Recognition: unknown
STS-Mixer: Spatio-Temporal-Spectral Mixer for 4D Point Cloud Video Understanding
Pith reviewed 2026-05-10 14:56 UTC · model grok-4.3
The pith
Transforming 4D point cloud videos into multi-band graph spectral signals and mixing them with spatiotemporal features improves capture of both coarse shapes and fine geometric details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
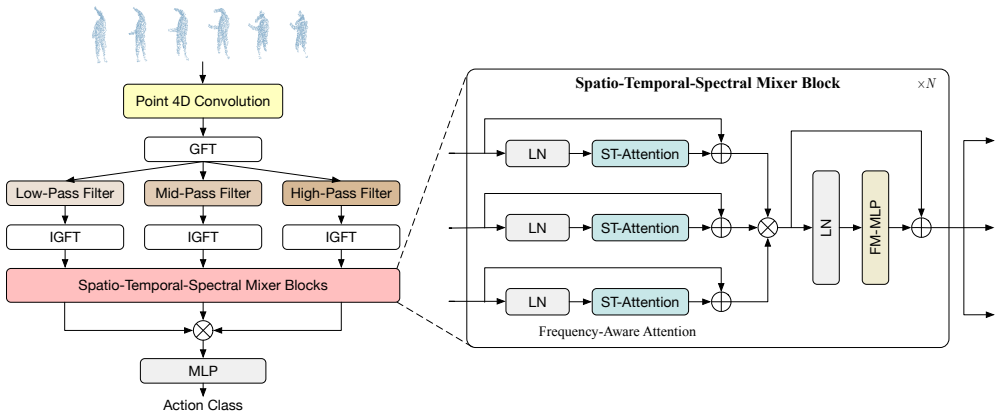
By transforming 4D point cloud videos into graph spectral signals, the signals can be decomposed into multiple frequency bands in which low-frequency components capture coarse shapes while high-frequency components encode fine-grained geometry details; STS-Mixer then integrates the multi-band spectral signals with spatiotemporal information to produce richer representations for 4D understanding.
What carries the argument
Spatio-Temporal-Spectral Mixer (STS-Mixer), a unified network that mixes spatial, temporal, and multi-band spectral representations derived from graph spectral decomposition of the input 4D point cloud video.
If this is right
- STS-Mixer produces higher accuracy than prior methods on standard 3D action recognition benchmarks.
- The same model also outperforms existing approaches on 4D semantic segmentation of point cloud videos.
- The spectral bands supply complementary geometric cues that pure spatiotemporal networks lack, enabling both fine-grained and holistic scene understanding.
- The framework remains a single unified architecture rather than separate pipelines for different frequency content.
Where Pith is reading between the lines
- The same spectral-decomposition step could be inserted into other graph-based 4D architectures without changing their overall training recipe.
- If the low- and high-frequency split generalizes across datasets, it offers a parameter-free way to inject multi-scale geometry into any point-cloud video model.
- The approach may extend naturally to other irregular dynamic data such as LiDAR sequences or motion-capture point sets where coarse-to-fine structure is also present.
Load-bearing premise
The assumption that spectral decomposition of point cloud videos reliably separates coarse shapes into low-frequency bands and fine details into high-frequency bands in a way that adds useful information when mixed with spatiotemporal features.
What would settle it
Run the same backbone on the action recognition and segmentation benchmarks once with the full STS-Mixer and once with the spectral mixing branch removed; if accuracy does not drop when the spectral branch is removed, the claimed benefit of the frequency-band integration is falsified.
