Recognition: unknown
Hidden Failures in Robustness: Why Supervised Uncertainty Quantification Needs Better Evaluation
Pith reviewed 2026-05-10 15:07 UTC · model grok-4.3
The pith
Supervised uncertainty probes in language models often fail under distribution shifts, especially for long-form outputs, and their reliability depends more on chosen inputs than on model architecture.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present a systematic study of supervised uncertainty probes across models, tasks, and OOD settings, training over 2,000 probes while varying the representation layer, feature type, and token aggregation strategy. Our evaluation highlights poor robustness in current methods, particularly in the case of long-form generations. We also find that probe robustness is driven less by architecture and more by the probe inputs. Middle-layer representations generalise more reliably than final-layer hidden states, and aggregating across response tokens is consistently more robust than relying on single-token features. These differences are often largely invisible in-distribution but become more impo
What carries the argument
The controlled variation of probe inputs—representation layer, feature type, and token aggregation—when training supervised estimators on model hidden states to predict uncertainty.
If this is right
- Middle-layer representations and multi-token aggregation should be preferred when designing uncertainty probes.
- Standard in-distribution tests are insufficient to certify probe reliability.
- Simple hybrid back-off methods that switch to more robust input choices can raise overall performance under shift.
- Better evaluation protocols are a necessary step before deploying these probes for hallucination detection.
Where Pith is reading between the lines
- Current benchmarks for uncertainty estimation may systematically overestimate reliability in practical use.
- The same input choices that help under shift could be combined with other signals such as generation length to create more stable detectors.
- If the patterns hold, probe designers could reduce the search space for future methods by focusing on middle layers and aggregated features from the start.
Load-bearing premise
The chosen tasks, models, and out-of-distribution settings are representative enough of real-world shifts to reveal general patterns in probe robustness.
What would settle it
A new test set of distribution shifts, such as different model scales or entirely unseen long-form tasks, where the observed advantages of middle layers and token aggregation disappear or reverse.
Figures




read the original abstract
Recent work has shown that the hidden states of large language models contain signals useful for uncertainty estimation and hallucination detection, motivating a growing interest in efficient probe-based approaches. Yet it remains unclear how robust existing methods are, and which probe designs provide uncertainty estimates that are reliable under distribution shift. We present a systematic study of supervised uncertainty probes across models, tasks, and OOD settings, training over 2,000 probes while varying the representation layer, feature type, and token aggregation strategy. Our evaluation highlights poor robustness in current methods, particularly in the case of long-form generations. We also find that probe robustness is driven less by architecture and more by the probe inputs. Middle-layer representations generalise more reliably than final-layer hidden states, and aggregating across response tokens is consistently more robust than relying on single-token features. These differences are often largely invisible in-distribution but become more important under distribution shift. Informed by our evaluation, we explore a simple hybrid back-off strategy for improving robustness, arguing that better evaluation is a prerequisite for building more robust probes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a systematic empirical investigation into the robustness of supervised uncertainty quantification probes for large language models. By training more than 2,000 probes while varying the representation layer, feature type, and token aggregation strategy across multiple models, tasks, and out-of-distribution (OOD) settings, the authors find that current methods exhibit poor robustness, especially in long-form generation scenarios. They conclude that probe robustness is primarily driven by the choice of probe inputs rather than the underlying model architecture, with middle-layer representations and aggregation across response tokens showing better generalization under distribution shift. These differences are often not apparent in in-distribution evaluations. The paper also proposes a simple hybrid back-off strategy to enhance robustness.
Significance. If the results hold, this paper makes a valuable contribution by emphasizing the need for better evaluation practices in uncertainty estimation for LLMs and providing empirical guidance on probe design choices that improve robustness under shift. The extensive scale of the experiments (over 2,000 probes) is a strength, offering broad coverage. The finding that in-distribution performance can mask important robustness issues under shift is particularly insightful and could influence how future work evaluates such methods. The hybrid strategy offers a practical starting point for improvement.
major comments (2)
- [§4 (OOD Settings)] The construction of the long-form generation OOD shifts is not described in sufficient detail (e.g., whether shifts involve topic changes, stylistic variations, or length-induced effects). This is critical because the headline result on poor robustness in long-form cases and the relative importance of probe inputs vs. architecture depends on these shifts being representative of deployment-relevant distribution changes.
- [§5 (Empirical Results)] While the paper claims consistent advantages for middle layers and token aggregation under shift, there is no mention of statistical significance testing or adjustments for multiple comparisons across the large number of probes and settings. This makes it difficult to determine whether the observed differences are robust or could be due to variability, directly impacting the reliability of the design recommendations.
minor comments (2)
- [Abstract] The abstract states 'training over 2,000 probes' without providing a breakdown or exact count, which would better convey the study's scope.
