Recognition: unknown
Prediction of chaotic dynamics from data: An introduction
Pith reviewed 2026-05-10 15:46 UTC · model grok-4.3
The pith
Machine learning can predict chaotic dynamics from finite time series data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
This chapter offers a principled approach to the prediction of chaotic systems from data. First, we introduce some concepts from dynamical systems' theory and chaos theory. Second, we introduce machine learning approaches for time-forecasting chaotic dynamics, such as echo state networks and long-short-term memory networks, whilst keeping a dynamical systems' perspective. Third, the lecture contains informal interpretations and pedagogical examples with prototypical chaotic systems (e.g., the Lorenz system).
What carries the argument
Echo state networks and long short-term memory networks, interpreted as recurrent dynamical systems that learn to reproduce chaotic time series from data.
If this is right
- Chaotic systems can be forecasted using recurrent neural networks trained on observed time series.
- The methods maintain sensitivity to initial conditions and other defining chaotic properties.
- Pedagogical examples with the Lorenz system clarify how the machine learning models replicate the dynamics.
- Supplementary coding tutorials enable direct implementation and testing of the forecasting techniques.
Where Pith is reading between the lines
- The same data-driven perspective could extend to hybrid models that blend learned dynamics with known physical equations for greater robustness.
- Statistical long-term behavior rather than exact short-term trajectories may prove more reliable for highly sensitive chaotic systems.
- The approach opens questions about how well these networks generalize across different chaotic regimes or parameter ranges.
Load-bearing premise
Finite observed time series data contain sufficient information for the chosen machine learning architectures to capture the essential chaotic dynamics without losing key properties such as sensitivity to initial conditions.
What would settle it
If the trained networks produce time series whose nearby trajectories diverge at a rate inconsistent with the positive Lyapunov exponent of the original system, such as the Lorenz equations, the prediction method would fail to capture the chaotic dynamics.
Figures
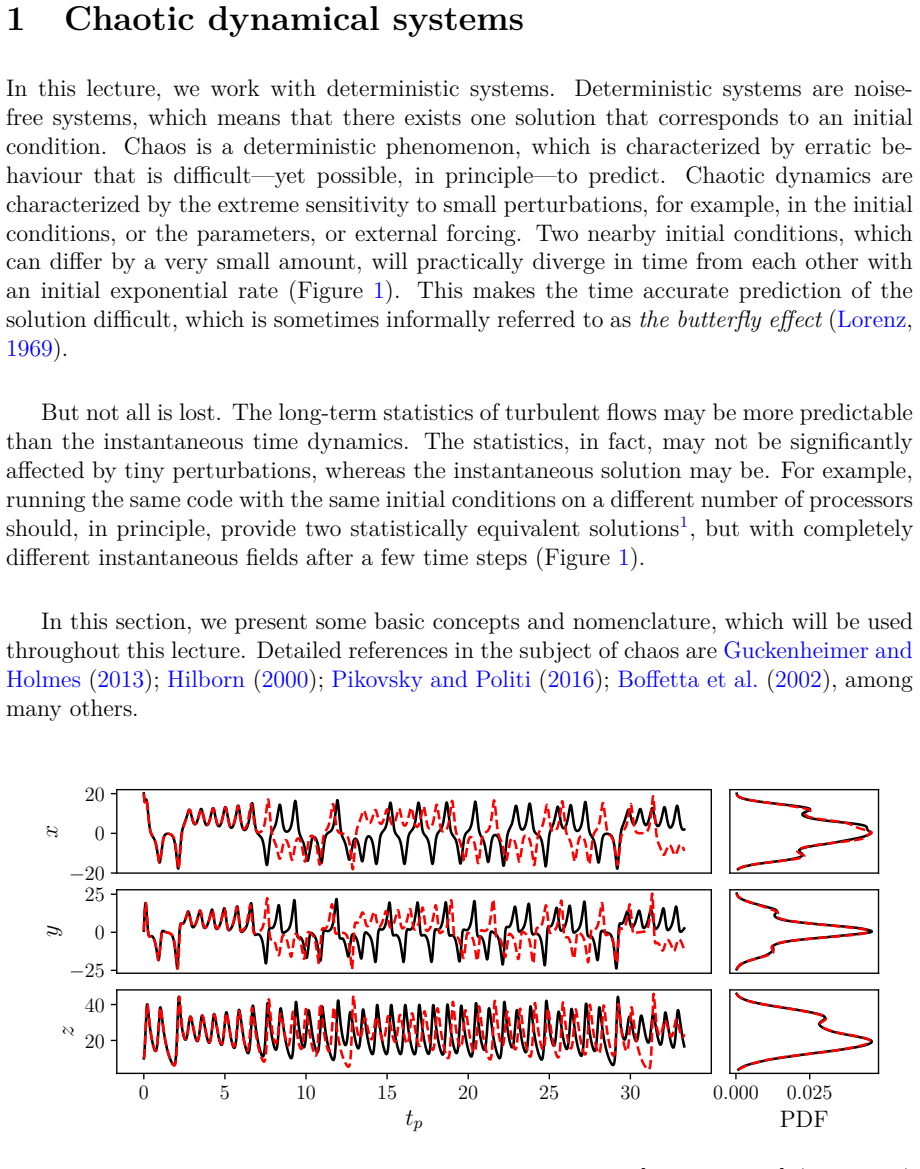
















read the original abstract
This chapter offers a principled approach to the prediction of chaotic systems from data. First, we introduce some concepts from dynamical systems' theory and chaos theory. Second, we introduce machine learning approaches for time-forecasting chaotic dynamics, such as echo state networks and long-short-term memory networks, whilst keeping a dynamical systems' perspective. Third, the lecture contains informal interpretations and pedagogical examples with prototypical chaotic systems (e.g., the Lorenz system), which elucidate the theory. The chapter is complemented by coding tutorials (online) at https://github.com/MagriLab/Tutorials.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is an introductory chapter that first reviews key concepts from dynamical systems and chaos theory, then presents machine learning methods for short-term forecasting of chaotic time series (specifically echo state networks and LSTM networks) while maintaining a dynamical-systems viewpoint, illustrates these with pedagogical examples on prototypical attractors such as the Lorenz system, and supplies accompanying reproducible coding tutorials hosted online.