Figures




read the original abstract
4D point cloud videos capture rich spatial and temporal dynamics of scenes which possess unique values in various 4D understanding tasks. However, most existing methods work in the spatiotemporal domain where the underlying geometric characteristics of 4D point cloud videos are hard to capture, leading to degraded representation learning and understanding of 4D point cloud videos. We address the above challenge from a complementary spectral perspective. By transforming 4D point cloud videos into graph spectral signals, we can decompose them into multiple frequency bands each of which captures distinct geometric structures of point cloud videos. Our spectral analysis reveals that the decomposed low-frequency signals capture more coarse shapes while high-frequency signals encode more fine-grained geometry details. Building on these observations, we design Spatio-Temporal-Spectral Mixer (STS-Mixer), a unified framework that mixes spatial, temporal, and spectral representations of point cloud videos. STS-Mixer integrates multi-band delineated spectral signals with spatiotemporal information to capture rich geometries and temporal dynamics, while enabling fine-grained and holistic understanding of 4D point cloud videos. Extensive experiments show that STS-Mixer achieves superior performance consistently across multiple widely adopted benchmarks on both 3D action recognition and 4D semantic segmentation tasks. Code and models are available at https://github.com/Vegetebird/STS-Mixer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STS-Mixer, a unified framework for 4D point cloud video understanding. It transforms input 4D point clouds into graph spectral signals, decomposes them into multiple frequency bands (claiming low-frequency bands capture coarse shapes and high-frequency bands encode fine-grained geometric details), and mixes the multi-band spectral representations with spatiotemporal features. The design is motivated by spectral analysis observations and is reported to achieve superior performance on 3D action recognition and 4D semantic segmentation benchmarks, with code released.
Significance. If the claimed frequency-band separation is quantitatively validated and shown to improve mixing over pure spatiotemporal baselines, the work would offer a useful complementary spectral lens for geometry-aware processing of dynamic point cloud videos. The public code release supports reproducibility and potential follow-up work in the field.
major comments (2)
- [Abstract and §3] Abstract and presumed §3 (Spectral Analysis): The central motivation that 'the decomposed low-frequency signals capture more coarse shapes while high-frequency signals encode more fine-grained geometry details' is presented as following from spectral analysis, yet no quantitative support (per-band reconstruction error, eigenfunction visualizations, or correlation metrics between frequency bands and geometric features) is provided for the chosen graph Laplacian on 4D data. This separation is load-bearing for justifying the multi-band mixer over existing spatiotemporal methods.
- [§4] §4 (Experiments): The claim of consistent superior performance across benchmarks requires explicit ablation studies isolating the contribution of the spectral mixing component (e.g., vs. spatiotemporal-only variants) and full tables with baselines, standard deviations, and statistical tests; without these, benchmark gains could arise from capacity or training differences rather than the spectral decomposition.
minor comments (1)
- [Abstract] Abstract: The phrasing 'possess unique values in various 4D understanding tasks' is slightly awkward and could be reworded for precision.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to strengthen the quantitative support and experimental rigor.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and presumed §3 (Spectral Analysis): The central motivation that 'the decomposed low-frequency signals capture more coarse shapes while high-frequency signals encode more fine-grained geometry details' is presented as following from spectral analysis, yet no quantitative support (per-band reconstruction error, eigenfunction visualizations, or correlation metrics between frequency bands and geometric features) is provided for the chosen graph Laplacian on 4D data. This separation is load-bearing for justifying the multi-band mixer over existing spatiotemporal methods.
Authors: We thank the referee for this observation. The original Section 3 provided qualitative visualizations of the decomposed bands on 4D point cloud examples, illustrating that low-frequency components preserve coarse geometry while high-frequency components capture finer details. However, we acknowledge the absence of quantitative metrics. In the revised manuscript we have added per-band reconstruction error curves using the 4D graph Laplacian, additional eigenfunction visualizations, and correlation analyses between band energies and geometric descriptors (e.g., mean curvature and normal variation). These new quantitative results appear in Section 3 and the supplementary material, directly supporting the frequency-band separation used to motivate the multi-band mixer. revision: yes
-
Referee: [§4] §4 (Experiments): The claim of consistent superior performance across benchmarks requires explicit ablation studies isolating the contribution of the spectral mixing component (e.g., vs. spatiotemporal-only variants) and full tables with baselines, standard deviations, and statistical tests; without these, benchmark gains could arise from capacity or training differences rather than the spectral decomposition.