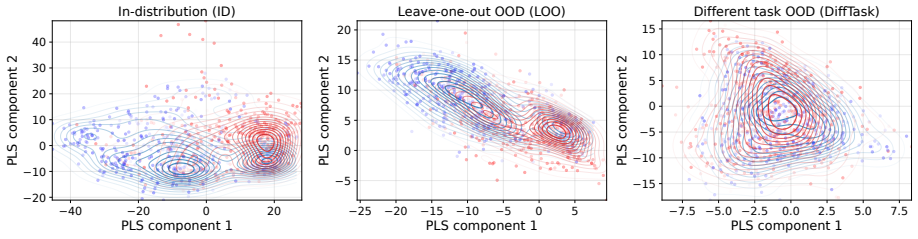
- [Figure captions] Some figures comparing in-distribution vs. OOD performance would benefit from clearer labeling of the axes and legends to highlight the key differences in robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the paper accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [§4 (OOD Settings)] The construction of the long-form generation OOD shifts is not described in sufficient detail (e.g., whether shifts involve topic changes, stylistic variations, or length-induced effects). This is critical because the headline result on poor robustness in long-form cases and the relative importance of probe inputs vs. architecture depends on these shifts being representative of deployment-relevant distribution changes.
Authors: We agree that the original description in §4 was insufficiently detailed. In the revised manuscript, we have expanded this section with explicit descriptions of the OOD construction process for long-form generation. This includes how topic shifts were implemented (e.g., from general to domain-specific queries), stylistic variations (e.g., changes in formality and structure), and controls for length-induced effects. We have also added concrete examples and a table summarizing the shift parameters to demonstrate that these are representative of realistic deployment changes. These additions directly support the robustness claims. revision: yes
-
Referee: [§5 (Empirical Results)] While the paper claims consistent advantages for middle layers and token aggregation under shift, there is no mention of statistical significance testing or adjustments for multiple comparisons across the large number of probes and settings. This makes it difficult to determine whether the observed differences are robust or could be due to variability, directly impacting the reliability of the design recommendations.
Authors: We acknowledge that formal statistical testing and multiple-comparison adjustments were not reported in the original submission. Our findings rely on consistent patterns observed across more than 2,000 probes, multiple models, and tasks, which we believe provide strong evidence of robustness. However, to address the concern, we have added basic significance testing (paired t-tests on key contrasts) in the revised §5, along with a discussion of observed variability. Full Bonferroni-style corrections across all settings proved computationally prohibitive given the experiment scale, but we now explicitly note this limitation and qualify our design recommendations accordingly. revision: partial
Circularity Check
Empirical evaluation with no derivation chain or self-referential reductions
full rationale
The paper conducts a large-scale empirical study training over 2,000 probes and comparing robustness across layers, feature types, and aggregation strategies under various OOD shifts. All claims rest on direct experimental measurements of performance differences (e.g., middle layers outperforming final layers, aggregation outperforming single-token features). No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central findings are observational comparisons that do not reduce to their own inputs by construction. Representativeness concerns about the chosen OOD regimes affect generalizability but do not constitute circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected OOD settings and tasks sufficiently represent real-world distribution shifts for uncertainty probes.
Reference graph
Works this paper leans on
-
[1]
Truth is universal: Robust detection of lies in llms. InAdvances in Neural Information Pro- cessing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, V ancouver , BC, Canada, December 10 - 15, 2024. Yung-Sung Chuang, Linlu Qiu, Cheng-Yu Hsieh, Ran- jay Krishna, Yoon Kim, and James R. Glass. 2024. Lookback lens: Det...
2024
-
[2]
InInternational Conference on Learning Representations
Measuring massive multitask language under- standing. InInternational Conference on Learning Representations. Karl Moritz Hermann, Tomás Kociský, Edward Grefen- stette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. 2015. Teaching machines to read and comprehend. InAdvances in Neural Information Processing Systems 28: Annual Conference on N...
-
[3]
Don’t give me the details, just the summary! topic-aware convolutional neural networks for ex- treme summarization. InProceedings of the 2018 Conference on Empirical Methods in Natural Lan- guage Processing, pages 1797–1807, Brussels, Bel- gium. Association for Computational Linguistics. Jingwei Ni, Ekaterina Fadeeva, Tianyi Wu, Mubashara Akhtar, Jiaheng ...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Siva Reddy, Danqi Chen, and Christopher D
OpenReview.net. Siva Reddy, Danqi Chen, and Christopher D. Manning
-
[5]
Coqa: A conversational question answering challenge.Trans. Assoc. Comput. Linguistics, 7:249– 266. Jie Ren, Stanislav Fort, Jeremiah Z. Liu, Abhijit Guha Roy, Shreyas Padhy, and Balaji Lakshminarayanan
-
[6]
Liu, Abhijit Guha Roy, Shreyas Padhy, and Balaji Lakshminarayanan
A simple fix to mahalanobis distance for im- proving near-ood detection.CoRR, abs/2106.09022. Andrea Santilli, Adam Golinski, Michael Kirchhof, Fed- erico Danieli, Arno Blaas, Miao Xiong, Luca Zap- pella, and Sinead Williamson. 2025. Revisiting un- certainty quantification evaluation in language mod- els: Spurious interactions with response length bias re...
-
[7]
Are the hidden states hiding something? test- ing the limits of factuality-encoding capabilities in LLMs. InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (V olume 1: Long Papers), pages 6089–6104, Vienna, Austria. Association for Computational Linguistics. Artem Shelmanov, Ekaterina Fadeeva, Akim Tsvigun, Ivan T...
-
[8]
InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 11328–11348, Toronto, Canada
AlignScore: Evaluating factual consistency with a unified alignment function. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 11328–11348, Toronto, Canada. Association for Computational Linguistics. Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. 2...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.