Significance. If the explanations remain accurate and the tutorials execute without modification, the chapter supplies a compact, accessible bridge between nonlinear dynamics and data-driven forecasting techniques. Its explicit emphasis on reproducibility and the dynamical-systems framing of reservoir and recurrent architectures could lower the barrier for researchers entering this intersection, particularly when used in teaching or as a starting reference.
minor comments (3)
- [Abstract] The abstract states that the chapter offers 'a principled approach'; because the text is expository and applies previously validated architectures, this phrasing risks overstating novelty. Consider rephrasing to 'a dynamical-systems-guided introduction to ...' or similar in the abstract and opening paragraph.
- [Introduction / Tutorial section] The description of the online tutorials is limited to a GitHub link. Adding a brief table or paragraph that lists the specific systems, network hyperparameters, and forecast horizons covered in each notebook would help readers assess coverage before downloading code.
- [ML approaches section] Informal interpretations of sensitivity to initial conditions and attractor reconstruction are mentioned; ensure that any statements about preservation of Lyapunov exponents or attractor dimension in the ML forecasts are accompanied by explicit caveats or references to the relevant literature on reservoir computing.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript and the recommendation for minor revision. The referee's summary correctly captures the chapter's structure: an introduction to dynamical systems and chaos concepts, followed by machine-learning approaches (echo state networks and LSTMs) viewed from a dynamical-systems perspective, illustrated with examples such as the Lorenz attractor, and supported by online reproducible tutorials. We are pleased that the significance for lowering the entry barrier in this interdisciplinary area is recognized.
Circularity Check
Expository introduction with no load-bearing derivations or self-referential claims
full rationale
The manuscript is explicitly positioned as a pedagogical review that introduces standard dynamical-systems concepts, surveys existing machine-learning architectures (ESNs, LSTMs), and supplies informal examples plus external coding tutorials. No new theorems, parameter fits, uniqueness results, or quantitative predictions are derived; therefore no step reduces by construction to its own inputs, fitted data, or self-citation chains. The text remains self-contained against external benchmarks and contains no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard concepts from dynamical systems theory and chaos theory hold.
Reference graph
Works this paper leans on
-
[1]
Bennetin, G., Galgani, L., Giorgilli, A., and Strelcyn, J.-M. (1980). Lyapunov character- istic exponents for smooth dynamical systems and for hamiltonian systems: A method for computing all of them.Meccanica, 15(9):27. Birkhoff, G. D. (1931). Proof of the ergodic theorem.Proceedings of the National Academy of Sciences, 17(12):656–660. Blonigan, P. J., Fe...
1980
-
[2]
Harris, C.R., Millman, K.J., vanderWalt, S.J., Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N
Springer Science & Business Media. Harris, C.R., Millman, K.J., vanderWalt, S.J., Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N. J., Kern, R., Picus, M., Hoyer, S., van Kerkwijk, M. H., Brett, M., Haldane, A., del R’ıo, J. F., Wiebe, M., Peterson, P., G’erard-Marchant, P., Sheppard, K., Reddy, T., Weckesser, W., Abb...
2020
-
[3]
echo state
Hassanaly, M. and Raman, V. (2019). Ensemble-LES analysis of perturbation response of turbulent partially-premixed flames.Proc. Combust. Inst., 37(2):2249–2257. Hilborn, R. C. (2000).Chaos and nonlinear dynamics: an introduction for scientists and engineers. Oxford university press. Hochreiter, S. and Schmidhuber, J. (1997). Long short-term memory.Neural ...
2019
-
[4]
Lagaris, I
Cambridge university press. Lagaris, I. E., Likas, A., and Fotiadis, D. I. (1998). Artificial neural networks for solving ordinary and partial differential equations.IEEE Trans. Neural Networks, 9(5):987–
1998
-
[5]
Lorenz, E. N. (1963). Deterministic Nonperiodic Flow.Journal of the Atmospheric Sci- ences, 20(2):130–141. Lorenz, E. N. (1969). Atmospheric predictability as revealed by naturally occurring ana- logues.Journal of the Atmospheric sciences, 26(4):636–646. Lu, Z., Pathak, J., Hunt, B., Girvan, M., Brockett, R., and Ott, E. (2017). Reservoir observers: Model...
1963
-
[6]
Oseledets, V. I. (1968). A multiplicative ergodic theorem. characteristic lyapunov, ex- ponents of dynamical systems.Trudy Moskovskogo Matematicheskogo Obshchestva, 19:179–210. Özalp, E., Margazoglou, G., and Magri, L. (2023). Physics-informed long short-term memory for forecasting and reconstruction of chaos. InComputational Science – ICCS 2023, pages 38...
1968
-
[7]
Virtanen, P
Springer Science & Business Media. Virtanen, P. and et al. (2020). SciPy 1.0: Fundamental Algorithms for Scientific Com- puting in Python.Nature Methods, 17:261–272. Vlachas, P., Pathak, J., Hunt, B., Sapsis, T., Girvan, M., Ott, E., and Koumoutsakos, P. (2020). Backpropagation algorithms and reservoir computing in recurrent neural networks for the foreca...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.