Authors: We agree that isolating the spectral mixing contribution and providing statistical reporting are necessary. The original experiments contained component ablations, yet they did not include a direct spatiotemporal-only control or full statistical analysis. In the revision we have added (i) explicit ablations replacing the spectral branch with additional spatiotemporal layers of matched capacity, (ii) complete tables reporting mean accuracy/mIoU together with standard deviations over five random seeds, and (iii) paired t-tests with p-values against the strongest baselines. These expanded results are now in Section 4 and the appendix, confirming that the observed gains are attributable to the spectral mixing rather than capacity or training differences. revision: yes
Circularity Check
No circularity; spectral separation is an independent empirical observation motivating an architectural design
full rationale
The paper transforms 4D point cloud videos into graph spectral signals, performs spectral analysis to observe that low-frequency bands capture coarse shapes and high-frequency bands capture fine details, and then designs the STS-Mixer to integrate these with spatiotemporal features. This observation is presented as the output of analysis on the chosen graph Laplacian rather than a definitional restatement or fitted parameter renamed as a result. The mixer architecture follows as a motivated construction without any equation or claim reducing back to the input data by construction. No self-citations serve as load-bearing uniqueness theorems, no ansatz is smuggled via prior work, and no predictions are statistically forced from subsets of the same data. The derivation chain remains self-contained against external graph signal processing principles.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 4D point cloud videos can be represented as graph signals whose spectral decomposition yields frequency bands that capture distinct geometric structures (coarse shapes in low frequencies, fine details in high frequencies).
invented entities (1)
-
STS-Mixer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
3Din- Action: Understanding human actions in 3D point clouds
Yizhak Ben-Shabat, Oren Shrout, and Stephen Gould. 3Din- Action: Understanding human actions in 3D point clouds. In CVPR, pages 19978–19987, 2024
2024
-
[3]
Fast resampling of three-dimensional point clouds via graphs.IEEE Transactions on Signal Processing, 66(3):666–681, 2017
Siheng Chen, Dong Tian, Chen Feng, Anthony Vetro, and Jelena Kovaˇcevi´c. Fast resampling of three-dimensional point clouds via graphs.IEEE Transactions on Signal Processing, 66(3):666–681, 2017
2017
-
[4]
PointMixer: MLP-Mixer for point cloud understanding
Jaesung Choe, Chunghyun Park, Francois Rameau, Jaesik Park, and In So Kweon. PointMixer: MLP-Mixer for point cloud understanding. InECCV, pages 620–640, 2022
2022
-
[5]
4D spatio-temporal convnets: Minkowski convolutional neural networks
Christopher Choy, JunYoung Gwak, and Silvio Savarese. 4D spatio-temporal convnets: Minkowski convolutional neural networks. InCVPR, pages 3075–3084, 2019
2019
-
[6]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021
2021
-
[7]
Structural relational reasoning of point clouds
Yueqi Duan, Yu Zheng, Jiwen Lu, Jie Zhou, and Qi Tian. Structural relational reasoning of point clouds. InCVPR, pages 949–958, 2019
2019
-
[8]
Hehe Fan and Yi Yang. PointRNN: Point recurrent neural network for moving point cloud processing.arXiv preprint arXiv:1910.08287, 2019
-
[9]
Point 4D trans- former networks for spatio-temporal modeling in point cloud videos
