to a generative task, but we note this limitation explicitly rather than claiming full equivalence. revision: partial
-
Referee: [§3] §3 (Dataset Construction): the ground truth dataset is described only as 'combining publicly available code samples' with no reported size, source list, train/test split ratios, or analysis of data leakage risk between training data and the held-out reference snippets used for similarity evaluation.
Authors: We have expanded §3 to report the dataset size, enumerate the public sources, specify the train/test split, and include a data-leakage analysis with mitigation steps such as deduplication and verification that held-out references do not overlap with training data. revision: yes
-
Referee: [Evaluation] Evaluation subsection: mean similarity scores are given without the number of test samples, number of generations per prompt, standard deviations, or statistical tests, rendering the 'exceeding 50%' and 'exceeding 40%' figures difficult to interpret as evidence of reliable semantic consistency.
Authors: The Evaluation subsection has been revised to state the number of test samples, generations per prompt, standard deviations, and results of statistical tests supporting the reported mean similarity scores. revision: yes
Circularity Check
No circularity: empirical metrics are direct held-out comparisons
full rationale
The paper reports an empirical ML pipeline: public PowerShell samples are assembled into a ground-truth dataset, models are fine-tuned, and outputs are scored against held-out references using parse-error rate plus standard similarity metrics (Edit Distance, METEOR). No equations, self-definitional quantities, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims reduce only to ordinary train/test evaluation on external data, which is independent of the reported numbers by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Publicly available code samples can be combined into a representative ground truth dataset for fine-tuning malicious PowerShell generators.
Reference graph
Works this paper leans on
-
[1]
Atomic Red Team, Atomic Red Team: Adversary Emulation for Cybersecurity, (2024).https://www.atomicredteam.io/(visited on 01/31/2025)
2024
-
[2]
In: 2024 IEEE Inter- national Conference on Cyber Security and Resilience (CSR)
Bianou, S.G., Batogna, R.G.: PENTEST-AI, an LLM-Powered Multi-Agents Frame- work for Penetration Testing Automation Leveraging Mitre Attack. In: 2024 IEEE International Conference on Cyber Security and Resilience (CSR), pp. 763–770. IEEE (2024).https://doi.org/10.1109/CSR61664.2024.10679480
-
[3]
Sensors23(18), 1–18 (2023), https://doi.org/10.3390/s23188014
Chowdhary, A., Jha, K., Zhao, M.: Generative Adversarial Network (GAN)-Based Autonomous Penetration Testing for Web Applications. Sensors23(18), 1–18 (2023). https://doi.org/10.3390/s23188014
-
[4]
org/(visited on 01/31/2025)
Corporation, M.: MITRE ATT&CK Framework, (2024).https://attack.mitre. org/(visited on 01/31/2025)
2024
-
[5]
deepseek
DeepSeek-AI, DeepSeek Chat Platform, (2025).https : / / chat . deepseek . com/ (visited on 01/31/2025)
2025
-
[6]
Delpy, B.: Mimikatz, (2011).https://github.com/gentilkiwi/mimikatz(visited on 01/31/2025) RedShell 13
2011
-
[7]
In: 33rd USENIX Security Symposium (USENIX Security 24), pp
Deng, G., Liu, Y., Mayoral-Vilches, V., Liu, P., Li, Y., Xu, Y., Zhang, T., Liu, Y., Pinzger, M., Rass, S.: PentestGPT: Evaluating and Harnessing Large Language Models for Automated Penetration Testing. In: 33rd USENIX Security Symposium (USENIX Security 24), pp. 847–864. USENIX Association (2024).https://www. usenix.org/conference/usenixsecurity24/presen...
2024
-
[8]
Face, H.: Hugging Face, (2025).https://huggingface.co/(visited on 01/31/2025)
2025
-
[9]
doi:10.1109/ICSE-FoSE59343.2023.00008
Fan, A., Gokkaya, B., Harman, M., Lyubarskiy, M., Sengupta, S., Yoo, S., Zhang, J.M.: Large Language Models for Software Engineering: Survey and Open Prob- lems. In: 2023 IEEE/ACM International Conference on Software Engineering: Fu- ture of Software Engineering (ICSE-FoSE), pp. 31–53. IEEE (2023).https://doi. org/10.1109/ICSE-FoSE59343.2023.00008
-
[10]
org / abs / 2407
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A., Yang, A., Mitra, A., Sravankumar, A., Korenev, A.: The Llama 3 Herd of Models, (2024).https : / / arxiv . org / abs / 2407 . 21783(visited on 01/31/2025)
2024
-
[11]
Hugging Face, evaluate: A Python library for model evaluation and comparison, (2025).https://pypi.org/project/evaluate/(visited on 01/31/2025)
2025
-
[12]
Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Dang, K., Yang, A., Men, R., Huang, F., Ren, X., Ren, X., Zhou, J., Lin, J.: Qwen2.5 Coder Technical Report, (2024).https://arxiv.org/abs/2409.12186 (visited on 01/31/2025)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
kuangzh, pylcs: A super fast C++ implementation of classic LCS problems using dynamic programming, (2023).https://pypi.org/project/pylcs/(visited on 01/31/2025)
2023
-
[14]
In: 2021 IEEE 32nd International Symposium on Software Reliability Engineering (ISSRE), pp
Liguori, P., Al-Hossami, E., Orbinato, V., Natella, R., Shaikh, S., Cotroneo, D., Cukic, B.: EVIL: Exploiting Software via Natural Language. In: 2021 IEEE 32nd International Symposium on Software Reliability Engineering (ISSRE), pp. 321–
2021
-
[15]
IEEE (2021).https://doi.org/10.1109/ISSRE52982.2021.00042
-
[16]
Liguori, P., Improta, C., Natella, R., Cukic, B., Cotroneo, D.: Who evaluates the evaluators? On automatic metrics for assessing AI-based offensive code generators. Expert Systems with Applications225(2023).https://doi.org/10.1016/j. eswa.2023.120073
work page doi:10.1016/j 2023
-
[17]
In: 18th USENIX WOOT Conference on Offensive Technologies (WOOT 24), pp
Liguori, P., Marescalco, C., Natella, R., Orbinato, V., Pianese, L.: The Power of Words: Generating PowerShell Attacks from Natural Language. In: 18th USENIX WOOT Conference on Offensive Technologies (WOOT 24), pp. 27–43. USENIX As- sociation (2024).https://www.usenix.org/conference/woot24/presentation/ liguori
2024
-
[18]
Lu, S., Guo, D., Ren, S., Huang, J., Svyatkovskiy, A., Blanco, A., Clement, C.B., Drain, D., Jiang, D., Tang, D., Li, G., Zhou, L., Shou, L., Zhou, L., Tufano, M., Gong, M., Zhou, M., Duan, N., Sundaresan, N., Deng, S.K., Fu, S., Liu, S.: CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation. CoRRabs/2102.04664(2021).https:...