Hehe Fan, Yi Yang, and Mohan Kankanhalli. Point 4D trans- former networks for spatio-temporal modeling in point cloud videos. InCVPR, pages 14204–14213, 2021
2021
-
[10]
PSTNet: Point spatio-temporal convolution on point cloud sequences
Hehe Fan, Xin Yu, Yuhang Ding, Yi Yang, and Mohan Kankanhalli. PSTNet: Point spatio-temporal convolution on point cloud sequences. InICLR, 2021
2021
-
[11]
Deep hierarchical representation of point cloud videos via spatio- temporal decomposition.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 44(12):9918–9930, 2021
Hehe Fan, Xin Yu, Yi Yang, and Mohan Kankanhalli. Deep hierarchical representation of point cloud videos via spatio- temporal decomposition.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 44(12):9918–9930, 2021
2021
-
[12]
Point spatio- temporal transformer networks for point cloud video mod- eling.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):2181–2192, 2023
Hehe Fan, Yi Yang, and Mohan Kankanhalli. Point spatio- temporal transformer networks for point cloud video mod- eling.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):2181–2192, 2023
2023
-
[13]
Wavelets on graphs via spectral graph theory.Applied and Computational Harmonic Analysis, 30(2):129–150, 2011
David K Hammond, Pierre Vandergheynst, and R´emi Gribon- val. Wavelets on graphs via spectral graph theory.Applied and Computational Harmonic Analysis, 30(2):129–150, 2011
2011
-
[14]
Masked motion prediction with semantic contrast for point cloud sequence learning
Yuehui Han, Can Xu, Rui Xu, Jianjun Qian, and Jin Xie. Masked motion prediction with semantic contrast for point cloud sequence learning. InECCV, pages 414–431, 2024
2024
-
[15]
Exploring the devil in graph spectral domain for 3D point cloud attacks
Qianjiang Hu, Daizong Liu, and Wei Hu. Exploring the devil in graph spectral domain for 3D point cloud attacks. InECCV, pages 229–248, 2022
2022
-
[16]
Graph signal processing for ge- ometric data and beyond: Theory and applications.IEEE Transactions on Multimedia, 24:3961–3977, 2021
Wei Hu, Jiahao Pang, Xianming Liu, Dong Tian, Chia-Wen Lin, and Anthony Vetro. Graph signal processing for ge- ometric data and beyond: Theory and applications.IEEE Transactions on Multimedia, 24:3961–3977, 2021
2021
-
[17]
X4D-Sceneformer: Enhanced scene understanding on 4D point cloud videos through cross-modal knowledge transfer
Linglin Jing, Ying Xue, Xu Yan, Chaoda Zheng, Dong Wang, Ruimao Zhang, Zhigang Wang, Hui Fang, Bin Zhao, and Zhen Li. X4D-Sceneformer: Enhanced scene understanding on 4D point cloud videos through cross-modal knowledge transfer. InAAAI, pages 2670–2678, 2024
2024
-
[18]
UST-SSM: Uni- fied spatio-temporal state space models for point cloud video modeling
Peiming Li, Ziyi Wang, Yulin Yuan, Hong Liu, Xiangming Meng, Junsong Yuan, and Mengyuan Liu. UST-SSM: Uni- fied spatio-temporal state space models for point cloud video modeling. InICCV, 2025
2025
-
[19]
Action recognition based on a bag of 3D points
Wanqing Li, Zhengyou Zhang, and Zicheng Liu. Action recognition based on a bag of 3D points. InCVPR Workshops, pages 9–14, 2010
2010
-
[20]
MHFormer: Multi-hypothesis transformer for 3D human pose estimation
Wenhao Li, Hong Liu, Hao Tang, Pichao Wang, and Luc Van Gool. MHFormer: Multi-hypothesis transformer for 3D human pose estimation. InCVPR, pages 13147–13156, 2022
2022
-
[21]
Hourglass tokenizer for efficient transformer-based 3D human pose estimation
Wenhao Li, Mengyuan Liu, Hong Liu, Pichao Wang, Jialun Cai, and Nicu Sebe. Hourglass tokenizer for efficient transformer-based 3D human pose estimation. InCVPR, pages 604–613, 2024
2024
-
[22]
Dingkang Liang, Tianrui Feng, Xin Zhou, Yumeng Zhang, Zhikang Zou, and Xiang Bai. Parameter-efficient fine-tuning in spectral domain for point cloud learning.arXiv preprint arXiv:2410.08114, 2024
-
[23]
PointMamba: A simple state space model for point cloud analysis
Dingkang Liang, Xin Zhou, Wei Xu, Xingkui Zhu, Zhikang Zou, Xiaoqing Ye, Xiao Tan, and Xiang Bai. PointMamba: A simple state space model for point cloud analysis. InNeurIPS, 2024
2024
-
[24]
Point cloud attacks in graph spectral domain: When 3D geometry meets graph signal processing.IEEE TPAMI, 46(5):3079–3095, 2023
Daizong Liu, Wei Hu, and Xin Li. Point cloud attacks in graph spectral domain: When 3D geometry meets graph signal processing.IEEE TPAMI, 46(5):3079–3095, 2023
2023
-
[25]
Mamba4D: Efficient long-sequence point cloud video understanding with disentangled spatial-temporal state space models
Jiuming Liu, Jinru Han, Lihao Liu, Angelica I Aviles-Rivero, Chaokang Jiang, Zhe Liu, and Hesheng Wang. Mamba4D: Efficient long-sequence point cloud video understanding with disentangled spatial-temporal state space models. InCVPR, 2025
2025
-
[26]
MeteorNet: Deep learning on dynamic 3D point cloud sequences
Xingyu Liu, Mengyuan Yan, and Jeannette Bohg. MeteorNet: Deep learning on dynamic 3D point cloud sequences. In ICCV, pages 9246–9255, 2019
2019
-
[27]
LeaF: learning frames for 4D point cloud sequence understanding
Yunze Liu, Junyu Chen, Zekai Zhang, Jingwei Huang, and Li Yi. LeaF: learning frames for 4D point cloud sequence understanding. InICCV, pages 604–613, 2023
2023
-
[28]
Swin Transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin Transformer: Hierarchical vision transformer using shifted windows. In ICCV, pages 10012–10022, 2021
2021
-
[29]
Rethinking network design and local geometry in point cloud: A simple residual MLP framework
Xu Ma, Can Qin, Haoxuan You, Haoxi Ran, and Yun Fu. Rethinking network design and local geometry in point cloud: A simple residual MLP framework. InICLR, 2022
2022
-
[30]
PointNet: Deep learning on point sets for 3D classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. PointNet: Deep learning on point sets for 3D classification and segmentation. InCVPR, pages 652–660, 2017
2017
-
[31]
PointNet++: Deep hierarchical feature learning on point sets in a metric space
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. PointNet++: Deep hierarchical feature learning on point sets in a metric space. InNeurIPS, 2017
2017
-
[32]
Spectral-GANs for high-resolution 3D point- cloud generation
Sameera Ramasinghe, Salman Khan, Nick Barnes, and Stephen Gould. Spectral-GANs for high-resolution 3D point- cloud generation. InIROS, pages 8169–8176, 2020
2020
-
[33]
The Synthia dataset: A 9 large collection of synthetic images for semantic segmenta- tion of urban scenes
German Ros, Laura Sellart, Joanna Materzynska, David Vazquez, and Antonio M Lopez. The Synthia dataset: A 9 large collection of synthetic images for semantic segmenta- tion of urban scenes. InCVPR, pages 3234–3243, 2016
2016
-
[34]
Patch- collaborative spectral point-cloud denoising
Guy Rosman, Anastasia Dubrovina, and Ron Kimmel. Patch- collaborative spectral point-cloud denoising. InComputer Graphics Forum, pages 1–12, 2013
2013
-
[35]
Masked spatio-temporal structure prediction for self-supervised learn- ing on point cloud videos
Zhiqiang Shen, Xiaoxiao Sheng, Hehe Fan, Longguang Wang, Yulan Guo, Qiong Liu, Hao Wen, and Xi Zhou. Masked spatio-temporal structure prediction for self-supervised learn- ing on point cloud videos. InICCV, pages 16580–16589, 2023
2023
-
[36]
PointCMP: Contrastive mask prediction for self-supervised learning on point cloud videos