-
[19]
Microsoft Corporation, PSScriptAnalyzer, (2025).https://github.com/PowerShell/ PSScriptAnalyzer(visited on 01/31/2025)
2025
-
[20]
Bessa et al
Mittal, N.: Nishang - Offensive PowerShell for Red Teams, (2018).https : / / github.com/samratashok/nishang(visited on 01/31/2025) 14 R. Bessa et al
2018
-
[21]
https://pypi.org/project/rouge/(visited on 01/31/2025)
Mora, S.: ROUGE: A pure Python implementation of the ROUGE metric, (2019). https://pypi.org/project/rouge/(visited on 01/31/2025)
2019
-
[22]
Natella, R., Liguori, P., Improta, C., Cukic, B., Cotroneo, D.: AI Code Generators for Security: Friend or Foe? IEEE Security and Privacy22(5), 73–81 (2024).https: //doi.org/10.1109/MSEC.2024.3355713
-
[23]
OpenAI, ChatGPT: Overview and Features, (2025).https://openai.com/chatgpt/ overview/(visited on 01/31/2025)
2025
-
[24]
com / powershell-tips-tricks/(visited on 01/31/2025)
Recipe, R.T.: PowerShell tips & tricks, (2025).https : / / redteamrecipe . com / powershell-tips-tricks/(visited on 01/31/2025)
2025
-
[25]
github.io/blog/qwen2.5/(visited on 01/31/2025)
Team, Q.: Qwen2.5: A Party of Foundation Models, (2024).https : / / qwenlm . github.io/blog/qwen2.5/(visited on 01/31/2025)
2024
-
[26]
TryHackMe, TryHackMe - Learn Cybersecurity, Penetration Testing, and Ethical Hacking, (2025).https://tryhackme.com/(visited on 01/31/2025)
2025
-
[27]
Unsloth AI, Unsloth: Open Source Fine-Tuning for LLMs, (2025).https : / / unsloth.ai/(visited on 01/31/2025)
2025
-
[28]
Unsloth Team, LoRA Hyperparameters Guide — Unsloth Docs, (2024).https: //docs.unsloth.ai/get-started/fine-tuning-guide/lora-hyperparameters- guide(visited on 01/31/2025)
2024
-
[29]
Advances in Neural Information Pro- cessing Systems30, 5999–6009 (2017).https://proceedings.neurips.cc/paper_ files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention is all you need. Advances in Neural Information Pro- cessing Systems30, 5999–6009 (2017).https://proceedings.neurips.cc/paper_ files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
2017
-
[30]
Vats, P., Mandot, M., Gosain, A.: A Comprehensive Literature Review of Penetra- tion Testing and Its Applications. In: 2020 8th International Conference on Reli- ability, Infocom Technologies and Optimization (Trends and Future Directions) ( ICRITO), pp. 674–680. IEEE (2020).https://doi.org/10.1109/ICRITO48877. 2020.9197961
-
[31]
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., Davison, J., Shleifer, S., Platen, P., Ma, C., Jernite, Y., Plu, J., Xu, C., Scao, T., Gugger, S., Rush, A.: Transformers: State-of- the-Art Natural Language Processing. In: EMNLP 2020 - Conference on Empirical Methods in Natural Language Pr...
-
[32]
Santosa, Asankhaya Sharma, and Ming Yi Ang
Yang, G., Chen, X., Zhou, Y., Yu, C.: DualSC: Automatic Generation and Sum- marization of Shellcode via Transformer and Dual Learning. In: 2022 IEEE Inter- national Conference on Software Analysis, Evolution and Reengineering (SANER), pp. 361–372 (2022).https://doi.org/10.1109/SANER53432.2022.00052
-
[33]
Journal of Systems and Software197(2023), https://doi.org/10.1016/j.jss.2022.111577
Yang, G., Zhou, Y., Chen, X., Zhang, X., Han, T., Chen, T.: ExploitGen: Template- augmented exploit code generation based on CodeBERT. Journal of Systems and Software197(2023).https://doi.org/10.1016/j.jss.2022.111577
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.