Zhiqiang Shen, Xiaoxiao Sheng, Longguang Wang, Yulan Guo, Qiong Liu, and Xi Zhou. PointCMP: Contrastive mask prediction for self-supervised learning on point cloud videos. InCVPR, pages 1212–1222, 2023
2023
-
[37]
Con- trastive predictive autoencoders for dynamic point cloud self- supervised learning
Xiaoxiao Sheng, Zhiqiang Shen, and Gang Xiao. Con- trastive predictive autoencoders for dynamic point cloud self- supervised learning. InAAAI, pages 9802–9810, 2023
2023
-
[38]
Point contrastive prediction with semantic clustering for self-supervised learning on point cloud videos
Xiaoxiao Sheng, Zhiqiang Shen, Gang Xiao, Longguang Wang, Yulan Guo, and Hehe Fan. Point contrastive prediction with semantic clustering for self-supervised learning on point cloud videos. InICCV, pages 16515–16524, 2023
2023
-
[39]
David I Shuman, Sunil K Narang, Pascal Frossard, Antonio Ortega, and Pierre Vandergheynst. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains.IEEE Signal Processing Magazine, 30(3):83–98, 2013
2013
-
[40]
PvNeXt: Rethinking network design and temporal motion for point cloud video recognition
Jie Wang, Tingfa Xu, Lihe Ding, Xinjie Zhang, Long Bai, and Jianan Li. PvNeXt: Rethinking network design and temporal motion for point cloud video recognition. InICLR, 2025
2025
-
[41]
PointWavelet: Learning in spectral domain for 3-d point cloud analysis.IEEE Transactions on Neural Networks and Learning Systems, 2024
Cheng Wen, Jianzhi Long, Baosheng Yu, and Dacheng Tao. PointWavelet: Learning in spectral domain for 3-d point cloud analysis.IEEE Transactions on Neural Networks and Learning Systems, 2024
2024
-
[42]
Point primitive transformer for long-term 4D point cloud video understanding
Hao Wen, Yunze Liu, Jingwei Huang, Bo Duan, and Li Yi. Point primitive transformer for long-term 4D point cloud video understanding. InECCV, pages 19–35, 2022
2022
-
[43]
Modeling point clouds with self-attention and gumbel subset sampling
Jiancheng Yang, Qiang Zhang, Bingbing Ni, Linguo Li, Jinx- ian Liu, Mengdie Zhou, and Qi Tian. Modeling point clouds with self-attention and gumbel subset sampling. InCVPR, pages 3323–3332, 2019
2019
-
[44]
Point cloud attribute compression with graph transform
Cha Zhang, Dinei Florencio, and Charles Loop. Point cloud attribute compression with graph transform. InICIP, pages 2066–2070, 2014
2066
-
[45]
Hypergraph spectral analysis and processing in 3D point cloud.IEEE Transactions on Image Processing, 30:1193–1206, 2020
Songyang Zhang, Shuguang Cui, and Zhi Ding. Hypergraph spectral analysis and processing in 3D point cloud.IEEE Transactions on Image Processing, 30:1193–1206, 2020
2020
-
[46]
Point Cloud Mamba: Point cloud learning via state space model
Tao Zhang, Haobo Yuan, Lu Qi, Jiangning Zhang, Qianyu Zhou, Shunping Ji, Shuicheng Yan, and Xiangtai Li. Point Cloud Mamba: Point cloud learning via state space model. In AAAI, pages 10121–10130, 2025
2025
-
[47]
Complete-to-partial 4D distillation for self-supervised point cloud sequence representation learning
Zhuoyang Zhang, Yuhao Dong, Yunze Liu, and Li Yi. Complete-to-partial 4D distillation for self-supervised point cloud sequence representation learning. InCVPR, pages 17661–17670, 2023
2023
-
[48]
No pain, big gain: classify dynamic point cloud sequences with static models by fitting feature-level space-time surfaces
Jia-Xing Zhong, Kaichen Zhou, Qingyong Hu, Bing Wang, Niki Trigoni, and Andrew Markham. No pain, big gain: classify dynamic point cloud sequences with static models by fitting feature-level space-time surfaces. InCVPR, pages 8510–8520, 2022. 10
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.